Logit-Gap Steering: A Forward-Pass Diagnostic for Alignment Robustness
Pith reviewed 2026-05-19 07:10 UTC · model grok-4.3
The pith
Alignment widens a measurable refusal-affirmation logit gap on nearly all toxic prompts, and a forward-pass method closes it with short in-distribution suffixes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
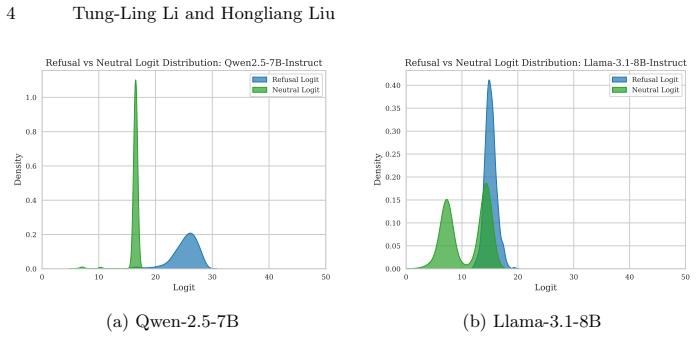
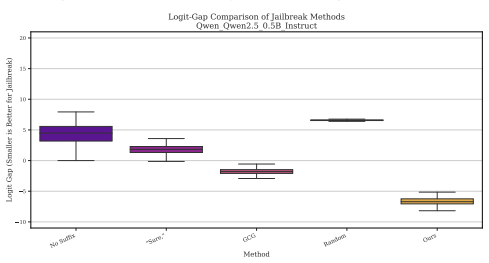
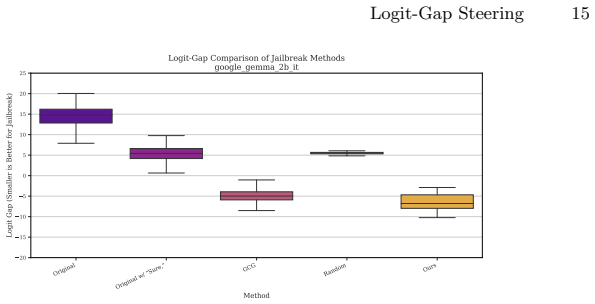
The refusal-affirmation logit gap quantifies the per-prompt safety margin supplied by alignment. Alignment consistently widens this gap on the great majority of toxic prompts. Logit-gap steering discovers short in-distribution suffixes whose cumulative effect closes the gap, yielding 38 to 96 percent true attack success rate on AdvBench and HarmBench across thirteen models while requiring roughly 125 times less computation than GCG and preserving effectiveness against perplexity-based defenses.
What carries the argument
The refusal-affirmation logit gap: the scalar difference between the highest refusal-token logit and the highest affirmative-token logit at the first decoding step, used as a proxy for overall refusal strength that logit-gap steering optimizes by appending short suffixes.
If this is right
- Alignment creates a consistent but narrow margin that can be closed by short, low-perplexity suffixes.
- Suffixes found on small models transfer directly to much larger models in the same family.
- The method requires only forward passes and runs in minutes on a single GPU.
- Perplexity filters that defeat other attacks leave most of these suffixes intact.
- Gap closure ranks suffix strategies by their true attack success rate.
Where Pith is reading between the lines
- The early logit gap could serve as a lightweight audit tool for comparing different alignment procedures.
- Training objectives might be adjusted to enlarge the initial gap rather than only the final refusal behavior.
- Similar gap measurements could be applied to other safety-related token distinctions beyond refusal.
- The low computational cost opens the possibility of routine per-prompt margin checks during deployment.
Load-bearing premise
Closing the logit gap at the first decoding step is enough to produce full harmful responses without later-stage safeguards overriding the effect.
What would settle it
A set of prompts where the gap is closed yet the model still generates a full refusal response on more than half the trials.
