Amoeba: Runtime Tensor Parallel Transformation for LLM Inference Services
Pith reviewed 2026-05-18 14:56 UTC · model grok-4.3
The pith
Amoeba enables runtime adjustment of tensor parallelism in LLM inference to better match request context lengths and increase throughput.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
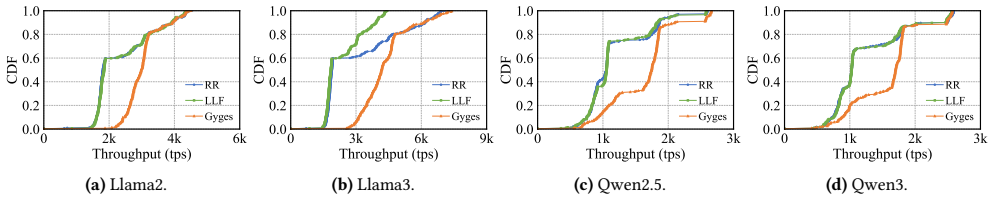
Amoeba proposes a runtime tensor parallel transformation for online LLM inference services that adaptively adjusts the TP degree of running instances to align with the dynamics of incoming requests. Long-context requests benefit from higher TP to support larger KV caches, whereas short-context requests favor lower TP to enhance concurrency. Real-world trace evaluations indicate throughput gains of 1.75x to 6.57x compared to state-of-the-art solutions.
What carries the argument
Runtime tensor parallel transformation that reconfigures the distribution of model computations across devices while the instances continue serving requests.
Load-bearing premise
The overhead of performing these runtime transformations remains low enough that net throughput gains stay positive even when context-length patterns change frequently.
What would settle it
A workload trace in which frequent switches between short and long context requests cause transformation overhead to drop overall throughput below that of any fixed static parallelism setting.
Figures











read the original abstract
In Large Language Model (LLM) inference services, it is challenging to make a parallelism strategy configuration, to efficiently process the requests of variance context lengths. Requests of long context require high degree of parallelism to provide more memory for Key-Value (KV) Cache, while requests of short context prefer low degree of parallelism to increase concurrency, thus improving throughput. To maintain high throughput while supporting large context lengths on demand, we propose Amoeba, a runtime Tensor Parallel (TP) transformation for online LLM inference services, which adaptively adjusts the TP of running instances to align with the dynamics of incoming requests. Evaluations using real-world traces show that Amoeba improves throughput by 1.75x-6.57x compared to state-of-the-art solutions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Amoeba, a runtime system that performs online tensor-parallelism (TP) degree transformations on live LLM inference instances. It claims to dynamically increase TP for long-context requests (to accommodate larger KV caches) and decrease TP for short-context requests (to raise concurrency), yielding 1.75×–6.57× throughput gains over prior static or coarse-grained baselines on real-world traces.
Significance. If the transformation overhead remains low under realistic request dynamics, Amoeba would address a practical bottleneck in production LLM serving by enabling fine-grained, instance-level adaptation without restarts. The reported speedups indicate potential for improved GPU utilization in variable-length workloads, which is a common pain point in inference clusters.
major comments (2)
- [§5] §5 (Evaluation) and abstract: throughput numbers (1.75×–6.57×) are stated without any reported measurements of per-transformation latency, KV-cache migration cost, all-to-all communication volume, or the observed frequency of TP changes in the traces. Because the central claim rests on net gains after overhead, the absence of these data makes it impossible to verify whether the reported improvements survive the skeptic’s concern about frequent context-length shifts.
- [§3.2] §3.2 (TP Transformation Protocol): the description of weight repartitioning and KV-cache redistribution does not quantify temporary throughput drop, synchronization barriers, or memory pressure during the transition. These quantities are load-bearing for the claim that adaptation remains beneficial when request patterns vary unpredictably.
minor comments (2)
- [Figure 4] Figure 4: axis labels and legend do not clearly distinguish the three baselines; a reader cannot immediately map curves to the systems named in the text.
