ASVspoof 5: Evaluation of Spoofing, Deepfake, and Adversarial Attack Detection Using Crowdsourced Speech
Pith reviewed 2026-05-16 16:30 UTC · model grok-4.3
The pith
Speech spoofing detectors perform well on crowdsourced data but lose accuracy under adversarial attacks and neural compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
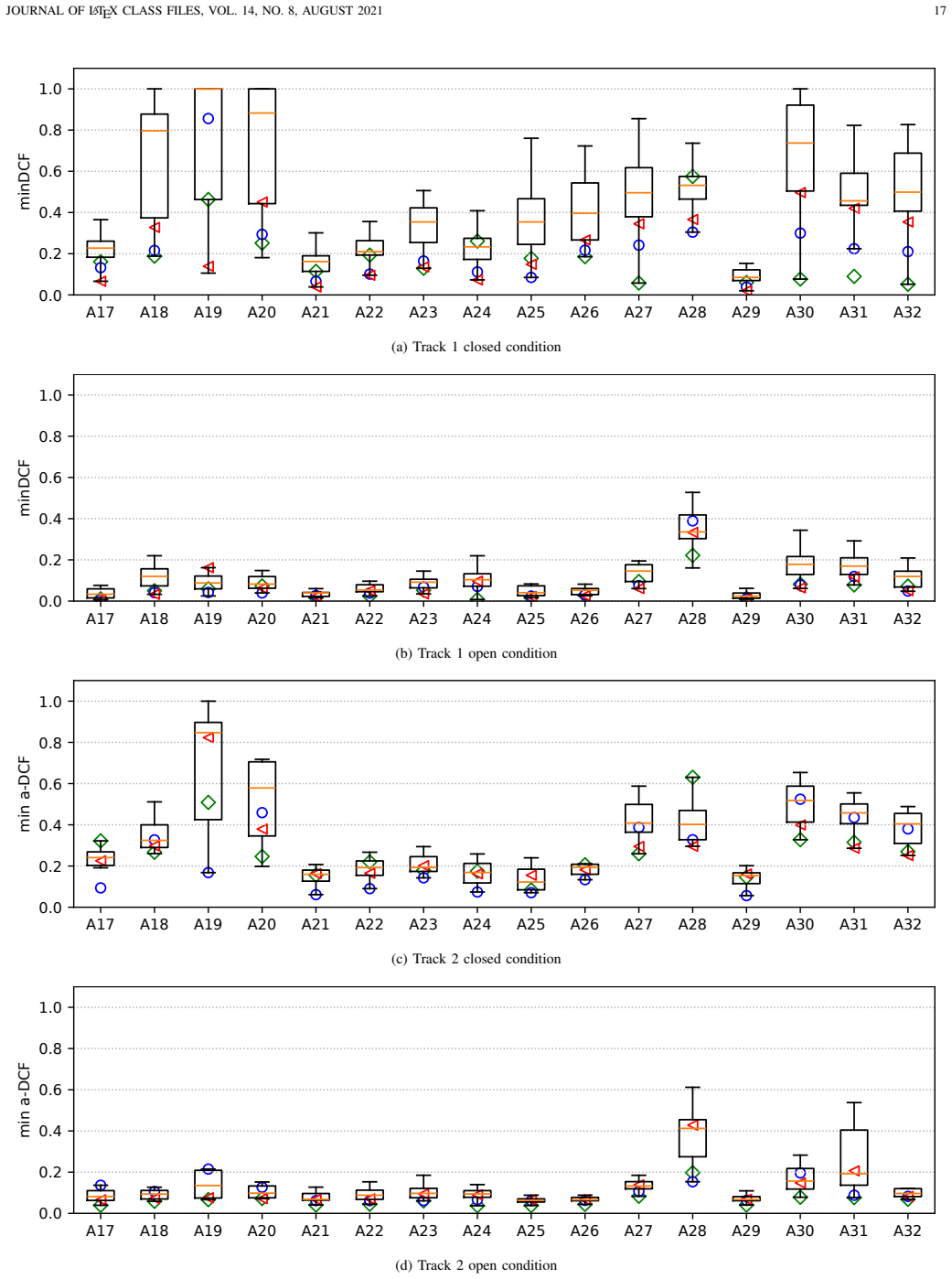
The paper reports that while many submitted detection systems achieve good performance on the new crowdsourced ASVspoof 5 database, their effectiveness decreases markedly when the same data is subjected to adversarial attacks or neural encoding and compression schemes, and it provides post-challenge analysis along with a calibration study to outline remaining challenges.
