SALSA-RL: Stability Analysis in the Latent Space of Actions for Reinforcement Learning
Pith reviewed 2026-05-23 02:37 UTC · model grok-4.3
The pith
A latent space model of actions lets RL agents forecast local instability before execution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SALSA-RL models control actions as dynamic time-dependent variables in a latent space by means of a pre-trained encoder-decoder and a state-dependent linear system. This construction permits local stability analysis that predicts instantaneous growth in action-norms before the actions are executed. The framework can be deployed non-invasively to assess the local stability of actions generated by pretrained RL agents while leaving their performance unchanged across diverse benchmark environments.
What carries the argument
A pre-trained encoder-decoder combined with a state-dependent linear system that models the evolution of actions in latent space.
If this is right
- Instantaneous growth in action-norms can be predicted before execution.
- The analysis applies to pretrained agents in a non-invasive way.
- Performance on benchmark environments stays the same.
- It advances interpretability for the design and analysis of RL systems.
Where Pith is reading between the lines
- Stability predictions might be used to modify or filter actions in real time for safer control.
- Similar latent linear models could apply to other sequential decision problems beyond RL.
- One could test whether the linear approximation holds over longer time horizons than the local analysis assumes.
Load-bearing premise
A pre-trained encoder-decoder and state-dependent linear system can capture the time evolution of actions well enough that local stability predictions remain meaningful.
What would settle it
Running the stability predictions on a trained agent and then observing that the predicted growth rates do not correspond to the actual changes in action norms during environment interactions.
Figures









read the original abstract
Modern deep reinforcement learning (DRL) methods have made significant advances in handling continuous action spaces. However, real-world control systems, especially those requiring precise and reliable performance, often demand interpretability in the sense of a-priori assessments of agent behavior to identify safe or failure-prone interactions with environments. To address this limitation, this work proposes SALSA-RL (Stability Analysis in the Latent Space of Actions), a novel RL framework that models control actions as dynamic, time-dependent variables evolving within a latent space. By employing a pre-trained encoder-decoder and a state-dependent linear system, this approach enables interpretability through local stability analysis, where instantaneous growth in action-norms can be predicted before their execution. It is demonstrated that SALSA-RL can be deployed in a non-invasive manner for assessing the local stability of actions from pretrained RL agents without compromising on performance across diverse benchmark environments. By enabling a more interpretable analysis of action generation, SALSA-RL provides a powerful tool for advancing the design, analysis, and theoretical understanding of RL systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SALSA-RL, a framework that models RL control actions as time-dependent variables in a latent space via a pre-trained encoder-decoder and state-dependent linear system. This enables local stability analysis to predict instantaneous growth rates of action norms before execution, providing interpretability for pretrained agents in a non-invasive way across benchmark environments without performance degradation.
Significance. If the modeling assumptions hold and the linearization faithfully captures relevant action dynamics, the method could supply a useful tool for a-priori safety assessment and interpretability in continuous-control RL. However, the manuscript supplies no empirical support for these assumptions, so the significance remains potential rather than demonstrated.
major comments (1)
- [Abstract] Abstract: the central claim that local stability predictions are meaningful requires that the pre-trained encoder-decoder and state-dependent linear system faithfully reproduce action time-evolution (small linearization error over relevant timescales and preservation of norm-growth dynamics in latent space). No reconstruction error, multi-step prediction error, or correlation between predicted and observed action-norm trajectories is reported, leaving the modeling assumption untested.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to validate the core modeling assumptions. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that local stability predictions are meaningful requires that the pre-trained encoder-decoder and state-dependent linear system faithfully reproduce action time-evolution (small linearization error over relevant timescales and preservation of norm-growth dynamics in latent space). No reconstruction error, multi-step prediction error, or correlation between predicted and observed action-norm trajectories is reported, leaving the modeling assumption untested.
