Bayesian Semiparametric Multivariate Density Regression with Coordinate-Wise Predictor Selection
Pith reviewed 2026-05-10 17:25 UTC · model grok-4.3
The pith
A Bayesian semiparametric model uses a Gaussian copula and Tucker tensor factorization to estimate multivariate densities while selecting influential covariates separately for each response coordinate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish that replacing the mode matrices in a Tucker tensor factorization with coordinate-specific random partition models on covariate levels, inside a Gaussian copula framework with shared-atom mixture marginals, yields a model that performs coordinate-wise predictor selection, aggregates similar covariate effects, and supports an efficient MCMC algorithm whose memory and time scale with the number of partitions rather than the original number of covariate levels.
What carries the argument
Tucker tensor factorization with coordinate-specific random partition models on covariate levels, which replaces traditional mode matrices to aggregate similar effects and identify coordinate-specific influential covariates.
If this is right
- Joint densities of multivariate responses can be estimated with flexible marginals whose covariate dependence differs by coordinate.
- The MCMC algorithm reduces memory use and computation time by working only with the aggregated levels identified by the random partitions.
- Similar covariate levels are automatically grouped so that they share the same effect on the mixture weights.
- Coordinate-specific subsets of influential covariates are identified without requiring the same predictors to affect every response dimension.
Where Pith is reading between the lines
- The partition-based aggregation could be adapted to settings with a very large number of categorical levels that would otherwise be computationally intractable.
- The same structure might be combined with other dependence models if the Gaussian copula assumption proves too restrictive in a given application.
- In fields that routinely collect many categorical predictors, such as nutrition or epidemiology, the coordinate-wise selection could produce more interpretable models than methods that force a common predictor set.
Load-bearing premise
The Gaussian copula fully captures the dependence across response coordinates, and the coordinate-specific random partitions correctly group covariate levels that share similar effects without bias or loss of flexibility.
What would settle it
Simulated data drawn from a multivariate distribution whose dependence cannot be represented by any Gaussian copula, or whose covariate effects do not form recoverable partitions, would produce visibly biased density estimates or incorrect coordinate-specific covariate selections.
Figures





read the original abstract
We propose a flexible Bayesian approach for estimating the joint density of a multivariate outcome of interest in the presence of categorical covariates. Leveraging a Gaussian copula framework, our method effectively captures the dependence structure across different coordinates of the multivariate response. The conditional (on covariates) marginal (across outcomes) distributions are modeled as flexible mixtures with shared atoms across coordinates, while the mixture weights are allowed to vary with covariates through a novel Tucker tensor factorization-based structure, which enables the identification of coordinate-specific subsets of influential covariates. In particular, we replace the traditional mode matrices with coordinate-specific random partition models on the covariate levels, offering a flexible mechanism to aggregate covariate levels that exhibit similar effects on the response. Additionally, to handle settings with many covariates, we introduce a Markov chain Monte Carlo algorithm that scales with the number of aggregated levels rather than the original levels, significantly reducing memory requirements and improving computational efficiency. We demonstrate the method's numerical performance through simulation experiments and its practical applicability through the analysis of NHANES dietary data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Bayesian semiparametric model for joint density estimation of a multivariate response given categorical covariates. It links coordinate-wise conditional marginals via a Gaussian copula, represents each marginal as a mixture of shared atoms whose weights depend on covariates through a Tucker tensor factorization, and replaces the factor matrices with coordinate-specific random partition models on covariate levels to induce coordinate-wise selection and aggregation of similar effects. An MCMC sampler is developed whose cost scales with the number of aggregated partition levels rather than the raw covariate cardinality; the approach is illustrated on simulations and NHANES dietary data.
Significance. If the central construction is valid, the method supplies a coherent way to perform flexible multivariate density regression while automatically selecting influential covariates separately for each response coordinate and borrowing strength across coordinates via shared atoms. The random-partition device for level aggregation and the resulting MCMC scaling are potentially useful in settings with many categorical predictors.
major comments (2)
- [§3.2] §3.2, the Tucker factorization with coordinate-specific partitions: the paper must demonstrate that the posterior on the partition allocations identifies the coordinate-specific influential subsets without confounding the shared-atom locations or the copula parameters; a formal identifiability argument or simulation recovery study under known sparse structure is needed.
- [§4.3] §4.3, MCMC complexity claim: the statement that the sampler scales with the number of aggregated levels rather than original levels is load-bearing for the efficiency contribution; the reported wall-clock times and effective sample sizes in the simulation study (Table 2) should be accompanied by a direct comparison against a non-aggregated baseline on the same data sets.
minor comments (2)
- [Abstract and §2.1] The abstract and §2.1 refer to 'shared atoms across coordinates' but do not state whether the atom locations are drawn from a common base measure or estimated separately; a brief clarifying sentence would remove ambiguity.
