Simulation-based inference with neural posterior estimation applied to X-ray spectral fitting -- III Deriving exact posteriors with dimension reduction and importance sampling
Pith reviewed 2026-05-16 21:14 UTC · model grok-4.3
The pith
Auto-encoder compression plus importance sampling turns neural X-ray posteriors into exact matches for nested sampling results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that after training a neural density estimator on the latent representations from a Cash-statistic-trained auto-encoder, applying likelihood-based importance sampling fully corrects approximation errors so that the resulting posteriors become statistically indistinguishable from nested sampling posteriors. Both the auto-encoder and the estimator are trained iteratively over multiple rounds with truncated proposals that concentrate around the target observation. On X-IFU-like simulations the method outperforms PCA and hand-crafted summaries, and the same pipeline applies to lower-resolution instruments while delivering order-of-magnitude speedups.
What carries the argument
Multi-round neural posterior estimation on spectra compressed by a Cash-statistic auto-encoder, refined by likelihood-based importance sampling.
If this is right
- Posteriors for X-ray spectral parameters become available in seconds rather than minutes or hours while remaining statistically identical to nested-sampling results.
- The same workflow applies without modification to data from X-IFU, Resolve, NICER, and XMM-Newton EPIC-pn across a wide range of spectral resolutions.
- Training in successive rounds with shrinking proposal distributions reduces the number of required simulations and therefore the overall compute time.
- The auto-encoder with Cash-statistic loss retains more parameter-relevant information than PCA or fixed summary statistics.
Where Pith is reading between the lines
- The pipeline could support real-time analysis of transient X-ray sources or large survey catalogs where nested sampling is currently too slow.
- Because importance sampling only needs an evaluable likelihood, the method may extend directly to other astronomical domains that already possess forward simulators but lack fast samplers.
- Replacing the auto-encoder with other learned compressors could test whether the same correction step works for even higher-dimensional data such as integral-field spectroscopy or time-resolved light curves.
Load-bearing premise
The auto-encoder must capture every piece of information in the spectrum that matters for the spectral parameters, and the importance sampling step must completely remove any remaining error from the neural approximation.
What would settle it
Generate a large set of simulated X-ray spectra with known true parameters, run both the neural-plus-importance-sampling pipeline and nested sampling on each, and check whether the 68 percent and 95 percent credible intervals for the parameters agree within sampling noise; disagreement beyond that noise would falsify the claim.
Figures













read the original abstract
Simulation-based inference (SBI) with neural posterior estimation (NPE) provides rapid X-ray spectral fitting in both Gaussian and Poisson regimes by learning approximate parameter posteriors from simulations. We investigate auto-encoders for compressing high-resolution X-ray spectra, motivated by newAthena X-ray Integral Field Unit (X-IFU), and use likelihood-based importance sampling to refine NPE outputs. Our auto-encoder maps spectra to a low-dimensional latent space and is trained with a custom loss equal to the Cash statistic (C-stat) between simulated and reconstructed spectra. A neural density estimator is then trained on the latent representations. Both models are trained in multiple rounds: at each round, new simulations are drawn from a truncated proposal concentrated around the observation, improving efficiency as the proposal contracts. After NPE convergence, we apply likelihood-based importance sampling to correct the learned posterior. To assess information retention, we train a diagnostic network that predicts the original spectral parameters from the latent space, and we also train a network to learn the likelihood directly to accelerate importance sampling. On X-IFU-like simulations, the auto-encoder and multi-round NPE outperforms PCA and hand-crafted spectral summaries in accuracy and robustness. After importance sampling, the resulting posteriors are statistically indistinguishable from those obtained with nested sampling. On a standard laptop, the full pipeline (simulation, compression, inference, correction) delivers 10x speedups. We further demonstrate the approach on XRISM/Resolve and on lower-resolution NICER and XMM-Newton EPIC-pn data, confirming applicability across instruments and resolutions. Overall, NPE on compressed spectra paired with likelihood-based importance sampling offers an exact yet efficient alternative for Bayesian X-ray spectral fitting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes a pipeline for X-ray spectral fitting that uses auto-encoder compression of spectra (trained with a Cash-statistic loss), multi-round neural posterior estimation in the latent space, and a final likelihood-based importance sampling correction step. The central claim is that the resulting posteriors are statistically indistinguishable from nested sampling results (hence 'exact'), while delivering ~10x speedups on a laptop and generalizing across instruments including X-IFU, XRISM/Resolve, NICER, and XMM-Newton EPIC-pn.
