Intuitive Surgical SurgToolLoc and SurgVU Challenges Results: 2022-2025
Pith reviewed 2026-05-24 08:37 UTC · model grok-4.3
The pith
The SurgToolLoc and SurgVU challenges document AI performance in surgical tool localization and visual understanding from 2022 to 2025.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors document the winning methods and their performance scores in the SurgToolLoc challenge for tool localization and the SurgVU challenge for surgical visual understanding over the years 2022 to 2025.
What carries the argument
The evaluation on the SurgToolLoc and SurgVU datasets using metrics for localization accuracy and visual understanding tasks.
If this is right
- Future research can build on the top performing methods as baselines.
- The released dataset enables standardized comparisons in surgical data science.
- High performance in these tasks suggests AI is approaching usability for assisting in robotic procedures.
Where Pith is reading between the lines
- Successful methods from these challenges could be integrated into robotic systems to provide real-time feedback to surgeons.
- Extending the challenges to include more varied surgical procedures might reveal gaps in current models.
- The results imply that visual understanding in surgery is solvable with existing computer vision techniques when given appropriate training data.
Load-bearing premise
The challenge tasks and datasets provide a meaningful proxy for real clinical robotic surgery scenarios that will translate to improved patient outcomes.
What would settle it
Deploying the top challenge models in live robotic surgeries and comparing error rates or patient outcomes to standard procedures without AI assistance.
Figures




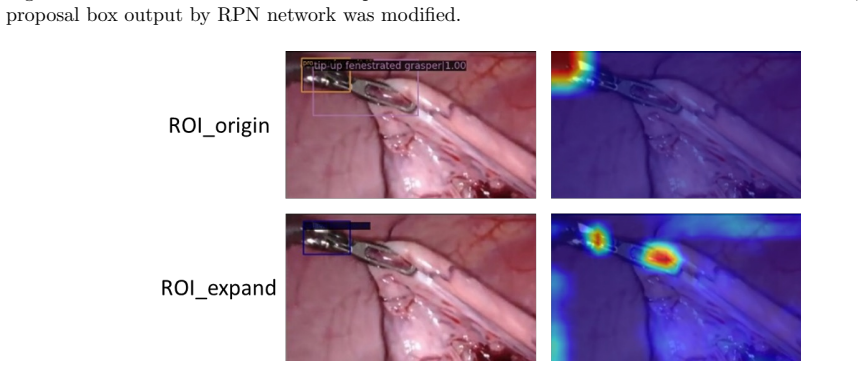































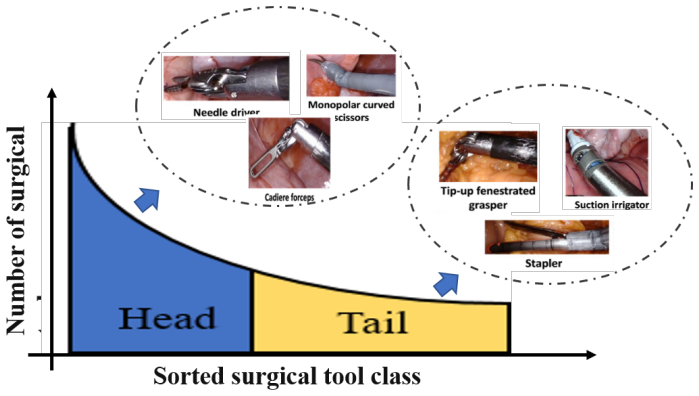






read the original abstract
Robotic assisted (RA) surgery promises to transform surgical intervention. Intuitive Surgical is committed to fostering these changes and the machine learning models and algorithms that will enable them. With these goals in mind we have invited the surgical data science community to participate in a yearly competition hosted through the Medical Imaging Computing and Computer Assisted Interventions (MICCAI) conference. With varying changes from year to year, we have challenged the community to solve difficult machine learning problems in the context of advanced RA applications. Here we document the results of these challenges, focusing on surgical tool localization (SurgToolLoc) and surgical visual understanding (SurgVU). The publicly released dataset that accompanies these challenges is detailed in a separate paper arXiv:2501.09209 [1].
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript documents the results of the Intuitive Surgical SurgToolLoc (surgical tool localization) and SurgVU (surgical visual understanding) challenges hosted annually at MICCAI from 2022 to 2025. It reports participation numbers, submitted methods, and performance metrics across the challenge tasks, while referring readers to a companion paper (arXiv:2501.09209) for details on the released datasets.
