Driving in Corner Case: A Real-World Adversarial Closed-Loop Evaluation Platform for End-to-End Autonomous Driving
Pith reviewed 2026-05-16 21:58 UTC · model grok-4.3
The pith
A closed-loop platform generates realistic adversarial corner cases to expose performance drops in end-to-end autonomous driving models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
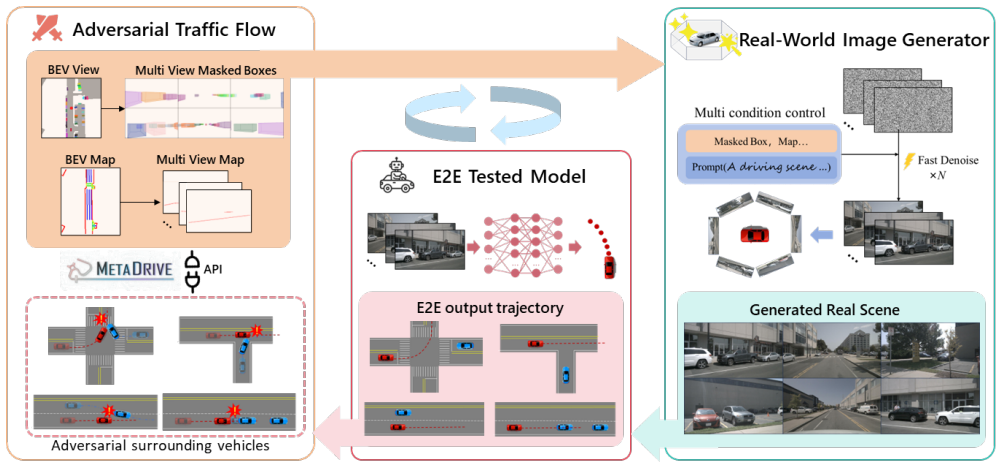
We propose a closed-loop evaluation platform for end-to-end autonomous driving that generates adversarial interactions in real-world scenes. A flow matching-based image generator produces realistic driving images from traffic environment information, while an efficient adversarial surrounding vehicle policy creates challenging interactions. Experiments on models including UniAD and VAD demonstrate performance degradation under the adversarial policy, indicating that the platform can detect potential issues and support improvements in safety and robustness.
What carries the argument
The flow matching-based real-world image generator that produces images from traffic data, paired with an adversarial traffic policy that models challenging vehicle interactions.
If this is right
- The platform generates realistic driving images efficiently and stably for repeated evaluation.
- End-to-end models show measurable performance degradation when exposed to adversarially created corner cases.
- The method identifies potential weaknesses in models trained on real-world data.
- This form of closed-loop testing can guide development toward safer autonomous driving systems.
Where Pith is reading between the lines
- The platform could be looped into training to improve model robustness against rare events.
- Similar adversarial generation might apply to other real-time perception tasks such as robotics navigation.
- Direct comparison of generated images against real camera footage from matching locations would test transfer fidelity.
- Extending the policy to include pedestrians or cyclists could surface additional failure modes not covered by vehicle-only interactions.
Load-bearing premise
The images produced by the flow matching generator are realistic enough that any model failures they trigger would also occur in actual physical driving.
What would settle it
Run the same tested models on physical test-track recreations of the generated scenarios and check whether performance degradation matches the platform's reported drops.
Figures




read the original abstract
Safety-critical corner cases, difficult to collect in the real world, are crucial for evaluating end-to-end autonomous driving. Adversarial interaction is an effective method to generate such safety-critical corner cases. While existing adversarial evaluation methods are built for models operating in simplified simulation environments, adversarial evaluation for real-world end-to-end autonomous driving has been little explored. To address this challenge, we propose a closed-loop evaluation platform for end-to-end autonomous driving, which can generate adversarial interactions in real-world scenes. In our platform, the real-world image generator cooperates with an adversarial traffic policy to evaluate various end-to-end models trained on real-world data. The generator, based on flow matching, efficiently and stably generates real-world images according to the traffic environment information. The efficient adversarial surrounding vehicle policy is designed to model challenging interactions and create corner cases that current autonomous driving systems struggle to handle. Experimental results demonstrate that the platform can generate realistic driving images efficiently. Through evaluating the end-to-end models such as UniAD and VAD, we demonstrate that based on the adversarial policy, our platform evaluates the performance degradation of the tested model in corner cases. This result indicates that this platform can effectively detect the model's potential issues, which will facilitate the safety and robustness of end-to-end autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a closed-loop evaluation platform for end-to-end autonomous driving that generates adversarial interactions in real-world scenes. It combines a flow-matching-based image generator, conditioned on traffic environment information, with an adversarial policy for surrounding vehicles to create safety-critical corner cases. Experiments on models such as UniAD and VAD are used to demonstrate performance degradation under the adversarial policy, with the claim that this detects potential issues in the tested models.