Authors: We agree that the abstract does not report explicit reconstruction error, multi-step prediction error, or direct correlation metrics between predicted and observed action-norm trajectories. The current manuscript instead demonstrates non-invasive deployment on pretrained agents with no performance degradation across benchmarks, which provides indirect evidence that the latent dynamics are sufficiently faithful for the intended stability analysis. To directly address the concern, we will add a dedicated subsection (and associated figures) in the Experiments section reporting reconstruction MSE, multi-step rollout error over relevant timescales, and Pearson correlation between predicted and empirical action-norm growth rates. This will make the validation of the linearization assumptions explicit. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper constructs a modeling pipeline (pre-trained encoder-decoder plus state-dependent linear system) explicitly to enable local stability analysis of action dynamics in latent space. The claimed predictions of instantaneous action-norm growth are outputs of this fitted model rather than independent results that reduce to the inputs by definition. No self-definitional equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described framework. The central claim concerns the interpretability utility of applying stability analysis to the constructed model, which remains self-contained and externally falsifiable via reconstruction or multi-step prediction errors.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Md Ferdous Alam, Max Shtein, Kira Barton, and David J Hoelzle. A physics-guided reinforcement learning framework for an autonomous manufacturing system with expensive data. In 2021 American Control Conference (ACC), pp. 484–490. IEEE, 2021
work page 2021
-
[2]
Karl Johan ˚Astr¨om and Tore H¨agglund. Advanced PID control. ISA-The Instrumentation, Systems and Automation Society, 2006
work page 2006
-
[3]
A survey on physics informed reinforcement learning: Review and open problems
Chayan Banerjee, Kien Nguyen, Clinton Fookes, and Maziar Raissi. A survey on physics informed reinforcement learning: Review and open problems. arXiv preprint arXiv:2309.01909, 2023
-
[4]
Prototype-based models in machine learning
Michael Biehl, Barbara Hammer, and Thomas Villmann. Prototype-based models in machine learning. Wiley Interdisciplinary Reviews: Cognitive Science, 7(2):92–111, 2016
work page 2016
-
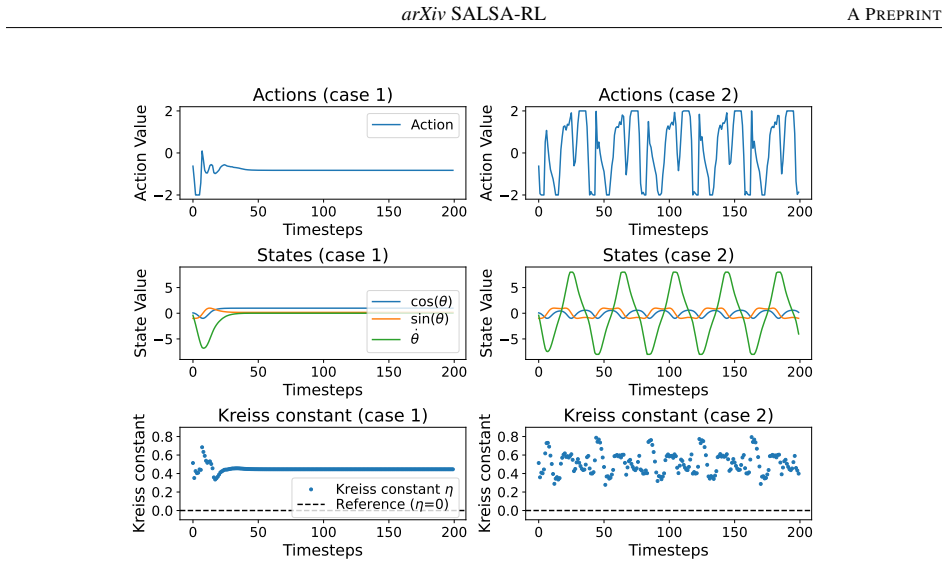
[5]
G Brockman. Openai gym. arXiv preprint arXiv:1606.01540, 2016. 12 arXiv SALSA-RL A PREPRINT
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
Safe learning in robotics: From learning-based control to safe reinforcement learning
Lukas Brunke, Melissa Greeff, Adam W Hall, Zhaocong Yuan, Siqi Zhou, Jacopo Panerati, and Angela P Schoellig. Safe learning in robotics: From learning-based control to safe reinforcement learning. Annual Review of Control, Robotics, and Autonomous Systems, 5(1):411–444, 2022
work page 2022
-
[7]
Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning
Jianyu Chen, Shengbo Eben Li, and Masayoshi Tomizuka. Interpretable end-to-end urban autonomous driving with latent deep reinforcement learning. IEEE Transactions on Intelligent Transportation Systems, 23(6):5068–5078, 2021
work page 2021
-
[8]
Physics-guided reinforcement learning for 3d molecular structures
Youngwoo Cho, Sookyung Kim, Peggy Pk Li, Mike P Surh, T Yong-Jin Han, and Jaegul Choo. Physics-guided reinforcement learning for 3d molecular structures. In Workshop at the 33rd Conference on Neural Information Processing Systems (NeurIPS), 2019
work page 2019
-
[9]
Interpretable and explainable logical policies via neurally guided symbolic abstraction
