AgentReview: Exploring Peer Review Dynamics with LLM Agents
Pith reviewed 2026-05-23 23:36 UTC · model grok-4.3
The pith
An LLM agent simulation framework shows reviewer biases cause 37.1% variation in paper decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
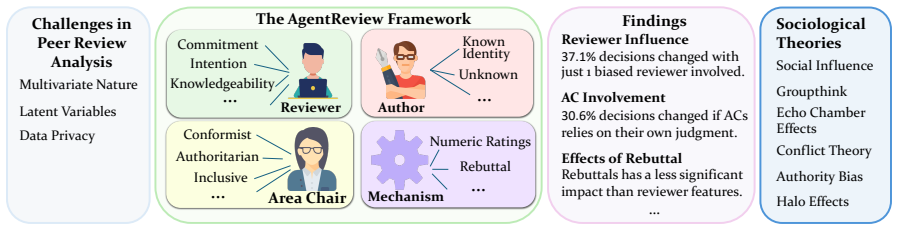
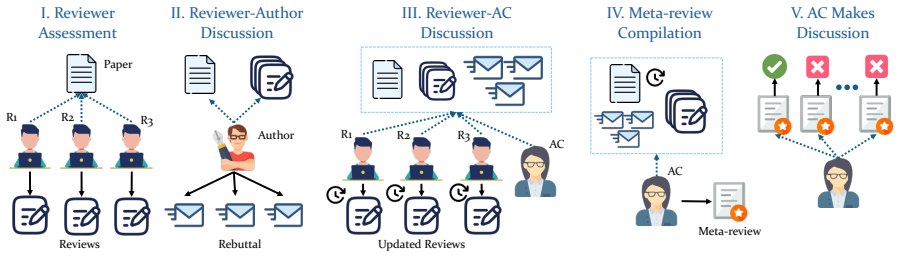
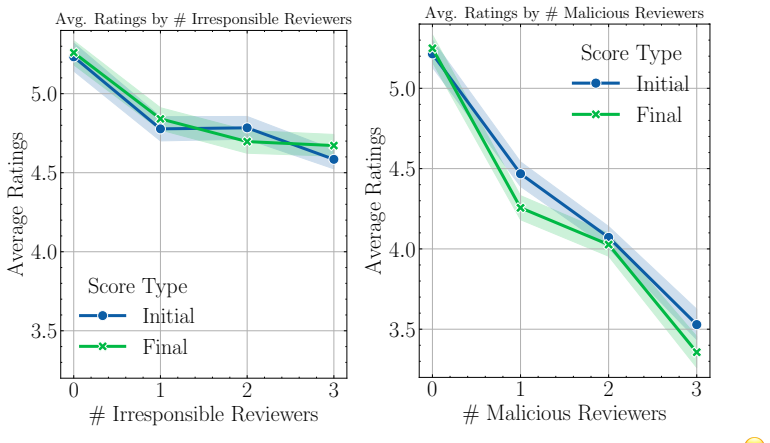
AgentReview is the first large language model based peer review simulation framework, which effectively disentangles the impacts of multiple latent factors and addresses the privacy issue. The study reveals a notable 37.1% variation in paper decisions due to reviewers' biases, supported by sociological theories such as the social influence theory, altruism fatigue, and authority bias.
What carries the argument
The AgentReview framework, which uses LLM agents to model individual reviewer behaviors and simulate the separate effects of latent factors including biases.
Load-bearing premise
Large language model agents can faithfully reproduce the multivariate biases and decision rules that drive real human reviewers without introducing simulation-specific artifacts.
What would settle it
A direct comparison of decision distributions produced by the AgentReview simulation against decision distributions from a large corpus of actual human peer reviews on identical papers.
