Multi-Modal Manipulation via Multi-Modal Policy Consensus
Pith reviewed 2026-05-18 11:47 UTC · model grok-4.3
The pith
A robotic manipulation policy factorizes into modality-specific diffusion models combined via a learned consensus router.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
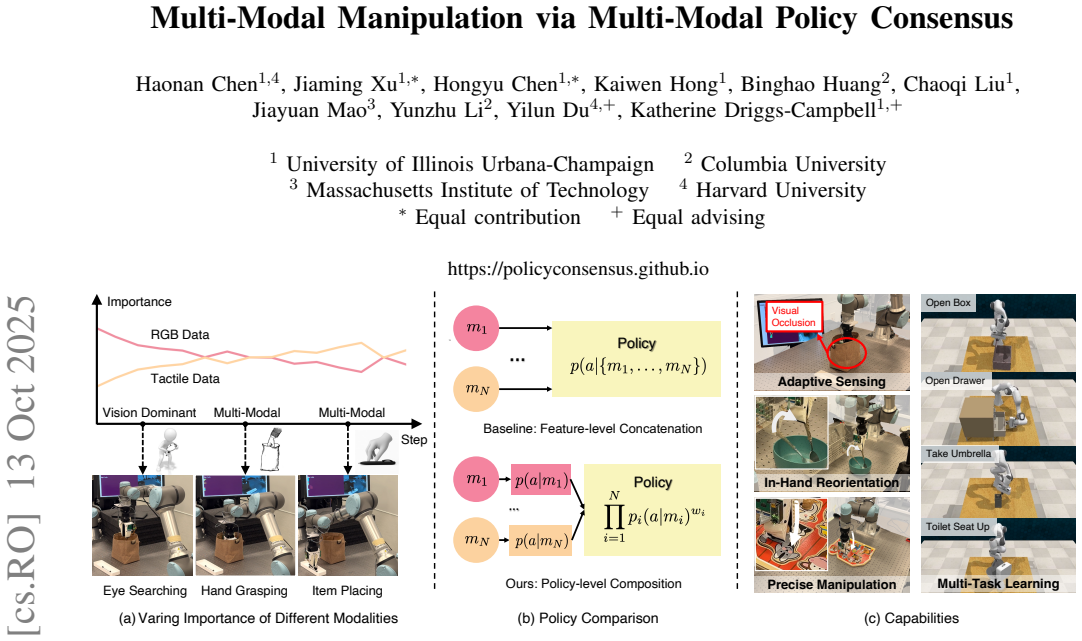
Our method factorizes the policy into a set of diffusion models, each specialized for a single representation, and employs a router network that learns consensus weights to adaptively combine their contributions, enabling incremental addition of new representations. Evaluations on simulated manipulation tasks in RLBench as well as real-world tasks such as occluded object picking, in-hand spoon reorientation, and puzzle insertion demonstrate significant outperformance over feature-concatenation baselines on scenarios requiring multimodal reasoning, with further robustness to physical perturbations and sensor corruption shown via perturbation-based importance analysis revealing adaptive shifts
What carries the argument
the router network that learns consensus weights to adaptively combine contributions from modality-specific diffusion models
If this is right
- The policy supports incremental incorporation of new sensory representations without retraining the entire system.
- Performance gains occur on contact-rich tasks where vision might otherwise dominate touch signals.
- Robustness is maintained under physical perturbations and sensor corruption.
- Importance analysis confirms adaptive weighting shifts between modalities during execution.
Where Pith is reading between the lines
- This factorization may enable automatic downweighting of faulty sensors without separate fault detection mechanisms.
- The consensus router could extend naturally to additional input types such as audio or force sensing in assembly scenarios.
- Scaling tests with four or more modalities would clarify whether consensus learning stays stable as the set grows.
Load-bearing premise
The router network successfully learns consensus weights that generalize across tasks and perturbations to produce the reported performance gains.
