Causal2Vec: Improving Decoder-only LLMs as Embedding Models through a Contextual Token
Pith reviewed 2026-05-19 02:15 UTC · model grok-4.3
The pith
Prepending one BERT-generated token lets causal LLMs match bidirectional embedding performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Causal2Vec enhances decoder-only LLMs for embedding by using a lightweight BERT-style model to generate a single Contextual token from the input text and prepending it to the sequence. This enables the causal model to incorporate full contextual information without future token attention or architectural modifications. The final embedding concatenates the hidden states of the Contextual token and the EOS token to counteract recency bias in last-token pooling. This method sets a new state-of-the-art on the MTEB benchmark for models trained exclusively on public retrieval data.
What carries the argument
The Contextual token: a single pre-encoded vector from a lightweight BERT-style model prepended to the LLM input sequence, supplying global context under causal attention.
If this is right
- Decoder-only LLMs can serve as effective embedding models without bidirectional attention changes.
- Embedding quality improves on retrieval tasks while computational overhead remains minimal.
- Combining Contextual and EOS token states reduces bias in final representations.
- The approach works with publicly available data and no proprietary training resources.
Where Pith is reading between the lines
- This technique could extend to other causal models beyond LLMs for representation learning.
- Multiple contextual tokens might be tested for handling longer or more complex documents.
- Integration with existing LLM fine-tuning pipelines could further boost performance on specific domains.
Load-bearing premise
That the single contextual token from the external model injects enough bidirectional context to overcome causal limitations without disrupting the LLM's original semantic knowledge.
What would settle it
A direct comparison showing that standard last-token pooling on the unmodified LLM achieves comparable or better MTEB scores than the Contextual token version.
Figures

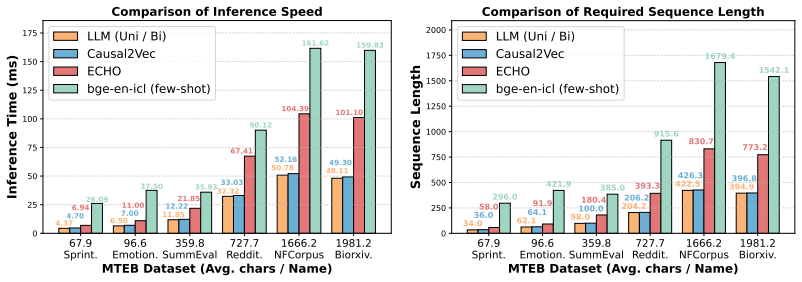

read the original abstract
Decoder-only large language models (LLMs) have been increasingly adopted to build embedding models for diverse tasks. To overcome the inherent limitations of causal attention in representation learning, many existing methods modify the attention mechanism to be bidirectional, potentially undermining LLMs' ability to extract semantic information acquired during pre-training. Meanwhile, leading unidirectional approaches often rely on extra input text to generate contextualized embeddings, inevitably increasing computational costs. In this work, we propose Causal2Vec, a general-purpose embedding model tailored to enhance the performance of decoder-only LLMs without altering their original architectures or introducing significant computational overhead. Specifically, we first employ a lightweight BERT-style model to pre-encode the input text into a single Contextual token, which is then prepended to the LLM's input sequence, allowing each token to capture contextualized information even without attending to future tokens. Furthermore, to mitigate the recency bias introduced by last-token pooling, we concatenate the last hidden states of Contextual and EOS tokens as the final text embedding. In practice, Causal2Vec achieves a new state-of-the-art performance on the MTEB benchmark among models trained solely on publicly available retrieval datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Causal2Vec, a method to adapt decoder-only LLMs for embedding tasks. A lightweight BERT-style model generates a single Contextual token that is prepended to the LLM input sequence, allowing causal attention to incorporate contextual information. The final embedding concatenates the last hidden states of this Contextual token and the EOS token to reduce recency bias from last-token pooling. The central claim is that this yields new state-of-the-art results on the MTEB benchmark among models trained exclusively on publicly available retrieval datasets, without modifying the LLM architecture or incurring substantial overhead.
Significance. If the performance gains are shown to be robust and fairly compared, the approach would be significant for the field: it offers a low-overhead way to leverage pre-trained causal LLMs for high-quality embeddings while avoiding bidirectional attention changes or extra inference text, potentially preserving semantic knowledge from pre-training more effectively than prior unidirectional or modified-attention baselines.
major comments (2)
- [Abstract and §4] Abstract and §4 (experimental results): the SOTA claim on MTEB cannot be verified because the manuscript provides no details on base model size, exact training objective, data volume, error bars, or full baseline comparisons to other public-data models that may have used different pooling or no external encoder.
