A Metamorphic Testing Perspective on Knowledge Distillation for Language Models of Code: Does the Student Deeply Mimic the Teacher?
Pith reviewed 2026-05-17 23:42 UTC · model grok-4.3
The pith
Student models distilled from large code teachers often fail to copy their behavioral patterns, exposing much larger drops when code is adversarially changed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Experiments on two code tasks using models compressed via Compressor, AVATAR, and MORPH show that MetaCompress detects up to 62 percent behavioral discrepancies between teacher and student. Under adversarial attacks the students exhibit up to 285 percent greater performance degradation than their teachers, a difference that accuracy-based evaluation alone does not reveal.
What carries the argument
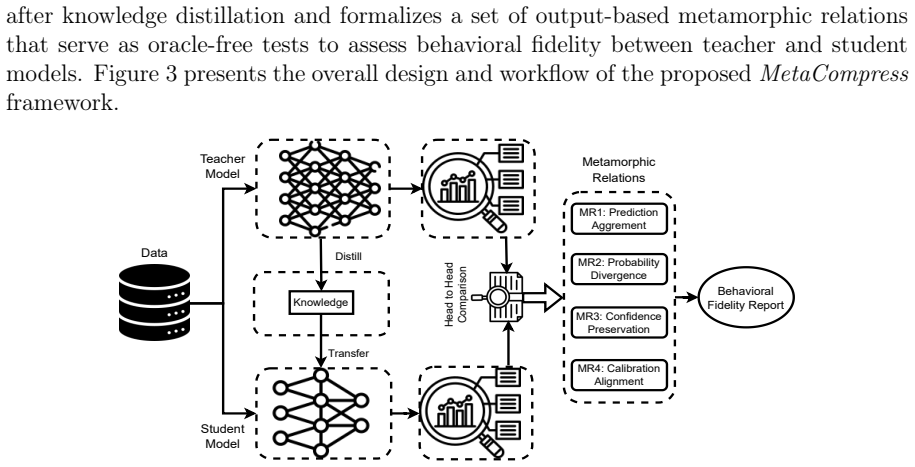
MetaCompress, a metamorphic testing framework that applies sets of behavior-preserving transformations to input code and measures output differences between teacher and student to quantify lack of deep mimicry.
If this is right
- Distillation pipelines for code models need behavioral-fidelity checks in addition to accuracy measurements.
- Adversarial robustness of the resulting student models can be substantially weaker than accuracy figures imply.
- Compressed code models require evaluation methods that test consistency under input transformations rather than single-point predictions.
- MetaCompress offers a concrete way to insert behavioral testing directly into the knowledge-distillation workflow.
Where Pith is reading between the lines
- The same metamorphic-testing lens could expose similar mimicry shortfalls when distilling models for natural-language or other software tasks.
- If behavioral gaps prove widespread, then redesigning distillation objectives to preserve robustness properties may become necessary.
- Teams deploying distilled code models should run separate robustness tests instead of assuming teacher-level behavior carries over.
- Certain distillation techniques might preserve behavioral fidelity better than others, opening a route for comparative studies.
Load-bearing premise
The chosen metamorphic relations really leave the expected model output unchanged for the studied code tasks, so any observed difference signals a genuine failure of mimicry rather than a flawed test.
What would settle it
Finding that teacher and student models produce matching outputs on all applied metamorphic relations and show identical performance drops under the same adversarial attacks would contradict the reported discrepancies.
Figures






read the original abstract
Transformer-based language models of code have achieved state-of-the-art performance across a wide range of software analytics tasks, but their practical deployment remains limited due to high computational costs, slow inference speeds, and significant environmental impact. To address these challenges, recent research has increasingly explored knowledge distillation as a method for compressing a large language model of code (the teacher) into a smaller model (the student) while maintaining performance. However, the degree to which a student model deeply mimics the predictive behavior and internal representations of its teacher remains largely unexplored, as current accuracy-based evaluation provides only a surface-level view of model quality and often fails to capture more profound discrepancies in behavioral fidelity between the teacher and student models. To address this gap, we empirically show that the student model often fails to deeply mimic the teacher model, resulting in up to 285% greater performance drop under adversarial attacks, which is not captured by traditional accuracy-based evaluation. Therefore, we propose MetaCompress, a metamorphic testing framework that systematically evaluates behavioral fidelity by comparing the outputs of teacher and student models under a set of behavior-preserving metamorphic relations. We evaluate MetaCompress on two widely studied tasks, using compressed versions of popular language models of code, obtained via three different knowledge distillation techniques: Compressor, AVATAR, and MORPH. The results show that MetaCompress identifies up to 62% behavioral discrepancies in student models, underscoring the need for behavioral fidelity evaluation within the knowledge distillation pipeline and establishing MetaCompress as a practical framework for testing compressed language models of code derived through knowledge distillation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that knowledge distillation for language models of code produces student models that fail to deeply mimic teacher behavior, as traditional accuracy metrics overlook substantial discrepancies; using the proposed MetaCompress metamorphic testing framework, it reports up to 62% behavioral discrepancies and up to 285% greater performance drops under adversarial attacks for students versus teachers across two tasks and three distillation methods (Compressor, AVATAR, MORPH) on models such as CodeBERT.
