The Detection-Extraction Gap: Models Know the Answer Before They Can Say It
Pith reviewed 2026-05-10 18:16 UTC · model grok-4.3
The pith
Language models determine the correct answer early in chain-of-thought but generate most tokens afterward.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across five model configurations, two families, and three benchmarks, 52--88% of chain-of-thought tokens are produced after the answer is recoverable from a partial prefix. Free continuations from early prefixes recover the correct answer even at 10% of the trace, while forced extraction fails on 42% of these cases. The answer is recoverable from the model state, yet prompt-conditioned decoding fails to extract it. The mismatch is formalized via a total-variation bound between free and forced continuation distributions.
What carries the argument
The detection-extraction gap: the mismatch between answers recoverable via free continuations from early prefixes and the failure of prompt-conditioned decoding to extract the same answers.
If this is right
- Black-box Adaptive Early Exit truncates 70-78% of serial generation while improving accuracy by 1-5 percentage points.
- For thinking-mode models, early exit prevents post-commitment overwriting and yields gains up to 5.8 percentage points.
- A cost-optimized variant achieves 68-73% reduction in API calls at a median of 9 calls.
- The total-variation bound provides quantitative estimates of how much the suffix prompt shifts the continuation distribution.
Where Pith is reading between the lines
- Standard decoding may systematically delay the surfacing of knowledge that is already present internally.
- Similar gaps could appear in tasks outside benchmarks, such as factual recall or code generation.
- Direct use of hidden-state probes might bypass text generation and detect knowledge even earlier than free continuations.
Load-bearing premise
Free continuations from early prefixes faithfully reflect the model's internal knowledge state without distortion by the particular continuation prompt or sampling procedure.
What would settle it
If forced extraction from the identical early prefixes recovers the answer at the same rate as free continuations, the claimed gap would not exist.
Figures















read the original abstract
Modern reasoning models continue generating long after the answer is already determined. Across five model configurations, two families, and three benchmarks, we find that 52--88% of chain-of-thought tokens are produced after the answer is recoverable from a partial prefix. This post-commitment generation reveals a structural phenomenon: the detection-extraction gap. Free continuations from early prefixes recover the correct answer even at 10% of the trace, while forced extraction fails on 42% of these cases. The answer is recoverable from the model state, yet prompt-conditioned decoding fails to extract it. We formalize this mismatch via a total-variation bound between free and forced continuation distributions, yielding quantitative estimates of suffix-induced shift. Exploiting this asymmetry, we propose Black-box Adaptive Early Exit (BAEE), which uses free continuations for both detection and extraction, truncating 70--78% of serial generation while improving accuracy by 1--5pp across all models. For thinking-mode models, early exit prevents post-commitment overwriting, yielding gains of up to 5.8pp; a cost-optimized variant achieves 68--73% reduction at a median of 9 API calls. Code is available at https://github.com/EdWangLoDaSc/know2say.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that reasoning models determine the correct answer early in chain-of-thought traces (52-88% of tokens generated post-recovery across five configurations, two families, and three benchmarks), yet forced extraction from the same prefixes fails in 42% of cases. It identifies this as a detection-extraction gap, formalizes the mismatch via a total-variation bound on suffix-induced distributional shift between free and forced continuations, and introduces Black-box Adaptive Early Exit (BAEE) that uses free sampling for both detection and extraction to truncate 70-78% of generation while gaining 1-5pp accuracy (up to 5.8pp for thinking-mode models).
Significance. If the core empirical pattern holds, the work identifies a structural inefficiency in how current models commit to and surface answers during extended reasoning, with direct implications for inference optimization. The BAEE method provides a practical, black-box intervention that reduces serial token generation while preserving or improving accuracy, and the total-variation framing offers a quantitative handle on prompt-induced shifts that could generalize beyond the reported benchmarks.
major comments (3)
- [Experimental protocol section] Experimental protocol section: the central statistic (52-88% post-commitment tokens) relies on free-continuation detection from 10%-prefixes, yet the manuscript provides no ablation or control showing that the continuation template itself is distributionally neutral relative to the original CoT prompt; any cue introduced by the detection prompt would directly inflate early-recovery rates and render the detection-extraction gap partly an artifact of the measurement procedure rather than an intrinsic model property.
- [§4 (total-variation bound)] §4 (total-variation bound): the quantitative estimates of suffix-induced shift are computed from the same observed free/forced continuation pairs used to measure the gap, creating a circular dependence that prevents the bound from serving as an independent validation of the claimed asymmetry.
- [Results tables] Results tables (e.g., Table 2 or equivalent): the reported accuracy gains for BAEE (1-5pp) and early-exit reductions (70-78%) lack error bars, number of runs, or statistical significance tests, so it is impossible to determine whether the improvements are robust across the five model configurations or sensitive to sampling variance.
minor comments (2)
- [Notation] Notation for 'recoverable' is used throughout without a precise, reproducible definition (e.g., majority vote threshold, exact sampling parameters, or prefix length schedule).