What carries the argument
The crowdsourced speech database with diverse speakers and recording conditions, evaluated against a mix of generative technologies plus adversarial and compression distortions.
If this is right
- Detection systems must incorporate defenses against adversarial perturbations to stay effective.
- Neural audio codecs introduce a new vulnerability that current methods do not handle well.
- Score calibration becomes essential for any practical use of these detectors.
- Future evaluations should include more advanced attack types and compression pipelines.
Where Pith is reading between the lines
- In deployed voice biometrics, these weaknesses could let attackers bypass authentication with modest effort.
- Hybrid detectors that combine multiple cues might reduce the observed performance drops.
- Testing the same systems on live telephone or streaming audio would provide a direct check on the reported trends.
Load-bearing premise
The crowdsourced database and chosen mix of generative technologies represent real-world spoofing threats and recording conditions reliably enough for evaluation.
What would settle it
Demonstration that the top-performing systems retain their high accuracy when the same evaluation data is modified by adversarial attacks and neural compression.
Figures








read the original abstract
ASVspoof 5 is the fifth edition in a series of challenges which promote the study of speech spoofing and deepfake detection solutions. A significant change from previous challenge editions is a new crowdsourced database collected from a substantially greater number of speakers under diverse recording conditions, and a mix of cutting-edge and legacy generative speech technology. With the new database described elsewhere, we provide in this paper an overview of the ASVspoof 5 challenge results for the submissions of 53 participating teams. While many solutions perform well, performance degrades under adversarial attacks and the application of neural encoding/compression schemes. Together with a review of post-challenge results, we also report a study of calibration in addition to other principal challenges and outline a road-map for the future of ASVspoof.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the results of the ASVspoof 5 challenge, the fifth in a series focused on speech spoofing and deepfake detection. It introduces a new crowdsourced database collected from a large number of speakers under diverse conditions, combined with both cutting-edge and legacy generative speech technologies. Based on submissions from 53 teams, the paper reports that many detection solutions perform well but experience performance degradation when subjected to adversarial attacks or neural encoding and compression schemes. Additionally, it reviews post-challenge results, examines calibration issues, and proposes a roadmap for future developments in the field.
Significance. This work is significant for the speech processing community as it provides an empirical benchmark for the robustness of spoofing detection systems against emerging threats like adversarial attacks and compression artifacts. The crowdsourced nature of the database aims to better reflect real-world variability, potentially leading to more reliable evaluations. If the degradation findings are confirmed with detailed metrics, they could influence the design of future detection algorithms and challenge protocols. The inclusion of calibration studies adds practical value for deployment scenarios.
major comments (2)
- [Abstract] Abstract: The central claim that performance degrades under adversarial attacks and neural encoding/compression schemes is stated without specific quantitative metrics (e.g., EER or t-DCF values pre- and post-attack), baseline comparisons, or statistical significance tests, which are required to substantiate the magnitude and reliability of the degradation across the 53 teams.
- [Challenge results] Challenge results section: The assessment of database representativeness does not address potential interactions between crowdsourcing-induced factors (microphone variability, background noise, channel effects) and attack types; without such analysis or controls, the observed degradation risks being dataset-specific rather than a general property of the detectors.
minor comments (2)
- [Roadmap] The roadmap for future ASVspoof editions could include more concrete milestones, such as specific metrics for robustness testing or plans for controlled recording conditions.
- [Throughout] Notation for performance metrics (e.g., any use of EER or t-DCF) should be defined on first use with reference to prior ASVspoof editions for consistency.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and recommendations. We provide point-by-point responses below and outline the revisions to be made in the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that performance degrades under adversarial attacks and neural encoding/compression schemes is stated without specific quantitative metrics (e.g., EER or t-DCF values pre- and post-attack), baseline comparisons, or statistical significance tests, which are required to substantiate the magnitude and reliability of the degradation across the 53 teams.