What would settle it
If new experiments on tasks with heavy visual occlusion and critical tactile requirements show no significant outperformance over feature-concatenation baselines, the value of the adaptive consensus weighting would be falsified.
Figures






read the original abstract
Effectively integrating diverse sensory modalities is crucial for robotic manipulation. However, the typical approach of feature concatenation is often suboptimal: dominant modalities such as vision can overwhelm sparse but critical signals like touch in contact-rich tasks, and monolithic architectures cannot flexibly incorporate new or missing modalities without retraining. Our method factorizes the policy into a set of diffusion models, each specialized for a single representation (e.g., vision or touch), and employs a router network that learns consensus weights to adaptively combine their contributions, enabling incremental of new representations. We evaluate our approach on simulated manipulation tasks in {RLBench}, as well as real-world tasks such as occluded object picking, in-hand spoon reorientation, and puzzle insertion, where it significantly outperforms feature-concatenation baselines on scenarios requiring multimodal reasoning. Our policy further demonstrates robustness to physical perturbations and sensor corruption. We further conduct perturbation-based importance analysis, which reveals adaptive shifts between modalities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a multi-modal policy for robotic manipulation by factorizing it into a set of diffusion models, each specialized for a single representation such as vision or touch. A router network learns consensus weights to adaptively combine the contributions from these models. This design is said to enable the incremental addition of new representations without retraining the entire policy, unlike feature concatenation approaches. The method is evaluated on simulated manipulation tasks in RLBench and real-world tasks including occluded object picking, in-hand spoon reorientation, and puzzle insertion, where it is reported to significantly outperform feature-concatenation baselines on scenarios requiring multimodal reasoning. Additional claims include robustness to physical perturbations and sensor corruption, supported by perturbation-based importance analysis revealing adaptive shifts between modalities.
Significance. Should the quantitative results and the incremental modality addition property be validated through appropriate experiments, this approach could provide a valuable framework for handling diverse sensory inputs in robotic policies. It addresses common issues with modality dominance in contact-rich tasks and offers potential for more flexible and scalable multi-modal systems in robotics.
major comments (2)
- [Abstract] The abstract asserts that the approach 'significantly outperforms feature-concatenation baselines' on RLBench and real tasks but supplies no quantitative metrics, error bars, ablation studies, or experimental protocol details, leaving the central claim without visible supporting evidence.
- [Abstract] The premise that the router enables incremental addition of new modalities without retraining the whole policy is central to the contribution but lacks any supporting experiment; the evaluations use fixed modality sets with no ablation or protocol for adding a new diffusion model post-training and updating only the router.
minor comments (1)
- [Abstract] There is a grammatical issue in 'enabling incremental of new representations'; it should read 'enabling incremental addition of new representations'.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment point by point below, indicating where we agree revisions are warranted and outlining the changes we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts that the approach 'significantly outperforms feature-concatenation baselines' on RLBench and real tasks but supplies no quantitative metrics, error bars, ablation studies, or experimental protocol details, leaving the central claim without visible supporting evidence.
Authors: We agree that the abstract would be strengthened by including key quantitative indicators to support the performance claim. The full manuscript already contains detailed results with success rates, standard deviations, error bars, and ablation studies in Sections 4 and 5. In the revised version we will update the abstract to report representative metrics (e.g., mean success rates and standard deviations on RLBench and the real-world tasks) while keeping the abstract concise. revision: yes
-
Referee: [Abstract] The premise that the router enables incremental addition of new modalities without retraining the whole policy is central to the contribution but lacks any supporting experiment; the evaluations use fixed modality sets with no ablation or protocol for adding a new diffusion model post-training and updating only the router.
