MapFormer: Self-Supervised Learning of Cognitive Maps with Input-Dependent Positional Embeddings
Pith reviewed 2026-05-17 06:03 UTC · model grok-4.3
The pith
MapFormers learn cognitive maps by updating positional embeddings with input-dependent matrices built from Lie-algebra exponentials, yielding near-perfect OOD generalization where standard models fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
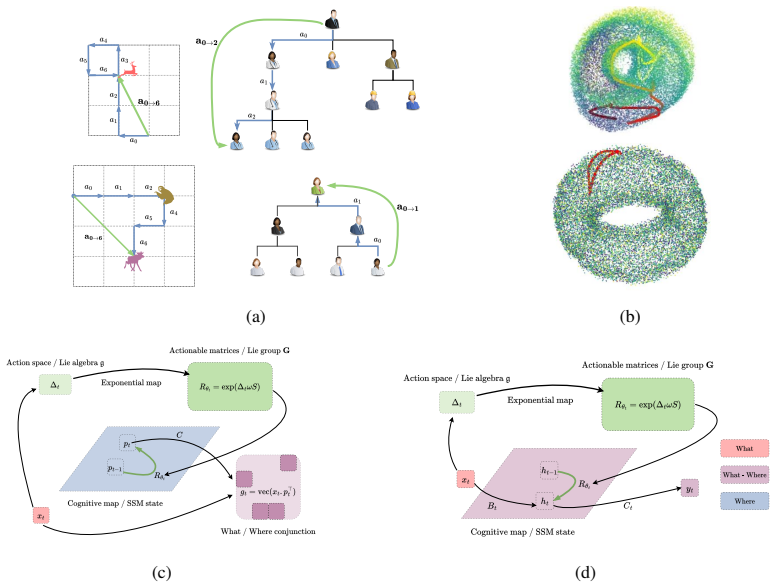
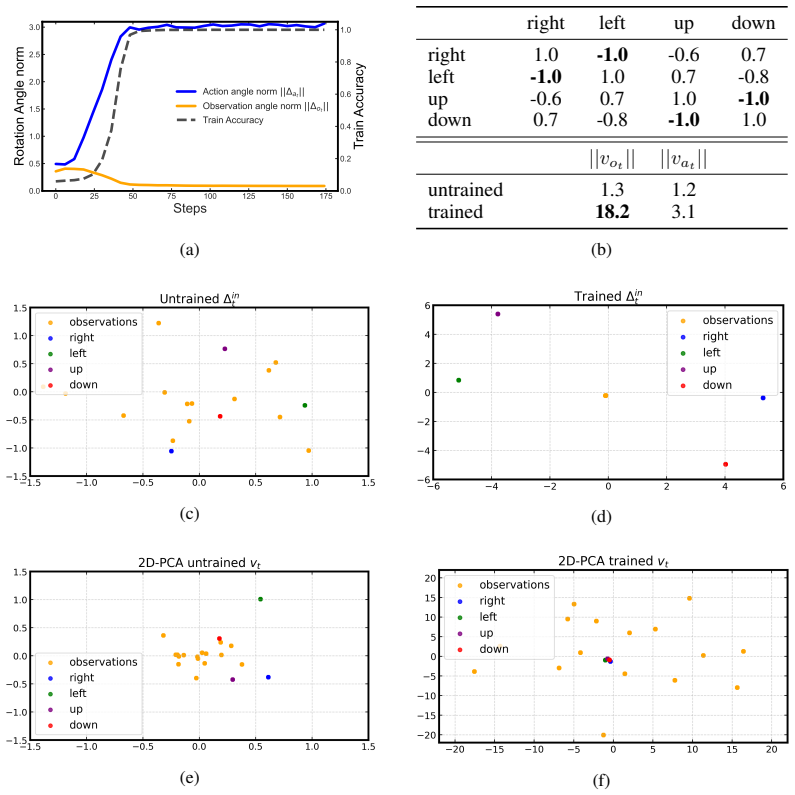
Cognitive maps are learned in the model by disentangling structural relationships in the inputs from their specific content, a property that can be achieved by updating position encodings with input-dependent matrices, built as exponentials of learned combinations of Lie-algebra generators. Two variants unify absolute and relative positional encoding to model episodic and working memory. On formal tasks targeting gating, 2D navigation and nested hierarchies the models achieve near-perfect out-of-distribution generalization while standard architectures fail; the same principle yields perplexity improvements on naturalistic data and supports both parallel computation on commutative maps and,,
What carries the argument
Input-dependent matrices constructed as exponentials of learned combinations of Lie-algebra generators that update position encodings to separate abstract relations from content.
