LLMs on the Line: Data Determines Loss-to-Loss Scaling Laws
Pith reviewed 2026-05-23 02:45 UTC · model grok-4.3
The pith
Pretraining data determines loss-to-loss scaling trends in LLMs, overriding model size, architecture, and training choices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
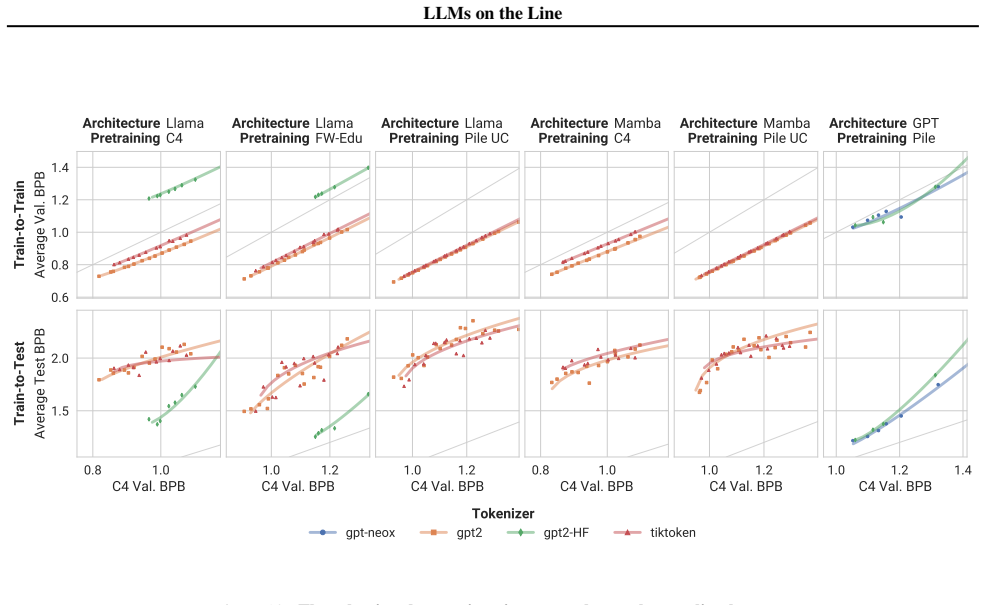
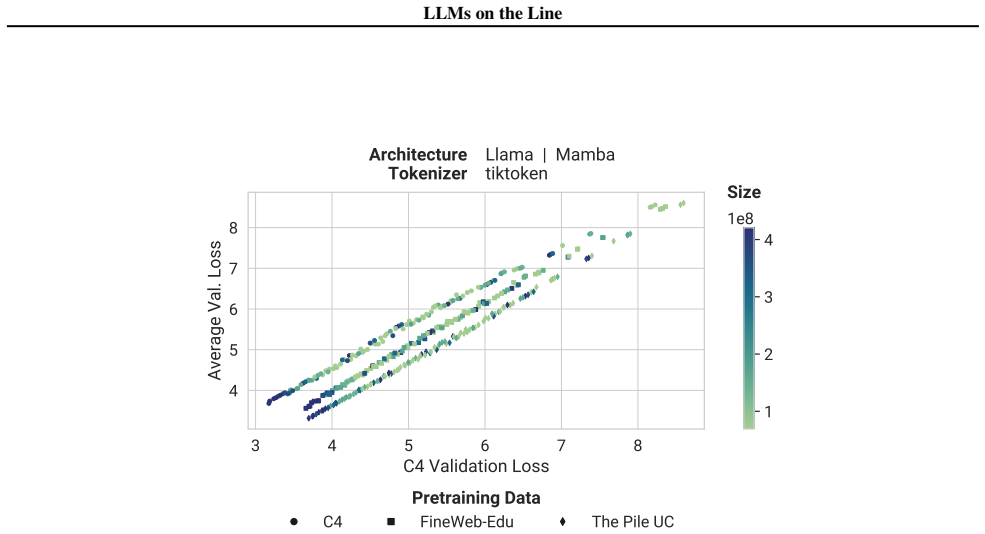
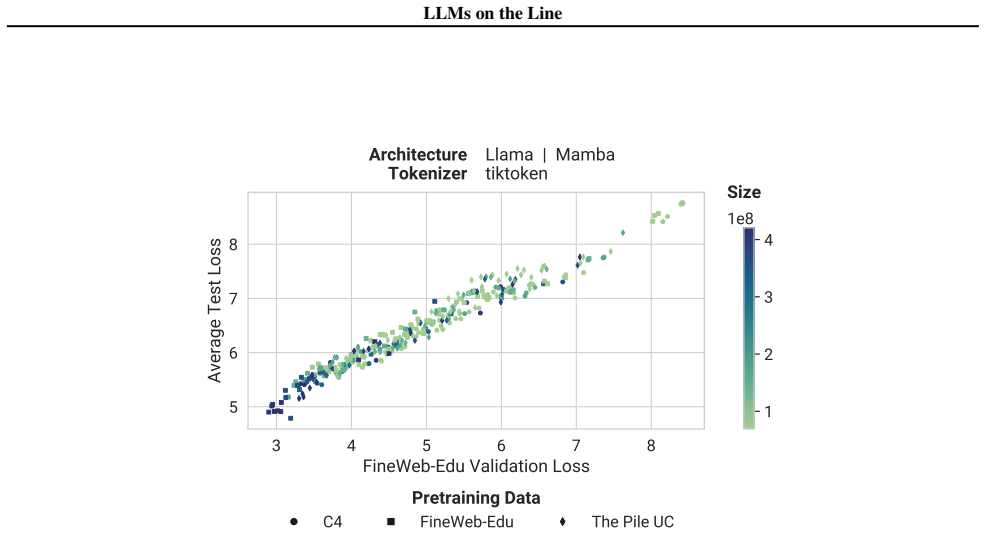