Figures
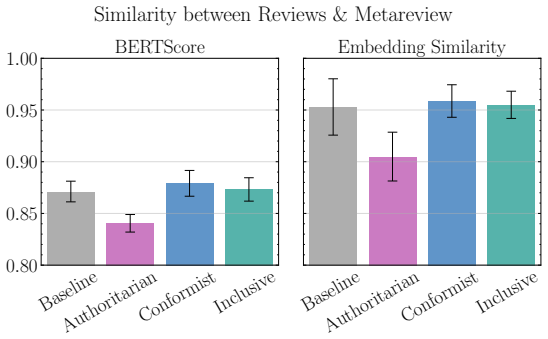
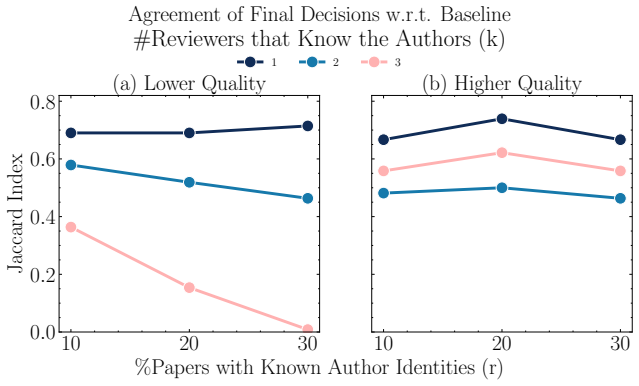
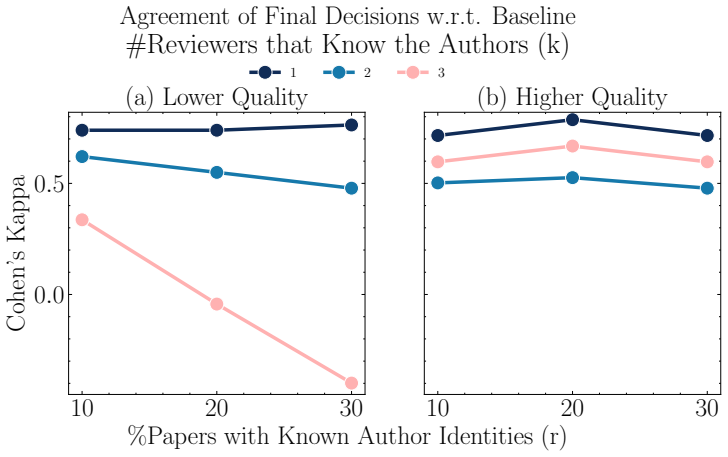

read the original abstract
Peer review is fundamental to the integrity and advancement of scientific publication. Traditional methods of peer review analyses often rely on exploration and statistics of existing peer review data, which do not adequately address the multivariate nature of the process, account for the latent variables, and are further constrained by privacy concerns due to the sensitive nature of the data. We introduce AgentReview, the first large language model (LLM) based peer review simulation framework, which effectively disentangles the impacts of multiple latent factors and addresses the privacy issue. Our study reveals significant insights, including a notable 37.1% variation in paper decisions due to reviewers' biases, supported by sociological theories such as the social influence theory, altruism fatigue, and authority bias. We believe that this study could offer valuable insights to improve the design of peer review mechanisms. Our code is available at https://github.com/Ahren09/AgentReview.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AgentReview, the first LLM-based peer review simulation framework intended to disentangle the effects of multiple latent factors (including reviewer biases) on peer review outcomes while circumventing privacy constraints of real data. It reports a central quantitative finding of 37.1% variation in paper decisions attributable to biases, interpreted through sociological theories such as social influence theory, altruism fatigue, and authority bias, and releases code for the simulation.
Significance. If the simulation were shown to reproduce human peer-review statistics, the framework could enable controlled study of bias mechanisms and mechanism design without access to sensitive data; the open code is a strength for potential reproducibility. At present the quantitative claims rest on unvalidated agent behavior, limiting immediate applicability.
major comments (3)
- [Abstract] Abstract: the headline claim of a 'notable 37.1% variation in paper decisions due to reviewers' biases' is presented without any description of the computation (e.g., how decision variation was aggregated across agent runs, what baseline was subtracted, or whether error bars or sensitivity checks were performed).
- [Abstract] Abstract: the assertion that AgentReview 'effectively disentangles' the impacts of latent factors (social influence, altruism fatigue, authority bias) is unsupported by any reported calibration, mapping to real inter-rater agreement statistics, ablation against prompt-only controls, or comparison to observed human bias magnitudes from peer-review datasets.
