Deep Thinking by Markov Chain of Continuous Thoughts
Pith reviewed 2026-05-18 12:21 UTC · model grok-4.3
The pith
MarCos lets transformers chain continuous thought representations to complete multi-step reasoning in one forward pass.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
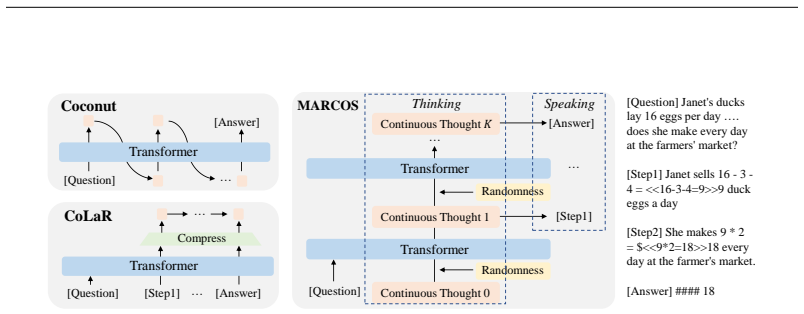
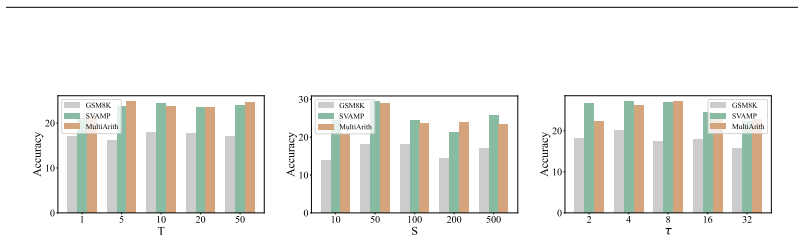
MarCos is an improvement of the transformer structure that allows fully continuous reasoning at the thought level. Unlike traditional transformer layers, which focus on refining token predictions at each time step, layers in MarCos map a continuous representation of a stepwise thought to the distribution of the next thought. This enables multi-step reasoning in a single pass of MarCos. Preliminary experimental results show that the increased information bandwidth elicits parallel thinking, and on real-world math tasks MarCos achieves more than 10× speedup in wall-clock time with the same level of accuracy.
What carries the argument
The MarCos layer that maps a continuous representation of a stepwise thought directly to the distribution of the next thought.
If this is right
- Multi-step reasoning completes inside one model pass instead of sequential token generation.
- Wall-clock inference time on math tasks drops by more than a factor of ten at matched accuracy.
- The model exhibits parallel thinking rather than single-threaded sequential reasoning.
- Higher information bandwidth across steps supports longer or more branched reasoning chains.
Where Pith is reading between the lines
- The continuous framing could be combined with existing discrete models to create hybrid fast-inference pipelines.
- Similar continuous mappings might be tested on planning or code-generation tasks that also require deep sequential dependencies.
- Limits of the approach could be probed by scaling the number of implicit reasoning steps beyond those tested in the paper.
- The Markov-chain view of thoughts suggests exploring connections to continuous dynamical systems for modeling internal reasoning trajectories.
Load-bearing premise
Replacing discrete token sampling with a direct continuous mapping from thought representation to next-thought distribution removes the information bottleneck and maintains reasoning quality.
What would settle it
A controlled test on a set of multi-step math problems where MarCos accuracy falls noticeably below a standard token-by-token transformer baseline.
Figures





read the original abstract
Transformer-based models can perform complicated reasoning by generating reasoning paths token by token. While effective, this approach often requires generating thousands of tokens to solve a single problem, which can be slow and computationally expensive. More importantly, it involves a discrete sampling operation at the end of each time step, creating an information bottleneck across time steps. In this work, we propose MarCos, an improvement of the transformer structure that allows fully continuous reasoning at the thought level. Unlike traditional transformer layers, which focus on refining token predictions at each time step, layers in MarCos map a continuous representation of a stepwise thought to the distribution of the next thought. This enables us to achieve multi-step reasoning in a single pass of MarCos. Preliminary experimental results on synthetic and real-world math tasks show the great potential of MarCos. Notably, we observe that the increased information bandwidth of MarCos elicits the ability of parallel thinking, in contrast to single-threaded thinking in traditional transformers. Meanwhile, in real-world math tasks, MarCos achieves more than $10\times$ speedup in wall-clock time with the same level of accuracy. Our code is available at https://github.com/Ljyustc/MarCos.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MarCos, a transformer variant in which each layer maps a continuous representation of a stepwise thought directly to the distribution over the next thought. This construction is claimed to support multi-step reasoning inside a single forward pass, to elicit parallel thinking, and to deliver more than 10× wall-clock speedup on real-world math tasks while preserving accuracy.