- [Results section] The abstract and introduction cite 'three benchmarks' but the results section does not tabulate per-benchmark breakdowns, making it hard to assess whether the 52-88% range is driven by a single outlier task.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below with clarifications and commit to revisions that strengthen the manuscript while remaining faithful to our original findings and experiments.
read point-by-point responses
-
Referee: Experimental protocol section: the central statistic (52-88% post-commitment tokens) relies on free-continuation detection from 10%-prefixes, yet the manuscript provides no ablation or control showing that the continuation template itself is distributionally neutral relative to the original CoT prompt; any cue introduced by the detection prompt would directly inflate early-recovery rates and render the detection-extraction gap partly an artifact of the measurement procedure rather than an intrinsic model property.
Authors: We appreciate the concern about potential distributional effects from the continuation template. Our template is a minimal continuation prompt ('Continue the reasoning from here:') chosen to avoid new instructions. To address this rigorously, we will add an ablation in the revised experimental protocol section comparing multiple neutral templates (empty continuation, varied phrasings, and direct suffix sampling) across a subset of configurations. This will demonstrate that early-recovery rates are robust and not inflated by template choice, confirming the gap as an intrinsic property. revision: yes
-
Referee: §4 (total-variation bound): the quantitative estimates of suffix-induced shift are computed from the same observed free/forced continuation pairs used to measure the gap, creating a circular dependence that prevents the bound from serving as an independent validation of the claimed asymmetry.
Authors: We agree that the total-variation estimates are derived from the same observed pairs and thus serve as a formalization of the measured shift rather than an independent validation. We will revise Section 4 to explicitly clarify this distinction, stating that the bound provides a quantitative handle on the free-vs-forced distributional mismatch to support interpretation of the detection-extraction gap, while the primary evidence remains the direct empirical comparison of answer recovery rates. revision: partial
-
Referee: Results tables (e.g., Table 2 or equivalent): the reported accuracy gains for BAEE (1-5pp) and early-exit reductions (70-78%) lack error bars, number of runs, or statistical significance tests, so it is impossible to determine whether the improvements are robust across the five model configurations or sensitive to sampling variance.
Authors: We acknowledge the need for statistical robustness reporting. In the revised manuscript we will add error bars (standard deviation over multiple independent runs), explicitly state the number of runs per configuration, and include statistical significance tests (e.g., paired t-tests or Wilcoxon tests) for the accuracy gains and token reductions. These will be incorporated into the results tables and discussed in the text. revision: yes
Circularity Check
No significant circularity detected; claims rest on direct empirical measurements.
full rationale
The paper's primary results consist of empirical statistics (52--88% post-commitment tokens, 42% forced-extraction failures) obtained by running free-continuation and forced-extraction experiments across five model configurations, two families, and three benchmarks. The total-variation bound is introduced only as a post-hoc formalization of the observed free/forced mismatch and does not generate any new quantitative predictions that reduce to fitted parameters or prior self-citations by construction. The BAEE method is a practical heuristic that exploits the measured asymmetry rather than deriving its performance from the same inputs it measures. No load-bearing self-citations, uniqueness theorems, or ansatzes appear in the provided abstract or description that would collapse the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Free continuations from partial prefixes recover the model's internal answer state more reliably than prompt-conditioned forced extraction
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Free continuations from early prefixes recover the correct answer even at 10% of the trace, while forced extraction fails on 42% of these cases... formalized via a total-variation bound between free and forced continuation distributions
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BAEE: Black-box Adaptive Early Exit... truncating 70–78% of serial generation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
commitment:PSCmeasures behavioral recoverability, which upper-bounds latent commitment (§5)
Recoverability vs. commitment:PSCmeasures behavioral recoverability, which upper-bounds latent commitment (§5). Multiple controls (difficulty stratification, common-solved subsets, and three-benchmark validation) partially address this gap. 10 Preprint• April 10, 2026
work page 2026
-
[2]
Temporal resolution: The main experiments use 9 checkpoints (10%–90%). To assess sensitivity, we run finer- grained probing on 50 problems with checkpoints at {2%, 4%, 5%, 6%, 8%, 10%, 12%, 15%, 20%, 25%, 30%, 40%, 50%} (Appendix K). PSC agreement at 2% already reaches 90%, confirming that the 10% grid does not artificially inflate post-commitment fractio...