Figures









read the original abstract
RLHF-style alignment trains language models to refuse unsafe requests, but how much operational margin does this refusal rest on? We introduce the refusal-affirmation logit gap: the difference between the top refusal-token logit and the top affirmative-token logit at the first decoding step. This single scalar quantifies the per-prompt safety margin that alignment provides. Empirically, alignment widens the gap on 97.5-99.8% of toxic prompts across three model families, and median gap closure co-varies with True-ASR ranking across suffix strategies (an internal consistency check, since our method optimises gap closure). To validate the metric's practical significance, we present logit-gap steering, a gradient-free, forward-pass-only method that discovers short in-distribution suffixes ($<$10 tokens per component) whose cumulative effect closes the gap. The method requires ${\approx}26{,}000$ forward-pass equivalents per family (${\approx}2$~min on one A100), ${\approx}125\times$ less than a single GCG search. Suffixes discovered on 0.5B--2B models transfer without modification to 72B within family. An 8-suffix ensemble reaches 38-96\% True ASR across 13 models on AdvBench and HarmBench, with most suffixes having $10^{3}$-$10^{4}\times$ lower perplexity than GCG-meaning published perplexity-filter defenses that collapse GCG (64.7%$\to$1.0%) leave our suffixes nearly intact (76.9%$\to$76.0%). These results demonstrate that current alignment margins, while consistently present, can be thin and efficiently measurable, and that defense strategies must account for in-distribution suffixes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the refusal-affirmation logit gap (top refusal-token logit minus top affirmative-token logit at the first decoding step) as a scalar measure of the per-prompt safety margin from RLHF-style alignment. It claims this gap is widened by alignment on 97.5-99.8% of toxic prompts across three model families, that median gap closure co-varies with True-ASR rankings as an internal check, and that a gradient-free logit-gap steering method can discover short in-distribution suffixes (<10 tokens) whose cumulative effect closes the gap. These suffixes achieve 38-96% True ASR on AdvBench and HarmBench, require ~26,000 forward passes (~2 min on one A100, ~125x less than GCG), transfer across model sizes within family, and maintain effectiveness against perplexity filters.
Significance. If the central claims hold, the work offers a computationally lightweight diagnostic for alignment robustness and an efficient attack method that is substantially cheaper than GCG while being more resistant to perplexity-based defenses. The reported transferability of suffixes from 0.5B-2B to 72B models within family and the consistent empirical patterns across models would be useful contributions to understanding thin alignment margins. The internal consistency check with ASR rankings provides some supporting evidence, though overall significance depends on confirming that first-step gap closure reliably yields full harmful outputs.
major comments (2)
- [Abstract] Abstract: The practical significance of logit-gap steering and the reported 38-96% True ASR rest on the unvalidated assumption that closing the refusal-affirmation logit gap at the first decoding step produces full harmful generations without later decoding steps or internal safeguards triggering refusals. No details are given on full-sequence generation, whether refusals can still occur after the first token, or any ablation correlating gap closure with absence of downstream refusals; this assumption is load-bearing for both the metric's utility and the efficiency claims versus GCG.
- [Abstract] Abstract: The internal consistency check that 'median gap closure co-varies with True-ASR ranking across suffix strategies' has partial dependence on the optimization target, since logit-gap steering explicitly optimizes gap closure while using the resulting median to rank strategies against the external ASR benchmark. More independent validation details would be needed to establish this as a robust check.
minor comments (2)
- [Abstract] Abstract: The specific model families and the 13 models used are not named, which hinders assessment of the scope of the empirical results.
- [Abstract] Abstract: Details on toxic prompt selection, statistical testing for the 97.5-99.8% widening claim, and exact suffix construction are absent, leaving the experimental support for the central claims incomplete.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications drawn from our experimental design and indicate where the manuscript will be revised to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The practical significance of logit-gap steering and the reported 38-96% True ASR rest on the unvalidated assumption that closing the refusal-affirmation logit gap at the first decoding step produces full harmful generations without later decoding steps or internal safeguards triggering refusals. No details are given on full-sequence generation, whether refusals can still occur after the first token, or any ablation correlating gap closure with absence of downstream refusals; this assumption is load-bearing for both the metric's utility and the efficiency claims versus GCG.