Quentin Delfosse, Hikaru Shindo, Devendra Dhami, and Kristian Kersting. Interpretable and explainable logical policies via neurally guided symbolic abstraction. Advances in Neural Information Processing Systems, 36, 2024
work page 2024
-
[10]
Benchmarking deep reinforcement learning for continuous control
Yan Duan, Xi Chen, Rein Houthooft, John Schulman, and Pieter Abbeel. Benchmarking deep reinforcement learning for continuous control. In International conference on machine learning, pp. 1329–1338. PMLR, 2016
work page 2016
-
[11]
Stochastic Neural Networks for Hierarchical Reinforcement Learning
Carlos Florensa, Yan Duan, and Pieter Abbeel. Stochastic neural networks for hierarchical reinforcement learning. arXiv preprint arXiv:1704.03012, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[12]
Addressing function approximation error in actor-critic methods
Scott Fujimoto, Herke Hoof, and David Meger. Addressing function approximation error in actor-critic methods. In International conference on machine learning, pp. 1587–1596. PMLR, 2018
work page 2018
-
[13]
A review on deep reinforcement learning for fluid mechanics
Paul Garnier, Jonathan Viquerat, Jean Rabault, Aur´elien Larcher, Alexander Kuhnle, and Elie Hachem. A review on deep reinforcement learning for fluid mechanics. Computers & Fluids, 225:104973, 2021
work page 2021
-
[14]
A survey on interpretable reinforcement learning
Claire Glanois, Paul Weng, Matthieu Zimmer, Dong Li, Tianpei Yang, Jianye Hao, and Wulong Liu. A survey on interpretable reinforcement learning. Machine Learning, pp. 1–44, 2024
work page 2024
-
[15]
A review of safe reinforcement learning: Methods, theories and applications
Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, and Alois Knoll. A review of safe reinforcement learning: Methods, theories and applications. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[16]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In International conference on machine learning, pp. 1861–1870. PMLR, 2018
work page 2018
-
[17]
Actor-critic reinforcement learning for control with stability guarantee
Minghao Han, Lixian Zhang, Jun Wang, and Wei Pan. Actor-critic reinforcement learning for control with stability guarantee. IEEE Robotics and Automation Letters, 5(4):6217–6224, 2020
work page 2020
-
[18]
Interpretable policies for reinforcement learning by genetic programming
Daniel Hein, Steffen Udluft, and Thomas A Runkler. Interpretable policies for reinforcement learning by genetic programming. Engineering Applications of Artificial Intelligence, 76:158–169, 2018
work page 2018
-
[19]
Quercus Hern´andez, Alberto Bad´ıas, Francisco Chinesta, and El´ıas Cueto. Port-metriplectic neural networks: thermodynamics-informed machine learning of complex physical systems. Computational Mechanics, 72(3): 553–561, 2023
work page 2023
-
[20]
Explainability in deep reinforcement learning
Alexandre Heuillet, Fabien Couthouis, and Natalia D´ıaz-Rodr´ıguez. Explainability in deep reinforcement learning. Knowledge-Based Systems, 214:106685, 2021
work page 2021
-
[21]
Neural logic reinforcement learning
Zhengyao Jiang and Shan Luo. Neural logic reinforcement learning. In International conference on machine learning, pp. 3110–3119. PMLR, 2019
work page 2019
-
[22]
Stability-certified reinforcement learning: A control-theoretic perspective
Ming Jin and Javad Lavaei. Stability-certified reinforcement learning: A control-theoretic perspective. IEEE Access, 8:229086–229100, 2020
work page 2020
-
[23]
Creativity of ai: Automatic symbolic option discovery for facilitating deep reinforcement learning
Mu Jin, Zhihao Ma, Kebing Jin, Hankz Hankui Zhuo, Chen Chen, and Chao Yu. Creativity of ai: Automatic symbolic option discovery for facilitating deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp. 7042–7050, 2022