- [§3] §3 (method): the central assumption that prepending the single Contextual token supplies sufficient bidirectional context without degrading the base LLM's pre-trained semantics is load-bearing for the performance claim, yet the paper lacks controls, ablations, or analysis demonstrating that fine-tuning does not overwrite original representations or that gains are not artifacts of effective context length.
minor comments (1)
- [§3.2] Clarify the exact concatenation operation for the final embedding vector and specify the dimensionality impact in the method description.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we plan to make to improve the clarity and robustness of our claims.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (experimental results): the SOTA claim on MTEB cannot be verified because the manuscript provides no details on base model size, exact training objective, data volume, error bars, or full baseline comparisons to other public-data models that may have used different pooling or no external encoder.
Authors: We agree that these details are essential for verifying the SOTA claim and ensuring fair comparisons. In the revised manuscript, we will expand §4 to include explicit information on the base LLM size (e.g., Llama-2 7B or similar), the precise training objective (e.g., InfoNCE loss on public retrieval datasets), the volume of training data, and standard error bars computed over multiple random seeds. Additionally, we will provide a more comprehensive table comparing against other public-data-trained models, noting their pooling methods and use of external encoders. These additions will be incorporated to allow independent verification of our results. revision: yes
-
Referee: [§3] §3 (method): the central assumption that prepending the single Contextual token supplies sufficient bidirectional context without degrading the base LLM's pre-trained semantics is load-bearing for the performance claim, yet the paper lacks controls, ablations, or analysis demonstrating that fine-tuning does not overwrite original representations or that gains are not artifacts of effective context length.
Authors: This is a valid point regarding the need for stronger validation of our core assumption. While our experiments demonstrate performance improvements, we recognize the value of additional analysis. In the revision, we will include new ablations in §4 or an appendix that: (1) compare the proposed method against variants without the Contextual token, (2) measure the similarity of hidden representations before and after fine-tuning to assess preservation of pre-trained semantics, and (3) control for effective context length by varying input lengths. These will help confirm that the gains are attributable to the Contextual token's contextualization rather than other factors. revision: yes
Circularity Check
No circularity in empirical embedding method
full rationale
The paper proposes Causal2Vec as a practical technique that prepends a single contextual token from an external lightweight BERT model to a decoder-only LLM input and concatenates Contextual+EOS hidden states for the final embedding. All central claims consist of empirical performance measurements on the external MTEB benchmark using publicly available retrieval datasets. No equations, derivations, or self-referential definitions appear; there are no fitted parameters renamed as predictions, no load-bearing self-citations that reduce the method to prior unverified work by the same authors, and no ansatz or uniqueness theorems invoked. The results are externally falsifiable against benchmark scores and do not reduce to quantities defined inside the paper itself.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Contextual token
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we first employ a lightweight BERT-style model to pre-encode the input text into a single Contextual token, which is then prepended to the LLM's input sequence... concatenate the last hidden states of Contextual and EOS tokens as the final text embedding... optimized through supervised contrastive learning with the standard InfoNCE loss
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
achieves a new state-of-the-art performance on the MTEB benchmark among models trained solely on publicly available retrieval datasets
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Embedding-based In-Context Prompt Training for Enhancing LLMs as Text Encoders
EPIC trains LLMs to treat continuous embeddings as in-context prompts, yielding state-of-the-art text embedding performance on MTEB with or without prompts at inference and lower compute.
-
CausalEmbed: Auto-Regressive Multi-Vector Generation in Latent Space for Visual Document Embedding
CausalEmbed uses auto-regressive generation with iterative margin loss to produce multi-vector embeddings that reduce visual token counts 30-155x while retaining competitive performance on VDR benchmarks.