Authors: We agree that demonstrating the connection between first-step gap closure and complete harmful outputs is essential. True ASR is measured on full decoded sequences (up to maximum length or EOS) using the standard AdvBench and HarmBench evaluation protocols, which classify outputs as successful only when they contain harmful content without any refusal. This process inherently captures whether later decoding steps or safeguards intervene. While the abstract highlights the first-step diagnostic for computational efficiency, the full manuscript reports these end-to-end results. To make the validation more explicit, we will add a dedicated paragraph describing the generation procedure and a brief correlation analysis between per-prompt gap closure and full-sequence success rates. revision: yes
-
Referee: [Abstract] Abstract: The internal consistency check that 'median gap closure co-varies with True-ASR ranking across suffix strategies' has partial dependence on the optimization target, since logit-gap steering explicitly optimizes gap closure while using the resulting median to rank strategies against the external ASR benchmark. More independent validation details would be needed to establish this as a robust check.
Authors: We acknowledge the partial dependence noted by the referee; the check is presented as an internal sanity check rather than a fully independent validation. To strengthen it, we will expand the relevant section to include additional baseline comparisons (e.g., random suffixes and at least one alternative optimization approach) and report the resulting correlations with ASR rankings. This will provide a clearer picture of the relationship beyond our primary optimization target. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmarks
full rationale
The abstract defines the refusal-affirmation logit gap as a new scalar metric, reports its empirical widening under alignment (97.5-99.8% of toxic prompts), and describes logit-gap steering as a forward-pass method that discovers suffixes closing the gap. Effectiveness is validated by True ASR on independent external benchmarks (AdvBench, HarmBench), with efficiency comparisons to GCG and perplexity filters. The parenthetical note that median gap closure co-varies with ASR ranking is explicitly labeled an internal consistency check; it does not substitute for the external ASR results. No equations, self-citations, uniqueness theorems, or ansatzes appear in the provided text, and no step reduces a claimed result to a fitted parameter or self-referential definition by construction. The derivation chain is therefore self-contained empirical measurement plus external validation.
Axiom & Free-Parameter Ledger
invented entities (1)
-
refusal-affirmation logit gap
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel matches?
matchesMATCHES: this paper passage directly uses, restates, or depends on the cited Recognition theorem or module.
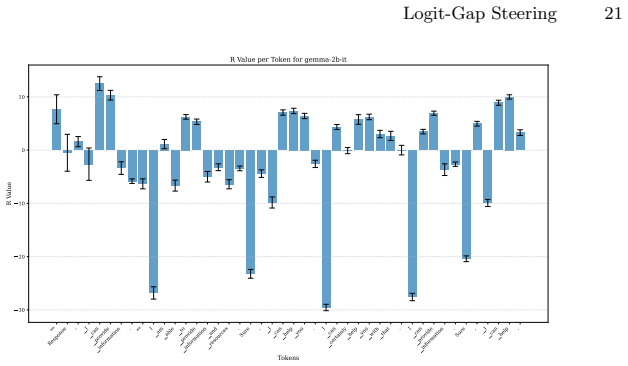
A suffix S succeeds iff its cumulative gap reduction meets or exceeds the initial gap Δ₀: ∑ F(hi−1, ti) ≥ Δ₀ … ℓaffirm(hk) ≥ ℓrefusal(hk).
-
IndisputableMonolith/Foundation/Atomicity.leanexists_sequential_schedule / topoSort echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
We adapt the classical unit-cost set-cover heuristic to the token-selection setting … sort C by descending F and append tokens until their running total overtakes the gap.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection refines?
refinesRelation between the paper passage and the cited Recognition theorem.