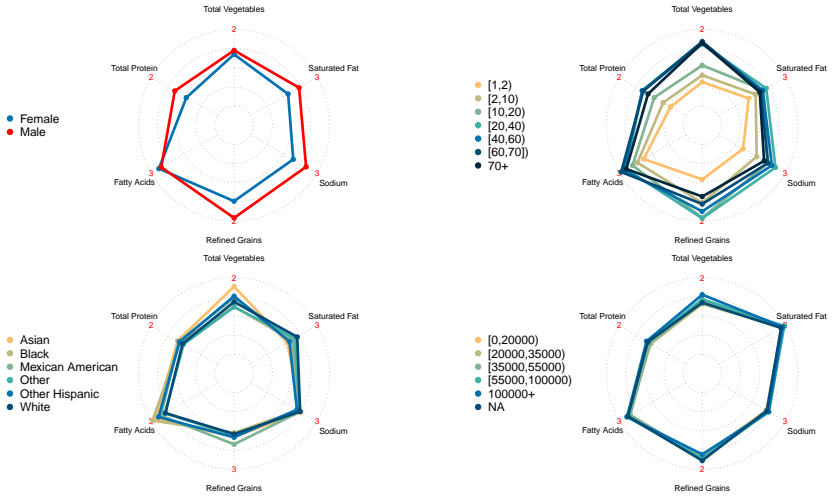
- [Figure 3] Figure 3 (NHANES results) would benefit from an additional panel showing the posterior inclusion probabilities for each covariate per coordinate so that the coordinate-wise selection claim can be visually verified.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive comments. We address the two major comments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§3.2] §3.2, the Tucker factorization with coordinate-specific partitions: the paper must demonstrate that the posterior on the partition allocations identifies the coordinate-specific influential subsets without confounding the shared-atom locations or the copula parameters; a formal identifiability argument or simulation recovery study under known sparse structure is needed.
Authors: The current manuscript presents simulation experiments in Section 5 that demonstrate recovery of coordinate-specific covariate influence under the proposed model. To more directly address potential confounding between partition allocations, shared atoms, and copula parameters, we will add a targeted recovery study with known sparse structures in the revision. We will also include a concise discussion of identifiability properties induced by the Tucker factorization combined with the coordinate-specific random partition priors. revision: yes
-
Referee: [§4.3] §4.3, MCMC complexity claim: the statement that the sampler scales with the number of aggregated levels rather than original levels is load-bearing for the efficiency contribution; the reported wall-clock times and effective sample sizes in the simulation study (Table 2) should be accompanied by a direct comparison against a non-aggregated baseline on the same data sets.
Authors: We agree that a head-to-head comparison would strengthen the efficiency claims. In the revised manuscript we will augment Table 2 (and the accompanying text) with wall-clock times and effective sample sizes obtained from a non-aggregated baseline implementation run on the identical simulated data sets. revision: yes
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper constructs a novel model by combining a Gaussian copula for multivariate dependence with coordinate-wise marginal mixtures sharing atoms and a Tucker tensor factorization using random partitions on covariate levels to enable selection and aggregation. This structure is defined directly from the modeling assumptions without reducing any claimed prediction or uniqueness result to a fitted parameter or prior self-citation by construction. The MCMC scaling follows from the aggregated partition representation rather than redefining inputs as outputs. Simulations and NHANES application provide external validation, confirming the derivation remains self-contained against the stated goals.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of shared mixture atoms
- concentration parameters of random partition models
axioms (2)
- domain assumption Gaussian copula sufficiently captures dependence among outcome coordinates
- domain assumption Coordinate-specific random partitions aggregate covariate levels with similar effects without distorting the posterior
invented entities (2)
-
Tucker tensor factorization structure for covariate-dependent mixture weights
no independent evidence
-
coordinate-specific random partition models on covariate levels
no independent evidence
Reference graph
Works this paper leans on
-
[1]
, " * write output.state after.block = add.period write newline
ENTRY address author booktitle chapter edition editor howpublished institution journal key month note number organization pages publisher school series title type volume year label extra.label sort.label INTEGERS output.state before.all mid.sentence after.sentence after.block FUNCTION init.state.consts #0 'before.all := #1 'mid.sentence := #2 'after.sente...
-
[2]
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in "In " FUNCTION format.date ye...
-
[3]
\@ifclassloaded aguplus natbib The aguplus class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command natbib from the document \@ifclassloaded nlinproc natbib The nlinproc class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later r...
-
[4]
@stdbsttrue NAT@ctr \@lbibitem[ NAT@ctr ] \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 [ @natanchorstart #2\@extra@b@citeb \@biblabel @num @natanchorend] @ifcmd#1(@)(@)\@nil #2 @lbibitem\@undefined @lbibitem\@lbibitem \@lbibitem[#1]#2 @lb...
-
[5]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifundefined NAT@sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifundefined bib@heading @heading NAT@ctr thebibliography [1] @ \@biblabel NAT@ctr \@bibsetup #1 NAT@ctr 0 @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.=1000 \@...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.