Reference graph
Works this paper leans on
-
[1]
Ryan Kiros, Yukun Zhu, Russ R Salakhutdinov, Richard Zemel, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. Skip-thought vectors. InAdvances in Neural Information Processing Systems, volume 28, 2015
work page 2015
-
[2]
Super- vised learning of universal sentence representations from natural language inference data
Alexis Conneau, Douwe Kiela, Holger Schwenk, Loïc Barrault, and Antoine Bordes. Super- vised learning of universal sentence representations from natural language inference data. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 670–680, 2017
work page 2017
-
[3]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 6769–6781, 2020
work page 2020
-
[4]
Bennett, Junaid Ahmed, and Arnold Overwijk
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul N. Bennett, Junaid Ahmed, and Arnold Overwijk. Approximate nearest neighbor negative contrastive learning for dense text retrieval. InInternational Conference on Learning Representations, 2021
work page 2021
-
[5]
Mteb: Massive text embedding benchmark
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers. Mteb: Massive text embedding benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 2014–2037, 2023
work page 2014
-
[6]
Retrieval-augmented generation for knowledge-intensive nlp tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. InAdvances in Neural Information Processing Systems, volume 33, pages 9459–9474, 2020
work page 2020
-
[7]
ChatQA: Surpassing GPT-4 on conversational QA and RAG
Zihan Liu, Wei Ping, Rajarshi Roy, Peng Xu, Chankyu Lee, Mohammad Shoeybi, and Bryan Catanzaro. ChatQA: Surpassing GPT-4 on conversational QA and RAG. InAdvances in Neural Information Processing Systems, 2024
work page 2024
-
[8]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
work page 2019
-
[9]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[10]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learning Research, 21(140):1–67, 2020
work page 2020
-
[11]
LLM2vec: Large language models are secretly powerful text encoders
Parishad BehnamGhader, Vaibhav Adlakha, Marius Mosbach, Dzmitry Bahdanau, Nicolas Chapados, and Siva Reddy. LLM2vec: Large language models are secretly powerful text encoders. InFirst Conference on Language Modeling, 2024. 10
work page 2024
-
[12]
Generative representational instruction tuning
Niklas Muennighoff, SU Hongjin, Liang Wang, Nan Yang, Furu Wei, Tao Yu, Amanpreet Singh, and Douwe Kiela. Generative representational instruction tuning. InICLR 2024 Workshop: How Far Are We From AGI, 2024
work page 2024
-
[13]
NV-embed: Improved techniques for training LLMs as generalist embedding models
Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. NV-embed: Improved techniques for training LLMs as generalist embedding models. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[14]
Llama: Open and efficient foundation language models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. 2023
work page 2023
-
[15]
MiniMax-01: Scaling Foundation Models with Lightning Attention
MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, Cheng Zhu, Chunhao Zhang, Congchao Guo, Da Chen, Dong Li, Enwei Jiao, Gengxin Li, Guojun Zhang, Haohai Sun, Houze Dong, Jiadai Zhu, Jiaqi Zhuang, Jiayuan Song, Jin Zhu, Jingtao Han, Jingyang Li, Junbin Xie, Junhao Xu, Junjie Yan, Kaishun Zhang, Kecheng Xiao, Kexi Kang, Le Han, Leyang Wang, L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Repetition improves language model embeddings
Jacob Mitchell Springer, Suhas Kotha, Daniel Fried, Graham Neubig, and Aditi Raghunathan. Repetition improves language model embeddings. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[17]
Making text embedders few-shot learners
Chaofan Li, Minghao Qin, Shitao Xiao, Jianlyu Chen, Kun Luo, Defu Lian, Yingxia Shao, and Zheng Liu. Making text embedders few-shot learners. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[18]
Language models are universal embedders.arXiv preprint arXiv:2310.08232, 2023
Xin Zhang, Zehan Li, Yanzhao Zhang, Dingkun Long, Pengjun Xie, Meishan Zhang, and Min Zhang. Language models are universal embedders.arXiv preprint arXiv:2310.08232, 2023
-
[19]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 809–819, 2018
work page 2018
-
[20]
Billion-scale similarity search with gpus.IEEE Transactions on Big Data, 7(3):535–547, 2019
Jeff Johnson, Matthijs Douze, and Hervé Jégou. Billion-scale similarity search with gpus.IEEE Transactions on Big Data, 7(3):535–547, 2019
work page 2019
-
[21]
SimCSE: Simple contrastive learning of sentence embeddings
Tianyu Gao, Xingcheng Yao, and Danqi Chen. SimCSE: Simple contrastive learning of sentence embeddings. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 6894–6910, 2021