Authors: The architecture factorizes the policy into independent modality-specific diffusion models whose outputs are combined by a router; this design permits a new diffusion model to be trained separately and integrated by updating only the router weights. While the current experiments evaluate fixed modality combinations to demonstrate overall performance, we acknowledge that an explicit incremental-addition experiment is absent. We will add such an experiment in the revision, training an initial policy on a subset of modalities and then introducing an additional modality while retraining only the router, to directly validate the claimed property. revision: yes
Circularity Check
No significant circularity; empirical architecture with no load-bearing derivations
full rationale
The paper presents an empirical method that factorizes policies into per-modality diffusion models combined via a learned router network. No equations, derivations, or first-principles results are described that reduce any claim to fitted parameters or self-referential definitions by construction. Evaluations on RLBench and real tasks are framed as direct performance comparisons against baselines, with no self-citation chains or uniqueness theorems invoked to force the architecture. The approach is self-contained as a proposed design tested on held-out scenarios.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our method factorizes the policy into a set of diffusion models, each specialized for a single representation ... and employs a router network that learns consensus weights to adaptively combine their contributions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Composing such policies corresponds to multiplying distributions, or equivalently summing their energies
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
TouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
TouchGuide improves contact-rich robot manipulation by steering diffusion or flow-matching visuomotor policies with tactile feasibility scores from a contrastively trained Contact Physical Model.
-
Flexible Multitask Learning with Factorized Diffusion Policy
A factorized modular diffusion policy improves fitting of multimodal robot actions and enables flexible task adaptation without catastrophic forgetting.
-
FlexiTac: A Low-Cost, Open-Source, Scalable Tactile Sensing Solution for Robotic Systems
FlexiTac is a scalable piezoresistive tactile sensing system with flexible FPC-Velostat-FPC pads and a 100 Hz multi-channel readout board that mounts on rigid or soft grippers and supports visuo-tactile learning.
-
Learning Versatile Humanoid Manipulation with Touch Dreaming
HTD, a multimodal transformer policy trained with behavioral cloning and touch dreaming to predict future tactile latents, achieves a 90.9% relative success rate improvement over baselines on five real-world contact-r...
Reference graph
Works this paper leans on
-
[1]
Robot sound interpretation: Combining sight and sound in learning-based control,
P. Chang, S. Liu, H. Chen, and K. Driggs-Campbell, “Robot sound interpretation: Combining sight and sound in learning-based control,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE Press, 2020, p. 5580–5587
work page 2020
-
[2]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg, “Making sense of vision and touch: Self- supervised learning of multimodal representations for contact-rich tasks,” in2019 International Conference on Robotics and Automation (ICRA). IEEE Press, 2019, p. 8943–8950
work page 2019
-
[3]
See, hear, and feel: Smart sensory fusion for robotic manipulation,
H. Li, Y . Zhang, J. Zhu, S. Wang, M. A. Lee, H. Xu, E. Adelson, L. Fei-Fei, R. Gao, and J. Wu, “See, hear, and feel: Smart sensory fusion for robotic manipulation,” inProceedings of The 6th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, K. Liu, D. Kulic, and J. Ichnowski, Eds., vol. 205. PMLR, 14–18 Dec 2023, pp. 1368–1378
