Visual-TableQA: Open-Domain Benchmark for Reasoning over Table Images
Pith reviewed 2026-05-18 17:33 UTC · model grok-4.3
The pith
A new dataset of rendered table images with complex questions allows fine-tuned vision-language models to outperform several proprietary systems on external benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By deploying a modular generation process that coordinates several language models through cross-model inspiration and collective filtering, the authors produce a dataset of table images and associated reasoning questions that, when used for fine-tuning, enables models to generalize effectively to independent benchmarks and surpass multiple proprietary vision-language models.
What carries the argument
The multi-model collaborative pipeline that assigns distinct roles to different language models for generation, validation, and inspiration, using stronger models to seed ideas and an LLM jury to ensure quality and diversity in the resulting table images and questions.
If this is right
- Models fine-tuned on the dataset maintain robust performance across different table reasoning tasks outside the original data.
- The synthetic dataset can be generated at low cost under 100 USD for the initial scale.
- The open pipeline allows replication and expansion to create even larger collections of table reasoning examples.
- Fine-tuned models can handle complex visual structures in tables that challenge current commercial systems.
Where Pith is reading between the lines
- This method of having models inspire one another could apply to generating training data for other visual reasoning domains like graphs or forms.
- If the generated questions capture real reasoning demands, similar pipelines might reduce reliance on human-annotated datasets for multimodal tasks.
- Further scaling could test whether such synthetic data supports training larger models specifically for document understanding.
Load-bearing premise
The data produced by the collaborative language model pipeline is diverse enough and free enough of artificial patterns to represent the kinds of tables and questions that appear in real documents and images.
What would settle it
A direct comparison showing that models fine-tuned on Visual-TableQA no longer outperform proprietary models when evaluated on a set of table images taken from actual scanned documents or web pages with typical rendering variations and noise.
Figures
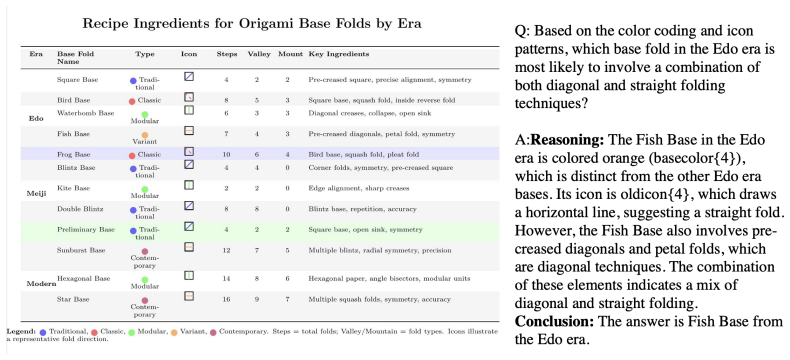




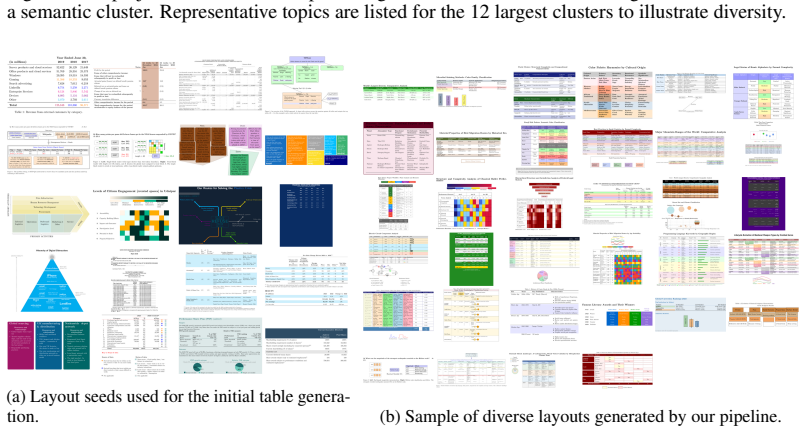





read the original abstract
Visual reasoning over structured data such as tables is a critical capability for modern vision-language models (VLMs), yet current benchmarks remain limited in scale, diversity, or reasoning depth, especially when it comes to rendered table images. Addressing this gap, we introduce Visual-TableQA, a large-scale, open-domain multimodal dataset specifically designed to evaluate and enhance visual reasoning over complex tabular data. Our generation pipeline is modular, scalable, and fully autonomous, involving multiple reasoning LLMs collaborating across distinct roles: generation, validation, and inspiration. Visual-TableQA comprises 2.5k richly structured LaTeX-rendered tables and 6k reasoning-intensive QA pairs, all produced at a cost of under USD 100. To promote diversity and creativity, our pipeline performs multi-model collaborative data generation via cross-model prompting ('inspiration') and LLM-jury filtering. Stronger models seed layouts and topics that weaker models elaborate, collectively distilling diverse reasoning patterns and visual structures into the dataset. Empirical results show that models fine-tuned on Visual-TableQA generalize robustly to external benchmarks, outperforming several proprietary models despite the dataset's synthetic nature. The full pipeline and resources are publicly available at https://github.com/AI-4-Everyone/Visual-TableQA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Visual-TableQA, an open-domain benchmark for visual reasoning over table images. It consists of 2.5k LaTeX-rendered tables and 6k QA pairs generated through a modular pipeline using multiple LLMs in collaborative roles for generation, validation, and inspiration via cross-model prompting. The central claim is that fine-tuning VLMs on this synthetic dataset leads to robust generalization on external benchmarks, with outperformance over several proprietary models.