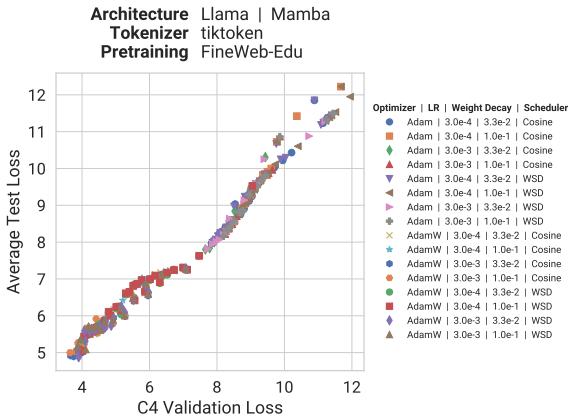
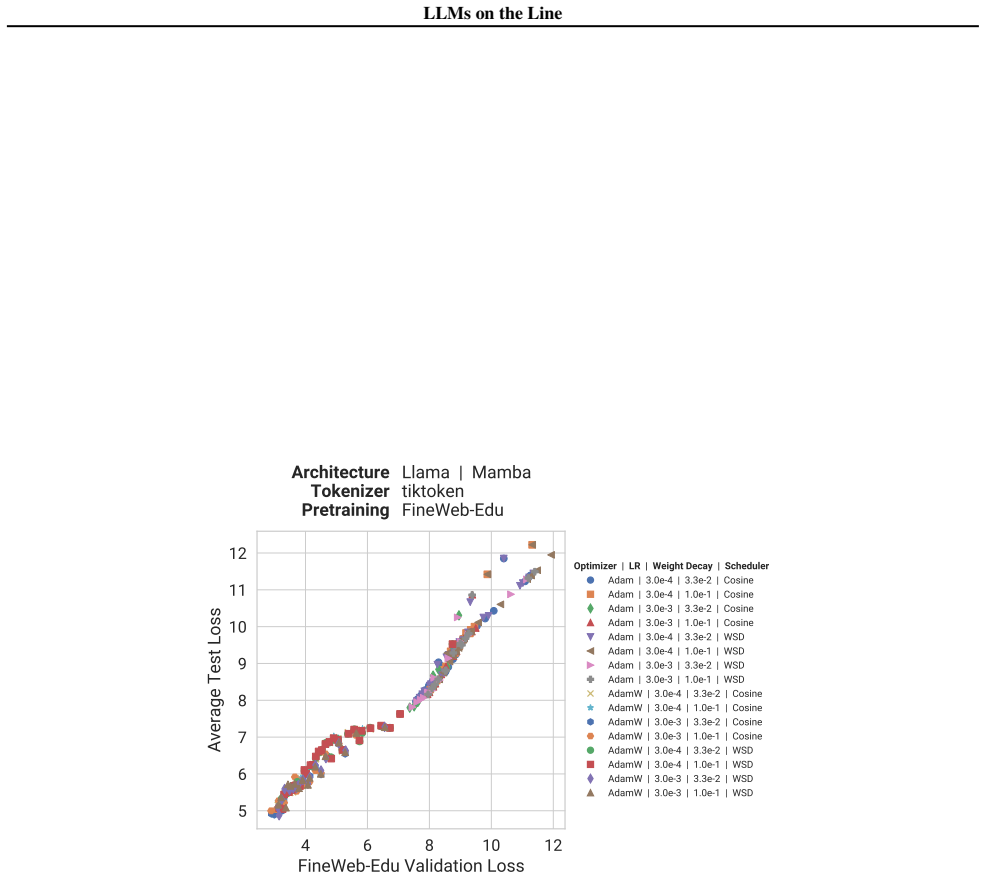
Our experiments reveal that the pretraining data determines the scaling trend. In contrast, model size, optimization hyperparameters, tokenizer and even significant architectural differences, such as between transformer-based models like Llama and state-space models like Mamba, generally have limited impact.