Significance. If the central claims hold, the platform would address a meaningful gap in evaluating end-to-end autonomous driving systems under realistic safety-critical conditions that are difficult to collect in the wild. The combination of generative image synthesis with closed-loop adversarial traffic modeling is a reasonable direction for the field. However, the significance is currently constrained by the absence of quantitative support for image realism and degradation attribution.
major comments (2)
- Abstract: the claim that the platform 'evaluates the performance degradation' of UniAD and VAD is unsupported because the abstract (and, per the provided description, the manuscript) supplies no quantitative metrics, error bars, baseline comparisons, or measurement details, leaving the central claim with limited evidential support.
- Abstract: the assertion that the flow-matching generator produces 'realistic driving images' is load-bearing for attributing any observed degradation to genuine corner-case interactions rather than generator artifacts, yet no validation (FID, LPIPS, human studies, or ablation isolating policy effects from image quality) is reported.
minor comments (1)
- Abstract: consider defining acronyms (UniAD, VAD) at first use and specifying the exact performance metrics used to quantify degradation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We have revised the manuscript to strengthen the quantitative support for the central claims, as outlined in the point-by-point responses below.
read point-by-point responses
-
Referee: Abstract: the claim that the platform 'evaluates the performance degradation' of UniAD and VAD is unsupported because the abstract (and, per the provided description, the manuscript) supplies no quantitative metrics, error bars, baseline comparisons, or measurement details, leaving the central claim with limited evidential support.
Authors: We agree that the abstract would benefit from explicit quantitative support. In the revised manuscript, we have updated the abstract to report specific metrics, including collision rate increases (UniAD: 4.2% ± 1.1% to 28.7% ± 3.5%; VAD: 3.8% ± 0.9% to 31.2% ± 4.1%) and success rate drops under the adversarial policy versus non-adversarial baselines. The full text now includes tables with these results, error bars from five independent runs, and a clear description of the closed-loop measurement protocol (e.g., failure defined as collision or off-road deviation within 10 seconds). revision: yes
-
Referee: Abstract: the assertion that the flow-matching generator produces 'realistic driving images' is load-bearing for attributing any observed degradation to genuine corner-case interactions rather than generator artifacts, yet no validation (FID, LPIPS, human studies, or ablation isolating policy effects from image quality) is reported.
Authors: We acknowledge the need for explicit validation of image realism. The revised manuscript adds a new subsection with quantitative results: FID score of 15.8 (vs. 22.4 for a baseline diffusion model), LPIPS of 0.12, and a human study with 100 participants (78% rated images as realistic or highly realistic on a 5-point scale). We also include an ablation comparing driving model performance on generated images versus real images under identical adversarial trajectories, confirming consistent degradation patterns and isolating the policy effect from generation artifacts. revision: yes
Circularity Check
No circularity: platform evaluation uses external models and reports empirical degradation without self-referential reductions
full rationale
The paper presents a closed-loop platform combining a flow-matching image generator with an adversarial traffic policy to expose corner-case failures in external end-to-end models (UniAD, VAD). No equations, fitted parameters, or predictions are defined in terms of one another; the generator produces images conditioned on traffic state, and degradation is measured directly on the tested models. No self-citations serve as load-bearing uniqueness theorems, no ansatzes are smuggled, and no known results are renamed as novel derivations. The work is therefore self-contained against external benchmarks, with any realism concerns falling under correctness rather than circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow matching can efficiently and stably generate realistic real-world driving images from traffic environment information.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The generator, based on flow matching, efficiently and stably generates real-world images according to the traffic environment information... Score(τ_i) = p_i · (c_i)^{w_c} · e^{-w_j J(τ_i)}
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_fourth_deriv_at_zero unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
flow matching... reformulating the stochastic differential equation (SDE) of the diffusion process into a deterministic ordinary differential equation (ODE)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Xiaomi OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
OneVL is the first latent CoT method to exceed explicit CoT accuracy on four driving benchmarks while running at answer-only speed, by supervising latent tokens with a visual world model decoder.
-
Xiaomi OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
OneVL achieves superior accuracy to explicit chain-of-thought reasoning at answer-only latency by supervising latent tokens with a visual world model decoder that predicts future frames.
-
From Research to Practice: An Interactive Rapid Review of Autonomous Driving System Testing in Industry
Industry practitioners identified 12 ADS testing challenges, prioritized two for end-to-end systems, and found that most of the 17 examined research studies lack direct applicability to real industrial contexts.