work page 2023
-
[4]
More than a feeling: Learning to grasp and regrasp using vision and touch,
R. Calandra, A. Owens, D. Jayaraman, J. Lin, W. Yuan, J. Malik, E. H. Adelson, and S. Levine, “More than a feeling: Learning to grasp and regrasp using vision and touch,”IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 3300–3307, 2018
work page 2018
-
[5]
General in-hand object rotation with vision and touch,
H. Qi, B. Yi, S. Suresh, M. Lambeta, Y . Ma, R. Calandra, and J. Malik, “General in-hand object rotation with vision and touch,” inProceed- ings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., vol. 229. PMLR, 06–09 Nov 2023, pp. 2549–2564
work page 2023
-
[6]
Visuotactile-rl: Learning multimodal manipulation policies with deep reinforcement learning,
J. Hansen, F. Hogan, D. Rivkin, D. Meger, M. Jenkin, and G. Dudek, “Visuotactile-rl: Learning multimodal manipulation policies with deep reinforcement learning,” in2022 International Conference on Robotics and Automation (ICRA), 2022, pp. 8298–8304
work page 2022
-
[7]
Compositional visual generation with energy based models,
Y . Du, S. Li, and I. Mordatch, “Compositional visual generation with energy based models,” inAdvances in Neural Information Processing Systems, 2020
work page 2020
-
[8]
Compo- sitional visual generation with composable diffusion models,
N. Liu, S. Li, Y . Du, A. Torralba, and J. B. Tenenbaum, “Compo- sitional visual generation with composable diffusion models,”arXiv preprint arXiv:2206.01714, 2022
-
[9]
Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc,
Y . Du, C. Durkan, R. Strudel, J. B. Tenenbaum, S. Dieleman, R. Fer- gus, J. Sohl-Dickstein, A. Doucet, and W. Grathwohl, “Reduce, reuse, recycle: Compositional generation with energy-based diffusion models and mcmc,” 2024
work page 2024
-
[10]
Compositional generative modeling: A single model is not all you need,
Y . Du and L. Kaelbling, “Compositional generative modeling: A single model is not all you need,”arXiv preprint arXiv:2402.01103, 2024
-
[11]
Compositional diffusion-based continuous constraint solvers,
Z. Yang, J. Mao, Y . Du, J. Wu, J. B. Tenenbaum, T. Lozano-Pérez, and L. P. Kaelbling, “Compositional diffusion-based continuous constraint solvers,” inProceedings of The 7th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., vol. 229. PMLR, 06–09 Nov 2023, pp. 3242–3265
work page 2023
-
[12]
Rlbench: The robot learning benchmark & learning environment,
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison, “Rlbench: The robot learning benchmark & learning environment,” 2019
work page 2019
-
[13]
R. S. Johansson and G. Westling, “Roles of glabrous skin receptors and sensorimotor memory in automatic control of precision grip when lifting rougher or more slippery objects,”Experimental Brain Research, vol. 56, pp. 550–564, 2004
work page 2004
-
[14]
Robotic grasping and contact: a review,
A. Bicchi and V . R. Kumar, “Robotic grasping and contact: a review,” Proceedings 2000 ICRA. Millennium Conference. IEEE International Conference on Robotics and Automation. Symposia Proceedings (Cat. No.00CH37065), vol. 1, pp. 348–353 vol.1, 2000
work page 2000
-
[15]
Towards safe multi-level human-robot interaction in industrial tasks,
Z. Huang, Y .-J. Mun, H. Chen, Y . Xie, Y . Niu, X. Li, N. Zhong, H.-I. You, D. L. McPherson, and K. Driggs-Campbell, “Towards safe multi-level human-robot interaction in industrial tasks,”ArXiv, vol. abs/2308.03222, 2023
-
[16]
Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation,
S. Suresh, H. Qi, T. Wu, T. Fan, L. Pineda, M. Lambeta, J. Malik, M. Kalakrishnan, R. Calandra, M. Kaess, J. Ortiz, and M. Mukadam, “Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation,”Science Robotics, p. adl0628, 2024
work page 2024
-
[17]
V . Dave, F. Lygerakis, and E. Rueckert, “Multimodal visual-tactile rep- resentation learning through self-supervised contrastive pre-training,” arXiv preprint arXiv:2401.12024, 2024
-
[18]