Significance. If the metamorphic relations prove valid and the empirical results are robust, this would be a meaningful contribution to software engineering by demonstrating the inadequacy of accuracy-only evaluation for compressed code models and providing a practical metamorphic testing framework to assess behavioral fidelity, which could guide more reliable distillation practices and deployment of efficient code models.
major comments (2)
- [Abstract] Abstract: The central empirical claim—that output differences under the metamorphic relations indicate failures of deep mimicry rather than artifacts—depends on the relations (e.g., variable renaming, statement reordering, identifier substitution) being behavior-preserving for the specific models and tasks. No validation details, semantic equivalence checks, or oracle procedures are described, which is load-bearing for attributing the reported 62% discrepancies and 285% adversarial drops to distillation quality.
- [Evaluation] Evaluation section (inferred from results reporting): The quantitative claims of up to 285% greater performance drop and 62% discrepancies require supporting details on data splits, statistical significance testing, number of experimental runs, and adversarial attack generation methodology to establish that post-hoc choices did not inflate the differences between teacher and student models.
minor comments (2)
- [Abstract] Abstract: Briefly list the specific metamorphic relations and the two tasks studied to give readers immediate context without needing to consult the full methods.
- [Throughout] Notation: Ensure 'MetaCompress' is consistently introduced as the framework name and that terms like 'behavioral fidelity' and 'deep mimicry' are defined on first use to improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We address each major comment in detail below and will revise the paper to incorporate additional information where it strengthens the work without altering our core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim—that output differences under the metamorphic relations indicate failures of deep mimicry rather than artifacts—depends on the relations (e.g., variable renaming, statement reordering, identifier substitution) being behavior-preserving for the specific models and tasks. No validation details, semantic equivalence checks, or oracle procedures are described, which is load-bearing for attributing the reported 62% discrepancies and 285% adversarial drops to distillation quality.
Authors: We agree that explicit validation of the metamorphic relations is important for rigorously attributing discrepancies to distillation rather than transformation artifacts. The relations in MetaCompress are selected from prior metamorphic testing work on code (e.g., variable renaming and reordering have been validated as semantics-preserving in studies on code clone detection and bug detection). In the revision, we will add a new subsection under Methodology describing the oracle procedures used: for each relation, we verify that the teacher model produces equivalent outputs on original and transformed inputs for a held-out validation set, supplemented by manual semantic checks on a random sample of 100 cases per task. This will clarify that the relations are behavior-preserving for the evaluated models and tasks. revision: yes
-
Referee: [Evaluation] Evaluation section (inferred from results reporting): The quantitative claims of up to 285% greater performance drop and 62% discrepancies require supporting details on data splits, statistical significance testing, number of experimental runs, and adversarial attack generation methodology to establish that post-hoc choices did not inflate the differences between teacher and student models.
Authors: We acknowledge that additional experimental details are needed for full reproducibility and to confirm robustness. The manuscript summarizes the evaluation but does not explicitly report all parameters. In the revision, we will expand the Evaluation section with: precise data split descriptions (e.g., 80/10/10 ratios with random seeds), statistical significance tests (paired t-tests with p-values reported for teacher-student differences), number of runs (five independent runs with different random seeds, reporting means and standard deviations), and adversarial attack details (using a combination of rule-based perturbations and an adapted TextAttack framework with fixed hyperparameters). These additions will demonstrate that the reported gaps are consistent across runs and not inflated by selective reporting. revision: yes
Circularity Check
No circularity in empirical framework and evaluation
full rationale
The paper is an empirical study that proposes the MetaCompress metamorphic testing framework and evaluates it on existing knowledge distillation techniques (Compressor, AVATAR, MORPH) applied to code models such as CodeBERT. Central claims rest on observed performance drops under adversarial attacks and output discrepancies under chosen metamorphic relations, which are external to any author-defined fitting or self-referential equations. No derivation chain reduces predictions or results to inputs by construction, and no load-bearing self-citations or uniqueness theorems are invoked to force the outcomes. The work is self-contained against the reported benchmarks and tasks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Metamorphic relations used are behavior-preserving transformations for the models under test
invented entities (1)
-
MetaCompress framework
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose MetaCompress, a metamorphic testing framework that systematically evaluates behavioral fidelity by comparing the outputs of teacher and student models under a set of behavior-preserving metamorphic relations.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Bidirectional Empowerment of Metamorphic Testing and Large Language Models: A Systematic Survey
A systematic survey of 93 studies that maps the bidirectional relationship between metamorphic testing and LLMs, proposing a taxonomy for MT applied to LLMs and LLMs applied to MT.