work page 2022
-
[24]
The joint spectral radius: theory and applications, volume 385
Rapha¨el Jungers. The joint spectral radius: theory and applications, volume 385. Springer Science & Business Media, 2009
work page 2009
-
[25]
Increasing the safety of adaptive cruise control using physics-guided reinforcement learning
Sorin Liviu Jurj, Dominik Grundt, Tino Werner, Philipp Borchers, Karina Rothemann, and Eike M ¨ohlmann. Increasing the safety of adaptive cruise control using physics-guided reinforcement learning. Energies, 14(22): 7572, 2021
work page 2021
-
[26]
Scalable deep reinforcement learning for vision-based robotic manipulation
Dmitry Kalashnikov, Alex Irpan, Peter Pastor, Julian Ibarz, Alexander Herzog, Eric Jang, Deirdre Quillen, Ethan Holly, Mrinal Kalakrishnan, Vincent Vanhoucke, et al. Scalable deep reinforcement learning for vision-based robotic manipulation. In Conference on robot learning, pp. 651–673. PMLR, 2018. 13 arXiv SALSA-RL A PREPRINT
work page 2018
-
[27]
Towards interpretable deep reinforcement learning with human- friendly prototypes
Eoin M Kenny, Mycal Tucker, and Julie Shah. Towards interpretable deep reinforcement learning with human- friendly prototypes. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[28]
A framework for output-feedback symbolic control
Mahmoud Khaled, Kuize Zhang, and Majid Zamani. A framework for output-feedback symbolic control. IEEE Transactions on Automatic Control, 68(9):5600–5607, 2022
work page 2022
-
[29]
Auto-Encoding Variational Bayes
Diederik P Kingma. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[30]
Floquet theory: a useful tool for understanding nonequilibrium dynamics
Christopher A Klausmeier. Floquet theory: a useful tool for understanding nonequilibrium dynamics. Theoretical Ecology, 1:153–161, 2008
work page 2008
-
[31]
Discovering symbolic policies with deep reinforcement learning
Mikel Landajuela, Brenden K Petersen, Sookyung Kim, Claudio P Santiago, Ruben Glatt, Nathan Mundhenk, Jacob F Pettit, and Daniel Faissol. Discovering symbolic policies with deep reinforcement learning. InInternational Conference on Machine Learning, pp. 5979–5989. PMLR, 2021
work page 2021
-
[32]
Continuous control with deep reinforcement learning
TP Lillicrap. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[33]
Physics-informed dyna-style model-based deep reinforcement learning for dynamic control
Xin-Yang Liu and Jian-Xun Wang. Physics-informed dyna-style model-based deep reinforcement learning for dynamic control. Proceedings of the Royal Society A, 477(2255):20210618, 2021
work page 2021
-
[34]
Sdrl: interpretable and data-efficient deep reinforce- ment learning leveraging symbolic planning
Daoming Lyu, Fangkai Yang, Bo Liu, and Steven Gustafson. Sdrl: interpretable and data-efficient deep reinforce- ment learning leveraging symbolic planning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 2970–2977, 2019
work page 2019
-
[35]
Task-oriented koopman-based control with contrastive encoder
Xubo Lyu, Hanyang Hu, Seth Siriya, Ye Pu, and Mo Chen. Task-oriented koopman-based control with contrastive encoder. In Conference on Robot Learning, pp. 93–105. PMLR, 2023
work page 2023
-
[36]
Isaac gym: High performance gpu-based physics simulation for robot learning, 2021
Viktor Makoviychuk, Lukasz Wawrzyniak, Yunrong Guo, Michelle Lu, Kier Storey, Miles Macklin, David Hoeller, Nikita Rudin, Arthur Allshire, Ankur Handa, and Gavriel State. Isaac gym: High performance gpu-based physics simulation for robot learning, 2021
work page 2021
-
[37]
Towards interpretable reinforcement learning using attention augmented agents