Significance. If the reported outcomes are accurate, the paper provides a useful archival record of community progress on standardized benchmarks in robotic surgery computer vision. Multi-year documentation of this form can help the field track incremental improvements in tool detection and scene understanding, and the public datasets enable follow-on reproducible work.
minor comments (3)
- The abstract states the purpose but contains no numerical results or key findings; the main text should include a concise summary table of top-performing methods and metrics in the introduction or a dedicated results overview section for quick reference.
- Ensure that all challenge years (2022–2025) are covered with consistent reporting of task definitions, evaluation metrics, and participation statistics; any year-to-year changes in rules or data should be explicitly tabulated.
- Clarify the relationship to the companion dataset paper: add a short paragraph in the introduction that distinguishes what is new in this results report versus what is already described in arXiv:2501.09209.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation to accept the manuscript. The assessment correctly identifies the value of a multi-year archival record of the SurgToolLoc and SurgVU challenges.
Circularity Check
No significant circularity detected
full rationale
The paper is a factual report documenting the results of the SurgToolLoc and SurgVU challenges from 2022-2025. It contains no mathematical derivations, predictions, fitted parameters, or generalization claims. The central claim is confined to reporting participation, methods, and numerical outcomes from external submissions, with the dataset referenced to a separate paper. No load-bearing self-citations, self-definitional steps, or reductions of outputs to inputs by construction are present. The derivation chain is empty by the nature of the document.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Surgical Visual Understanding (SurgVU) Dataset
Releases the SurgVU dataset of surgical videos and labels to enable machine learning research in surgical data science.
Reference graph
Works this paper leans on
-
[1]
Surgical visual understanding (surgvu) dataset, 2025
Aneeq Zia, Max Berniker, Rogerio Nespolo, Conor Perreault, Ziheng Wang, Benjamin Mueller, Ryan Schmidt, Kiran Bhattacharyya, Xi Liu, and Anthony Jarc. Surgical visual understanding (surgvu) dataset, 2025. 69
work page 2025
-
[2]
Trends in robot-assisted procedures for general surgery in the veterans health administration
Michael A Mederos, R Lorie Jacob, Rachel Ward, Rivfka Shenoy, Melinda M Gibbons, Mark D Girgis, Devan Kansagara, Denise Hynes, Paul G Shekelle, and Karli Kondo. Trends in robot-assisted procedures for general surgery in the veterans health administration. Journal of Surgical Research , 279:788–795, 2022
work page 2022
-
[3]
Exploring the paradigm of robotic surgery and its contribution to the growth of surgical volume
Emily A Grimsley, Tara M Barry, Haroon Janjua, Emanuel Eguia, Christopher DuCoin, and Paul C Kuo. Exploring the paradigm of robotic surgery and its contribution to the growth of surgical volume. Surgery Open Science, 10:36–42, 2022
work page 2022
-
[4]
Surgical data science– from concepts toward clinical translation
Lena Maier-Hein, Matthias Eisenmann, Duygu Sarikaya, Keno M¨ arz, Toby Collins, Anand Malpani, Johannes Fallert, Hubertus Feussner, Stamatia Giannarou, Pietro Mascagni, et al. Surgical data science– from concepts toward clinical translation. Medical image analysis, 76:102306, 2022
work page 2022
-
[5]
Surgical data science: the new knowledge domain
S Swaroop Vedula and Gregory D Hager. Surgical data science: the new knowledge domain. Innovative surgical sciences, 2(3):109–121, 2017
work page 2017
-
[6]
Sonia Guerin, Arnaud Huaulm´ e, Vincent Lavoue, Pierre Jannin, and Krystel Nyangoh Timoh. Review of automated performance metrics to assess surgical technical skills in robot-assisted laparoscopy. Surgical Endoscopy, pages 1–18, 2022
work page 2022
-
[7]
Francisco Luongo, Ryan Hakim, Jessica H Nguyen, Animashree Anandkumar, and Andrew J Hung. Deep learning-based computer vision to recognize and classify suturing gestures in robot-assisted surgery. Surgery, 169(5):1240–1244, 2021