Sim2real manipulation on unknown objects with tactile- based reinforcement learning,
E. Su, C. Jia, Y . Qin, W. Zhou, A. Macaluso, B. Huang, and X. Wang, “Sim2real manipulation on unknown objects with tactile- based reinforcement learning,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 9234–9241
work page 2024
-
[19]
Visuo-tactile transformers for manipulation,
Y . Chen, M. Van der Merwe, A. Sipos, and N. Fazeli, “Visuo-tactile transformers for manipulation,” in6th Annual Conference on Robot Learning, 2022
work page 2022
-
[20]
Robot synesthesia: In-hand manipulation with visuotactile sensing,
Y . Yuan, H. Che, Y . Qin, B. Huang, Z.-H. Yin, K.-W. Lee, Y . Wu, S.-C. Lim, and X. Wang, “Robot synesthesia: In-hand manipulation with visuotactile sensing,”arXiv preprint arXiv:2312.01853, 2023
-
[21]
3d vitac:learning fine-grained manipulation with visuo-tactile sensing,
B. Huang, Y . Wang, X. Yang, Y . Luo, and Y . Li, “3d vitac:learning fine-grained manipulation with visuo-tactile sensing,” inProceedings of Robotics: Conference on Robot Learning(CoRL), 2024
work page 2024
-
[22]
Learning to compose visual relations,
N. Liu, S. Li, Y . Du, J. B. Tenenbaum, and A. Torralba, “Learning to compose visual relations,” inAdvances in Neural Information Processing Systems, A. Beygelzimer, Y . Dauphin, P. Liang, and J. W. Vaughan, Eds., 2021
work page 2021
-
[23]
Composable energy policies for reactive motion generation and reinforcement learning,
J. Urain, A. Li, P. Liu, C. D’Eramo, and J. Peters, “Composable energy policies for reactive motion generation and reinforcement learning,” The International Journal of Robotics Research, vol. 42, no. 10, pp. 827–858, 2023
work page 2023
-
[24]
Energy-based Models are Zero-Shot Planners for Composi- tional Scene Rearrangement,
N. Gkanatsios, A. Jain, Z. Xian, Y . Zhang, C. Atkeson, and K. Fragki- adaki, “Energy-based Models are Zero-Shot Planners for Composi- tional Scene Rearrangement,” inRobotics: Science and Systems, 2023
work page 2023
-
[25]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Rep- resentations, 2021
work page 2021
-
[26]
Planning with diffusion for flexible behavior synthesis,
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” inInternational Conference on Machine Learning, 2022
work page 2022
-
[27]
Is Conditional Generative Modeling all you need for Decision-Making?
A. Ajay, Y . Du, A. Gupta, J. Tenenbaum, T. Jaakkola, and P. Agrawal, “Is conditional generative modeling all you need for decision- making?”arXiv preprint arXiv:2211.15657, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Generative trajectory stitching through diffusion composition,
Y . Luo, U. A. Mishra, Y . Du, and D. Xu, “Generative trajectory stitching through diffusion composition,” 2025
work page 2025
-
[29]
Improving Factuality and Reasoning in Language Models through Multiagent Debate
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch, “Improv- ing factuality and reasoning in language models through multiagent debate,”arXiv preprint arXiv:2305.14325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Generative skill chaining: Long-horizon skill planning with diffusion models,
U. A. Mishra, S. Xue, Y . Chen, and D. Xu, “Generative skill chaining: Long-horizon skill planning with diffusion models,” inConference on Robot Learning. PMLR, 2023, pp. 2905–2925
work page 2023
-
[31]
Compositional foundation models for hierarchical planning
A. Ajay, S. Han, Y . Du, S. Li, A. Gupta, T. Jaakkola, J. Tenen- baum, L. Kaelbling, A. Srivastava, and P. Agrawal, “Composi- tional foundation models for hierarchical planning,”arXiv preprint arXiv:2309.08587, 2023
-
[32]
Causal composition diffusion model for closed-loop traffic generation,
H. Lin, X. Huang, T. Phan-Minh, D. S. Hayden, H. Zhang, D. Zhao, S. Srinivasa, E. M. Wolff, and H. Chen, “Causal composition diffusion model for closed-loop traffic generation,”arXiv preprint arXiv:2412.17920, 2024
-
[33]