Authors: We agree that the abstract would benefit from explicit quantitative support. The full manuscript presents detailed EER and t-DCF results across the 53 submissions that demonstrate the degradation under both adversarial attacks and neural encoding/compression schemes, together with baseline comparisons. We will revise the abstract to include representative pre- and post-attack metrics and to reference the consistency observed across teams. revision: yes
-
Referee: [Challenge results] Challenge results section: The assessment of database representativeness does not address potential interactions between crowdsourcing-induced factors (microphone variability, background noise, channel effects) and attack types; without such analysis or controls, the observed degradation risks being dataset-specific rather than a general property of the detectors.
Authors: We acknowledge the value of examining interactions between crowdsourcing factors and attack types. The manuscript emphasizes that the crowdsourced database was designed to reflect real-world variability and that degradation is observed consistently across a broad range of attack types and the 53 submitted systems. A dedicated interaction analysis is not present in the current version. We will add a concise discussion of this issue in the challenge results section, noting the observed consistency while acknowledging that further controlled experiments would strengthen claims of generality. revision: partial
Circularity Check
Empirical challenge evaluation with no derivation chain
full rationale
The paper reports empirical results from the ASVspoof 5 challenge involving 53 teams on a crowdsourced speech database. No mathematical derivations, equations, or first-principles predictions are presented; performance metrics are direct outcomes of submitted systems evaluated on held-out data. The central observations (degradation under adversarial attacks and neural encoding) are measured quantities, not quantities fitted or defined in terms of themselves. Self-citations to prior ASVspoof editions describe the series history but do not bear the load of any claim. The work is self-contained as a benchmark report against external submissions and does not reduce any result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard ASVspoof evaluation metrics and protocols are appropriate for assessing detection performance across submissions.
Reference graph
Works this paper leans on
-
[1]
ISO/IEC 30107. Information technology – biometric presentation attack detection,
“ISO/IEC 30107. Information technology – biometric presentation attack detection,” Standard, 2016
work page 2016
-
[2]
Spoofing and countermeasures for speaker verification: A survey,
Z. Wu et al., “Spoofing and countermeasures for speaker verification: A survey,”speech communication, vol. 66, pp. 130–153, 2015
work page 2015
-
[3]
YourTTS: Towards zero-shot multi-speaker TTS and zero-shot voice conversion for everyone,
E. Casanova et al., “YourTTS: Towards zero-shot multi-speaker TTS and zero-shot voice conversion for everyone,” inProc. ICML, 2022, pp. 2709–2720
work page 2022
-
[4]
Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers,
S. Chen et al., “Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers,”IEEE Transactions on Audio, Speech and Language Processing, vol. 33, pp. 705–718, 2025
work page 2025
-
[5]
ESPnet-TTS: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit,
T. Hayashi et al., “ESPnet-TTS: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit,” inProc. ICASSP, 2020, pp. 7654–7658
work page 2020
-
[6]
Eren and The Coqui TTS Team,Coqui TTS, version 1.4, Jan
G. Eren and The Coqui TTS Team,Coqui TTS, version 1.4, Jan. 2021
work page 2021
-
[7]
The IMS Toucan system for the Blizzard Challenge 2021,
F. Lux et al., “The IMS Toucan system for the Blizzard Challenge 2021,” inProc. Blizzard Challenge Workshop, 2021, pp. 14–19
work page 2021
-
[8]
Tan,Neural Text-to-Speech Synthesis, en
X. Tan,Neural Text-to-Speech Synthesis, en. Springer Nature Singa- pore, 2023
work page 2023
-
[9]
Harper et al.,NeMo: a toolkit for Conversational AI and Large Language Models
E. Harper et al.,NeMo: a toolkit for Conversational AI and Large Language Models
-
[10]
ElevenLabs,ElevenLabs Python Library
-
[11]
ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,