If this is right
- The models reach near-perfect OOD generalization on gating, 2D navigation, and nested-hierarchy tasks where standard transformers fail.
- MapFormers remain scalable and deliver perplexity gains on naturalistic data.
- Commutative maps permit efficient parallel computation while non-commutative maps can still be acquired through sequential path integration.
Where Pith is reading between the lines
- The same Lie-algebra construction could be inserted into other sequence models to test whether the disentangling effect improves structural generalization beyond transformers.
- If the approach generalizes, it would supply a concrete route for adding geometric inductive bias to large language models on tasks that require tracking abstract relations.
- Testing the matrices on data whose underlying structure lies outside Lie-algebra representations would reveal the limits of the current inductive bias.
Load-bearing premise
That input-dependent matrices constructed as exponentials of learned combinations of Lie-algebra generators will reliably disentangle structural relationships from content across the tested domains.
What would settle it
If ablating the input dependence of the matrices produces no drop in out-of-distribution accuracy on the Dyck-language or navigation tasks relative to standard positional encodings, the claimed necessity of the mechanism would be falsified.
Figures






read the original abstract
A cognitive map is an internal model which encodes the abstract relationships among entities in the world, giving humans and animals the flexibility to adapt to new situations, with a strong out-of-distribution (OOD) generalization that current AI systems still do not possess. To bridge this gap, we introduce $\textit{MapFormers}$, new Transformer-based architectures, which can learn cognitive maps from observational data and perform path-integration without supervision. Cognitive maps are learned in the model by disentangling structural relationships in the inputs from their specific content, a property that can be achieved by updating position encodings with input-dependent matrices, built as exponentials of learned combinations of Lie-algebra generators. We developed two variants of $\textit{MapFormers}$ that unify absolute and relative positional encoding to model episodic (EM) and working memory (WM), respectively. We tested $\textit{MapFormers}$ on several formal tasks targeting distinct cognitive capacities, including gating, 2D navigation and nested hierarchies (Dyck Languages). Our results demonstrate that $\textit{MapFormers}$ significantly outperform current AI architectures, achieving near-perfect OOD generalization where standard models fail. Furthermore, we show that $\textit{MapFormers}$ are scalable; evaluations on naturalistic data yield perplexity improvements over baselines, suggesting that these principles extend to large-scale, real-world domains. These results are obtained through efficient parallel computation on commutative maps, though our models can also learn non-commutative cognitive maps via sequential path-integration. Overall, these results suggest that input-dependent matrices provide a critical structural bias, by disentangling abstract relations from content in order to drive robust OOD generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MapFormers, Transformer variants that learn cognitive maps self-supervised from observational data by updating positional encodings with input-dependent matrices formed as matrix exponentials of learned linear combinations of Lie-algebra generators. Two variants unify absolute and relative positional encodings to model episodic and working memory, respectively. The models are evaluated on formal tasks (gating, 2D navigation, Dyck languages) and naturalistic data, with claims of near-perfect OOD generalization and perplexity improvements over baselines, enabled by efficient parallel computation on commutative maps (with sequential path-integration for non-commutative cases).
Significance. If the central empirical claims hold, the work supplies a concrete architectural mechanism for injecting group-theoretic structure into positional encodings, offering a potential route to the relational abstraction and OOD robustness that standard Transformers lack. The explicit separation of structure from content via Lie-algebra parametrization, together with the unification of absolute/relative encodings and support for both parallel and sequential map integration, constitutes a substantive contribution to the literature on inductive biases for sequence models.
major comments (2)
- [§3.2] §3.2 (position-update rule): the manuscript asserts that exponentials of learned combinations of Lie-algebra generators produce updates that disentangle abstract relations from token content, yet provides neither a derivation of this separation property from the underlying group structure nor an invariance argument under content-preserving transformations. Without such a derivation, the mechanistic justification for the headline OOD claim remains incomplete.