Significance. If the importance-sampling correction recovers posteriors that are statistically indistinguishable from nested sampling despite the learned components, the method would offer a practical route to fast Bayesian inference on high-resolution spectra. The multi-round training with adaptive proposals and the custom C-stat loss for the auto-encoder are concrete engineering contributions that improve efficiency over standard SBI or PCA-based summaries.
major comments (2)
- [Abstract] Abstract and title: the claim that 'after importance sampling, the resulting posteriors are statistically indistinguishable from those obtained with nested sampling' and the title's assertion of 'exact posteriors' rest on the assumption that the importance weights are computed with the true likelihood. The manuscript states that a neural network is trained 'to learn the likelihood directly to accelerate importance sampling'; any residual approximation error in this learned likelihood propagates directly into the weights and therefore into the corrected posterior, so the indistinguishability result must be demonstrated with the exact Cash statistic rather than the learned surrogate.
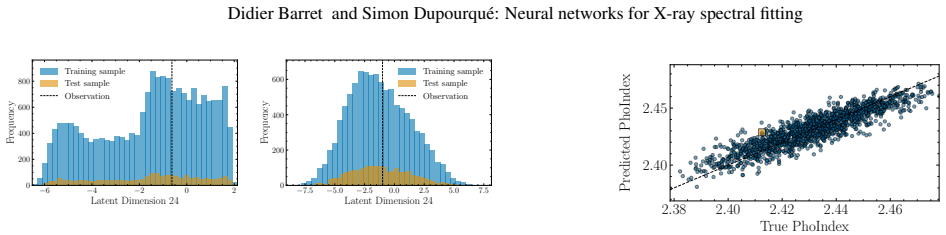
- [Methods] Auto-encoder and diagnostic network section: the claim that the latent representation retains all information relevant to the spectral parameters is load-bearing for the dimension-reduction step. The diagnostic network that predicts parameters from the latent space is mentioned, but no quantitative metrics (e.g., bias or variance inflation relative to uncompressed spectra, or mutual information between latent variables and parameters) are reported; without these, it is impossible to verify that the compression does not introduce an irreversible information bottleneck before the NPE and IS stages.
minor comments (2)
- [Abstract] The abstract reports '10x speedups' without specifying the baseline (direct nested sampling on full spectra?) or breaking down wall-clock time among simulation, training, inference, and IS stages; adding these details would make the efficiency claim more reproducible.
- [Methods] Notation for the multi-round proposal truncation and the exact form of the importance weights (especially whether they use the learned or exact likelihood) should be defined explicitly in the methods section to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive review. We address each major comment below, agreeing where revisions are needed to strengthen the claims and providing clarifications based on the manuscript content.
read point-by-point responses
-
Referee: [Abstract] Abstract and title: the claim that 'after importance sampling, the resulting posteriors are statistically indistinguishable from those obtained with nested sampling' and the title's assertion of 'exact posteriors' rest on the assumption that the importance weights are computed with the true likelihood. The manuscript states that a neural network is trained 'to learn the likelihood directly to accelerate importance sampling'; any residual approximation error in this learned likelihood propagates directly into the weights and therefore into the corrected posterior, so the indistinguishability result must be demonstrated with the exact Cash statistic rather than the learned surrogate.