X. Liu et al., “ASVspoof 2021: Towards spoofed and deepfake speech detection in the wild,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 31, pp. 2507–2522, 2023
work page 2021
-
[12]
Natural TTS synthesis by conditioning wavenet on Mel spectrogram predictions,
J. Shen et al., “Natural TTS synthesis by conditioning wavenet on Mel spectrogram predictions,” inProc. ICASSP, 2018, pp. 4779–4783
work page 2018
-
[13]
ADD 2022: The first audio deep synthesis detection challenge,
J. Yi et al., “ADD 2022: The first audio deep synthesis detection challenge,” inProc. ICASSP, 2022, pp. 9216–9220
work page 2022
-
[14]
ADD 2023: The Second Audio Deepfake Detection Challenge,
J. Yi et al., “ADD 2023: The Second Audio Deepfake Detection Challenge,” inProc. IJCAI DADA Workshop, May 2023
work page 2023
-
[15]
SAFE: Synthetic Audio Forensics Evaluation Chal- lenge,
T. Kirill et al., “SAFE: Synthetic Audio Forensics Evaluation Chal- lenge,” inProc. ACM IH&MMSEC Workshop, 2025, pp. 174–180
work page 2025
-
[16]
N. M ¨uller,Using mlaad for source tracing of audio deepfakes, https: //deepfake-total.com/sourcetracing, Fraunhofer AISEC, Nov. 2024
work page 2024
-
[17]
ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge,
Z. Wu et al., “ASVspoof 2015: The first automatic speaker verification spoofing and countermeasures challenge,” inProc. Interspeech, 2015, pp. 2037–2041
work page 2015
-
[18]
WaveNet: A Generative Model for Raw Audio
A. v. d. Oord et al., “Wavenet: A generative model for raw audio,” arXiv preprint arXiv:1609.03499, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[19]
Tacotron: Towards End-to-End Speech Synthesis,
Y . Wang et al., “Tacotron: Towards End-to-End Speech Synthesis,” in Proc. Interspeech, 2017, pp. 4006–4010
work page 2017
-
[20]
V oice Conversion Challenge 2020 — Intra-lingual semi-parallel and cross-lingual voice conversion —,
Y . Zhao et al., “V oice Conversion Challenge 2020 — Intra-lingual semi-parallel and cross-lingual voice conversion —,” inProc. Joint Workshop for the Blizzard Challenge and Voice Conversion Challenge 2020, 2020, pp. 80–98
work page 2020
-
[21]
X. Wang et al., “Asvspoof 5: Design, collection and validation of resources for spoofing, deepfake, and adversarial attack detection using crowdsourced speech,”Computer Speech & Language, vol. 95, p. 101 825, 2026
work page 2026
-
[22]
ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,
X. Wang et al., “ASVspoof 5: Crowdsourced speech data, deepfakes, and adversarial attacks at scale,” inProc. ASVspoof Workshop, 2024, pp. 1–8
work page 2024
-
[23]
Application-independent evaluation of speaker detection,
N. Br ¨ummer and J. du Preez, “Application-independent evaluation of speaker detection,”Computer Speech & Language, vol. 20, no. 2, pp. 230–275, 2006
work page 2006
-
[24]
a-DCF: An architecture ag- nostic metric with application to spoofing-robust speaker verification,
H.-j. Shim, J.-w. Jung, T. Kinnunen, et al., “a-DCF: An architecture ag- nostic metric with application to spoofing-robust speaker verification,” inProc. Speaker Odyssey, 2024, pp. 158–164
work page 2024
-
[25]
Tandem assessment of spoofing countermeasures and automatic speaker verification: Funda- mentals,
T. Kinnunen, H. Delgado, N. Evans, et al., “Tandem assessment of spoofing countermeasures and automatic speaker verification: Funda- mentals,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 28, pp. 2195–2210, 2020
work page 2020
-
[26]
t-EER: Parameter-free tandem evaluation of countermeasures and biometric comparators,
T. H. Kinnunen, K. A. Lee, H. Tak, et al., “t-EER: Parameter-free tandem evaluation of countermeasures and biometric comparators,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 2622–2637, 2024
work page 2024
-
[27]
Delgado et al.,ASVspoof 5 evaluation plan (phase 2), 2024
H. Delgado et al.,ASVspoof 5 evaluation plan (phase 2), 2024
work page 2024
-
[28]
MLS: A large-scale multilingual dataset for speech research,
V . Pratap et al., “MLS: A large-scale multilingual dataset for speech research,” inProc. Interspeech, 2020, pp. 2757–2761
work page 2020
-
[29]
M. Panariello et al., “Malafide: a novel adversarial convolutive noise attack against deepfake and spoofing detection systems,” inProc. Interspeech, 2023, pp. 2868–2872
work page 2023
-