-
Knowledge Distillation Must Account for What It Loses
Knowledge distillation should be reframed as a lossy projection and evaluated with a taxonomy of off-metric losses plus a Distillation Loss Statement reporting preserved and lost capabilities.
-
Knowledge Distillation Must Account for What It Loses
Knowledge distillation evaluations must report lost teacher capabilities via a Distillation Loss Statement rather than relying solely on task scores.
Reference graph
Works this paper leans on
-
[1]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, I. Polosukhin, Attention is all you need, Advances in neural information processing systems 30 (2017)
work page 2017
- [2]
- [3]
- [4]
-
[5]
J. Chen, X. Hu, Z. Li, C. Gao, X. Xia, D. Lo, Code search is all you need? im- proving code suggestions with code search, in: Proceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
work page 2024
-
[6]
J. Shi, Z. Yang, B. Xu, H. J. Kang, D. Lo, Compressing pre-trained models of code into 3 mb, in: Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, ASE ’22, Association for Computing Machinery, New York, NY, USA, 2023.doi:10.1145/3551349.3556964. URLhttps://doi.org/10.1145/3551349.3556964
-
[7]
R. Schwartz, J. Dodge, N. A. Smith, O. Etzioni, Green ai, Communications of the ACM 63 (12) (2020) 54–63
work page 2020
-
[8]
V. J. Hellendoorn, S. Proksch, H. C. Gall, A. Bacchelli, When code completion fails: A case study on real-world completions, in: 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE), IEEE, 2019, pp. 960–970
work page 2019
-
[9]
Distilling the Knowledge in a Neural Network
G. Hinton, O. Vinyals, J. Dean, Distilling the knowledge in a neural network, arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[10]
J. Shi, Z. Yang, H. J. Kang, B. Xu, J. He, D. Lo, Greening large language models of code, in: Proceedings of the 46th International Conference on Software Engineering: Software Engineering in Society, ICSE-SEIS’24, Association for Computing Machin- ery, New York, NY, USA, 2024, p. 142–153.doi:10.1145/3639475.3640097. URLhttps://doi-org.libproxy.smu.edu.sg...
-
[11]
J. Shi, Z. Yang, D. Lo, Efficient and green large language models for software en- gineering: Vision and the road ahead, ACM Transactions on Software Engineering and Methodology (2024). 27
work page 2024
-
[12]
X. Wei, S. K. Gonugondla, S. Wang, W. Ahmad, B. Ray, H. Qian, X. Li, V. Ku- mar, Z. Wang, Y. Tian, et al., Towards greener yet powerful code generation via quantization: An empirical study, in: Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2023, pp. 224–236
work page 2023
- [13]
-
[14]
arXiv preprint arXiv:2412.13737 (2024)
G. d’Aloisio, L. Traini, F. Sarro, A. Di Marco, On the compression of language models for code: An empirical study on codebert, arXiv preprint arXiv:2412.13737 (2024)
-
[15]
Y. Chen, Y. Ye, Z. Li, Y. Ma, C. Gao, Smaller but better: Self-paced knowledge distillation for lightweight yet effective lcms, Proceedings of the ACM on Software Engineering 2 (FSE) (2025) 3057–3080
work page 2025
-
[16]
Z. Feng, D. Guo, D. Tang, N. Duan, X. Feng, M. Gong, L. Shou, B. Qin, T. Liu, D. Jiang, et al., Codebert: A pre-trained model for programming and natural lan- guages, arXiv:2002.08155 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[17]
Z. Yang, J. Shi, J. He, D. Lo, Natural attack for pre-trained models of code, in: Proceedings of the 44th ICSE, 2022, pp. 1482–1493
work page 2022
- [18]
-
[19]
Z. Zeng, H. Tan, H. Zhang, J. Li, Y. Zhang, L. Zhang, An extensive study on pre- trained models for program understanding and generation, in: 31st ACM SIGSOFT ISSTA, 2022, pp. 39–51
work page 2022
-
[20]
T. Y. Chen, F.-C. Kuo, H. Liu, P.-L. Poon, D. Towey, T. Tse, Z. Q. Zhou, Metamor- phic testing: A review of challenges and opportunities, ACM Computing Surveys (CSUR) 51 (1) (2018) 1–27
work page 2018
-
[21]
D. Guo, S. Ren, S. Lu, Z. Feng, D. Tang, S. Liu, L. Zhou, N. Duan, A. Svy- atkovskiy, S. Fu, et al., Graphcodebert: Pre-training code representations with data flow, arXiv:2009.08366 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[22]