- [Abstract] Abstract: the central modeling assumption that LLM agents can faithfully isolate and replicate the multivariate latent factors driving human reviewers is stated without evidence that the simulation outputs match empirical distributions rather than prompt-induced artifacts.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive comments. We agree that the abstract requires greater transparency regarding the 37.1% figure, the meaning of 'disentangles,' and the modeling assumptions. We have revised the abstract accordingly and provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of a 'notable 37.1% variation in paper decisions due to reviewers' biases' is presented without any description of the computation (e.g., how decision variation was aggregated across agent runs, what baseline was subtracted, or whether error bars or sensitivity checks were performed).
Authors: We agree the abstract omitted methodological detail. The 37.1% is the mean absolute difference in final accept/reject decisions between bias-enabled and no-bias control simulations, aggregated across 1,000 independent agent runs per paper; a no-bias baseline is subtracted and standard deviations are reported in Section 4. We have added a one-sentence description of this procedure and a reference to the results section in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the assertion that AgentReview 'effectively disentangles' the impacts of latent factors (social influence, altruism fatigue, authority bias) is unsupported by any reported calibration, mapping to real inter-rater agreement statistics, ablation against prompt-only controls, or comparison to observed human bias magnitudes from peer-review datasets.
Authors: The phrasing 'effectively disentangles' was intended to describe the controlled simulation design that permits independent activation of each factor. We accept that this wording implies stronger validation than is provided. The manuscript contains factor ablations but no direct mapping to human inter-rater statistics, which is precluded by privacy constraints on real review data. We have replaced the phrase with 'simulates the isolated effects of' and added an explicit limitations clause in the abstract. revision: yes
-
Referee: [Abstract] Abstract: the central modeling assumption that LLM agents can faithfully isolate and replicate the multivariate latent factors driving human reviewers is stated without evidence that the simulation outputs match empirical distributions rather than prompt-induced artifacts.
Authors: We acknowledge that the abstract presents the modeling assumption without accompanying evidence or caveats. The full paper reports consistency checks and prompt ablations, yet these do not constitute a match to empirical human distributions. We have inserted a brief acknowledgment of the assumption and a pointer to the limitations section discussing potential prompt artifacts. revision: partial
Circularity Check
No circularity: simulation outputs treated as independent evidence
full rationale
The paper introduces an LLM-agent simulation framework to explore peer-review dynamics and reports a 37.1% decision variation attributable to biases. This figure is generated by running the forward simulation under different bias conditions rather than by fitting parameters to the simulation's own outputs or by any self-referential definition. No equations, uniqueness theorems, or self-citations are shown that would reduce the reported statistic to a tuned input or to prior work by the same authors. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can be configured to exhibit independent reviewer behaviors that mirror human latent variables such as bias and social influence.
Forward citations
Cited by 1 Pith paper
-
When AI reviews science: Can we trust the referee?
AI peer review systems are vulnerable to prompt injections, prestige biases, assertion strength effects, and contextual poisoning, as demonstrated by a new attack taxonomy and causal experiments on real conference sub...