Significance. If the empirical claims are substantiated, the work would offer a concrete route to reducing the token-generation bottleneck in reasoning models and could stimulate research on continuous-state Markov processes for multi-step inference. The absence of any parameter-free derivation or machine-checked proof is noted, but the architectural idea itself is a clear departure from discrete sampling.
major comments (2)
- [Abstract] Abstract: the central claims of “multi-step reasoning in a single pass,” “parallel thinking,” and “more than 10× speedup … with the same level of accuracy” are presented without any description of the number of MarCos layers, the datasets, baselines, number of runs, or error bars. These omissions make the empirical assertions impossible to evaluate.
- [Architecture] Architecture / Method (implied by the single-pass construction): the model is realized by stacking a fixed number of MarCos layers, each advancing one continuous thought step. No analysis is given of what happens when the minimal reasoning depth required by a problem exceeds this fixed depth, nor is any variable-length or early-stopping mechanism described. This assumption is load-bearing for the variable-length multi-step claim.
minor comments (2)
- [Abstract] The abstract refers to “synthetic and real-world math tasks” but supplies no concrete task names or references; adding these would improve reproducibility.
- [Abstract] The GitHub link is provided, yet the manuscript does not state the exact commit or tag used for the reported results.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of “multi-step reasoning in a single pass,” “parallel thinking,” and “more than 10× speedup … with the same level of accuracy” are presented without any description of the number of MarCos layers, the datasets, baselines, number of runs, or error bars. These omissions make the empirical assertions impossible to evaluate.
Authors: We agree that additional details in the abstract would improve evaluability. In the revised version, we will update the abstract to specify that experiments use 4 MarCos layers for multi-step reasoning, evaluate on synthetic arithmetic tasks and real-world math benchmarks such as GSM8K, compare against standard transformer baselines with chain-of-thought, and report results averaged over 5 runs with standard error bars shown in the experimental section. Full quantitative details remain in the body of the paper due to space constraints. revision: yes
-
Referee: [Architecture] Architecture / Method (implied by the single-pass construction): the model is realized by stacking a fixed number of MarCos layers, each advancing one continuous thought step. No analysis is given of what happens when the minimal reasoning depth required by a problem exceeds this fixed depth, nor is any variable-length or early-stopping mechanism described. This assumption is load-bearing for the variable-length multi-step claim.
Authors: The current design indeed employs a fixed number of layers, each corresponding to one continuous thought transition. For the tasks in our experiments, this fixed depth was chosen to be adequate based on preliminary analysis of required reasoning steps. We will add a new subsection in the revised manuscript discussing the implications of fixed depth, including potential failure modes for deeper problems and outlining future directions such as recurrent application of the MarCos block or confidence-based early stopping. This preserves the single-pass advantage for problems within the depth limit while acknowledging the limitation for arbitrary depths. revision: partial
Circularity Check
No circularity: architectural proposal with experimental support remains self-contained
full rationale
The paper introduces MarCos as a structural modification to transformers that replaces discrete token sampling with direct continuous-to-distribution mappings per layer, claiming this removes information bottlenecks and enables single-pass multi-step reasoning. No equations, fitted parameters, or self-citations are shown that reduce any claimed prediction or speedup to the input definition by construction. The 10× wall-clock improvement and parallel-thinking observation are presented as empirical outcomes on math tasks rather than tautological consequences of the model definition. The derivation chain consists of an independent architectural change whose validity rests on external benchmarks, not internal redefinition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Continuous representations of thoughts can be mapped directly to distributions over subsequent thoughts without incurring the information loss of discrete sampling.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery; embed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