Significance. If the empirical results hold, this provides a low-cost, scalable approach to generating diverse and reasoning-intensive table image data, addressing limitations in existing benchmarks for VLM visual reasoning on structured data. The public availability of the pipeline and dataset is a notable strength.
major comments (2)
- [§3] The data generation pipeline relies exclusively on clean LaTeX renders without incorporating or ablating real-world visual perturbations (e.g., perspective distortion, compression artifacts, irregular alignments). This is load-bearing for the generalization claim, as it may limit the dataset's ability to exercise the same visual parsing demands as real table images.
- [§4] The reported outperformance on external benchmarks lacks sufficient detail on exact metrics, baseline implementations, statistical tests, and error analysis to fully substantiate the robustness claim, particularly given the synthetic nature of the training data.
minor comments (2)
- [Abstract] The cost 'under USD 100' is stated but no itemized breakdown or comparison to alternative generation methods is provided in the main text.
- [§2] Related work section could benefit from more explicit comparison to other synthetic table datasets in terms of scale and reasoning depth.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and indicate the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [§3] The data generation pipeline relies exclusively on clean LaTeX renders without incorporating or ablating real-world visual perturbations (e.g., perspective distortion, compression artifacts, irregular alignments). This is load-bearing for the generalization claim, as it may limit the dataset's ability to exercise the same visual parsing demands as real table images.
Authors: We agree that the exclusive use of clean LaTeX renders represents a limitation for claims about robustness to real-world visual conditions. The pipeline was intentionally designed around clean renders to emphasize diversity in table structure and multi-step reasoning rather than low-level image degradation. To address the concern, we will add a new subsection in the Experiments section reporting an ablation where controlled perturbations (perspective distortion, JPEG compression, and alignment noise) are applied to a held-out portion of the test tables. We will also expand the Limitations section to explicitly discuss the scope of the generalization claims and note that future extensions will incorporate more varied real-world captures. revision: partial
-
Referee: [§4] The reported outperformance on external benchmarks lacks sufficient detail on exact metrics, baseline implementations, statistical tests, and error analysis to fully substantiate the robustness claim, particularly given the synthetic nature of the training data.
Authors: We acknowledge that the current presentation of results is high-level. In the revised manuscript we will expand the evaluation section to report per-benchmark accuracy and F1 scores with standard deviations across three random seeds, provide the exact prompting templates and API versions used for all proprietary baselines, include paired statistical significance tests, and add a qualitative error analysis that categorizes failure modes on the external sets. These additions will be placed in the main text or a dedicated appendix to allow readers to assess the strength of the generalization results. revision: yes
Circularity Check
No significant circularity detected; evaluation chain is independent of generation inputs.