- [§5] §5 (experimental section) and associated tables: no ablation is reported that replaces the Lie-algebra parametrization with a simpler input-dependent update (e.g., an MLP directly predicting the update matrix from the current token). Consequently it is impossible to determine whether the reported near-perfect OOD generalization on Dyck languages and navigation tasks is attributable to the group-theoretic construction or to generic increases in capacity and training dynamics.
minor comments (2)
- [§3] The notation for the specific Lie-algebra generators and the precise form of the learned linear combination should be stated explicitly (e.g., with an equation defining the basis matrices) to allow reproduction.
- [Figures 3-5] Figure captions and axis labels in the navigation and Dyck-language plots would benefit from explicit mention of the OOD split definition and the exact metric (accuracy, edit distance, etc.) being plotted.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major point below and have revised the manuscript to strengthen the mechanistic justification and empirical validation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (position-update rule): the manuscript asserts that exponentials of learned combinations of Lie-algebra generators produce updates that disentangle abstract relations from token content, yet provides neither a derivation of this separation property from the underlying group structure nor an invariance argument under content-preserving transformations. Without such a derivation, the mechanistic justification for the headline OOD claim remains incomplete.
Authors: We agree that an explicit derivation would improve the mechanistic grounding. In the revised §3.2 we now include a derivation showing that the update matrix exp(∑ α_k G_k), with coefficients α_k derived from input relations, produces positional shifts that depend solely on the abstract transformation group element and are invariant to content-preserving re-labelings of tokens. The argument proceeds by noting that the Lie-algebra generators span the tangent space of the structure group, so linear combinations encode only relational displacements; the exponential map then yields group elements whose action on positions commutes with any content-only transformation. A short invariance lemma is added to formalize this separation. revision: yes
-
Referee: [§5] §5 (experimental section) and associated tables: no ablation is reported that replaces the Lie-algebra parametrization with a simpler input-dependent update (e.g., an MLP directly predicting the update matrix from the current token). Consequently it is impossible to determine whether the reported near-perfect OOD generalization on Dyck languages and navigation tasks is attributable to the group-theoretic construction or to generic increases in capacity and training dynamics.
Authors: We concur that the current experiments leave open the possibility that gains arise from increased capacity rather than the specific inductive bias. We have therefore added the requested ablation: an MLP that directly regresses the update matrix from the token embedding, keeping parameter count comparable. The new results (now reported in §5 and an additional table) show that the MLP variant improves over standard Transformers but falls well short of near-perfect OOD generalization on the Dyck and navigation suites, whereas MapFormer retains its performance. This indicates that the Lie-algebra parametrization supplies a critical structural bias beyond generic input-dependent updates. revision: yes
Circularity Check
No significant circularity: architectural choice grounded in Lie-algebra structure, not reduced to fitted inputs or self-citation
full rationale
The paper's central mechanism—constructing input-dependent positional updates as exponentials of linear combinations of Lie-algebra generators—is presented as a mathematical ansatz drawn from group theory to achieve disentangling of structure from content. This is not equivalent to the target OOD generalization metric by construction, nor is it a fitted parameter renamed as a prediction. No load-bearing step reduces the claimed near-perfect generalization on Dyck languages or navigation tasks to a self-citation chain or to the same observational data used for training. Empirical results on formal tasks and naturalistic data provide independent falsifiable content. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Lie-algebra generators can be linearly combined and exponentiated to produce matrices that represent structural transformations independent of content.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean, AlexanderDuality.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