What carries the argument
Loss-to-loss scaling laws relating pretraining loss to downstream task performance, with pretraining data as the primary controlling factor.
If this is right
- Practitioners should prioritize curating pretraining datasets to achieve desired downstream scaling behavior.
- Model architectures and optimization settings can be chosen mainly for training speed and cost without changing the expected loss-to-loss relationship.
- Scaling predictions for new tasks can be based primarily on the pretraining data used rather than the specific model details.
- Different model families will exhibit similar scaling behavior when trained on the same data.
Where Pith is reading between the lines
- Data curation may become the main lever for controlling generalization patterns across many future model designs.
- The result suggests testing whether particular data properties, such as domain coverage or token statistics, are what actually fix the scaling line.
- If data dominates, then methods that alter effective training data during pretraining could be used to steer downstream scaling without retraining from scratch.
Load-bearing premise
The range of models, data sources, and tasks tested is representative enough for the data-dominance conclusion to apply beyond these specific cases.
What would settle it
A clear case where two models with different architectures or sizes, trained on identical pretraining data, produce substantially different loss-to-loss scaling slopes on the same downstream tasks.
Figures




























read the original abstract
Scaling laws guide the development of large language models (LLMs) by offering estimates for the optimal balance of model size, tokens, and compute. More recently, loss-to-loss scaling laws that relate losses across pretraining datasets and downstream tasks have emerged as a powerful tool for understanding and improving LLM performance and generalization. In this work, we investigate which factors most strongly influence loss-to-loss scaling. Our experiments reveal that the pretraining data determines the scaling trend. In contrast, model size, optimization hyperparameters, tokenizer and even significant architectural differences, such as between transformer-based models like Llama and state-space models like Mamba, generally have limited impact. Consequently, practitioners should carefully curate suitable pretraining datasets for optimal downstream performance, while architectures and other settings can be freely optimized for training efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates factors influencing loss-to-loss scaling laws across pretraining datasets and downstream tasks in LLMs. It claims that pretraining data is the dominant determinant of the scaling trends, while model size, optimization hyperparameters, tokenizer choice, and even major architectural differences (e.g., transformer-based Llama vs. state-space Mamba) have limited impact. The authors conclude that practitioners should prioritize data curation over other design choices for optimal downstream performance.
Significance. If the central empirical claim holds after proper controls, the result would meaningfully redirect LLM scaling research and practice toward data-centric approaches rather than architecture or hyperparameter search, with direct implications for training efficiency and generalization. The work builds on recent loss-to-loss scaling literature by attempting to isolate the dominant variable through comparative experiments.
major comments (2)
- [Experiments / Results] Experimental comparisons (likely §4 or §5): the claim that architecture has limited impact (including Llama vs. Mamba) requires Llama and Mamba models to be pretrained on identical data distributions; if the runs used different corpora, observed scaling differences are confounded by data rather than architecture, directly undermining the isolation of data as the sole determinant.
- [Methods] Methods and experimental design (likely §3): the manuscript provides no details on controls for data overlap, statistical significance testing, data exclusion criteria, or variance across runs, leaving the support for the central claim that 'data determines the scaling trend' difficult to evaluate and potentially non-generalizable.
minor comments (2)
- [Introduction] Notation for loss-to-loss relations could be clarified with an explicit equation early in the paper to avoid ambiguity when comparing across sections.