-
[3]
Competition-level mathematics and common-sense reasoning remain future work
Benchmark scope: Results span MATH-500, GPQA-Diamond, and HumanEval (Appendices O, Q), covering math, science, and code generation. Competition-level mathematics and common-sense reasoning remain future work
-
[4]
White-box comparison: Our indirect comparison (§5) shows estimates consistent with white-box reports; a direct comparison on the same model is future work
-
[5]
EFA suffix bias: 9–16% ofEFAprobes on unsolvable problems return “correct” answers; this is accounted for in our gap analysis and does not affectPSC-based metrics
-
[6]
Total-token cost:BAEEtrades serial depth for parallel width, increasing total tokens 3–5 × under empirical continuation lengths (MATH-500: 3.6–5.0×; GPQA-Diamond: 3.1–5.0×; §4.5.3), always below SC-8-full’s fixed 8.0×. Under parallel execution (standard in API deployments), the latency reduction (63–76%) is the operationally relevant metric; in token-budg...
work page 2024
-
[7]
Early-agreement gate: require PSC@10% ≥0.50 . This eliminates 74.2% of FPs while retaining 89.2% of TPs. The intuition is that genuine commitments are evident from the earliest checkpoint; late-onset “commitments” are suspect
-
[8]
Monotonicity check: require ≤2PSCdrops across the trajectory. This eliminates 93.9% of FPs but also removes 39.0% of TPs, making it too aggressive for general use but effective as a high-confidence filter
-
[9]
\boxed{” which biases the model toward emitting whatever is currently “closest to an answer
Variance + non-monotonicity: flag if PSC variance>0.06 anddrops ≥3 . This catches 54.5% of FPs while losing only 9.6% of TPs, making it a practical operating point for deployment. Practical recommendation.For deployment on new domains, we recommend a two-stage protocol: (1) apply the standard θ threshold for early exit; (2) post-filter triggered problems ...
work page 2026
-
[10]
Premature termination(59% of failures): the model emits a short ( ≤2 character) output, typically a single number or symbol. This suggests the forcing suffix triggers an “answer now” reflex that bypasses the model’s normal multi-step evaluation. The analogy is forcing a student to write a final answer mid-calculation: they write whatever is on their scrat...
-
[11]
Intermediate-value extraction(30%): the model outputs a recognizable intermediate result (e.g., an unsimplified expression, a partial sum, or the result of the first step of a nested computation). These failures areinformative: the model has clearly begun the correct computation but has not yet completed it. The gap here is temporal, not informational: th...
-
[12]
Sign/parity errors(11%): the model produces an answer with the correct magnitude but wrong sign, parity, or off-by-one index. These are the closest to “near-misses” and suggest the forcing suffix disrupts bookkeeping operations (tracking alternating signs, counting iterations) that the model maintains implicitly during free generation. Why free continuati...
work page 2026
-
[13]
The null-prefix baseline is substantially lower (59–78% vs 88% on MATH), confirming that GPQA requires genuine multi-step reasoning that cold-start sampling cannot easily replicate
-
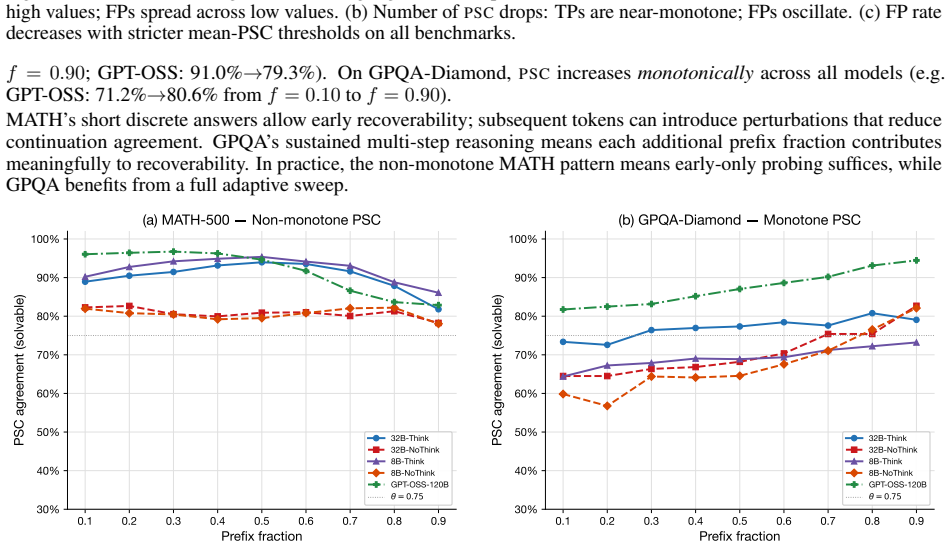
[14]
The prefix’s incremental contributiongrows with prefix length: GPT-OSS gains+3.4 pp at f= 0.10 but +8.8 pp at f= 0.50, consistent with GPQA’s monotonically increasingPSCtrajectory (§4.3). Together, these results paint a coherent picture: the prefix encodes a progressively richer representation of the model’s computation. On easy benchmarks (MATH), the mod...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.