action-dependent matrices ... Wa = exp(A) ... path integration ... cumsum ... Lie algebra
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
rotations R_θ on torus/grid for 2D navigation cognitive maps
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Gardner, Erik Hermansen, Marius Pachitariu, Yoram Burak, Nils A
Richard J. Gardner, Erik Hermansen, Marius Pachitariu, Yoram Burak, Nils A. Baas, Ben- jamin A. Dunn, May-Britt Moser, and Edvard I. Moser. Toroidal topology of population activity in grid cells.Nature, 602(7895):123–128, Feb 2022
work page 2022
-
[2]
Whittington, William Dorrell, Timothy E.J
James C.R. Whittington, William Dorrell, Timothy E.J. Behrens, Surya Ganguli, and Mohamady El-Gaby. A tale of two algorithms: Structured slots explain prefrontal sequence memory and are unified with hippocampal cognitive maps.Neuron, 113(2):321–333.e6, Jan 2025
work page 2025
-
[3]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In I. Guyon, U. V on Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
work page 2017
-
[4]
Sparks of artificial general intelligence: Early experiments with gpt-4, 2023
Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, Harsha Nori, Hamid Palangi, Marco Tulio Ribeiro, and Yi Zhang. Sparks of artificial general intelligence: Early experiments with gpt-4, 2023
work page 2023
-
[5]
Levels of agi for operationalizing progress on the path to agi, 2024
Meredith Ringel Morris, Jascha Sohl-dickstein, Noah Fiedel, Tris Warkentin, Allan Dafoe, Aleksandra Faust, Clement Farabet, and Shane Legg. Levels of agi for operationalizing progress on the path to agi, 2024
work page 2024
-
[6]
Chen, Ashesh Rambachan, Jon Kleinberg, and Sendhil Mullainathan
Keyon Vafa, Justin Y . Chen, Ashesh Rambachan, Jon Kleinberg, and Sendhil Mullainathan. Evaluating the world model implicit in a generative model, 2024
work page 2024
-
[7]
Easy problems that llms get wrong, 2024
Sean Williams and James Huckle. Easy problems that llms get wrong, 2024
work page 2024
-
[8]
Right for the wrong reasons: Diagnosing syn- tactic heuristics in natural language inference
Tom McCoy, Ellie Pavlick, and Tal Linzen. Right for the wrong reasons: Diagnosing syn- tactic heuristics in natural language inference. In Anna Korhonen, David Traum, and Lluís Màrquez, editors,Proceedings of the 57th Annual Meeting of the Association for Computa- tional Linguistics, pages 3428–3448, Florence, Italy, July 2019. Association for Computation...
work page 2019
-
[9]
Neural networks and the chomsky hierarchy
Gregoire Deletang, Anian Ruoss, Jordi Grau-Moya, Tim Genewein, Li Kevin Wenliang, Elliot Catt, Chris Cundy, Marcus Hutter, Shane Legg, Joel Veness, and Pedro A Ortega. Neural networks and the chomsky hierarchy. InThe Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[10]
Timothy E.J. Behrens, Timothy H. Muller, James C.R. Whittington, Shirley Mark, Alon B. Baram, Kimberly L. Stachenfeld, and Zeb Kurth-Nelson. What is a cognitive map? organizing knowledge for flexible behavior.Neuron, 100(2):490–509, 2018
work page 2018
-
[11]
Edward C. Tolman. Cognitive maps in rats and men.Psychological Review, 55(4):189–208, 1948
work page 1948
-
[12]
J. O’Keefe and L. Nadel.The hippocampus as a cognitive map. Clarendon Press, Oxford, United Kingdom, 1978
work page 1978
-
[13]
Torkel Hafting, Marianne Fyhn, Sturla Molden, May-Britt Moser, and Edvard I. Moser. Mi- crostructure of a spatial map in the entorhinal cortex.Nature, 436(7052):801–806, Aug 2005
work page 2005
-
[14]
Dmitriy Aronov, Rhino Nevers, and David W. Tank. Mapping of a non-spatial dimension by the hippocampal–entorhinal circuit.Nature, 543(7647):719–722, Mar 2017
work page 2017
-
[15]
Nikolaus Kriegeskorte and Katherine R. Storrs. Grid cells for conceptual spaces?Neuron, 92(2):280–284, 2016
work page 2016
-
[16]
Seongmin A. Park, Douglas S. Miller, and Erie D. Boorman. Inferences on a multidimensional social hierarchy use a grid-like code.Nature Neuroscience, 24(9):1292–1301, Sep 2021
work page 2021
-
[17]
James CR Whittington, Timothy H Muller, Shirley Mark, Guifen Chen, Caswell Barry, Neil Burgess, and Timothy EJ Behrens. The tolman-eichenbaum machine: Unifying space and relational memory through generalisation in the hippocampal formation.bioRxiv, 2019. 23