full rationale
The paper presents an empirical dataset construction pipeline using multi-LLM collaboration to produce 2.5k LaTeX-rendered tables and 6k QA pairs, followed by fine-tuning and testing on external benchmarks. No mathematical derivations, equations, or self-referential definitions appear in the provided text. The central claim of robust generalization rests on separate external evaluation sets rather than any fitted parameter or generation output being renamed as a prediction. Self-citations are absent from the load-bearing steps, and the pipeline is described as autonomous without reducing results to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can effectively collaborate across generation, validation, and inspiration roles to produce diverse, reasoning-intensive QA pairs for rendered table images.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our generation pipeline is modular, scalable, and fully autonomous, involving multiple reasoning LLMs collaborating across distinct roles: generation, validation, and inspiration. Visual-TableQA comprises 2.5k richly structured LaTeX-rendered tables and 6k reasoning-intensive QA pairs
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Empirical results show that models fine-tuned on Visual-TableQA generalize robustly to external benchmarks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
TableVision: A Large-Scale Benchmark for Spatially Grounded Reasoning over Complex Hierarchical Tables
TableVision benchmark shows explicit spatial grounding recovers MLLM reasoning on hierarchical tables, delivering 12.3% accuracy improvement through a decoupled perception-reasoning framework.
Reference graph
Works this paper leans on
-
[1]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Magid: An automated pipeline for generating synthetic multi-modal datasets
Hossein Aboutalebi, Hwanjun Song, Yusheng Xie, Arshit Gupta, Justin Sun, Hang Su, Igor Shalyminov, Nikolaos Pappas, Siffi Singh, and Saab Mansour. Magid: An automated pipeline for generating synthetic multi-modal datasets. arXiv preprint arXiv:2403.03194, 2024
-
[3]
Pranav Agarwal and Ioana Ciuc a . Supernova event dataset: Interpreting large language model's personality through critical event analysis. arXiv preprint arXiv:2506.12189, 2025
-
[4]
Model card addendum: Claude 3.5 haiku and upgraded claude 3.5 sonnet
Anthropic . Model card addendum: Claude 3.5 haiku and upgraded claude 3.5 sonnet. https://assets.anthropic.com/m/1cd9d098ac3e6467/original/Claude-3-Model-Card-October-Addendum.pdf, 2024. Accessed: 2025-08-01
work page 2024
-
[5]
Claude opus 4 & claude sonnet 4 — system card
Anthropic . Claude opus 4 & claude sonnet 4 — system card. https://www.anthropic.com/claude-4-system-card, May 2025. Accessed: 2025-08-01
work page 2025
-
[6]
Qwen-vl: A versatile vision-language model with image, text, and box comprehension
Shaohan Chen, Yujia Zhang, Xiangpeng Cao, Shaolei He, Chen Zhao, Zhihua Liu, Chongming Li, Jing Liu, Qiang Liu, Fan Liu, et al. Qwen-vl: A versatile vision-language model with image, text, and box comprehension. arXiv preprint arXiv:2403.18751, 2024 a . URL https://arxiv.org/abs/2403.18751
-
[7]
Tabfact: A large-scale dataset for table-based fact verification
Wenhu Chen, Hongmin Wang, Jianshu Chen, Yunkai Zhang, Hong Wang, Shiyang Li, Xiyou Zhou, and William Yang Wang. Tabfact: A large-scale dataset for table-based fact verification. In International Conference on Learning Representations, 2020 a . URL https://openreview.net/forum?id=rkeJRhNYDH
work page 2020
-
[8]
H ybrid QA : A dataset of multi-hop question answering over tabular and textual data
Wenhu Chen, Hanwen Zha, Zhiyu Chen, Wenhan Xiong, Hong Wang, and William Yang Wang. H ybrid QA : A dataset of multi-hop question answering over tabular and textual data. In Trevor Cohn, Yulan He, and Yang Liu (eds.), Findings of the Association for Computational Linguistics: EMNLP 2020, pp.\ 1026--1036, Online, November 2020 b . Association for Computatio...