- [Figures] Figure captions should explicitly state the exact model/data pairs shown to allow readers to verify the architecture-controlled comparisons.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point-by-point below, agreeing where controls or details are needed and committing to revisions that strengthen the manuscript without altering its central claims.
read point-by-point responses
-
Referee: [Experiments / Results] Experimental comparisons (likely §4 or §5): the claim that architecture has limited impact (including Llama vs. Mamba) requires Llama and Mamba models to be pretrained on identical data distributions; if the runs used different corpora, observed scaling differences are confounded by data rather than architecture, directly undermining the isolation of data as the sole determinant.
Authors: We agree that identical pretraining data distributions are required to isolate architecture. In our experiments, Llama and Mamba models were pretrained on the same data distributions precisely to avoid this confound; the observed similarity in loss-to-loss scaling is therefore attributable to architecture rather than data. We will revise §4 to explicitly state this control, describe the data-matching procedure, and include supporting details on the shared corpora. revision: yes
-
Referee: [Methods] Methods and experimental design (likely §3): the manuscript provides no details on controls for data overlap, statistical significance testing, data exclusion criteria, or variance across runs, leaving the support for the central claim that 'data determines the scaling trend' difficult to evaluate and potentially non-generalizable.
Authors: We acknowledge the absence of these methodological details in the current version. The revised manuscript will add a dedicated subsection in §3 covering: (i) controls and checks for data overlap between pretraining and downstream sets, (ii) the statistical significance tests applied to scaling trends, (iii) explicit data exclusion criteria, and (iv) reported variance or standard errors across multiple independent runs. These additions will make the support for the data-dominance claim fully evaluable. revision: yes
Circularity Check
Empirical comparisons with no circular derivation chain
full rationale
The paper reports experimental results on loss-to-loss scaling across varied pretraining data, model sizes, optimizers, tokenizers, and architectures (Llama vs. Mamba). No equations, fitted parameters, or first-principles derivations are presented that reduce to their own inputs by construction. The central claim rests on direct empirical contrasts rather than self-definitional relations, renamed known results, or load-bearing self-citations. The study is self-contained against external benchmarks via replication of the reported training runs and loss measurements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Exploring the landscape of distributional robustness for question answering models, 2022
Awadalla, A., Wortsman, M., Ilharco, G., Min, S., Magnusson, I., Hajishirzi, H., and Schmidt, L. Exploring the landscape of distributional robustness for question answering models, 2022. URL https://arxiv.org/abs/2210.12517
-
[2]
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Biderman, S., Schoelkopf, H., Anthony, Q., Bradley, H., O'Brien, K., Hallahan, E., Khan, M. A., Purohit, S., Prashanth, U. S., Raff, E., Skowron, A., Sutawika, L., and van der Wal, O. Pythia: A suite for analyzing large language models across training and scaling, 2023. URL https://arxiv.org/abs/2304.01373
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
PIQA: Reasoning about Physical Commonsense in Natural Language
Bisk, Y., Zellers, R., Bras, R. L., Gao, J., and Choi, Y. Piqa: Reasoning about physical commonsense in natural language, 2019. URL https://arxiv.org/abs/1911.11641
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[4]
Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow
Black, S., Gao, L., Wang, P., Leahy, C., and Biderman, S. Gpt-neo: Large scale autoregressive language modeling with mesh-tensorflow. 2021. URL https://api.semanticscholar.org/CorpusID:245758737
work page 2021
-
[5]
GPT-NeoX-20B: An Open-Source Autoregressive Language Model
Black, S., Biderman, S., Hallahan, E., Anthony, Q., Gao, L., Golding, L., He, H., Leahy, C., McDonell, K., Phang, J., Pieler, M., Prashanth, U. S., Purohit, S., Reynolds, L., Tow, J., Wang, B., and Weinbach, S. Gpt-neox-20b: An open-source autoregressive language model, 2022. URL https://arxiv.org/abs/2204.06745
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[6]
Loss-to-loss prediction: Scaling laws for all datasets, 2024
Brandfonbrener, D., Anand, N., Vyas, N., Malach, E., and Kakade, S. Loss-to-loss prediction: Scaling laws for all datasets, 2024. URL https://arxiv.org/abs/2411.12925
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge, 2018. URL https://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Dao, T. and Gu, A. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality, 2024. URL https://arxiv.org/abs/2405.21060
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Documenting large webtext corpora: A case study on the colossal clean crawled corpus, 2021
Dodge, J., Sap, M., Marasović, A., Agnew, W., Ilharco, G., Groeneveld, D., Mitchell, M., and Gardner, M. Documenting large webtext corpora: A case study on the colossal clean crawled corpus, 2021. URL https://arxiv.org/abs/2104.08758
-
[10]
Understanding emergent abilities of language models from the loss perspective, 2025
Du, Z., Zeng, A., Dong, Y., and Tang, J. Understanding emergent abilities of language models from the loss perspective, 2025. URL https://arxiv.org/abs/2403.15796
-
[11]
Data determines distributional robustness in contrastive language image pre-training (clip), 2022
Fang, A., Ilharco, G., Wortsman, M., Wan, Y., Shankar, V., Dave, A., and Schmidt, L. Data determines distributional robustness in contrastive language image pre-training (clip), 2022. URL https://arxiv.org/abs/2205.01397
-
[12]
Gadre, S. Y., Smyrnis, G., Shankar, V., Gururangan, S., Wortsman, M., Shao, R., Mercat, J., Fang, A., Li, J., Keh, S., Xin, R., Nezhurina, M., Vasiljevic, I., Jitsev, J., Soldaini, L., Dimakis, A. G., Ilharco, G., Koh, P. W., Song, S., Kollar, T., Carmon, Y., Dave, A., Heckel, R., Muennighoff, N., and Schmidt, L. Language models scale reliably with over-t...
-
[13]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Gao, L., Biderman, S., Black, S., Golding, L., Hoppe, T., Foster, C., Phang, J., He, H., Thite, A., Nabeshima, N., Presser, S., and Leahy, C. The pile: An 800gb dataset of diverse text for language modeling, 2020. URL https://arxiv.org/abs/2101.00027
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[14]
Thomas Hartvigsen, Saadia Gabriel, Hamid Palangi, Maarten Sap, Dipankar Ray, and Ece Kamar
Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu, J., Noac’h, A. L., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang, J., Reynolds, L., Schoelkopf, H., Skowron, A., Sutawika, L., Tang, E., Thite, A., Wang, B., Wang, K., and Zou, A. A framework for few-shot language model evaluation, 07 2024. URL http...
-
[15]
S., Kozareva, Z., and Roemmele, M
Gordon, A. S., Kozareva, Z., and Roemmele, M. Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In AAAI Spring Symposium: Logical Formalizations of Commonsense Reasoning, 2011. URL https://api.semanticscholar.org/CorpusID:434646
work page 2011
-
[16]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., et al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
OLM o: Accelerating the science of language models
Groeneveld, D., Beltagy, I., Walsh, E., Bhagia, A., Kinney, R., Tafjord, O., Jha, A., Ivison, H., Magnusson, I., Wang, Y., Arora, S., Atkinson, D., Authur, R., Chandu, K., Cohan, A., Dumas, J., Elazar, Y., Gu, Y., Hessel, J., Khot, T., Merrill, W., Morrison, J., Muennighoff, N., Naik, A., Nam, C., Peters, M., Pyatkin, V., Ravichander, A., Schwenk, D., Sha...