Reference graph
Works this paper leans on
-
[1]
Ivan Stelmakh, Nihar B Shah, Aarti Singh, and Hal Daumé III. Prior and prejudice: The novice reviewers’ bias against resubmissions in conference peer review.HCI, 5(CSCW1):1–17, 2021
work page 2021
-
[2]
Investigating fairness disparities in peer review: A language model enhanced approach
Jiayao Zhang, Hongming Zhang, Zhun Deng, and Dan Roth. Investigating fairness disparities in peer review: A language model enhanced approach. arXiv:2211.06398, 2022
-
[3]
Double-blind peer review affects reviewer ratings and editor decisions at an ecology journal
Charles W Fox, Jennifer Meyer, and Emilie Aimé. Double-blind peer review affects reviewer ratings and editor decisions at an ecology journal. Functional Ecology, 37(5):1144–1157, 2023
work page 2023
-
[4]
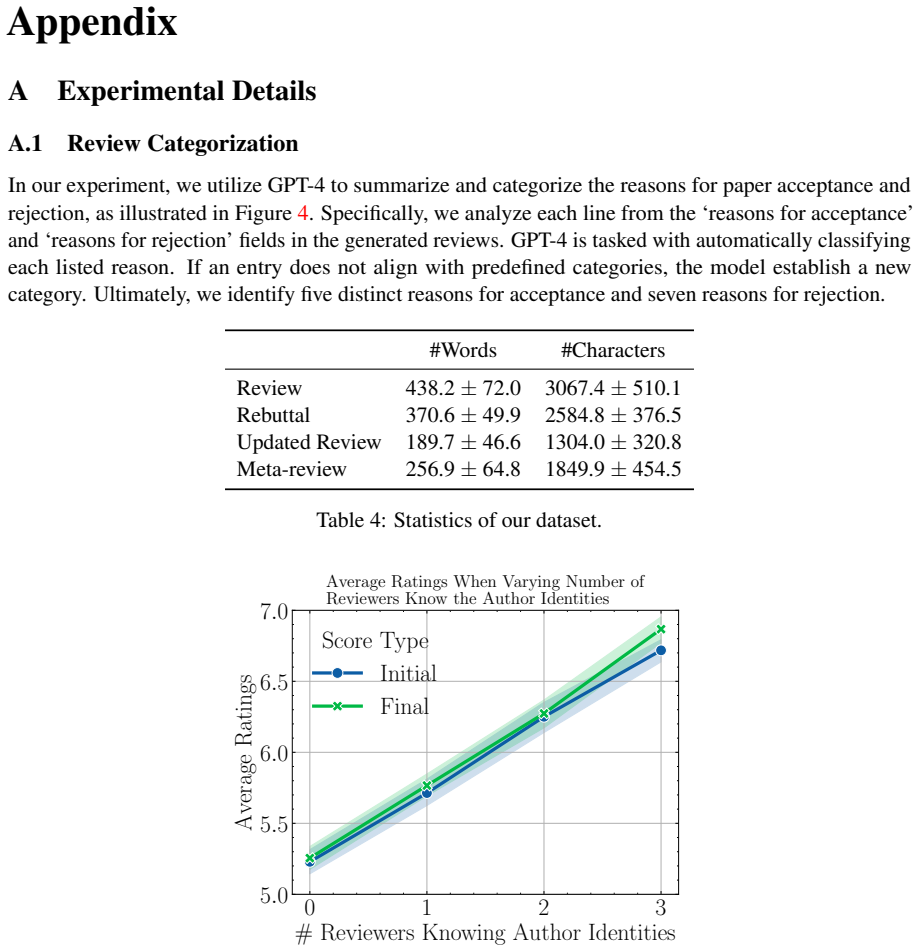
Does double-blind peer review reduce bias? evidence from a top computer science conference
Mengyi Sun, Jainabou Barry Danfa, and Misha Teplitskiy. Does double-blind peer review reduce bias? evidence from a top computer science conference. Journal of the Association for Information Science and Technology, 73(6):811–819, 2022
work page 2022
-
[5]
Yuxuan Lu and Yuqing Kong. Calibrating “cheap signals” in peer review without a prior.NeurIPS, 36, 2024
work page 2024
-
[6]
A one-size-fits-all approach to improving randomness in paper assignment
Yixuan Xu, Steven Jecmen, Zimeng Song, and Fei Fang. A one-size-fits-all approach to improving randomness in paper assignment. NeurIPS, 36, 2024
work page 2024
-
[7]
The shackles of peer review: Unveiling the flaws in the ivory tower
Ying Liu, Kaiqi Yang, Yue Liu, and Michael GB Drew. The shackles of peer review: Unveiling the flaws in the ivory tower. arXiv:2310.05966, 2023
-
[8]
OpenAI. Gpt-4 technical report. Arxiv Preprint, arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Significant-Gravitas. Autogpt. https://github.com/Significant-Gravitas/ AutoGPT, 2023
work page 2023
-
[11]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. Autogen: Enabling next-gen llm applications via multi- agent conversation framework. arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Chatarena: Multi-agent language game environments for large language models
Yuxiang Wu, Zhengyao Jiang, Akbir Khan, Yao Fu, Laura Ruis, Edward Grefenstette, and Tim Rocktäschel. Chatarena: Multi-agent language game environments for large language models. GitHub repository, 2023
work page 2023
-
[13]
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, et al. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. In ICLR, 2023
work page 2023
-
[14]
Competeai: Understanding the competition behaviors in large language model-based agents
Qinlin Zhao, Jindong Wang, Yixuan Zhang, Yiqiao Jin, Kaijie Zhu, Hao Chen, and Xing Xie. Competeai: Understanding the competition behaviors in large language model-based agents. In ICML, 2024
work page 2024