work page 2021
-
[8]
Andrew J Hung, Jian Chen, Saum Ghodoussipour, Paul J Oh, Zequn Liu, Jessica Nguyen, Sanjay Pu- rushotham, Inderbir S Gill, and Yan Liu. A deep-learning model using automated performance metrics and clinical features to predict urinary continence recovery after robot-assisted radical prostatectomy. BJU international, 124(3):487–495, 2019
work page 2019
-
[9]
How to bring surgery to the next level: interpretable skills assessment in robotic-assisted surgery
Kristen C Brown, Kiran D Bhattacharyya, Sue Kulason, Aneeq Zia, and Anthony Jarc. How to bring surgery to the next level: interpretable skills assessment in robotic-assisted surgery. Visceral medicine, 36(6):463–470, 2020
work page 2020
-
[10]
Automated surgical skill assessment in rmis training
Aneeq Zia and Irfan Essa. Automated surgical skill assessment in rmis training. International journal of computer assisted radiology and surgery , 13(5):731–739, 2018
work page 2018
-
[11]
Temporal clustering of surgical activities in robot-assisted surgery
Aneeq Zia, Chi Zhang, Xiaobin Xiong, and Anthony M Jarc. Temporal clustering of surgical activities in robot-assisted surgery. International journal of computer assisted radiology and surgery , 12(7):1171– 1178, 2017
work page 2017
-
[12]
Novel evaluation of surgical activ- ity recognition models using task-based efficiency metrics
Aneeq Zia, Liheng Guo, Linlin Zhou, Irfan Essa, and Anthony Jarc. Novel evaluation of surgical activ- ity recognition models using task-based efficiency metrics. International journal of computer assisted radiology and surgery, 14(12):2155–2163, 2019
work page 2019
-
[13]
Surgical activity recognition in robot-assisted radical prostatectomy using deep learning
Aneeq Zia, Andrew Hung, Irfan Essa, and Anthony Jarc. Surgical activity recognition in robot-assisted radical prostatectomy using deep learning. In International Conference on Medical Image Computing and Computer-Assisted Intervention , pages 273–280. Springer, 2018
work page 2018
-
[14]
Biomedical image analysis competitions: The state of current participation practice
Matthias Eisenmann, Annika Reinke, Vivienn Weru, Minu Dietlinde Tizabi, Fabian Isensee, Tim J Adler, Patrick Godau, Veronika Cheplygina, Michal Kozubek, Sharib Ali, et al. Biomedical image analysis competitions: The state of current participation practice. arXiv preprint arXiv:2212.08568 , 2022
-
[15]
Surgical visual domain adaptation: results from the miccai 2020 surgvisdom challenge
Aneeq Zia, Kiran Bhattacharyya, Xi Liu, Ziheng Wang, Satoshi Kondo, Emanuele Colleoni, Beatrice van Amsterdam, Razeen Hussain, Raabid Hussain, Lena Maier-Hein, et al. Surgical visual domain adaptation: results from the miccai 2020 surgvisdom challenge. arXiv preprint arXiv:2102.13644, 2021. 70
-
[16]
Learning motion flows for semi- supervised instrument segmentation from robotic surgical video
Zixu Zhao, Yueming Jin, Xiaojie Gao, Qi Dou, and Pheng-Ann Heng. Learning motion flows for semi- supervised instrument segmentation from robotic surgical video. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part III 23 , pages 679–689. Springer, 2020
work page 2020
-
[17]
Aneeq Zia, Kiran Bhattacharyya, Xi Liu, Ziheng Wang, Max Berniker, Satoshi Kondo, Emanuele Colleoni, Dimitris Psychogyios, Yueming Jin, Jinfan Zhou, et al. Objective surgical skills assessment and tool localization: Results from the miccai 2021 simsurgskill challenge. arXiv preprint arXiv:2212.04448, 2022
-
[18]
Stereo correspondence and reconstruction of endoscopic data challenge
Max Allan, Jonathan Mcleod, Congcong Wang, Jean Claude Rosenthal, Zhenglei Hu, Niklas Gard, Peter Eisert, Ke Xue Fu, Trevor Zeffiro, Wenyao Xia, et al. Stereo correspondence and reconstruction of endoscopic data challenge. arXiv preprint arXiv:2101.01133 , 2021
-
[19]
2018 robotic scene segmentation challenge, 2020
Max Allan, Satoshi Kondo, Sebastian Bodenstedt, Stefan Leger, Rahim Kadkhodamohammadi, Imanol Luengo, Felix Fuentes, Evangello Flouty, Ahmed Mohammed, Marius Pedersen, Avinash Kori, Vargh- ese Alex, Ganapathy Krishnamurthi, David Rauber, Robert Mendel, Christoph Palm, Sophia Bano, Guinther Saibro, Chi-Sheng Shih, Hsun-An Chiang, Juntang Zhuang, Junlin Yan...