Authors: We agree that a rigorous claim of 'exact' posteriors requires the importance sampling (IS) correction to use the true likelihood (exact Cash statistic). The manuscript trains a network to learn the likelihood for computational acceleration during IS, and reports that the resulting posteriors are statistically indistinguishable from nested sampling. To directly address the concern, we will revise the manuscript by adding a comparison in the results section: recomputing the IS weights on the same NPE samples using the exact Cash statistic and showing that the corrected posteriors remain statistically indistinguishable (with negligible differences from the learned-likelihood version). We will update the abstract and title to clarify that 'exact' refers to the final IS step with the true likelihood, and report the accuracy of the learned likelihood approximator (e.g., via residual statistics on held-out simulations). revision: yes
-
Referee: [Methods] Auto-encoder and diagnostic network section: the claim that the latent representation retains all information relevant to the spectral parameters is load-bearing for the dimension-reduction step. The diagnostic network that predicts parameters from the latent space is mentioned, but no quantitative metrics (e.g., bias or variance inflation relative to uncompressed spectra, or mutual information between latent variables and parameters) are reported; without these, it is impossible to verify that the compression does not introduce an irreversible information bottleneck before the NPE and IS stages.
Authors: We acknowledge that while the diagnostic network is described in the manuscript as a means to assess information retention, explicit quantitative metrics were not provided in the original text. In the revised version, we will add a new subsection (or expanded table) reporting quantitative diagnostics for the auto-encoder, including: (i) mean squared error, bias, and variance of parameter predictions from the latent space versus predictions from uncompressed spectra; (ii) mutual information estimates between latent variables and spectral parameters; and (iii) comparison of posterior widths or credible intervals obtained with and without compression to quantify any variance inflation. These additions will directly verify that the compression step does not introduce an irreversible information bottleneck. revision: yes
Circularity Check
No significant circularity: derivation grounded in external simulations and true likelihood
full rationale
The paper trains an auto-encoder with a Cash-statistic loss on simulated spectra, trains an NPE on the resulting latent space using multi-round proposals drawn from simulations, and then applies importance sampling that reweights using the likelihood (with an optional learned-likelihood network only for acceleration). The central claim that the corrected posteriors are statistically indistinguishable from nested sampling is presented as an empirical outcome verified on X-IFU-like simulations against an independent nested-sampling run that uses the exact Cash statistic. No equation or step reduces a prediction to a fitted quantity by construction, no uniqueness theorem is imported from self-citation to force the result, and the information-retention diagnostic is a separate check rather than a definitional loop. The pipeline therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- latent dimension
- number of training rounds
axioms (2)
- domain assumption Neural networks can learn an accurate mapping from compressed spectra to parameter posteriors when trained on sufficient simulations.
- domain assumption Importance sampling with the true likelihood corrects any bias in the neural posterior estimate.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
auto-encoder ... trained by minimizing a custom loss equal to the Cash statistic (C-stat) between the simulated and reconstructed spectra
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
likelihood-based importance sampling to refine NPE outputs ... neural network that learns the likelihood function directly
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2508.12939 , year=
Abadi, M., Agarwal, A., Barham, P., et al. 2015, TensorFlow: Large-Scale Ma- chine Learning on Heterogeneous Systems, software available from tensor- flow.org Antonelli, V ., Pietschner, D., Strecker, R., et al. 2024, in Society of Photo-Optical Instrumentation Engineers (SPIE) Conference Series, V ol. 13093, Space Tele- scopes and Instrumentation 2024: U...
-
[2]
Appendix C: Application toXMM-Newtondata We aim to illustrate the signature of an under-trained neural den- sity estimator. To this end, we analyze theXMM-NewtonEPIC- PN spectrum of the ultra-luminous X-ray source ULX-4 in NGC 7793, as retrieved by Quintin et al. (2021). We adopt the same spectral model as in Dupourqué et al. (2024), comprising an ab- sor...
work page 2021
-
[3]
Subsequently, we apply weighted importance sampling, evaluating 400,000 likelihoods via exact computation, which is fast due to the high simulation speed. For comparison, we perform a secondSIXSArun using a larger training set of 2,500 spectra, still relatively small by recommended guidelines as listed above. Figure C.1 contrasts the resultingSIXSAposte- ...
work page 2008
-
[4]
SIXSA (AE 64, WIS, 25000) jaxspec Fig. C.2.JSD of theSIXSAposteriors corrected by weighted importance sampling with respect to theBXAposteriors. Four training sample sizes are considered for the neural density estimator : 500, 2500, 5,000 and 25,000 respectively. The horizontal dashed lines indicate the limit under which the posterior distributions can be...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.