Human motion diffusion as a generative prior,
Y . Shafir, G. Tevet, R. Kapon, and A. H. Bermano, “Human motion diffusion as a generative prior,”arXiv preprint arXiv:2303.01418, 2023
-
[34]
Coma: Compositional human motion generation with multi-modal agents,
S. Sun, G. De Araujo, J. Xu, S. Zhou, H. Zhang, Z. Huang, C. You, and X. Xie, “Coma: Compositional human motion generation with multi-modal agents,”arXiv preprint arXiv:2412.07320, 2024
-
[35]
Poco: Policy composition from and for heterogeneous robot learning,
L. Wang, J. Zhao, Y . Du, E. H. Adelson, and R. Tedrake, “Poco: Policy composition from and for heterogeneous robot learning,”arXiv preprint arXiv:2402.02511, 2024
-
[36]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” in Proceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[37]
Imitating human behaviour with diffusion models,
T. Pearce, T. Rashid, A. Kanervisto, D. Bignell, M. Sun, R. Georgescu, S. V . Macua, S. Z. Tan, I. Momennejad, K. Hofmann,et al., “Imitating human behaviour with diffusion models,”ICLR, 2023
work page 2023
-
[38]
Goal-conditioned imitation learning using score-based diffusion policies,
M. Reuss, M. Li, X. Jia, and R. Lioutikov, “Goal-conditioned imitation learning using score-based diffusion policies,” inProceedings of Robotics: Science and Systems (RSS), 2023
work page 2023
-
[39]
X. Zhu, B. Huang, and Y . Li, “Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper,”arXiv preprint arXiv:2507.15062, 2025
-
[40]
H. Chen, J. Xu, L. Sheng, T. Ji, S. Liu, Y . Li, and K. Driggs-Campbell, “Learning coordinated bimanual manipulation policies using state diffusion and inverse dynamics models,” in2025 IEEE International Conference on Robotics and Automation (ICRA), 2025
work page 2025
-
[41]
Tool-as- interface: Learning robot policies from observing human tool use,
H. Chen, C. Zhu, S. Liu, Y . Li, and K. Driggs-Campbell, “Tool-as- interface: Learning robot policies from observing human tool use,” in Conference on Robot Learning (CoRL), 2025
work page 2025
-
[42]
Edmp: Ensemble-of-costs-guided diffusion for motion planning,
K. Saha, V . Mandadi, J. Reddy, A. Srikanth, A. Agarwal, B. Sen, A. Singh, and M. Krishna, “Edmp: Ensemble-of-costs-guided diffusion for motion planning,”arXiv, 2023
work page 2023
-
[43]
Vt-refine: Learning bimanual assembly with visuo-tactile feedback via simulation fine-tuning,
B. Huang, J. Xu, I. Akinola, W. Yang, B. Sundaralingam, R. O’Flaherty, D. Fox, X. Wang, A. Mousavian, Y .-W. Chao,et al., “Vt-refine: Learning bimanual assembly with visuo-tactile feedback via simulation fine-tuning,” inRSS 2025 Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond
work page 2025
-
[44]
Hierarchical diffusion for offline decision making,
W. Li, X. Wang, B. Jin, and H. Zha, “Hierarchical diffusion for offline decision making,” inInternational Conference on Machine Learning, 2023, pp. 20 035–20 064
work page 2023
-
[45]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang,et al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,”arXiv preprint arXiv:2411.15139, 2024
-
[46]
Modality- composable diffusion policy via inference-time distribution-level com- position,
J. Cao, Q. Zhang, H. Guo, J. Wang, H. Cheng, and R. Xu, “Modality- composable diffusion policy via inference-time distribution-level com- position,” 2025
work page 2025
-
[47]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems, 2020
work page 2020
-
[48]
Emerging properties in self-supervised vision trans- formers,
M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision trans- formers,” inProceedings of the International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[49]
DINOv2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. HAZIZA, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Je- gou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski, “DINOv2: Learning robust visual features withou...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.