work page 2018
-
[20]
Endonet: a deep architecture for recognition tasks on laparoscopic videos
Andru P Twinanda, Sherif Shehata, Didier Mutter, Jacques Marescaux, Michel De Mathelin, and Nicolas Padoy. Endonet: a deep architecture for recognition tasks on laparoscopic videos. IEEE transactions on medical imaging, 36(1):86–97, 2016
work page 2016
-
[21]
Amy Jin, Serena Yeung, Jeffrey Jopling, Jonathan Krause, Dan Azagury, Arnold Milstein, and Li Fei- Fei. Tool detection and operative skill assessment in surgical videos using region-based convolutional neural networks. In 2018 IEEE winter conference on applications of computer vision (WACV) , pages 691–699. IEEE, 2018
work page 2018
-
[22]
Imagenet large scale visual recognition challenge
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision , 115(3):211–252, 2015
work page 2015
-
[23]
Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines
Yinda Xu, Zeyu Wang, Zuoxin Li, Ye Yuan, and Gang Yu. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 12549–12556, 2020
work page 2020
-
[24]
Cascade r-cnn: Delving into high quality object detection
Zhaowei Cai and Nuno Vasconcelos. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6154–6162, 2018
work page 2018
-
[25]
2017 robotic instrument segmentation challenge, 2019
Max Allan, Alex Shvets, Thomas Kurmann, Zichen Zhang, Rahul Duggal, Yun-Hsuan Su, Nicola Rieke, Iro Laina, Niveditha Kalavakonda, Sebastian Bodenstedt, Luis Herrera, Wenqi Li, Vladimir Iglovikov, Huoling Luo, Jian Yang, Danail Stoyanov, Lena Maier-Hein, Stefanie Speidel, and Mahdi Azizian. 2017 robotic instrument segmentation challenge, 2019
work page 2017
-
[26]
Shvets, Alexander Rakhlin, Alexandr A
Alexey A. Shvets, Alexander Rakhlin, Alexandr A. Kalinin, and Vladimir I. Iglovikov. Automatic instrument segmentation in robot-assisted surgery using deep learning. In 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA) . IEEE, December 2018
work page 2018
-
[27]
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, and Saining Xie. A convnet for the 2020s. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11976–11986, 2022
work page 2022
-
[28]
Efficientnet: Rethinking model scaling for convolutional neural networks
Mingxing Tan and Quoc Le. Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning , pages 6105–6114. PMLR, 2019. 71
work page 2019
-
[29]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision , pages 618–626, 2017
work page 2017
- [30]
-
[31]
Weakly supervised pseudo-label assisted learning for als point cloud semantic segmentation
Puzuo Wang and Wei Yao. Weakly supervised pseudo-label assisted learning for als point cloud semantic segmentation. arXiv preprint arXiv:2105.01919 , 2021
-
[32]
Fastai: A layered API for deep learning
Jeremy Howard and Sylvain Gugger. Fastai: A layered API for deep learning. Information, 11(2):108, feb 2020
work page 2020
-
[33]
Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen Lo, and Ross Girshick. Detectron2, 2019
work page 2019
-
[34]
Surgical tool detection in open surgery videos
Ryo Fujii, Ryo Hachiuma, Hiroki Kajita, and Hideo Saito. Surgical tool detection in open surgery videos. Applied Sciences, 12(20), 2022
work page 2022
-
[35]
Swin transformer v2: Scaling up capacity and resolution
Ze Liu, Han Hu, Yutong Lin, Zhuliang Yao, Zhenda Xie, Yixuan Wei, Jia Ning, Yue Cao, Zheng Zhang, Li Dong, Furu Wei, and Baining Guo. Swin transformer v2: Scaling up capacity and resolution. In CVPR, pages 12009–12019, June 2022
work page 2022
-
[36]
Efficientnetv2: Smaller models and faster training
Mingxing Tan and Quoc Le. Efficientnetv2: Smaller models and faster training. In ICML, 2021
work page 2021
-
[37]
Aggregated Residual Transformations for Deep Neural Networks
Saining Xie, Ross B. Girshick, Piotr Doll´ ar, Zhuowen Tu, and Kaiming He. Aggregated residual trans- formations for deep neural networks. CoRR, abs/1611.05431, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [38]
-
[39]
Grad- cam++: Generalized gradient-based visual explanations for deep convolutional networks
Aditya Chattopadhay, Anirban Sarkar, Prantik Howlader, and Vineeth N Balasubramanian. Grad- cam++: Generalized gradient-based visual explanations for deep convolutional networks. In WACV, 2018
work page 2018
-
[40]
Imagenet: A large-scale hierar- chical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierar- chical image database. In CVPR, 2009