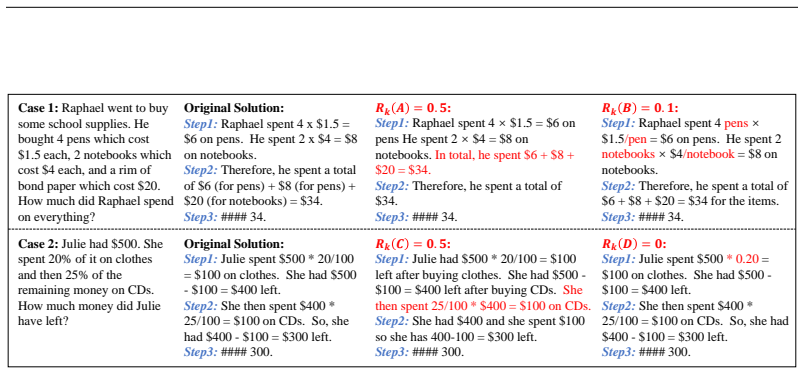
we model reasoning as a hidden Markov chain of continuous, high-dimensional 'thoughts'. Each reasoning step involves a transition of the internal thoughts... Neu_deep and Neu_shallow... R_k ~ N(μ_k, σ_k) ... Thinker(Neu_deep_{k-1}, Neu_shallow_{k-1}, H_in, R_k)
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel; Jcost_pos_of_ne_one unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
two-phase variational training scheme... L_ELBO_k = E[log p(y_k | R_k)] - KL(q(R_k | y_k) || p(R_k)) + λ ||R_k||_1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Internalized Reasoning for Long-Context Visual Document Understanding
A synthetic pipeline creates and internalizes reasoning traces in VLMs for long-context visual document understanding, with a 32B model surpassing a 235B model on MMLongBenchDoc and showing 12.4x fewer output tokens.
-
RuPLaR : Efficient Latent Compression of LLM Reasoning Chains with Rule-Based Priors From Multi-Step to One-Step
RuPLaR replaces multi-step latent CoT with a single-model one-step generator guided by rule-based priors and a joint consistency-plus-alignment loss, delivering 11.1 percent higher accuracy at lower token cost.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. Sparse autoen- coders find highly interpretable features in language models.arXiv preprint arXiv:2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2311.01460 , year=
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stu- art Shieber. Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460,
-
[4]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit cot to implicit cot: Learning to inter- nalize cot step by step.arXiv preprint arXiv:2405.14838,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach.arXiv preprint arXiv:2502.05171,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Auto-Encoding Variational Bayes
10 Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Mawps: A math word problem repository
Rik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman, and Hannaneh Hajishirzi. Mawps: A math word problem repository. InProceedings of the 2016 conference of the north american chapter of the association for computational linguistics: human language technologies, pp. 1152–1157,
work page 2016
-
[9]
Tianyi Li, Mingda Chen, Bowei Guo, and Zhiqiang Shen. A survey on diffusion language models. arXiv preprint arXiv:2508.10875,
-
[10]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 2080–2094,
work page 2021
-
[11]
Solving general arithmetic word problems
Subhro Roy and Dan Roth. Solving general arithmetic word problems. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pp. 1743–1752,
work page 2015
-
[12]
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Compressing chain-of-thought into continuous space via self-distillation.arXiv preprint arXiv:2502.21074,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2505.16552 (2025)
Wenhui Tan, Jiaze Li, Jianzhong Ju, Zhenbo Luo, Jian Luan, and Ruihua Song. Think silently, think fast: Dynamic latent compression of llm reasoning chains.arXiv preprint arXiv:2505.16552,
-
[14]
Qwen Team. Qwen2 technical report.arXiv preprint arXiv:2407.10671,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models
Fengli Xu, Qianyue Hao, Zefang Zong, Jingwei Wang, Yunke Zhang, Jingyi Wang, Xiaochong Lan, Jiahui Gong, Tianjian Ouyang, Fanjin Meng, et al. Towards large reasoning models: A survey of reinforced reasoning with large language models.arXiv preprint arXiv:2501.09686,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
The training batch size is 256, and both training phases run for 10 epochs
It is trained by AdamW with a learning rate of1e−4and a weight decay of 0.01. The training batch size is 256, and both training phases run for 10 epochs. To simplify prototyping, the number of thinking steps is fixed asK= 3, although our model also supports dynamically deciding this number. For text data, each period (“.”) is treated as a separate step. I...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.