- [§2.1] §2.1: the notation for TP degree (e.g., “TP-4”) is introduced without an explicit definition or reference to the underlying model-parallelism formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that greater transparency on transformation overheads is needed to fully substantiate the net throughput claims and have revised the manuscript to address both major comments.
read point-by-point responses
-
Referee: [§5] §5 (Evaluation) and abstract: throughput numbers (1.75×–6.57×) are stated without any reported measurements of per-transformation latency, KV-cache migration cost, all-to-all communication volume, or the observed frequency of TP changes in the traces. Because the central claim rests on net gains after overhead, the absence of these data makes it impossible to verify whether the reported improvements survive the skeptic’s concern about frequent context-length shifts.
Authors: We acknowledge the value of explicitly reporting these quantities. The end-to-end throughput results already incorporate all transformation costs because they were measured on live instances processing the real-world traces. To make the overheads visible, we will add a dedicated subsection in §5 with new measurements of per-transformation latency, KV-cache migration cost, all-to-all communication volume, and the observed frequency of TP changes. These data will be presented in additional tables and figures so readers can directly assess net gains. revision: yes
-
Referee: [§3.2] §3.2 (TP Transformation Protocol): the description of weight repartitioning and KV-cache redistribution does not quantify temporary throughput drop, synchronization barriers, or memory pressure during the transition. These quantities are load-bearing for the claim that adaptation remains beneficial when request patterns vary unpredictably.
Authors: We agree that quantifying these transient effects strengthens the protocol description. We will expand §3.2 with measured values for temporary throughput drop, synchronization barrier duration, and peak memory pressure during weight repartitioning and KV-cache redistribution. Additional micro-benchmark results collected under varying request arrival patterns will be included to show that these costs remain low enough for the adaptation to remain beneficial. revision: yes
Circularity Check
No significant circularity; empirical system evaluation stands on external comparisons
full rationale
The paper presents Amoeba as a runtime system for dynamic tensor-parallelism adjustment in LLM serving, with claims resting on throughput measurements from real-world traces versus baselines. No equations, fitted parameters, or derivations appear in the provided abstract or description; the central result is an empirical performance delta (1.75x-6.57x) rather than any self-referential definition or prediction. Self-citations, if present, are not load-bearing for the core claim, which remains falsifiable against independent implementations and traces. This is the standard non-circular outcome for a systems paper whose value is demonstrated by measurement rather than internal construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose Cross-Instance Parallelism Transformation (Gyges), which adaptively adjusts the parallelism strategies of running instances to align with the dynamics of incoming requests.
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
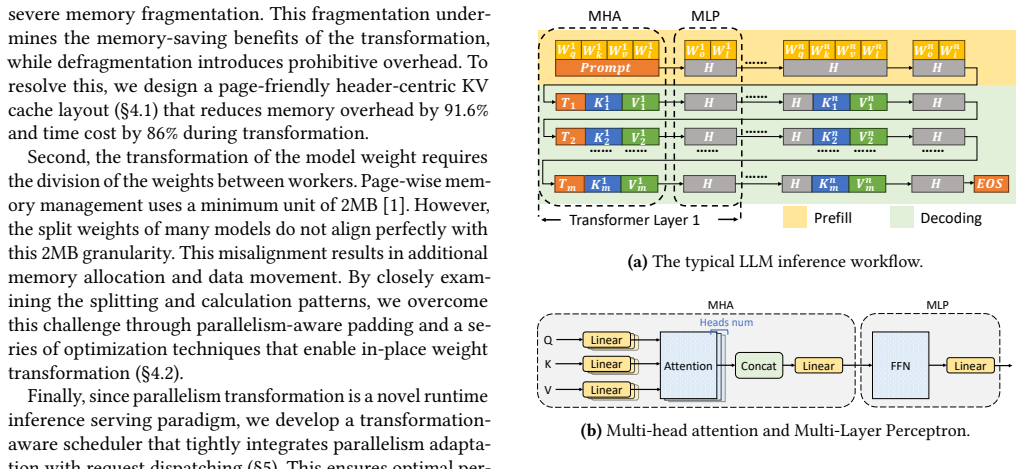
page-friendly, header-centric KV cache layout to accelerate KV cache transformations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Foundry: Template-Based CUDA Graph Context Materialization for Fast LLM Serving Cold Start
Foundry uses template-based CUDA graph context materialization to reduce LLM serving cold-start latency by up to 99% while preserving CUDA graph throughput gains.