work page 2009
-
[41]
Shallow feature matters for weakly supervised object localization
Jun Wei, Qin Wang, Zhen Li, Sheng Wang, S Kevin Zhou, and Shuguang Cui. Shallow feature matters for weakly supervised object localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5993–6001, 2021
work page 2021
-
[42]
Query2label: A simple transformer way to multi-label classification
Shilong Liu, Lei Zhang, Xiao Yang, Hang Su, and Jun Zhu. Query2label: A simple transformer way to multi-label classification. arXiv preprint arXiv:2107.10834 , 2021
-
[43]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
work page 2016
-
[44]
Asymmetric loss for multi-label classification
Emanuel Ben-Baruch, Tal Ridnik, Nadav Zamir, Asaf Noy, Itamar Friedman, Matan Protter, and Lihi Zelnik-Manor. Asymmetric loss for multi-label classification. arXiv preprint arXiv:2009.14119 , 2020
-
[45]
Gary Bradski. The opencv library. Dr. Dobb’s Journal: Software Tools for the Professional Programmer, 25(11):120–123, 2000
work page 2000
-
[46]
Emerging Properties in Self-Supervised Vision Transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, et al. Emerging Properties in Self-Supervised Vision Transformers. In ICCV, 2021
work page 2021
-
[47]
iBOT: Image BERT Pre-Training with Online Tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, et al. iBOT: Image BERT Pre-Training with Online Tokenizer. ICLR, 2022
work page 2022
-
[48]
A deep learning spatial-temporal framework for detecting surgical tools in laparoscopic videos
Tamer Abdulbaki Alshirbaji, Nour Aldeen Jalal, Paul D Docherty, Thomas Neumuth, and Knut M¨ oller. A deep learning spatial-temporal framework for detecting surgical tools in laparoscopic videos. Biomed- ical Signal Processing and Control , 68:102801, 2021. 72
work page 2021
-
[49]
Thibaut Durand, Taylor Mordan, Nicolas Thome, and Matthieu Cord. Wildcat: Weakly supervised learning of deep convnets for image classification, pointwise localization and segmentation. In Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 642–651, 2017
work page 2017
-
[50]
Weakly-supervised learn- ing for tool localization in laparoscopic videos
Armine Vardazaryan, Didier Mutter, Jacques Marescaux, and Nicolas Padoy. Weakly-supervised learn- ing for tool localization in laparoscopic videos. In Intravascular Imaging and Computer Assisted Stenting and Large-Scale Annotation of Biomedical Data and Expert Label Synthesis , pages 169–179. Springer, 2018
work page 2018
-
[51]
Chinedu Innocent Nwoye, Didier Mutter, Jacques Marescaux, and Nicolas Padoy. Weakly supervised convolutional LSTM approach for tool tracking in laparoscopic videos.International journal of computer assisted radiology and surgery, 14(6):1059–1067, 2019
work page 2019
-
[52]
Squeeze-and-excitation networks
Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages 7132–7141, 2018
work page 2018
-
[53]
T. Abdulbaki Alshirbaji, Nour A. Jalal, Paul D. Docherty, P. T. Neumuth, and Knut M¨ oller. Improving the Generalisability of Deep CNNs by Combining Multi-stage Features for Surgical Tool Classification. In 2022 44th Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 533–536. IEEE, 2022
work page 2022
-
[54]
Surgical tool classification in la- paroscopic videos using convolutional neural network
Tamer Abdulbaki Alshirbaji, Nour Aldeen Jalal, and Knut M¨ oller. Surgical tool classification in la- paroscopic videos using convolutional neural network. Current Directions in Biomedical Engineering , 4(1):407–410, 2018
work page 2018
-
[55]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint, 2020
work page 2020
-
[56]
DeVries Terrance, and Graham W. Taylor. Improved regularization of convolutional neural networks with cutout. arXiv preprint
-
[57]
Randaugment: Practical automated data augmentation with a reduced search space
Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. arXiv e-prints, 2019
work page 2019
-
[58]
Asymmetric loss for multi-label classification
Tal Ridnik, Emanuel Ben-Baruch, Nadav Zamir, Asaf Noy, Itamar Friedman, Matan Protter, and Lihi Zelnik-Manor. Asymmetric loss for multi-label classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision , pages 82–91, 2021
work page 2021
-
[59]
YOLOv4: Optimal Speed and Accuracy of Object Detection
Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 , 2020
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[60]