[30]
M. Todisco et al., “Malacopula: Adversarial automatic speaker verifi- cation attacks using a neural-based generalised hammerstein model,” inProc. ASVspoof Workshop 2024, 2024, pp. 94–100
work page 2024
-
[31]
Grad-TTS: A diffusion probabilistic model for text- to-speech,
V . Popov et al., “Grad-TTS: A diffusion probabilistic model for text- to-speech,” inProc. ICML, 2021, pp. 8599–8608
work page 2021
-
[32]
Diffusion-based voice conversion with fast maximum likelihood sampling scheme,
V . Popov et al., “Diffusion-based voice conversion with fast maximum likelihood sampling scheme,” inProc. ICLR, 2022
work page 2022
-
[33]
I. Steiner and S. Le Maguer, “Creating new language and voice com- ponents for the updated MaryTTS text-to-speech synthesis platform,” inProc. LREC, 2018, pp. 3171–3175
work page 2018
-
[34]
High fidelity neural audio compression,
A. D ´efossez et al., “High fidelity neural audio compression,”Transac- tions on Machine Learning Research, 2023
work page 2023
-
[35]
Self-supervised speech representation learning: A review,
A. Mohamed et al., “Self-supervised speech representation learning: A review,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1179–1210, Oct. 2022
work page 2022
-
[36]
Investigating self-supervised front ends for speech spoofing countermeasures,
X. Wang and J. Yamagishi, “Investigating self-supervised front ends for speech spoofing countermeasures,” inProc. Odyssey, 2022, pp. 100– 106
work page 2022
-
[37]
H. Tak et al., “Automatic speaker verification spoofing and deepfake detection using Wav2vec 2.0 and data augmentation,” inProc. Odyssey, 2022, pp. 112–119
work page 2022
-
[38]
Audio Deepfake Detection with Self- Supervised XLS-R and SLS Classifier,
Q. Zhang, S. Wen, and T. Hu, “Audio Deepfake Detection with Self- Supervised XLS-R and SLS Classifier,” inProc. ACM MM, 2024, pp. 6765–6773
work page 2024
-
[39]
V oxceleb2: Deep speaker recognition,
J. S. Chung, A. Nagrani, and A. Zisserman, “V oxceleb2: Deep speaker recognition,” inProc. Interspeech, 2018, pp. 1086–1090
work page 2018
-
[40]
Librispeech: An ASR corpus based on public domain audio books,
V . Panayotov et al., “Librispeech: An ASR corpus based on public domain audio books,” inProc. ICASSP, 2015, pp. 5206–5210
work page 2015
-
[41]
J. Yamagishi, C. Veaux, and K. MacDonald,CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92), 2019
work page 2019
-
[42]
Libri-Light: A Benchmark for ASR with Limited or No Supervision,
J. Kahn et al., “Libri-Light: A Benchmark for ASR with Limited or No Supervision,” inProc. ICASSP, May 2020, pp. 7669–7673
work page 2020
-
[43]
J.-w. Jung et al., “Improved RawNet with feature map scaling for text-independent speaker verification using raw waveforms,” inProc. Interspeech, 2020, pp. 1496–1500
work page 2020
-
[44]
End-to-end anti-spoofing with RawNet2,
H. Tak et al., “End-to-end anti-spoofing with RawNet2,” inProc. ICASSP, 2021, pp. 6369–6373
work page 2021
-
[45]
AASIST: Audio anti-spoofing using integrated spectro-temporal graph attention networks,
J.-w. Jung et al., “AASIST: Audio anti-spoofing using integrated spectro-temporal graph attention networks,” inProc. ICASSP, 2022, pp. 6367–6371
work page 2022
-
[46]
SASV 2022: The first spoofing-aware speaker verification challenge,
J.-w. Jung et al., “SASV 2022: The first spoofing-aware speaker verification challenge,” inProc. Interspeech, 2022, pp. 2893–2897
work page 2022
-
[47]
X. Wang et al., “Revisiting and improving scoring fusion for spoofing- aware speaker verification using compositional data analysis,” inProc. Interspeech, 2024, pp. 1110–1114
work page 2024
-
[48]
MFA-conformer: Multi-scale feature aggregation conformer for automatic speaker verification,
Y . Zhang et al., “MFA-conformer: Multi-scale feature aggregation conformer for automatic speaker verification,” inProc. Interspeech, 2022, pp. 306–310
work page 2022
-
[49]
NIST,NIST 2020 CTS Speaker Recognition ChallengeEvaluation Plan, 2020
work page 2020
-
[50]
Ferrer,Calibration tutorial, https://github.com/luferrer/CalibrationTutorial, 2024
L. Ferrer,Calibration tutorial, https://github.com/luferrer/CalibrationTutorial, 2024
work page 2024
-
[51]
N. Br ¨ummer and E. d. Villiers,The BOSARIS Toolkit: Theory, Algo- rithms and Code for Surviving the New DCF, Atlanta, 2011
work page 2011
-