-
[15]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. In UIST, pages 1–22, 2023
work page 2023
-
[16]
Prd: Peer rank and discussion improve large language model based evaluations
Ruosen Li, Teerth Patel, and Xinya Du. Prd: Peer rank and discussion improve large language model based evaluations. arXiv preprint arXiv:2307.02762, 2023
-
[17]
Unveiling the sentinels: Assessing ai performance in cybersecurity peer review
Liang Niu, Nian Xue, and Christina Pöpper. Unveiling the sentinels: Assessing ai performance in cybersecurity peer review. arXiv:2309.05457, 2023. 12
-
[18]
Weixin Liang, Yuhui Zhang, Hancheng Cao, Binglu Wang, Daisy Ding, Xinyu Yang, Kailas V odrahalli, Siyu He, Daniel Smith, Yian Yin, et al. Can large language models provide useful feedback on research papers? a large-scale empirical analysis. arXiv:2310.01783, 2023
-
[19]
A fair and free prompt-based research assistant
Mahsa Shamsabadi and Jennifer D’Souza. A fair and free prompt-based research assistant. arXiv:2405.14601, 2024
-
[20]
Exploring multi-document information consolidation for scientific sentiment summarization
Miao Li, Jey Han Lau, and Eduard Hovy. Exploring multi-document information consolidation for scientific sentiment summarization. arXiv:2402.18005, 2024
-
[21]
Marg: Multi-agent review generation for scientific papers
Mike D’Arcy, Tom Hope, Larry Birnbaum, and Doug Downey. Marg: Multi-agent review generation for scientific papers. arXiv:2401.04259, 2024
-
[22]
John C Turner. Social influence. Thomson Brooks/Cole Publishing Co, 1991
work page 1991
-
[23]
Joshua D Angrist. The perils of peer effects. Labour Economics, 30:98–108, 2014
work page 2014
-
[24]
Irving L Janis. Groupthink. IEEE Engineering Management Review, 36(1):36, 2008
work page 2008
-
[25]
The echo chamber effect on social media
Matteo Cinelli, Gianmarco De Francisci Morales, Alessandro Galeazzi, Walter Quattrociocchi, and Michele Starnini. The echo chamber effect on social media. PNAS, 118(9):e2023301118, 2021
work page 2021
-
[26]
The halo effect: Evidence for unconscious alteration of judgments
Richard E Nisbett and Timothy D Wilson. The halo effect: Evidence for unconscious alteration of judgments. Journal of personality and social psychology, 35(4):250, 1977
work page 1977
-
[27]
Anchoring bias affects mental model formation and user reliance in explainable ai systems
Mahsan Nourani, Chiradeep Roy, Jeremy E Block, Donald R Honeycutt, Tahrima Rahman, Eric Ragan, and Vibhav Gogate. Anchoring bias affects mental model formation and user reliance in explainable ai systems. In IUI, pages 340–350, 2021
work page 2021
-
[28]
Inconsistency in conference peer review: revisiting the 2014 neurips experiment
Corinna Cortes and Neil D Lawrence. Inconsistency in conference peer review: revisiting the 2014 neurips experiment. arXiv:2109.09774, 2021
-
[29]
Social influence: Compliance and conformity