Alexander Mott, Daniel Zoran, Mike Chrzanowski, Daan Wierstra, and Danilo Jimenez Rezende. Towards interpretable reinforcement learning using attention augmented agents. Advances in neural information processing systems, 32, 2019
work page 2019
-
[38]
Data-efficient hierarchical reinforcement learning
Ofir Nachum, Shixiang Shane Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. Advances in neural information processing systems, 31, 2018
work page 2018
-
[39]
Adaptive optics control using model-based reinforcement learning
Jalo Nousiainen, Chang Rajani, Markus Kasper, and Tapio Helin. Adaptive optics control using model-based reinforcement learning. Optics Express, 29(10):15327–15344, 2021
work page 2021
-
[40]
Hierarchical reinforcement learning: A comprehensive survey
Shubham Pateria, Budhitama Subagdja, Ah-hwee Tan, and Chai Quek. Hierarchical reinforcement learning: A comprehensive survey. ACM Computing Surveys (CSUR), 54(5):1–35, 2021
work page 2021
-
[41]
Jean Rabault, Miroslav Kuchta, Atle Jensen, Ulysse R ´eglade, and Nicolas Cerardi. Artificial neural networks trained through deep reinforcement learning discover control strategies for active flow control. Journal of fluid mechanics, 865:281–302, 2019
work page 2019
-
[42]
Antonin Raffin. Rl baselines3 zoo. https://github.com/DLR-RM/rl-baselines3-zoo , 2020
work page 2020
-
[43]
Gunther Reissig and Matthias Rungger. Symbolic optimal control. IEEE Transactions on Automatic Control, 64 (6):2224–2239, 2018
work page 2018
-
[44]
Koopman-Assisted Reinforcement Learning
Preston Rozwood, Edward Mehrez, Ludger Paehler, Wen Sun, and Steven L Brunton. Koopman-assisted reinforcement learning. arXiv preprint arXiv:2403.02290, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[46]
Multivariable feedback control: analysis and design
Sigurd Skogestad and Ian Postlethwaite. Multivariable feedback control: analysis and design. john Wiley & sons, 2005
work page 2005
-
[47]
Reinforcement learning: An introduction
Richard S Sutton. Reinforcement learning: An introduction. A Bradford Book, 2018
work page 2018
-
[48]
Adaptive control schemes for improving the control system dynamics: a review
Pankaj Swarnkar, Shailendra Kumar Jain, and Rajesh Kumar Nema. Adaptive control schemes for improving the control system dynamics: a review. IETE Technical Review, 31(1):17–33, 2014
work page 2014
-
[49]
Programmati- cally interpretable reinforcement learning
Abhinav Verma, Vijayaraghavan Murali, Rishabh Singh, Pushmeet Kohli, and Swarat Chaudhuri. Programmati- cally interpretable reinforcement learning. In International Conference on Machine Learning, pp. 5045–5054. PMLR, 2018
work page 2018
-
[50]
Toward physics-guided safe deep reinforcement learning for green data center cooling control
Ruihang Wang, Xinyi Zhang, Xin Zhou, Yonggang Wen, and Rui Tan. Toward physics-guided safe deep reinforcement learning for green data center cooling control. In 2022 ACM/IEEE 13th International Conference on Cyber-Physical Systems (ICCPS), pp. 159–169. IEEE, 2022. 14 arXiv SALSA-RL A PREPRINT
work page 2022
-
[51]
Embed to control: A locally linear latent dynamics model for control from raw images
Manuel Watter, Jost Springenberg, Joschka Boedecker, and Martin Riedmiller. Embed to control: A locally linear latent dynamics model for control from raw images. Advances in neural information processing systems, 28, 2015
work page 2015
-
[52]
Model-based deep reinforcement learning for accelerated learning from flow simulations
Andre Weiner and Janis Geise. Model-based deep reinforcement learning for accelerated learning from flow simulations. Meccanica, pp. 1–18, 2024
work page 2024
-
[53]
Koopman q-learning: Offline reinforcement learning via symmetries of dynamics