[52]
S. van Lierop et al., “An overview of log likelihood ratio cost in forensic science – where is it used and what values can we expect?” Forensic Science International: Synergy, vol. 8, p. 100 466, 2024
work page 2024
-
[53]
Parallelchain lab’s anti-spoofing systems for asvspoof 5,
T. Tran, T. D. Bui, and P. Simatis, “Parallelchain lab’s anti-spoofing systems for asvspoof 5,” inProc. ASVspoof Workshop, 2024, pp. 9–15
work page 2024
-
[54]
Data augmentations for audio deepfake detection for the asvspoof5 closed condition,
R. Duroselle et al., “Data augmentations for audio deepfake detection for the asvspoof5 closed condition,” inProc. ASVspoof Workshop, 2024, pp. 16–23
work page 2024
-
[55]
USTC-KXDIGIT system description for asvspoof5 challenge,
Y . Chen et al., “USTC-KXDIGIT system description for asvspoof5 challenge,” inProc. ASVspoof Workshop, 2024, pp. 109–115
work page 2024
-
[56]
Intema system description for the asvspoof5 challenge: Power weighted score fusion,
A. Aliyev and A. Kondratev, “Intema system description for the asvspoof5 challenge: Power weighted score fusion,” inProc. ASVspoof Workshop, 2024, pp. 152–157
work page 2024
-
[57]
Exploring wavlm back-ends for speech spoofing and deepfake detection,
T. Stourbe et al., “Exploring wavlm back-ends for speech spoofing and deepfake detection,” inProc. ASVspoof Workshop, 2024, pp. 72–78
work page 2024
-
[58]
Whispeak speech deepfake detection systems for the asvspoof5 challenge,
P. Falez and T. Marteau, “Whispeak speech deepfake detection systems for the asvspoof5 challenge,” inProc. ASVspoof Workshop, 2024, pp. 32–35. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14
work page 2024
-
[59]
Szu-afs antispoofing system for the asvspoof 5 chal- lenge,
Y . Xu et al., “Szu-afs antispoofing system for the asvspoof 5 chal- lenge,” inProc. ASVspoof Workshop, 2024, pp. 64–71
work page 2024
-
[60]
Idvoice team system description for asvspoof5 challenge,
A. Okhotnikov et al., “Idvoice team system description for asvspoof5 challenge,” inProc. ASVspoof Workshop, 2024, pp. 43–47
work page 2024
-
[61]
J. M. Mart ´ın-Do˜nas et al., “ASASVIcomtech: the Vicomtech-UGR speech deepfake detection and SASV systems for the ASVspoof5 Challenge,” inProc. ASVspoof Workshop, 2024, pp. 144–151
work page 2024
-
[62]
Speaker recognition in unconstrained environments.,
A. Nautsch, “Speaker recognition in unconstrained environments.,” Ph.D. dissertation, Darmstadt University of Technology, Germany, 2019
work page 2019
-
[63]
SpecAugment: A simple data augmentation method for automatic speech recognition,
D. S. Park et al., “SpecAugment: A simple data augmentation method for automatic speech recognition,” inProc. Interspeech, 2019, pp. 2613–2617
work page 2019
-
[64]
H. Tak et al., “Rawboost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,” in Proc. ICASSP, 2022, pp. 6382–6386
work page 2022
-
[65]
Deep residual learning for image recognition,
K. He et al., “Deep residual learning for image recognition,” inProc. CVPR, 2016, pp. 770–778
work page 2016
-
[66]
Open source voice creation toolkit for the MARY TTS platform,
M. Schr ¨oder et al., “Open source voice creation toolkit for the MARY TTS platform,” inProc. Interspeech, 2011, pp. 3253–3256
work page 2011
-
[67]
Spoofed speech from the perspective of a forensic phonetician,
C. Kirchh ¨ubel and G. Brown, “Spoofed speech from the perspective of a forensic phonetician,” inProc. Interspeech, 2022, pp. 1308–1312
work page 2022
-
[68]
Wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski et al., “Wav2vec 2.0: A framework for self-supervised learning of speech representations,” inProc. NuerIPS, vol. 33, 2020, pp. 12 449–12 460
work page 2020
-
[69]
Wavlm: Large-scale self-supervised pre-training for full stack speech processing,
S. Chen et al., “Wavlm: Large-scale self-supervised pre-training for full stack speech processing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
work page 2022
-
[70]
An introduction to application- independent evaluation of speaker recognition systems,
D. A. Van Leeuwen and N. Br ¨ummer, “An introduction to application- independent evaluation of speaker recognition systems,” inSpeaker Classification I, Springer, 2007, pp. 330–353
work page 2007
-
[71]
Out of a hundred trials, how many errors does your speaker verifier make?