Robert B Cialdini and Noah J Goldstein. Social influence: Compliance and conformity. Annu. Rev. Psychol., 55:591–621, 2004
work page 2004
-
[30]
Guangyao Zhang, Furong Shang, Weixi Xie, Yuhan Guo, Chunlin Jiang, and Xianwen Wang. Do conspicuous manuscripts experience shorter time in the duration of peer review? arXiv:2112.09360, 2021
-
[31]
Otomar J Bartos and Paul Wehr. Using conflict theory. Cambridge University Press, 2002
work page 2002
-
[32]
Counterfactual evaluation of peer-review assignment policies
Martin Saveski, Steven Jecmen, Nihar Shah, and Johan Ugander. Counterfactual evaluation of peer-review assignment policies. NeurIPS, 36, 2024
work page 2024
-
[33]
Bertscore: Evaluat- ing text generation with bert
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluat- ing text generation with bert. In ICLR, 2020
work page 2020
-
[34]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In EMNLP, pages 3982–3992, 2019
work page 2019
-
[35]
Estimating the causal effect of early arxiving on paper acceptance
Yanai Elazar, Jiayao Zhang, David Wadden, Bo Zhang, and Noah A Smith. Estimating the causal effect of early arxiving on paper acceptance. In CLeaR, pages 913–933. PMLR, 2024
work page 2024
-
[36]
A system-level analysis of conference peer review
Yichi Zhang, Fang-Yi Yu, Grant Schoenebeck, and David Kempe. A system-level analysis of conference peer review. In EC, pages 1041–1080, 2022
work page 2022
-
[37]
Peer prediction for peer review: designing a marketplace for ideas
Alexander Ugarov. Peer prediction for peer review: designing a marketplace for ideas. arXiv:2303.16855, 2023. 13
-
[38]
Chatgpt identifies gender disparities in scientific peer review
Jeroen PH Verharen. Chatgpt identifies gender disparities in scientific peer review. Elife, 12:RP90230, 2023
work page 2023
-
[39]
Safeguarding scientific integrity: Examining conflicts of interest in the peer review process
Leslie D McIntosh and Cynthia Hudson Vitale. Safeguarding scientific integrity: Examining conflicts of interest in the peer review process. arXiv:2308.04297, 2023
-
[40]
Dimity Stephen. Distinguishing articles in questionable and non-questionable journals using quantitative indicators associated with quality. arXiv:2405.06308, 2024
-
[41]
Reviewer assignment problem: A scoping review
Jelena Jovanovic and Ebrahim Bagheri. Reviewer assignment problem: A scoping review. arXiv:2305.07887, 2023
-
[42]
Artificial intelligence to support publishing and peer review: A summary and review
Kayvan Kousha and Mike Thelwall. Artificial intelligence to support publishing and peer review: A summary and review. Learned Publishing, 37(1):4–12, 2024
work page 2024
-
[43]
Junjie Huang, Win-bin Huang, Yi Bu, Qi Cao, Huawei Shen, and Xueqi Cheng. What makes a successful rebuttal in computer science conferences?: A perspective on social interaction. Journal of Informetrics, 17(3):101427, 2023
work page 2023
-
[44]
Introducing the next generation of claude, 2024