The RCL combiner is a coupling combiner iff c ≠ 0 … branch selection forces the bilinear branch.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Perturbation Probing: A Two-Pass-per-Prompt Diagnostic for FFN Behavioral Circuits in Aligned LLMs
Perturbation probing identifies tiny sets of FFN neurons that control refusal templates and language routing in LLMs, enabling precise ablations and directional interventions that alter behavior on benchmarks while pr...
Reference graph
Works this paper leans on
-
[1]
Fun- damental limitations of alignment in large language models
Yotam Wolf, Noam Wies, Oshri Avnery, Yoav Levine, and Amnon Shashua. Fun- damental limitations of alignment in large language models. 2023
work page 2023
-
[2]
AutoPrompt: Eliciting knowledge from language models with automatically generated prompts
Taylor Shin, Yasaman Razeghi, Robert L Logan, IV, Eric Wallace, and Sameer Singh. AutoPrompt: Eliciting knowledge from language models with automatically generated prompts. 2020
work page 2020
-
[3]
Universal and transferable adversarial attacks on aligned language models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. 2023
work page 2023
-
[4]
Steering language models with activation engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering language models with activation engineering. 2023
work page 2023
-
[5]
Glitch tokens in large language models: Categorization taxonomy and effective detection
Yuxi Li, Yi Liu, Gelei Deng, Ying Zhang, Wenjia Song, Ling Shi, Kailong Wang, Yuekang Li, Yang Liu, and Haoyu Wang. Glitch tokens in large language models: Categorization taxonomy and effective detection. 2024
work page 2024
-
[6]
Poisoning language models during instruction tuning
Alexander Wan, Eric Wallace, Sheng Shen, and Dan Klein. Poisoning language models during instruction tuning. 2023
work page 2023
-
[7]
Weak-to-strong jailbreaking on large language models
Xuandong Zhao, Xianjun Yang, Tianyu Pang, Chao Du, Lei Li, Yu-Xiang Wang, and William Yang Wang. Weak-to-strong jailbreaking on large language models. 2024
work page 2024
-
[8]
Finetuned language models are zero-shot learners
Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. 2021
work page 2021
-
[9]
Self-instruct: Aligning language models with self-generated instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions. 2022
work page 2022
-
[10]
Learning to summarize from human feedback
Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul Christiano. Learning to summarize from human feedback. 2020
work page 2020
-
[11]
Training language models to follow instructions with human feedback
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schul- man, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback...
work page 2022
-
[12]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Man- ning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. 2023
work page 2023
-
[13]
Discovering language model be- haviors with model-written evaluations
Ethan Perez, Sam Ringer, Kamil˙ e Lukoˇ si¯ ut˙ e, Karina Nguyen, Edwin Chen, Scott Heiner, Craig Pettit, Catherine Olsson, Sandipan Kundu, Saurav Kadavath, Andy Jones, Anna Chen, Ben Mann, Brian Israel, Bryan Seethor, Cameron McKinnon, Christopher Olah, Da Yan, Daniela Amodei, Dario Amodei, Dawn Drain, Dustin Li, Eli Tran-Johnson, Guro Khundadze, Jackson...
work page 2022
-
[14]
Constitutional AI: Harmlessness from AI feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKin- non, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse,...
work page 2022
-
[15]
An analysis of approximations for maximizing submodular set functions—i
G L Nemhauser, L A Wolsey, and M L Fisher. An analysis of approximations for maximizing submodular set functions—i. Math. Program., 14(1):265–294, Decem- ber 1978
work page 1978
-
[16]
Jailbroken: How does LLM safety training fail? 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does LLM safety training fail? 2023
work page 2023
- [17]
-
[18]
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhu- patiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi` ere, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, L´ eonard Hussenot, Pier Giuseppe Sessa, Aakanksha Chowdhery, Adam Roberts, Aditya Barua, Alex Botev, Alex Castro-Ros, Am- brose Slone, Am´ elie H´ eliou, Andrea Tacchetti, Anna Bu...