-
[18]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Gu, A. and Dao, T. Mamba: Linear-time sequence modeling with selective state spaces, 2024. URL https://arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Measuring Massive Multitask Language Understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding, 2021. URL https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Hestness, J., Narang, S., Ardalani, N., Diamos, G., Jun, H., Kianinejad, H., Patwary, M. M. A., Yang, Y., and Zhou, Y. Deep learning scaling is predictable, empirically, 2017. URL https://arxiv.org/abs/1712.00409
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[21]
Training Compute-Optimal Large Language Models
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., de Las Casas, D., Hendricks, L. A., Welbl, J., Clark, A., Hennigan, T., Noland, E., Millican, K., van den Driessche, G., Damoc, B., Guy, A., Osindero, S., Simonyan, K., Elsen, E., Rae, J. W., Vinyals, O., and Sifre, L. Training compute-optimal large language models, 2022. UR...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Hu, S., Tu, Y., Han, X., He, C., Cui, G., Long, X., Zheng, Z., Fang, Y., Huang, Y., Zhao, W., Zhang, X., Thai, Z. L., Zhang, K., Wang, C., Yao, Y., Zhao, C., Zhou, J., Cai, J., Zhai, Z., Ding, N., Jia, C., Zeng, G., Li, D., Liu, Z., and Sun, M. Minicpm: Unveiling the potential of small language models with scalable training strategies, 2024. URL https://a...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Scaling laws for downstream task performance of large language models, 2024
Isik, B., Ponomareva, N., Hazimeh, H., Paparas, D., Vassilvitskii, S., and Koyejo, S. Scaling laws for downstream task performance of large language models, 2024. URL https://arxiv.org/abs/2402.04177
-
[24]
Scaling Laws for Neural Language Models
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models, 2020. URL https://arxiv.org/abs/2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [25]
-
[26]
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization, 2017. URL https://arxiv.org/abs/1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
SGDR: Stochastic Gradient Descent with Warm Restarts
Loshchilov, I. and Hutter, F. Sgdr: Stochastic gradient descent with warm restarts, 2017. URL https://arxiv.org/abs/1608.03983
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regularization, 2019. URL https://arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[29]
K., Schaeffer, R., Poulton, A., Koyejo, S., Stenetorp, P., Narang, S., and Hupkes, D
Madaan, L., Singh, A. K., Schaeffer, R., Poulton, A., Koyejo, S., Stenetorp, P., Narang, S., and Hupkes, D. Quantifying variance in evaluation benchmarks, 2024. URL https://arxiv.org/abs/2406.10229
-
[30]
Does clip's generalization performance mainly stem from high train-test similarity?, 2024 a
Mayilvahanan, P., Wiedemer, T., Rusak, E., Bethge, M., and Brendel, W. Does clip's generalization performance mainly stem from high train-test similarity?, 2024 a . URL https://arxiv.org/abs/2310.09562
-
[31]
S., Wiedemer, T., Rusak, E., Juhos, A., Bethge, M., and Brendel, W
Mayilvahanan, P., Zimmermann, R. S., Wiedemer, T., Rusak, E., Juhos, A., Bethge, M., and Brendel, W. In search of forgotten domain generalization, 2024 b . URL https://arxiv.org/abs/2410.08258
-
[32]
W., Shankar, V., Liang, P., Carmon, Y., and Schmidt, L
Miller, J., Taori, R., Raghunathan, A., Sagawa, S., Koh, P. W., Shankar, V., Liang, P., Carmon, Y., and Schmidt, L. Accuracy on the line: On the strong correlation between out-of-distribution and in-distribution generalization, 2021. URL https://arxiv.org/abs/2107.04649
-
[33]
Penedo, G., Malartic, Q., Hesslow, D., Cojocaru, R., Cappelli, A., Alobeidli, H., Pannier, B., Almazrouei, E., and Launay, J. The refinedweb dataset for falcon llm: Outperforming curated corpora with web data, and web data only, 2023. URL https://arxiv.org/abs/2306.01116
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale
Penedo, G., Kydlíček, H., allal, L. B., Lozhkov, A., Mitchell, M., Raffel, C., Werra, L. V., and Wolf, T. The fineweb datasets: Decanting the web for the finest text data at scale, 2024. URL https://arxiv.org/abs/2406.17557
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Resolving discrepancies in compute-optimal scaling of language models, 2025
Porian, T., Wortsman, M., Jitsev, J., Schmidt, L., and Carmon, Y. Resolving discrepancies in compute-optimal scaling of language models, 2025. URL https://arxiv.org/abs/2406.19146
-
[36]
Language models are unsupervised multitask learners
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. Language models are unsupervised multitask learners. 2019. URL https://api.semanticscholar.org/CorpusID:160025533