Reference graph
Works this paper leans on
-
[1]
Recent advancements in end-to-end au- tonomous driving using deep learning: A survey,
P. S. Chib and P. Singh, “Recent advancements in end-to-end au- tonomous driving using deep learning: A survey,”IEEE Transactions on Intelligent Vehicles, vol. 9, no. 1, pp. 103–118, 2023
work page 2023
-
[2]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[3]
Planning-oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wanget al., “Planning-oriented autonomous driving,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 17 853–17 862
work page 2023
-
[4]
Vad: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “Vad: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 8340–8350
work page 2023
-
[5]
H. Wang, P. Cai, R. Fan, Y . Sun, and M. Liu, “End-to-end interactive prediction and planning with optical flow distillation for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 2229–2238
work page 2021
-
[6]
King: Generating safety-critical driving scenarios for robust imitation via kinematics gradients,
N. Hanselmann, K. Renz, K. Chitta, A. Bhattacharyya, and A. Geiger, “King: Generating safety-critical driving scenarios for robust imitation via kinematics gradients,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 335–352
work page 2022
-
[7]
Generat- ing useful accident-prone driving scenarios via a learned traffic prior,
D. Rempe, J. Philion, L. J. Guibas, S. Fidler, and O. Litany, “Generat- ing useful accident-prone driving scenarios via a learned traffic prior,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 305–17 315
work page 2022
-
[8]
Advsim: Generating safety-critical scenarios for self- driving vehicles,
J. Wang, A. Pun, J. Tu, S. Manivasagam, A. Sadat, S. Casas, M. Ren, and R. Urtasun, “Advsim: Generating safety-critical scenarios for self- driving vehicles,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9909–9918
work page 2021
-
[9]
Multimodal safety-critical scenarios generation for decision-making algorithms evaluation,
W. Ding, B. Chen, B. Li, K. J. Eun, and D. Zhao, “Multimodal safety-critical scenarios generation for decision-making algorithms evaluation,”IEEE Robotics and Automation Letters, vol. 6, no. 2, pp. 1551–1558, 2021
work page 2021
-
[10]
Adversarial evaluation of autonomous vehicles in lane-change scenarios,
B. Chen, X. Chen, Q. Wu, and L. Li, “Adversarial evaluation of autonomous vehicles in lane-change scenarios,”IEEE transactions on intelligent transportation systems, vol. 23, no. 8, pp. 10 333–10 342, 2021
work page 2021
-
[11]
Carla: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “Carla: An open urban driving simulator,” inConference on robot learning. PMLR, 2017, pp. 1–16
work page 2017
-
[12]
Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning,
Q. Li, Z. Peng, L. Feng, Q. Zhang, Z. Xue, and B. Zhou, “Metadrive: Composing diverse driving scenarios for generalizable reinforcement learning,”IEEE transactions on pattern analysis and machine intelli- gence, vol. 45, no. 3, pp. 3461–3475, 2022
work page 2022
-
[13]
Recent development and applications of sumo-simulation of urban mobility,
D. Krajzewicz, J. Erdmann, M. Behrisch, L. Biekeret al., “Recent development and applications of sumo-simulation of urban mobility,” International journal on advances in systems and measurements, vol. 5, no. 3&4, pp. 128–138, 2012
work page 2012
-
[14]
GAIA-1: A Generative World Model for Autonomous Driving
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado, “Gaia-1: A generative world model for autonomous driving,”arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Y . Wang, J. He, L. Fan, H. Li, Y . Chen, and Z. Zhang, “Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 749–14 759
work page 2024
-
[16]
Drive- dreamer: Towards real-world-drive world models for autonomous driving,
X. Wang, Z. Zhu, G. Huang, X. Chen, J. Zhu, and J. Lu, “Drive- dreamer: Towards real-world-drive world models for autonomous driving,” inEuropean conference on computer vision. Springer, 2024, pp. 55–72
work page 2024
-
[17]
Street-view image generation from a bird’s-eye view layout,
A. Swerdlow, R. Xu, and B. Zhou, “Street-view image generation from a bird’s-eye view layout,”IEEE Robotics and Automation Letters, vol. 9, no. 4, pp. 3578–3585, 2024
work page 2024
-
[18]
arXiv preprint arXiv:2308.01661 (2023)
K. Yang, E. Ma, J. Peng, Q. Guo, D. Lin, and K. Yu, “Bevcontrol: Accurately controlling street-view elements with multi-perspective consistency via bev sketch layout,”arXiv preprint arXiv:2308.01661, 2023
-
[19]
Panacea: Panoramic and controllable video generation for autonomous driving,
Y . Wen, Y . Zhao, Y . Liu, F. Jia, Y . Wang, C. Luo, C. Zhang, T. Wang, X. Sun, and X. Zhang, “Panacea: Panoramic and controllable video generation for autonomous driving,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 6902–6912