-
[9]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 24185--24198, 2024 b
work page 2024
-
[10]
DeepSeek-AI . DeepSeek-R1-Distill-Qwen-32B . https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B, 2025. Model card. Accessed: 2025-08-01
work page 2025
-
[11]
Xingyu Fu, Minqian Liu, Zhengyuan Yang, John Corring, Yijuan Lu, Jianwei Yang, Dan Roth, Dinei Florencio, and Cha Zhang. Refocus: Visual editing as a chain of thought for structured image understanding. arXiv preprint arXiv:2501.05452, 2025
-
[12]
Roscoe: A suite of metrics for scoring step-by-step reasoning
Olga Golovneva, Moya Peng Chen, Spencer Poff, Martin Corredor, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz. Roscoe: A suite of metrics for scoring step-by-step reasoning. In The Eleventh International Conference on Learning Representations
-
[13]
Google . Gemini 2.0 flash: Model card. https://storage.googleapis.com/model-cards/documents/gemini-2-flash.pdf, 2025 a . Published: 2025-04-15. Accessed: 2025-08-01
work page 2025
-
[14]
Google . Gemini 2.5 flash: Model card. https://storage.googleapis.com/model-cards/documents/gemini-2.5-flash.pdf, 2025 b . Updated: 2025-06-26. Accessed: 2025-08-01
work page 2025
-
[15]
Google . Gemini 2.5 pro: Model card. https://storage.googleapis.com/model-cards/documents/gemini-2.5-pro.pdf, 2025 c . Model card. Last updated: 2025-06-27. Accessed: 2025-08-01
work page 2025
-
[16]
Distill visual chart reasoning ability from llms to mllms
Wei He, Zhiheng Xi, Wanxu Zhao, Xiaoran Fan, Yiwen Ding, Zifei Shan, Tao Gui, Qi Zhang, and Xuanjing Huang. Distill visual chart reasoning ability from llms to mllms
-
[17]
Lora: Low-rank adaptation of large language models
Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations
-
[18]
Texpert: A multi-level benchmark for evaluating latex code generation by llms
Sahil Kale and Vijaykant Nadadur. Texpert: A multi-level benchmark for evaluating latex code generation by llms. arXiv preprint arXiv:2506.16990, 2025
-
[19]
AIT-QA : Q uestion answering dataset over complex tables in the airline industry
Yannis Katsis, Saneem Chemmengath, Vishwajeet Kumar, Samarth Bharadwaj, Mustafa Canim, Michael Glass, Alfio Gliozzo, Feifei Pan, Jaydeep Sen, Karthik Sankaranarayanan, and Soumen Chakrabarti. AIT-QA : Q uestion answering dataset over complex tables in the airline industry. In Anastassia Loukina, Rashmi Gangadharaiah, and Bonan Min (eds.), Proceedings of t...
- [20]
-
[21]
arXiv preprint arXiv:2404.19205 , year =
Yoonsik Kim, Moonbin Yim, and Ka Yeon Song. Tablevqa-bench: A visual question answering benchmark on multiple table domains. arXiv preprint arXiv:2404.19205, 2024
-
[22]
Thirteen ways to look at the correlation coefficient
Joseph Lee Rodgers and W Alan Nicewander. Thirteen ways to look at the correlation coefficient. The American Statistician, 42 0 (1): 0 59--66, 1988
work page 1988
-
[23]
Smir: Efficient synthetic data pipeline to improve multi-image reasoning
Andrew Li, Rahul Thapa, Rahul Chalamala, Qingyang Wu, Kezhen Chen, and James Zou. Smir: Efficient synthetic data pipeline to improve multi-image reasoning. arXiv preprint arXiv:2501.03675, 2025
-
[24]
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Feng Li, Renrui Zhang, Hao Zhang, Yuanhan Zhang, Bo Li, Wei Li, Zejun Ma, and Chunyuan Li. Llava-next-interleave: Tackling multi-image, video, and 3d in large multimodal models. arXiv preprint arXiv:2407.07895, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Chartqa: A benchmark for question answering about charts with visual and logical reasoning
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning
-
[26]
Minesh Mathew, Dimosthenis Karatzas, R Manmatha, and CV Jawahar. Docvqa: A dataset for vqa on document images. corr abs/2007.00398 (2020). arXiv preprint arXiv:2007.00398, 2020
-
[27]
Llama 4 Maverick 17B-128E Instruct
Meta AI . Llama 4 Maverick 17B-128E Instruct . https://huggingface.co/meta-llama/Llama-4-Maverick-17B-128E-Instruct, 2025. Model card. Accessed: 2025-08-01
work page 2025
-
[28]
Mistral Small 3.1 24B Instruct
Mistral AI . Mistral Small 3.1 24B Instruct . https://huggingface.co/mistralai/Mistral‑Small‑3.1‑24B‑Instruct‑2503, 2025. Model card. Accessed: 2025‑08‑01
work page 2025
-
[29]
OpenAI. GPT-4o . https://openai.com/index/gpt-4o, 2024. Accessed: 2025-07-30
work page 2024
-
[30]
OpenAI . GPT-4.1 . https://openai.com/index/gpt-4-1/, 2025 a . Accessed: 2025-08-01
work page 2025
-
[31]
OpenAI . GPT-4o-mini . https://platform.openai.com/docs/models/gpt-4o, 2025 b . Accessed: 2025-08-01
work page 2025
-
[32]
OpenAI. OpenAI o3 Reasoning Model . https://openai.com/index/introducing-o3-and-o4-mini/, 2025. Accessed: 2025‑07‑31
work page 2025
-
[33]
Panupong Pasupat and Percy Liang. Compositional semantic parsing on semi-structured tables. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp.\ 1470--1480, Beijing, China, July 2015. Association for Computational L...