Anthropic. Introducing the next generation of claude, 2024
work page 2024
-
[45]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Dynamic evaluation of large language models by meta probing agents
Kaijie Zhu, Jindong Wang, Qinlin Zhao, Ruochen Xu, and Xing Xie. Dynamic evaluation of large language models by meta probing agents. In ICML, 2024
work page 2024
-
[47]
Better to ask in english: Cross-lingual evaluation of large language models for healthcare queries
Yiqiao Jin, Mohit Chandra, Gaurav Verma, Yibo Hu, Munmun De Choudhury, and Srijan Kumar. Better to ask in english: Cross-lingual evaluation of large language models for healthcare queries. In Web Conference, 2024
work page 2024
-
[48]
Mm-soc: Benchmarking multimodal large language models in social media platforms
Yiqiao Jin, Minje Choi, Gaurav Verma, Jindong Wang, and Srijan Kumar. Mm-soc: Benchmarking multimodal large language models in social media platforms. In ACL, 2024
work page 2024
-
[49]
Weiqi Wang and Yangqiu Song. Mars: Benchmarking the metaphysical reasoning abilities of language models with a multi-task evaluation dataset, 2024
work page 2024
-
[50]
scelmo: Embeddings from language models are good learners for single-cell data analysis
Tianyu Liu, Tianqi Chen, Wangjie Zheng, Xiao Luo, and Hongyu Zhao. scelmo: Embeddings from language models are good learners for single-cell data analysis. bioRxiv, pages 2023–12, 2023
work page 2023
-
[51]
Haoran Wang and Kai Shu. Backdoor activation attack: Attack large language models using activation steering for safety-alignment. arXiv:2311.09433, 2023
-
[52]
Large language models can be good privacy protection learners
Yijia Xiao, Yiqiao Jin, Yushi Bai, Yue Wu, Xianjun Yang, Xiao Luo, Wenchao Yu, Xujiang Zhao, Yanchi Liu, Haifeng Chen, et al. Large language models can be good privacy protection learners. In EMNLP, 2024
work page 2024
-
[53]
Proto- typical reward network for data-efficient rlhf
Jinghan Zhang, Xiting Wang, Yiqiao Jin, Changyu Chen, Xinhao Zhang, and Kunpeng Liu. Proto- typical reward network for data-efficient rlhf. In ACL, 2024
work page 2024
-
[54]
Disentangling logic: The role of context in large language model reasoning capabilities
Wenyue Hua, Kaijie Zhu, Lingyao Li, Lizhou Fan, Shuhang Lin, Mingyu Jin, Haochen Xue, Zelong Li, JinDong Wang, and Yongfeng Zhang. Disentangling logic: The role of context in large language model reasoning capabilities. arXiv preprint arXiv:2406.02787, 2024
-
[55]
Dyval 2: Dynamic evaluation of large language models by meta probing agents
Kaijie Zhu, Jindong Wang, Qinlin Zhao, Ruochen Xu, and Xing Xie. Dyval 2: Dynamic evaluation of large language models by meta probing agents. arXiv:2402.14865, 2024. 14
-
[56]
Nphardeval4v: A dynamic reasoning benchmark of multimodal large language models
Lizhou Fan, Wenyue Hua, Xiang Li, Kaijie Zhu, Mingyu Jin, Lingyao Li, Haoyang Ling, Jinkui Chi, Jindong Wang, Xin Ma, et al. Nphardeval4v: A dynamic reasoning benchmark of multimodal large language models. arXiv:2403.01777, 2024