work page 2019
- [37]
-
[38]
WinoGrande: An Adversarial Winograd Schema Challenge at Scale
Sakaguchi, K., Bras, R. L., Bhagavatula, C., and Choi, Y. Winogrande: An adversarial winograd schema challenge at scale, 2019. URL https://arxiv.org/abs/1907.10641
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[39]
SocialIQA: Commonsense Reasoning about Social Interactions
Sap, M., Rashkin, H., Chen, D., LeBras, R., and Choi, Y. Socialiqa: Commonsense reasoning about social interactions, 2019. URL https://arxiv.org/abs/1904.09728
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[40]
Saunshi, N., Karp, S., Krishnan, S., Miryoosefi, S., Reddi, S. J., and Kumar, S. On the inductive bias of stacking towards improving reasoning, 2024. URL https://arxiv.org/abs/2409.19044
-
[41]
Why has predicting downstream capabilities of frontier ai models with scale remained elusive?, 2024
Schaeffer, R., Schoelkopf, H., Miranda, B., Mukobi, G., Madan, V., Ibrahim, A., Bradley, H., Biderman, S., and Koyejo, S. Why has predicting downstream capabilities of frontier ai models with scale remained elusive?, 2024. URL https://arxiv.org/abs/2406.04391
-
[42]
Slimpajama-dc: Understanding dat a combinations for llm training
Shen, Z., Tao, T., Ma, L., Neiswanger, W., Liu, Z., Wang, H., Tan, B., Hestness, J., Vassilieva, N., Soboleva, D., and Xing, E. Slimpajama-dc: Understanding data combinations for llm training, 2024. URL https://arxiv.org/abs/2309.10818
-
[43]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Shoeybi, M., Patwary, M., Puri, R., LeGresley, P., Casper, J., and Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism, 2020. URL https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[44]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Talmor, A., Herzig, J., Lourie, N., and Berant, J. Commonsenseqa: A question answering challenge targeting commonsense knowledge, 2019. URL https://arxiv.org/abs/1811.00937
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[45]
Measuring robustness to natural distribution shifts in image classification, 2020
Taori, R., Dave, A., Shankar, V., Carlini, N., Recht, B., and Schmidt, L. Measuring robustness to natural distribution shifts in image classification, 2020. URL https://arxiv.org/abs/2007.00644
-
[46]
W., Fedus, W., Rao, J., Narang, S., Tran, V
Tay, Y., Dehghani, M., Abnar, S., Chung, H. W., Fedus, W., Rao, J., Narang, S., Tran, V. Q., Yogatama, D., and Metzler, D. Scaling laws vs model architectures: How does inductive bias influence scaling?, 2022. URL https://arxiv.org/abs/2207.10551
-
[47]
Y., Haziza, D., Wehrstedt, L., Copet, J., Teytaud, O., and Lopez-Paz, D
Videau, M., Idrissi, B. Y., Haziza, D., Wehrstedt, L., Copet, J., Teytaud, O., and Lopez-Paz, D. Meta Lingua : A minimal PyTorch LLM training library, 2024. URL https://github.com/facebookresearch/lingua
work page 2024
-
[48]
Virtanen, P., Gommers, R., Oliphant, T. E., Haberland, M., Reddy, T., Cournapeau, D., Burovski, E., Peterson, P., Weckesser, W., Bright, J., van der Walt , S. J., Brett, M., Wilson, J., Millman, K. J., Mayorov, N., Nelson, A. R. J., Jones, E., Kern, R., Larson, E., Carey, C. J., Polat, \.I ., Feng, Y., Moore, E. W., VanderPlas , J., Laxalde, D., Perktold,...
-
[49]
Wang, B. and Komatsuzaki, A. Gpt-j-6b: A 6 billion parameter autoregressive language model, 2021
work page 2021
-
[50]
Wang, S., Chen, Z., Li, B., He, K., Zhang, M., and Wang, J. Scaling laws across model architectures: A comparative analysis of dense and moe models in large language models, 2024. URL https://arxiv.org/abs/2410.05661
-
[51]
Pretraining frequency predicts compositional generalization of CLIP on real-world tasks
Wiedemer, T., Sharma, Y., Prabhu, A., Bethge, M., and Brendel, W. Pretraining frequency predicts compositional generalization of CLIP on real-world tasks. In NeurIPS 2024 Workshop on Compositional Learning: Perspectives, Methods, and Paths Forward, 2024. URL https://openreview.net/forum?id=NDXoM1wYgl
work page 2024
-
[52]
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Wolf, T., Debut, L., Sanh, V., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., Davison, J., Shleifer, S., von Platen, P., Ma, C., Jernite, Y., Plu, J., Xu, C., Scao, T. L., Gugger, S., Drame, M., Lhoest, Q., and Rush, A. M. Huggingface's transformers: State-of-the-art natural language processing, 2020. URL https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[53]
HellaSwag: Can a Machine Really Finish Your Sentence?
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. Hellaswag: Can a machine really finish your sentence?, 2019. URL https://arxiv.org/abs/1905.07830
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[54]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.