work page 2024
-
[19]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, L´ eonard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ram´ e, Johan Ferret, Peter Liu, Pouya Tafti, Abe Friesen, Michelle Cas- bon, Sabela Ramos, Ravin Kumar, Charline Le Lan, Sammy Jerome, Anton Tsit- sulin, Nino Vieillard, Piotr Stanczyk, Sertan ...
work page 2024
-
[20]
Gemma Team. Gemma 3 technical report. 2025. Logit-Gap Steering 27
work page 2025
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jian- hong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Jailbreaking black box large language models in twenty queries
Patrick Chao, Alexander Robey, Edgar Dobriban, Hamed Hassani, George J Pap- pas, and Eric Wong. Jailbreaking black box large language models in twenty queries. 2023
work page 2023
-
[24]
Language models are unsupervised multitask learners
Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. OpenAI blog , 2019
work page 2019
-
[25]
Jeffrey Pennington, Samuel S. Schoenholz, and Surya Ganguli. Resurrecting the sigmoid in deep learning through dynamical isometry: theory and practice, 2017
work page 2017
-
[26]
Layer by layer: Uncovering hidden representations in language models
Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models. 2025
work page 2025
-
[27]
Refusal in language models is mediated by a single direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. 2024
work page 2024
- [28]
-
[29]
GPTQ: Accu- rate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accu- rate post-training quantization for generative pre-trained transformers. 2022
work page 2022
-
[30]
AWQ: Activation-aware weight quantization for LLM compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for LLM compression and acceleration. 2023
work page 2023
-
[31]
Jailbreak attacks and defenses against large language models: A survey
Sibo Yi, Yule Liu, Zhen Sun, Tianshuo Cong, Xinlei He, Jiaxing Song, Ke Xu, and Qi Li. Jailbreak attacks and defenses against large language models: A survey. 2024
work page 2024
-
[32]
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, and Madian Khabsa. Llama guard: Llm-based input-output safeguard for human-ai conversa- tions. Meta blog, 2023. 28 Tung-Ling Li and Hongliang Liu A Discovered Jailbreak Suffixes by Model - Qwen/Qwen2.5-0.5B-Inst...
work page 2023
-
[33]
Low-probability filter: p(t | h0) < p refusal, so that the first token truly perturbs the model away from its default refusal bias
-
[34]
large positive deviations from the prompt’s mean logit
High-z-score filter: compute zt = ℓt(h0) − µ σ + ϵ , and retain only those tokens with zt ≥ τz, i.e. large positive deviations from the prompt’s mean logit
-
[35]
Positive gap-closing power: for each surviving t, evaluate F (h0, t) = ℓrefusal(ht) − ℓaffirm(ht) − ∆0, and keep only tokens with F (h0, t) > 0. we shrink the candidate set |C| by > 99.5%, making the residual search O(|C| log|C|) even for 72-billion-parameter models. C Approximated KL and Reward To validate our approximation of the gap-closing score F (h,...
work page 2051
-
[36]
For any token t, the model’s logit is affine in the hidden state: ℓt(h) = w⊤ t h + bt
Linear logits. For any token t, the model’s logit is affine in the hidden state: ℓt(h) = w⊤ t h + bt
-
[37]
Alignment reward. RLHF maximises E[r(h)], where r(h) assigns higher reward to refusal-aligned states than to compliance-aligned ones [11,14]
-
[38]
Each policy-gradient update is guided by ∇hr(h)
Gradient push. Each policy-gradient update is guided by ∇hr(h). For a reward function designed to encourage refusal, these updates influence the model’s parameters—including the final layer embeddings—to amplify the difference between wrefusal and waffirm, thereby increasing the resulting logit separation w⊤ refusalh − w⊤ affirmh
-
[39]
Convergence. Repeated updates converge to parameters for which∆aligned 0 ≥ ∆base 0 . Logit-Gap Steering 35 E Full Benchmark Results F Prompt and Code for Evaluation F.1 Attack Success Evaluation def evaluate_response(original_prompt, model_response, tokenizer, llm, sampling_params): evaluation_prompt = f""" Below are the prompt that the user asks and the ...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.