N. Br ¨ummer, L. Ferrer, and A. Swart, “Out of a hundred trials, how many errors does your speaker verifier make?” InProc. Interspeech, 2021, pp. 1059–1063
work page 2021
-
[72]
Does Audio Deepfake Detection Generalize?
Nicolas M ¨uller and Pavel Czempin and Franziska Diekmann and Adam Froghyar and Konstantin B ¨ottinger, “Does Audio Deepfake Detection Generalize?” InProc. Interspeech, 2022, 2783–2787
work page 2022
-
[73]
Nes2Net: A Lightweight Nested Architecture for Foundation Model Driven Speech Anti-spoofing,
T. Liu et al., “Nes2Net: A Lightweight Nested Architecture for Foundation Model Driven Speech Anti-spoofing,”IEEE Transactions on Information Forensics and Security, Oct. 2025
work page 2025
-
[74]
MoLEx: Mixture of LoRA Experts in Speech Self-Supervised Models for Audio Deepfake Detec- tion,
Z. Pan, S. H. Bhupendra, and J. Wu, “MoLEx: Mixture of LoRA Experts in Speech Self-Supervised Models for Audio Deepfake Detec- tion,” inProc. ASRU, 2025, (accepted)
work page 2025
-
[75]
Mixture of low- rank adapter experts in generalizable audio deepfake detection,
J. Laakkonen, I. Kukanov, and V . Hautam ¨aki, “Mixture of low- rank adapter experts in generalizable audio deepfake detection,”arXiv preprint arXiv:2509.13878, 2025
-
[76]
MLAAD: The Multi-Language Audio Anti- Spoofing Dataset,
N. M. M ¨uller et al., “MLAAD: The Multi-Language Audio Anti- Spoofing Dataset,” inProc. IJCNN, Jun. 2024, pp. 1–7
work page 2024
-
[77]
Revealing Cross-Lingual Bias in Synthetic Speech Detection under Controlled Conditions,
V . Moreno et al., “Revealing Cross-Lingual Bias in Synthetic Speech Detection under Controlled Conditions,” en, in5th Symposium on Security and Privacy in Speech Communication, Aug. 2025, pp. 1–7
work page 2025
-
[78]
Towards quantifying and reducing language mismatch effects in cross-lingual speech anti-spoofing,
T. Liu et al., “Towards quantifying and reducing language mismatch effects in cross-lingual speech anti-spoofing,” inProc. SLT, 2024, pp. 1185–1192
work page 2024
-
[79]
Unmasking real-world audio deepfakes: A data- centric approach,
D. Combei et al., “Unmasking real-world audio deepfakes: A data- centric approach,” inProc. Interspeech, 2025, pp. 5343–5347
work page 2025
-
[80]
An initial investigation for detecting vocoder fingerprints of fake audio,
X. Yan et al., “An initial investigation for detecting vocoder fingerprints of fake audio,” inProceedings of the 1st international workshop on deepfake detection for audio multimedia, 2022, pp. 61–68
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.