-
[57]
Semi-offline reinforcement learning for optimized text generation
Changyu Chen, Xiting Wang, Yiqiao Jin, Victor Ye Dong, Li Dong, Jie Cao, Yi Liu, and Rui Yan. Semi-offline reinforcement learning for optimized text generation. In ICML, 2023
work page 2023
-
[58]
Benchmarking foundation models with language-model-as-an-examiner
Yushi Bai, Jiahao Ying, Yixin Cao, Xin Lv, Yuze He, Xiaozhi Wang, Jifan Yu, Kaisheng Zeng, Yijia Xiao, Haozhe Lyu, et al. Benchmarking foundation models with language-model-as-an-examiner. arXiv:2306.04181, 2023
-
[59]
Can large language model agents simulate human trust behaviors? arXiv:2402.04559, 2024
Chengxing Xie, Canyu Chen, Feiran Jia, Ziyu Ye, Kai Shu, Adel Bibi, Ziniu Hu, Philip Torr, Bernard Ghanem, and Guohao Li. Can large language model agents simulate human trust behaviors? arXiv:2402.04559, 2024
-
[60]
Lumos: Learning Agents with Unified Data, Modular Design, and Open-Source LLMs
Da Yin, Faeze Brahman, Abhilasha Ravichander, Khyathi Chandu, Kai-Wei Chang, Yejin Choi, and Bill Yuchen Lin. Lumos: Learning Agents with Unified Data, Modular Design, and Open-Source LLMs. arXiv:2311.05657, 2023
-
[61]
Zhaoyi Li, Kelin Yu, Shuo Cheng, and Danfei Xu. League++: Empowering continual robot learning through guided skill acquisition with large language models. In ICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024
work page 2024
-
[62]
Alpacaeval: An automatic evaluator of instruction-following models, 2023
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models, 2023
work page 2023
-
[63]
Chateval: Towards better llm-based evaluators through multi-agent debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. In ICLR, 2023
work page 2023
-
[64]
Surveying (dis) parities and concerns of compute hungry nlp research
Ji-Ung Lee, Haritz Puerto, Betty van Aken, Yuki Arase, Jessica Zosa Forde, Leon Derczynski, Andreas Rücklé, Iryna Gurevych, Roy Schwartz, Emma Strubell, et al. Surveying (dis) parities and concerns of compute hungry nlp research. arXiv:2306.16900, 2023
-
[65]
Weixin Liang, Zachary Izzo, Yaohui Zhang, Haley Lepp, Hancheng Cao, Xuandong Zhao, Lingjiao Chen, Haotian Ye, Sheng Liu, Zhi Huang, et al. Monitoring ai-modified content at scale: A case study on the impact of chatgpt on ai conference peer reviews. arXiv:2403.07183, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[66]
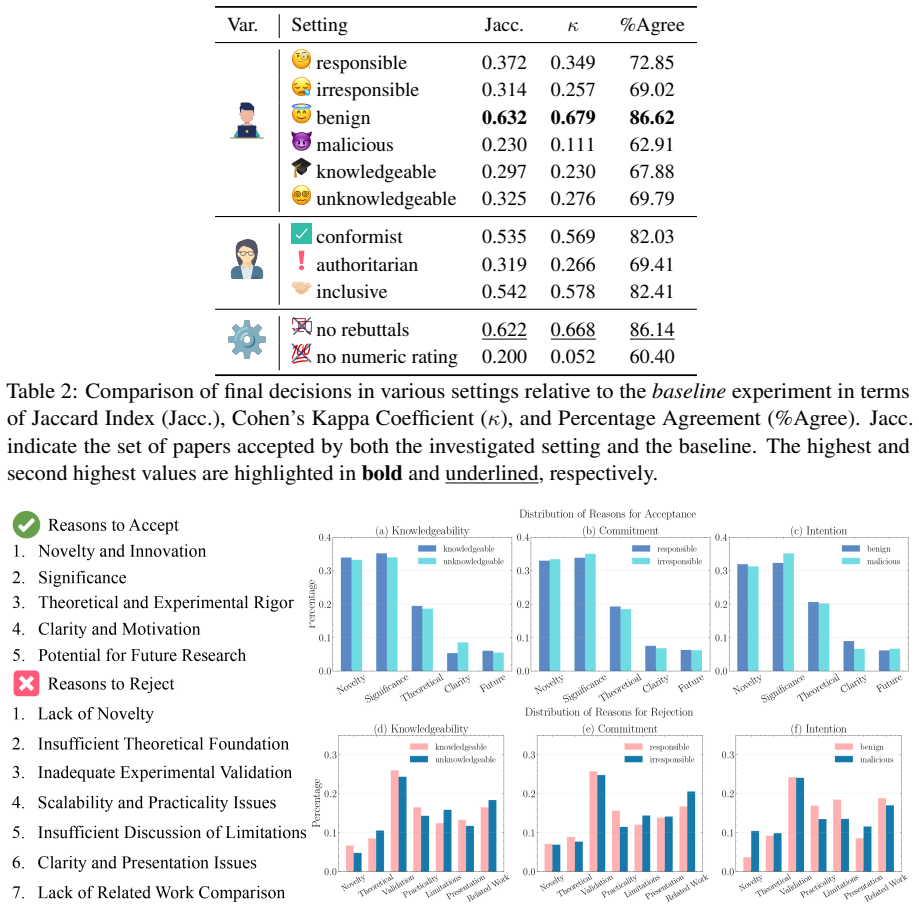
Xu Ma, Yuqian Zhou, Huan Wang, Can Qin, Bin Sun, Chang Liu, and Yun Fu. Image as set of points. In ICLR, 2022. 15 Appendix A Experimental Details A.1 Review Categorization In our experiment, we utilize GPT-4 to summarize and categorize the reasons for paper acceptance and rejection, as illustrated in Figure 4. Specifically, we analyze each line from the ‘...
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.