A. Panichella, Metamorphic-based many-objective distillation of llms for code- related tasks, in: 2025 IEEE/ACM 47th International Conference on Software En- gineering (ICSE), IEEE Computer Society, 2025, pp. 766–766
work page 2025
-
[23]
S. Lu, D. Guo, S. Ren, J. Huang, A. Svyatkovskiy, A. Blanco, C. Clement, D. Drain, D. Jiang, D. Tang, et al., Codexglue: A machine learning benchmark dataset for code understanding and generation, arXiv:2102.04664 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [24]
-
[25]
Y. Wang, W. Wang, S. Joty, S. C. Hoi, Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation, arXiv:2109.00859 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[26]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, Bert: Pre-training of deep bidirectional transformers for language under- standing, arXiv:1810.04805 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[27]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Y. Liu, Roberta: A robustly optimized bert pretraining approach, arXiv:1907.11692 364 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[28]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
V. Sanh, Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter, arXiv:1910.01108 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[29]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
H. Husain, H.-H. Wu, T. Gazit, M. Allamanis, M. Brockschmidt, Codesearchnet challenge: Evaluating the state of semantic code search, arXiv:1909.09436 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[30]
X. Hou, Y. Zhao, Y. Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, H. Wang, Large language models for software engineering: A systematic literature review, ACM Transactions on Software Engineering and Methodology 33 (8) (2024) 1–79
work page 2024
-
[31]
StarCoder 2 and The Stack v2: The Next Generation
A. Lozhkov, R. Li, L. B. Allal, F. Cassano, J. Lamy-Poirier, N. Tazi, A. Tang, D. Pykhtar, J. Liu, Y. Wei, et al., Starcoder 2 and the stack v2: The next generation, arXiv preprint arXiv:2402.19173 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y. Burda, N. Joseph, G. Brockman, et al., Evaluating large language models trained on code, arXiv preprint arXiv:2107.03374 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[33]
X. Liu, X. Liu, L. Bo, X. Wu, Y. Yang, X. Sun, F. Zhou, Pioneer: improving the robustness of student models when compressing pre-trained models of code, Automated Software Engineering 33 (1) (2026) 1–30
work page 2026
-
[34]
C. Xu, J. McAuley, A survey on model compression and acceleration for pretrained language models, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 37, 2023, pp. 10566–10575
work page 2023
-
[35]
V. Sanh, T. Wolf, A. Rush, Movement pruning: Adaptive sparsity by fine-tuning, Advances in neural information processing systems 33 (2020) 20378–20389
work page 2020
- [36]
- [37]
- [38]
-
[39]
T. N. Sainath, B. Kingsbury, V. Sindhwani, E. Arisoy, B. Ramabhadran, Low-rank matrix factorization for deep neural network training with high-dimensional out- put targets, in: 2013 IEEE international conference on acoustics, speech and signal processing, IEEE, 2013, pp. 6655–6659
work page 2013
- [40]
- [41]
- [42]
-
[43]
X. Xie, J. W. Ho, C. Murphy, G. Kaiser, B. Xu, T. Y. Chen, Testing and validating machinelearningclassifiersbymetamorphictesting, JournalofSystemsandSoftware 84 (4) (2011) 544–558
work page 2011
- [44]
-
[45]
D. Xiao, Z. Liu, Y. Yuan, Q. Pang, S. Wang, Metamorphic testing of deep learning compilers, Proceedings of the ACM on Measurement and Analysis of Computing Systems 6 (1) (2022) 1–28
work page 2022
- [46]
-
[47]
Intriguing properties of neural networks
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, R. Fergus, Intriguing properties of neural networks, arXiv:1312.6199 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
- [48]
-
[49]
S. Kullback, R. A. Leibler, On information and sufficiency, The annals of mathemat- ical statistics 22 (1) (1951) 79–86
work page 1951
-
[50]