Reference graph
Works this paper leans on
-
[1]
2024. Virtual memory management minimum granularity.https: //forums.developer.nvidia.com/t/virtual-memory-management- minimum-granularity/268699. (2024)
work page 2024
-
[2]
AMD ROCM Software.https://www.amd.com/en/products/so ftware/rocm.html
2025. AMD ROCM Software.https://www.amd.com/en/products/so ftware/rocm.html. (2025)
work page 2025
-
[3]
CUDA Toolkit.https://developer.nvidia.com/cuda-toolkit
2025. CUDA Toolkit.https://developer.nvidia.com/cuda-toolkit. (2025)
work page 2025
-
[4]
Llama: Industry Leading, Open-Source AI.https://www.llama
2025. Llama: Industry Leading, Open-Source AI.https://www.llama. com/. (2025)
work page 2025
-
[5]
2025. NVIDIA Triton Inference Server.https://docs.nvidia.com/deep learning/triton-inference-server/user-guide/docs/index.html. (2025)
work page 2025
-
[6]
Qwen: Qwickly forging AGI, enhancing intelligence.https: //qwenlm.github.io/
2025. Qwen: Qwickly forging AGI, enhancing intelligence.https: //qwenlm.github.io/. (2025)
work page 2025
-
[7]
2025. SGLang is a fast serving framework for large language models and vision language models.https://github.com/sgl-project/sglang. (2025)
work page 2025
-
[8]
Welcome to vLLM: Easy, fast, and cheap LLM serving for every- one.https://docs.vllm.ai/en/latest/
2025. Welcome to vLLM: Easy, fast, and cheap LLM serving for every- one.https://docs.vllm.ai/en/latest/. (2025)
work page 2025
-
[9]
Rongxin Cheng, Yuxin Lai, Xingda Wei, Rong Chen, and Haibo Chen
- [10]
-
[11]
Krishna Teja Chitty-Venkata, Siddhisanket Raskar, Bharat Kale, Farah Ferdaus, Aditya Tanikanti, Ken Raffenetti, Valerie Taylor, Murali Emani, and Venkatram Vishwanath. 2024. LLM-Inference-Bench: Inference Benchmarking of Large Language Models on AI Acceler- ators . In SC24-W: Workshops of the International Conference for High Performance Computing, Networ...
-
[12]
Daniel Crankshaw, Xin Wang, Guilio Zhou, Michael J. Franklin, Joseph E. Gonzalez, and Ion Stoica. 2017. Clipper: A Low-Latency Online Prediction Serving System. In 14th USENIX Symposium on Networked Systems Design and Implementation (NSDI 17). USENIX Association, Boston, MA, 613–627.https://www.usenix.org/conferenc e/nsdi17/technical-sessions/presentation...
work page 2017
-
[13]
Weihao Cui, Han Zhao, Quan Chen, Hao Wei, Zirui Li, Deze Zeng, Chao Li, and Minyi Guo. 2022. DVABatch: Diversity-aware Multi- Entry Multi-Exit Batching for Efficient Processing of DNN Services on GPUs. In 2022 USENIX Annual Technical Conference (USENIX ATC 22). USENIX Association, Carlsbad, CA, 183–198.https://www.usenix .org/conference/atc22/presentation/cui
work page 2022
-
[14]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[15]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. (2022). arXiv:cs.LG/2205.14135https://arxiv.org/abs/22 05.14135 11
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Jingqi Feng, Yukai Huang, Rui Zhang, Sicheng Liang, Ming Yan, and Jie Wu. 2025. WindServe: Efficient Phase-Disaggregated LLM Serv- ing with Stream-based Dynamic Scheduling. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25). Association for Computing Machinery, New York, NY, USA, 1283–1295.https://doi.org/10.1145...