work page 2024
-
[20]
R. Gao, K. Chen, E. Xie, L. Hong, Z. Li, D.-Y . Yeung, and Q. Xu, “Magicdrive: Street view generation with diverse 3d geometry con- trol,”arXiv preprint arXiv:2310.02601, 2023
-
[21]
arXiv preprint arXiv:2505.15880 (2025)
Z. Xu, B. Li, H.-a. Gao, M. Gao, Y . Chen, M. Liu, C. Yan, H. Zhao, S. Feng, and H. Zhao, “Challenger: Affordable adversarial driving video generation,”arXiv preprint arXiv:2505.15880, 2025
-
[22]
Drivearena: A closed-loop generative simulation platform for autonomous driving,
X. Yang, L. Wen, Y . Ma, J. Mei, X. Li, T. Wei, W. Lei, D. Fu, P. Cai, M. Douet al., “Drivearena: A closed-loop generative simulation platform for autonomous driving,”arXiv preprint arXiv:2408.00415, 2024
-
[23]
Training adversarial agents to exploit weaknesses in deep control policies,
S. Kuutti, S. Fallah, and R. Bowden, “Training adversarial agents to exploit weaknesses in deep control policies,” in2020 IEEE Interna- tional Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 108–114
work page 2020
-
[24]
M. Koren, A. Nassar, and M. J. Kochenderfer, “Finding failures in high-fidelity simulation using adaptive stress testing and the backward algorithm,” in2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 5944–5949
work page 2021
-
[25]
Efficient generation of safety-critical scenarios combining dynamic and static scenario parameters,
Z. Wang, X. Li, D. Wei, L. Wang, and Y . Huang, “Efficient generation of safety-critical scenarios combining dynamic and static scenario parameters,”IEEE Transactions on Intelligent Vehicles, 2024
work page 2024
-
[26]
Learning to collide: An adaptive safety-critical scenarios generating method,
W. Ding, B. Chen, M. Xu, and D. Zhao, “Learning to collide: An adaptive safety-critical scenarios generating method,” in2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 2243–2250
work page 2020
-
[27]
Cat: Closed-loop adversarial training for safe end-to-end driving,
L. Zhang, Z. Peng, Q. Li, and B. Zhou, “Cat: Closed-loop adversarial training for safe end-to-end driving,” inConference on Robot Learn- ing. PMLR, 2023, pp. 2357–2372
work page 2023
-
[28]
X. Zhang, Z. Zhou, Z. Wang, Y . Ji, Y . Huang, and H. Chen, “Co-mtp: A cooperative trajectory prediction framework with multi-temporal fu- sion for autonomous driving,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 801–807
work page 2025
-
[29]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,”arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Fast ode-based sampling for diffusion models in around 5 steps,
Z. Zhou, D. Chen, C. Wang, and C. Chen, “Fast ode-based sampling for diffusion models in around 5 steps,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7777–7786
work page 2024
-
[31]
Genie: Higher-order denoising diffusion solvers,
T. Dockhorn, A. Vahdat, and K. Kreis, “Genie: Higher-order denoising diffusion solvers,”Advances in Neural Information Processing Sys- tems, vol. 35, pp. 30 150–30 166, 2022
work page 2022
-
[32]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, and J. Zhu, “Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps,”Advances in neural information processing systems, vol. 35, pp. 5775–5787, 2022
work page 2022
-
[33]
Pseudo numerical methods for diffusion models on manifolds
L. Liu, Y . Ren, Z. Lin, and Z. Zhao, “Pseudo numerical methods for diffusion models on manifolds,”arXiv preprint arXiv:2202.09778, 2022
-
[34]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
High-resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
work page 2022
-
[36]
Denoising Diffusion Implicit Models
J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,”arXiv preprint arXiv:2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
Diff2flow: Training flow matching models via diffusion model alignment,
J. Schusterbauer, M. Gui, F. Fundel, and B. Ommer, “Diff2flow: Training flow matching models via diffusion model alignment,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 28 347–28 357
work page 2025
-
[38]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavoneet al., “Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 28 706– 28 719, 2024
work page 2024
-
[39]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PmLR, 2021, pp. 8748–8763
work page 2021
-
[40]
Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,
S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y . Chai, B. Sapp, C. R. Qi, Y . Zhouet al., “Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9710–9719
work page 2021
-
[41]
Densetnt: End-to-end trajectory pre- diction from dense goal sets,
J. Gu, C. Sun, and H. Zhao, “Densetnt: End-to-end trajectory pre- diction from dense goal sets,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15 303–15 312
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.