J. Svajlenko, J. F. Islam, I. Keivanloo, C. K. Roy, M. M. Mia, Towards a big data curated benchmark of inter-project code clones, in: 2014 IEEE International Con- ference on Software Maintenance and Evolution, IEEE, 2014, pp. 476–480
work page 2014
-
[51]
W. Wang, G. Li, B. Ma, X. Xia, Z. Jin, Detecting code clones with graph neural network and flow-augmented abstract syntax tree, in: 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER), IEEE, 2020, pp. 261–271. 30
work page 2020
-
[52]
Y. Zhou, S. Liu, J. Siow, X. Du, Y. Liu, Devign: Effective vulnerability identification by learning comprehensive program semantics via graph neural networks, Advances in NIPS 32 (2019)
work page 2019
-
[53]
X. Du, M. Wen, Z. Wei, S. Wang, H. Jin, An extensive study on adversarial attack against pre-trained models of code, in: 31st FSE, 2023, pp. 489–501
work page 2023
-
[54]
M. Friedman, The use of ranks to avoid the assumption of normality implicit in the analysis of variance, Journal of the american statistical association 32 (200) (1937) 675–701
work page 1937
-
[55]
R.F.Woolson, Wilcoxonsigned-ranktest, Wileyencyclopediaofclinicaltrials(2007) 1–3
work page 2007
-
[56]
W. E. Wong, J. R. Horgan, S. London, H. Agrawal, A study of effective regression testing in practice, in: PROCEEDINGS The Eighth International Symposium On Software Reliability Engineering, IEEE, 1997, pp. 264–274
work page 1997
-
[57]
Y. Jia, M. Harman, An analysis and survey of the development of mutation testing, IEEE transactions on software engineering 37 (5) (2010) 649–678
work page 2010
-
[58]
X. Xie, Z. Zhang, T. Y. Chen, Y. Liu, P.-L. Poon, B. Xu, Mettle: A metamorphic testing approach to assessing and validating unsupervised machine learning systems, IEEE Transactions on Reliability 69 (4) (2020) 1293–1322
work page 2020
-
[59]
Z. Sun, Z. Chen, J. Zhang, D. Hao, Fairness testing of machine translation systems, ACM Transactions on Software Engineering and Methodology 33 (6) (2024) 1–27
work page 2024
- [60]
-
[61]
J. M. Zhang, M. Harman, L. Ma, Y. Liu, Machine learning testing: Survey, land- scapes and horizons, IEEE Transactions on Software Engineering 48 (1) (2020) 1–36
work page 2020
-
[62]
W. Wu, Y. Cao, N. Yi, R. Ou, Z. Zheng, Detecting and reducing the factual hal- lucinations of large language models with metamorphic testing, Proceedings of the ACM on Software Engineering 2 (FSE) (2025) 1432–1453
work page 2025
- [63]
- [64]
- [65]
-
[66]
J. Ba, R. Caruana, Do deep nets really need to be deep?, Advances in neural infor- mation processing systems 27 (2014). 31
work page 2014
-
[67]
L. Wang, K.-J. Yoon, Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks, IEEE transactions on pattern analysis and machine intelligence 44 (6) (2021) 3048–3068
work page 2021
- [68]
-
[69]
X. Zhu, J. Li, Y. Liu, C. Ma, W. Wang, A survey on model compression for large language models, Transactions of the Association for Computational Linguistics 12 (2024) 1556–1577
work page 2024
-
[70]
M. Xu, D. Cai, W. Yin, S. Wang, X. Jin, X. Liu, Resource-efficient algorithms and systems of foundation models: A survey, ACM Computing Surveys 57 (5) (2025) 1–39
work page 2025
- [71]
- [72]
- [73]
-
[74]
S. Ye, K. Xu, S. Liu, H. Cheng, J.-H. Lambrechts, H. Zhang, A. Zhou, K. Ma, Y. Wang, X. Lin, Adversarial robustness vs. model compression, or both?, in: Pro- ceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 111–120
work page 2019
- [75]
-
[76]
S.K.Gourtani, N.Meratnia, Improvingrobustnessofcompressedmodelswithweight sharing through knowledge distillation, in: 2024 IEEE 10th International Conference on Edge Computing and Scalable Cloud (EdgeCom), IEEE, 2024, pp. 13–21
work page 2024
-
[77]
J. Zhu, L. Wang, X. Han, Safety and performance, why not both? bi-objective optimized model compression toward ai software deployment, in: Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, 2022, pp. 1–13
work page 2022
- [78]
- [79]
-
[80]
C. Buciluˇ a, R. Caruana, A. Niculescu-Mizil, Model compression, in: Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, 2006, pp. 535–541. 32
work page 2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.