-
[17]
Ke Hong, Guohao Dai, Jiaming Xu, Qiuli Mao, Xiuhong Li, Jun Liu, Kangdi Chen, Yuhan Dong, and Yu Wang. 2024. FlashDecoding++: Faster Large Language Model Inference with Asynchronization, Flat GEMM Optimization, and Heuristics. In Proceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. De Sa (Eds.), Vol. 6. 148–161.https://proceeding...
work page 2024
-
[18]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Sto- ica. 2023. Efficient Memory Management for Large Language Model Serving with PagedAttention. (2023). arXiv:cs.LG/2309.06180https: //arxiv.org/abs/2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Zhuohan Li, Lianmin Zheng, Yinmin Zhong, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving. In 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). USENIX Association, Boston, MA,...
work page 2023
-
[20]
Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu, Shen Li, Zhigang Ji, Tao Xie, Yong Li, and Wei Lin. 2024. Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache. (2024). arXiv:cs.DC/2401.02669https://arxiv.org/abs/2401.02669
-
[21]
Anand Padmanabha Iyer, Mingyu Guan, Yinwei Dai, Rui Pan, Swapnil Gandhi, and Ravi Netravali. 2024. Improving DNN Inference Through- put Using Practical, Per-Input Compute Adaptation. In Proceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP ’24). Association for Computing Machinery, New York, NY, USA, 624–639.https://doi.org/10...
-
[22]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. In 2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA). 118–132.https://doi.org/10.1109/ISCA59077.2024.00019
-
[23]
Ramya Prabhu, Ajay Nayak, Jayashree Mohan, Ramachandran Ram- jee, and Ashish Panwar. 2025. vAttention: Dynamic Memory Man- agement for Serving LLMs without PagedAttention. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1 (ASPLOS ’25). Association for Computing Machin...
-
[24]
Haichen Shen, Lequn Chen, Yuchen Jin, Liangyu Zhao, Bingyu Kong, Matthai Philipose, Arvind Krishnamurthy, and Ravi Sundaram. 2019. Nexus: a GPU cluster engine for accelerating DNN-based video analysis. In Proceedings of the 27th ACM Symposium on Operating Systems Principles (SOSP ’19). Association for Computing Machinery, New York, NY, USA, 322–337.https:...
-
[25]
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang
-
[26]
In Proceedings of the 40th International Conference on Machine Learning (ICML’23)
FlexGen: high-throughput generative inference of large language models with a single GPU. In Proceedings of the 40th International Conference on Machine Learning (ICML’23). JMLR.org, Article 1288, 23 pages
- [27]
-
[28]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: dynamic scheduling for large language model serving. In Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation (OSDI’24). USENIX Association, USA, Article 10, 19 pages
work page 2024
-
[29]
Xiaohui Wang, Ying Xiong, Yang Wei, Mingxuan Wang, and Lei Li
- [30]
-
[31]
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, and Xin Jin. 2024. LoongServe: Efficiently Serving Long-Context Large Language Models with Elastic Sequence Parallelism. InProceedings of the ACM SIGOPS 30th Symposium on Operating Systems Principles (SOSP ’24). Association for Computing Machinery, New York, NY, USA, 640–654.https://doi.org/10...
-
[32]
Bingyang Wu, Yinmin Zhong, Zili Zhang, Shengyu Liu, Fangyue Liu, Yuanhang Sun, Gang Huang, Xuanzhe Liu, and Xin Jin. 2024. Fast Distributed Inference Serving for Large Language Models. (2024). arXiv:cs.LG/2305.05920https://arxiv.org/abs/2305.05920
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX Association, Carlsbad, CA, 521–538.https://www.usenix.org/confere nce/osdi22/presentation/yu
work page 2022
-
[34]
Hong Zhang, Yupeng Tang, Anurag Khandelwal, and Ion Stoica
-
[35]
In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23)
SHEPHERD: Serving DNNs in the Wild. In 20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). USENIX Association, Boston, MA, 787–808.https://www. usenix.org/conference/nsdi23/presentation/zhang-hong
-
[36]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. 2022. Alpa: Automat- ing Inter- and Intra-Operator Parallelism for Distributed Deep Learn- ing. In 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). USENIX...
work page 2022
-
[37]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: disaggregating prefill and decoding for goodput-optimized large language model serving. In Proceedings of the 18th USENIX Conference on Operating Systems Design and Implementation (OSDI’24). USENIX Association, USA, Article 11, 18 pages. 12
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.