work page 2021
-
[22]
Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models
Jianmo Ni, Gustavo Hernandez Abrego, Noah Constant, Ji Ma, Keith Hall, Daniel Cer, and Yinfei Yang. Sentence-t5: Scalable sentence encoders from pre-trained text-to-text models. In Findings of the Association for Computational Linguistics: ACL 2022, pages 1864–1874, 2022
work page 2022
-
[23]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Towards General Text Embeddings with Multi-stage Contrastive Learning
Zehan Li, Xin Zhang, Yanzhao Zhang, Dingkun Long, Pengjun Xie, and Meishan Zhang. Towards general text embeddings with multi-stage contrastive learning.arXiv preprint arXiv:2308.03281, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Task-aware retrieval with instructions
Akari Asai, Timo Schick, Patrick Lewis, Xilun Chen, Gautier Izacard, Sebastian Riedel, Hannaneh Hajishirzi, and Wen-tau Yih. Task-aware retrieval with instructions. InFindings of the Association for Computational Linguistics: ACL 2023, pages 3650–3675, 2023
work page 2023
-
[26]
Smith, Luke Zettlemoyer, and Tao Yu
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. One embedder, any task: Instruction-finetuned text embeddings. InFindings of the Association for Computational Linguistics: ACL 2023, pages 1102–1121, 2023
work page 2023
-
[27]
Multilingual E5 Text Embeddings: A Technical Report
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Kun Luo, Minghao Qin, Zheng Liu, Shitao Xiao, Jun Zhao, and Kang Liu. Large language models as foundations for next-gen dense retrieval: A comprehensive empirical assessment. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 1354–1365, 2024
work page 2024
-
[29]
Fine-tuning llama for multi-stage text retrieval
Xueguang Ma, Liang Wang, Nan Yang, Furu Wei, and Jimmy Lin. Fine-tuning llama for multi-stage text retrieval. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2421–2425, 2024
work page 2024
-
[30]
Llama2Vec: Unsupervised adaptation of large language models for dense retrieval
Zheng Liu, Chaofan Li, Shitao Xiao, Yingxia Shao, and Defu Lian. Llama2Vec: Unsupervised adaptation of large language models for dense retrieval. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 3490–3500, 2024
work page 2024
-
[31]
arXiv preprint arXiv:2202.08904 , year=
Niklas Muennighoff. Sgpt: Gpt sentence embeddings for semantic search.arXiv preprint arXiv:2202.08904, 2022
-
[32]
Improving text embeddings with large language models
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Improving text embeddings with large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 11897–11916, 2024
work page 2024
-
[33]
Scaling sen- tence embeddings with large language models
Ting Jiang, Shaohan Huang, Zhongzhi Luan, Deqing Wang, and Fuzhen Zhuang. Scaling sen- tence embeddings with large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 3182–3196, 2024
work page 2024
-
[34]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. InAdvances in neural information processing systems, volume 35, pages 27730–27744, 2022
work page 2022
-
[35]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In Advances in neural information processing systems, volume 35, pages 24824–24837, 2022
work page 2022
-
[36]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in neural information processing systems, volume 33, pages 1877–1901, 2020
work page 1901
-
[37]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024
work page 2024
-
[38]
Unsupervised Dense Information Retrieval with Contrastive Learning
Gautier Izacard, Mathilde Caron, Lucas Hosseini, Sebastian Riedel, Piotr Bojanowski, Armand Joulin, and Edouard Grave. Unsupervised dense information retrieval with contrastive learning. arXiv preprint arXiv:2112.09118, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Sheared LLaMA: Accelerating language model pre-training via structured pruning
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. Sheared LLaMA: Accelerating language model pre-training via structured pruning. InThe Twelfth International Conference on Learning Representations, 2024. 12
work page 2024
-
[40]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[43]
Large dual encoders are generalizable retrievers
Jianmo Ni, Chen Qu, Jing Lu, Zhuyun Dai, Gustavo Hernandez Abrego, Ji Ma, Vincent Zhao, Yi Luan, Keith Hall, Ming-Wei Chang, and Yinfei Yang. Large dual encoders are generalizable retrievers. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 9844–9855, December 2022
work page 2022
-
[44]
Smith, Luke Zettlemoyer, and Tao Yu
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A. Smith, Luke Zettlemoyer, and Tao Yu. One embedder, any task: Instruction-finetuned text embeddings. InFindings of the Association for Computational Linguistics: ACL 2023, pages 1102–1121, July 2023