work page 2019
-
[18]
Freyja Ólafsdóttir, Daniel Bush, and Caswell Barry
H. Freyja Ólafsdóttir, Daniel Bush, and Caswell Barry. The role of hippocampal replay in memory and planning.Current Biology, 28(1):R37–R50, Jan 2018
work page 2018
-
[19]
Howard, Amir Homayoun Javadi, Yichao Yu, Ravi D
Lorelei R. Howard, Amir Homayoun Javadi, Yichao Yu, Ravi D. Mill, Laura C. Morrison, Rebecca Knight, Michelle M. Loftus, Laura Staskute, and Hugo J. Spiers. The hippocampus and entorhinal cortex encode the path and euclidean distances to goals during navigation.Current Biology, 24(12):1331–1340, 2014
work page 2014
-
[20]
Rüdiger Wehner and Mandyam V . Srinivasan. Searching behaviour of desert ants, genus- cataglyphis (formicidae, hymenoptera).Journal of comparative physiology, 142(3):315–338, Sep 1981
work page 1981
-
[21]
Roformer: Enhanced transformer with rotary position embedding, 2023
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023
work page 2023
-
[22]
Whittington, Joseph Warren, and Timothy E.J
James C.R. Whittington, Joseph Warren, and Timothy E.J. Behrens. Relating transformers to models and neural representations of the hippocampal formation, 2022
work page 2022
-
[23]
Hopfield networks is all you need, 2021
Hubert Ramsauer, Bernhard Schäfl, Johannes Lehner, Philipp Seidl, Michael Widrich, Thomas Adler, Lukas Gruber, Markus Holzleitner, Milena Pavlovi´c, Geir Kjetil Sandve, Victor Greiff, David Kreil, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. Hopfield networks is all you need, 2021
work page 2021
-
[24]
Self-attention with relative position repre- sentations, 2018
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position repre- sentations, 2018
work page 2018
-
[25]
Lee, Pan Li, and Zhangyang Wang
Jiajun Zhu, Peihao Wang, Ruisi Cai, Jason D. Lee, Pan Li, and Zhangyang Wang. Rethinking addressing in language models via contexualized equivariant positional encoding, 2025
work page 2025
-
[26]
Contextual position encoding: Learning to count what’s important, 2024
Olga Golovneva, Tianlu Wang, Jason Weston, and Sainbayar Sukhbaatar. Contextual position encoding: Learning to count what’s important, 2024
work page 2024
- [27]
-
[28]
Mamba: Linear-time sequence modeling with selective state spaces, 2024
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2024
work page 2024
-
[29]
William Dorrell, Peter E. Latham, Timothy E. J. Behrens, and James C. R. Whittington. Actionable neural representations: Grid cells from minimal constraints, 2023
work page 2023
-
[30]
Anthony W Knapp and Anthony William Knapp.Lie groups beyond an introduction, volume
-
[31]
Tri Dao and Albert Gu. Transformers are ssms: Generalized models and efficient algorithms through structured state space duality, 2024
work page 2024
-
[32]
Efficiently modeling long sequences with structured state spaces, 2022
Albert Gu, Karan Goel, and Christopher Ré. Efficiently modeling long sequences with structured state spaces, 2022
work page 2022
-
[33]
Li, Madian Khabsa, Han Fang, and Hao Ma
Sinong Wang, Belinda Z. Li, Madian Khabsa, Han Fang, and Hao Ma. Linformer: Self-attention with linear complexity, 2020
work page 2020
-
[34]
Decoupled weight decay regularization, 2019
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019
work page 2019
-
[35]
James C. R. Whittington, Will Dorrell, Surya Ganguli, and Timothy E. J. Behrens. Disentangle- ment with biological constraints: A theory of functional cell types, 2023
work page 2023
-
[36]
Marco Baroni and Roberto Zamparelli. Nouns are vectors, adjectives are matrices: Representing adjective-noun constructions in semantic space. In Hang Li and Lluís Màrquez, editors, Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, pages 1183–1193, Cambridge, MA, October 2010. Association for Computational Linguistics. 24
work page 2010
-
[37]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page 2025
-
[38]
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, Alex Bridgland, Clemens Meyer, Simon A. A. Kohl, Andrew J. Ballard, Andrew Cowie, Bernardino Romera-Paredes, Stanislav Nikolov, Rishub Jain, Jonas Adler, Trevor Back, Stig Petersen, David Reim...
work page 2021
-
[39]
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model, 2024. 25 10 Appendix 10.1MAmPa: Mamba with skew-symmetric block-diagonal matrices As explained in sec.3.4, one only needs to modify the recurrent matrix A:=S=−S ⊤ of selective SSM...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.