Cholecseg8k: a semantic segmen- tation dataset for laparoscopic cholecystectomy based on cholec80
W-Y Hong, C-L Kao, Y-H Kuo, J-R Wang, W-L Chang, and C-S Shih. Cholecseg8k: a semantic segmen- tation dataset for laparoscopic cholecystectomy based on cholec80. arXiv preprint arXiv:2012.12453 , 2020
-
[61]
Lena Maier-Hein, Sven Mersmann, Daniel Kondermann, Sebastian Bodenstedt, Alexandro Sanchez, Christian Stock, Hannes Gotz Kenngott, Mathias Eisenmann, and Stefanie Speidel. Can masses of non- experts train highly accurate image classifiers? In International conference on medical image computing and computer-assisted intervention, pages 438–445. Springer, 2014
work page 2014
-
[62]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[63]
Weakly supervised convolutional lstm approach for tool tracking in laparoscopic videos
Chinedu Innocent Nwoye, Didier Mutter, Jacques Marescaux, and Nicolas Padoy. Weakly supervised convolutional lstm approach for tool tracking in laparoscopic videos. International journal of computer assisted radiology and surgery, 14:1059–1067, 2019. 73
work page 2019
-
[64]
Chinedu Innocent Nwoye, Tong Yu, Cristians Gonzalez, Barbara Seeliger, Pietro Mascagni, Didier Mutter, Jacques Marescaux, and Nicolas Padoy. Rendezvous: Attention mechanisms for the recognition of surgical action triplets in endoscopic videos. Medical Image Analysis, 78:102433, 2022
work page 2022
-
[65]
Rethinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826, 2016
work page 2016
-
[66]
Fastai: A layered api for deep learning
Jeremy Howard and Sylvain Gugger. Fastai: A layered api for deep learning. Information, 11(2):108, 2020
work page 2020
-
[67]
Deep learning with noisy labels: Exploring techniques and remedies in medical image analysis
Davood Karimi, Haoran Dou, Simon K Warfield, and Ali Gholipour. Deep learning with noisy labels: Exploring techniques and remedies in medical image analysis. Medical image analysis, 65:101759, 2020
work page 2020
-
[68]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duch- esnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011
work page 2011
-
[69]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[70]
Faster r-cnn: Towards real-time object detection with region proposal networks, 2016
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks, 2016
work page 2016
-
[71]
U-net: Convolutional networks for biomedical image segmentation, 2015
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation, 2015
work page 2015
-
[72]
Ultralytics YOLO, January 2023
Glenn Jocher, Ayush Chaurasia, and Jing Qiu. Ultralytics YOLO, January 2023
work page 2023
-
[73]
Mixformer: End-to-end tracking with iterative mixed attention, 2022
Yutao Cui, Cheng Jiang, Limin Wang, and Gangshan Wu. Mixformer: End-to-end tracking with iterative mixed attention, 2022
work page 2022
-
[74]
Dinov2: Learning robust visual features without supervision, 2024
Maxime Oquab, Timoth´ ee Darcet, Th´ eo Moutakanni, Huy Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv´ e Jegou, Julien Mairal, Patri...
work page 2024
-
[75]
Deep residual learning for image recognition, 2015
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015
work page 2015
-
[76]
Masked autoen- coders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollar, and Ross Girshick. Masked autoen- coders are scalable vision learners. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun 2022
work page 2022
-
[77]
Joint feature learning and relation modeling for tracking: A one-stream framework
Botao Ye, Hong Chang, Bingpeng Ma, and Shiguang Shan. Joint feature learning and relation modeling for tracking: A one-stream framework
-
[78]
Yolox: Exceeding yolo series in 2021
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun, and Megvii Technology. Yolox: Exceeding yolo series in 2021
work page 2021
-
[79]
Rtmdet: An empirical study of designing real-time object detectors
Chengqi Lyu, Wenwei Zhang, Haian Huang, Yue Zhou, Yudong Wang, Yanyi Liu, Shilong Zhang, Kai Chen, Concat Conv, and Resize Concat. Rtmdet: An empirical study of designing real-time object detectors
-
[80]
Weighted boxes fusion: Ensembling boxes from different object detection models
Roman Solovyev, Weimin Wang, and Tatiana Gabruseva. Weighted boxes fusion: Ensembling boxes from different object detection models. Image and Vision Computing , page 104117, Mar 2021. 74
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.