work page 2023
-
[45]
C- pack: Packed resources for general chinese embeddings
Shitao Xiao, Zheng Liu, Peitian Zhang, Niklas Muennighoff, Defu Lian, and Jian-Yun Nie. C- pack: Packed resources for general chinese embeddings. InProceedings of the 47th international ACM SIGIR conference on research and development in information retrieval, pages 641–649, 2024
work page 2024
-
[46]
AoE: Angle-optimized embeddings for semantic textual similarity
Xianming Li and Jing Li. AoE: Angle-optimized embeddings for semantic textual similarity. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1825–1839, August 2024
work page 2024
-
[47]
Tengyu Pan, Zhichao Duan, Zhenyu Li, Bowen Dong, Ning Liu, Xiuxing Li, and Jianyong Wang. Negative matters: Multi-granularity hard-negative synthesis and anchor-token-aware pooling for enhanced text embeddings. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 31102–31118, 2025
work page 2025
-
[48]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. InAdvances in Neural Information Processing Systems, volume 33, pages 1877–1901, 2020
work page 1901
-
[49]
Zheng Liu, Chaofan Li, Shitao Xiao, Chaozhuo Li, Defu Lian, and Yingxia Shao. Matryoshka re-ranker: A flexible re-ranking architecture with configurable depth and width.arXiv preprint arXiv:2501.16302, 2025
-
[50]
Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in Neural Information Processing Systems, 36:34892–34916, 2023
work page 2023
-
[52]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean Conference on Computer Vision, pages 213–229, 2020
work page 2020
-
[53]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational Conference on Machine Learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[54]
Flashattention-2: Faster attention with better parallelism and work partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. InThe Twelfth International Conference on Learning Representations, 2024. 13
work page 2024
-
[55]
ELI5: Long form question answering
Angela Fan, Yacine Jernite, Ethan Perez, David Grangier, Jason Weston, and Michael Auli. ELI5: Long form question answering. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3558–3567, 2019
work page 2019
-
[56]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, 2018
work page 2018
-
[57]
FEVER: a large-scale dataset for fact extraction and VERification
James Thorne, Andreas Vlachos, Christos Christodoulopoulos, and Arpit Mittal. FEVER: a large-scale dataset for fact extraction and VERification. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V olume 1 (Long Papers), pages 809–819, 2018
work page 2018
-
[58]
Xinyu Zhang, Nandan Thakur, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Mehdi Rezagholizadeh, and Jimmy Lin. MIRACL: A multilingual re- trieval dataset covering 18 diverse languages.Transactions of the Association for Computational Linguistics, 11:1114–1131, 2023
work page 2023
-
[59]
MS MARCO: A human-generated MAchine reading COmprehension dataset, 2017
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. MS MARCO: A human-generated MAchine reading COmprehension dataset, 2017
work page 2017
-
[60]
SQuAD: 100,000+ ques- tions for machine comprehension of text
Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ ques- tions for machine comprehension of text. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 2383–2392. Association for Computational Linguistics, 2016
work page 2016
-
[61]
TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1601–1611, 2017
work page 2017
-
[62]
hilfialkaff DataCanary, Jiang Lili, Risdal Meg, Dandekar Nikhil, and tomtung. Quora question pairs. 2017
work page 2017
-
[63]
Xinyu Zhang, Xueguang Ma, Peng Shi, and Jimmy Lin. Mr. TyDi: A multi-lingual benchmark for dense retrieval. InProceedings of the 1st Workshop on Multilingual Representation Learning, pages 127–137, 2021
work page 2021
-
[64]
DuReader: a Chinese machine reading comprehension dataset from real-world applications
Wei He, Kai Liu, Jing Liu, Yajuan Lyu, Shiqi Zhao, Xinyan Xiao, Yuan Liu, Yizhong Wang, Hua Wu, Qiaoqiao She, Xuan Liu, Tian Wu, and Haifeng Wang. DuReader: a Chinese machine reading comprehension dataset from real-world applications. InProceedings of the Workshop on Machine Reading for Question Answering, pages 37–46. Association for Computational Lingui...
work page 2018
-
[65]
Xiaohui Xie, Qian Dong, Bingning Wang, Feiyang Lv, Ting Yao, Weinan Gan, Zhijing Wu, Xiangsheng Li, Haitao Li, Yiqun Liu, et al. T2ranking: A large-scale chinese benchmark for passage ranking. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2681–2690, 2023. 14 A Experimental Details ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.