Matthias Weissenbacher, Samarth Sinha, Animesh Garg, and Kawahara Yoshinobu. Koopman q-learning: Offline reinforcement learning via symmetries of dynamics. In International conference on machine learning , pp. 23645–23667. PMLR, 2022
work page 2022
-
[54]
Explainable ai and reinforcement learning—a systematic review of current approaches and trends
Lindsay Wells and Tomasz Bednarz. Explainable ai and reinforcement learning—a systematic review of current approaches and trends. Frontiers in artificial intelligence, 4:550030, 2021
work page 2021
-
[55]
Interpretable deep reinforcement learning for optimizing heterogeneous energy storage systems
Luolin Xiong, Yang Tang, Chensheng Liu, Shuai Mao, Ke Meng, Zhaoyang Dong, and Feng Qian. Interpretable deep reinforcement learning for optimizing heterogeneous energy storage systems. IEEE Transactions on Circuits and Systems I: Regular Papers, 2023
work page 2023
-
[56]
Reinforcement learning with prototypical representations
Denis Yarats, Rob Fergus, Alessandro Lazaric, and Lerrel Pinto. Reinforcement learning with prototypical representations. In International Conference on Machine Learning, pp. 11920–11931. PMLR, 2021
work page 2021
-
[57]
Learning deep neural network representations for koopman operators of nonlinear dynamical systems
Enoch Yeung, Soumya Kundu, and Nathan Hodas. Learning deep neural network representations for koopman operators of nonlinear dynamical systems. In 2019 American Control Conference (ACC), pp. 4832–4839. IEEE, 2019
work page 2019
-
[58]
Physics-guided deep reinforcement learning for flow field denoising
Mustafa Z Yousif, Meng Zhang, Yifan Yang, Haifeng Zhou, Linqi Yu, and HeeChang Lim. Physics-guided deep reinforcement learning for flow field denoising. arXiv preprint arXiv:2302.09559, 2023
-
[59]
Reinforcement learning with knowledge representation and reasoning: A brief survey
Chao Yu, Xuejing Zheng, Hankz Hankui Zhuo, Hai Wan, and Weilin Luo. Reinforcement learning with knowledge representation and reasoning: A brief survey. arXiv preprint arXiv:2304.12090, 2023
-
[60]
Concept learning for interpretable multi-agent reinforcement learning
Renos Zabounidis, Joseph Campbell, Simon Stepputtis, Dana Hughes, and Katia P Sycara. Concept learning for interpretable multi-agent reinforcement learning. In Conference on Robot Learning, pp. 1828–1837. PMLR, 2023
work page 2023
-
[61]
Stable and safe reinforcement learning via a barrier-lyapunov actor-critic approach
Liqun Zhao, Konstantinos Gatsis, and Antonis Papachristodoulou. Stable and safe reinforcement learning via a barrier-lyapunov actor-critic approach. In 2023 62nd IEEE Conference on Decision and Control (CDC), pp. 1320–1325. IEEE, 2023
work page 2023
-
[62]
Sindy-rl: Interpretable and efficient model-based reinforcement learning
Nicholas Zolman, Urban Fasel, J Nathan Kutz, and Steven L Brunton. Sindy-rl: Interpretable and efficient model-based reinforcement learning. arXiv preprint arXiv:2403.09110, 2024. 15 arXiv SALSA-RL A PREPRINT A Derivation of the Policy Gradient for SALSA-RL A.1 Policy Formulation A latent dynamic control policy is defined based on Eqs. (3), (4), (5), and ...
-
[63]
Region of Instability (T: 0–30): Initial local instability before any actions are applied
-
[64]
Region of Recovery (T: 30–150): Control actions are applied to recover the system from local instability to stability
-
[65]
Region of Control Failure (T: 150–200): The control is removed, and the system transitions back from local stability to instability. From the spectral radius and eigenvalue plot (first column, third row), regions of local instability (ρ1 > 1) are evident in time Regions 1 and 3, as well as at the initial stage of Region 2. In Region 2, the policy successf...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.