-
[34]
Qwen Team . Qwen3-30B-A3B . https://huggingface.co/Qwen/Qwen3-30B-A3B, 2025 a . Model card. Accessed: 2025-08-01
work page 2025
-
[35]
Qwen Team . Qwen3-Qwen3-32B . https://huggingface.co/Qwen/Qwen3-32B, 2025 b . Model card. Accessed: 2025-08-01
work page 2025
-
[36]
Qwen Team . Qwen3-QwQ-32B . https://huggingface.co/Qwen/QwQ-32B, 2025 c . Model card. Accessed: 2025-08-01
work page 2025
-
[37]
Reka AI . Reka Flash 3 . https://huggingface.co/RekaAI/reka-flash-3, 2025. Model card. Accessed: 2025-08-01
work page 2025
-
[38]
Z. Z. Ren, Zhihong Shao, Junxiao Song, Huajian Xin, Haocheng Wang, Wanjia Zhao, Liyue Zhang, Zhe Fu, Qihao Zhu, Dejian Yang, Z. F. Wu, Zhibin Gou, Shirong Ma, Hongxuan Tang, Yuxuan Liu, Wenjun Gao, Daya Guo, and Chong Ruan. Deepseek-prover-v2: Advancing formal mathematical reasoning via reinforcement learning for subgoal decomposition. arXiv preprint arXi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.21801 2025
-
[39]
Multimodal \ qa \ : complex question answering over text, tables and images
Alon Talmor, Ori Yoran, Amnon Catav, Dan Lahav, Yizhong Wang, Akari Asai, Gabriel Ilharco, Hannaneh Hajishirzi, and Jonathan Berant. Multimodal \ qa \ : complex question answering over text, tables and images. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=ee6W5UgQLa
work page 2021
-
[40]
Qwen Team. Qwen2.5-vl, January 2025. URL https://qwenlm.github.io/blog/qwen2.5-vl/
work page 2025
-
[41]
Deepseek-r1t-chimera, April 2025
TNG Technology Consulting GmbH . Deepseek-r1t-chimera, April 2025. URL https://huggingface.co/tngtech/DeepSeek-R1T-Chimera
work page 2025
-
[42]
URL https://huggingface.co/datasets/cmarkea/table-vqa
Cyrile Delestre Tom Agonnoude, 2024. URL https://huggingface.co/datasets/cmarkea/table-vqa
work page 2024
-
[43]
A graph-based synthetic data pipeline for scaling high-quality reasoning instructions
Jiankang Wang, Jianjun Xu, Xiaorui Wang, Yuxin Wang, Mengting Xing, Shancheng Fang, Zhineng Chen, Hongtao Xie, and Yongdong Zhang. A graph-based synthetic data pipeline for scaling high-quality reasoning instructions. CoRR, 2024 a
work page 2024
-
[44]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024 b . URL https://openreview.net/forum?id=QWTCcxMpPA
work page 2024
-
[45]
Grok 3 beta — the age of reasoning agents
xAI . Grok 3 beta — the age of reasoning agents. https://x.ai/news/grok-3, 2025. Accessed: 2025-08-01
work page 2025
-
[46]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[47]
Xinyi Zheng, Douglas Burdick, Lucian Popa, Xu Zhong, and Nancy Xin Ru Wang. Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. In 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pp.\ 697--706. IEEE, 2021
work page 2021
-
[48]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Victor Zhong, Caiming Xiong, and Richard Socher. Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR, abs/1709.00103, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Towards complex document understanding by discrete reasoning
Fengbin Zhu, Wenqiang Lei, Fuli Feng, Chao Wang, Haozhou Zhang, and Tat-Seng Chua. Towards complex document understanding by discrete reasoning. In Proceedings of the 30th ACM International Conference on Multimedia, pp.\ 4857--4866, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.