Self-Improving Tabular Language Models via Iterative Reward-Guided Post-Training
Pith reviewed 2026-05-21 00:13 UTC · model grok-4.3
The pith
TabGRAA improves a tabular language model backbone beyond supervised fine-tuning using iterative group-relative alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
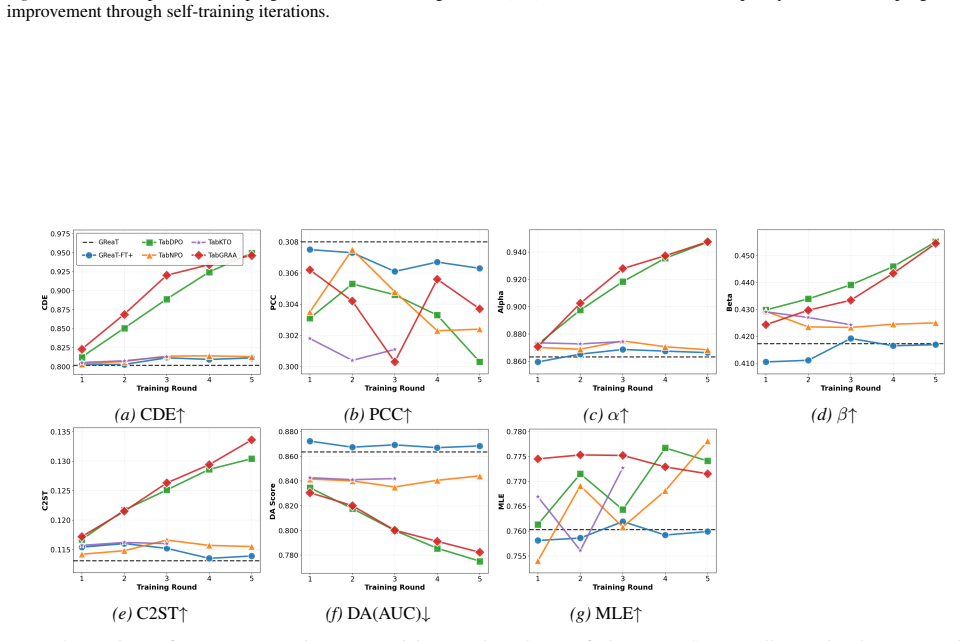
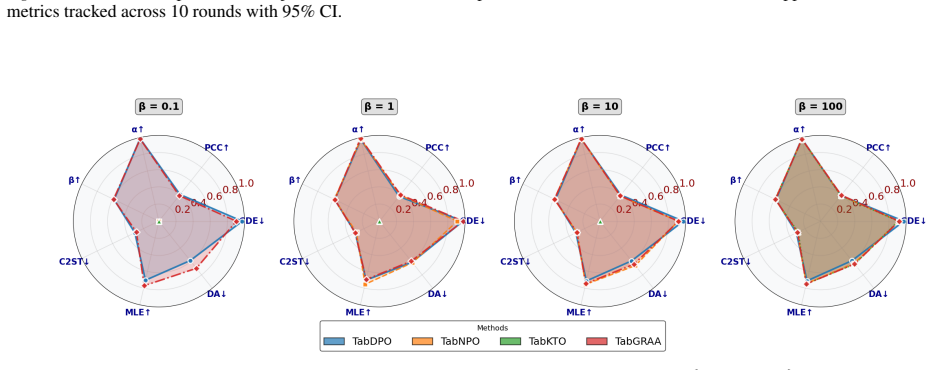
TabGRAA performs alignment by comparing high- and low-reward generated groups using group-averaged policy and reference log-ratios rather than pairwise preferences, and when used in a generate-score-align loop it improves the GReaT backbone on fidelity and utility metrics across five benchmarks while matching the supervised baseline on privacy diagnostics.
What carries the argument
TabGRAA (Tabular Group-Relative Advantage Alignment), which updates the model by contrasting group-level log-ratio averages from high-reward versus low-reward synthetic row samples.
If this is right
- The post-training loop works with both classifier-based and classifier-free rewards.
- Meaningful reward rankings and stable group updates are necessary for the gains, not extra training alone.
- Proper separation of the scorer from the generator helps maintain the fidelity-utility-privacy balance.
- TabGRAA serves as a complementary self-improving method alongside strong static tabular synthesizers.
Where Pith is reading between the lines
- This suggests potential for applying similar iterative alignment to other generative tasks involving structured outputs.
- Reward functions based on data properties could enable ongoing self-improvement in synthetic data systems.
- Testing the method on larger scale models or different tabular domains like medical records would be a natural next step.
Load-bearing premise
The gains rely on the reward providing rankings that actually reflect the desired properties of the synthetic data and on the group updates being stable without collapse or overfitting.
What would settle it
If applying TabGRAA with a non-informative reward that ranks generated rows randomly produces no gains over the supervised fine-tuning baseline on the five benchmarks, that would falsify the central claim.
Figures



















read the original abstract
Tabular language models can generate synthetic tables by modeling rows as token sequences, but they are typically trained once with supervised fine-tuning and then used as static synthesizers. This is limiting because next-token likelihood does not directly optimize the distributional, utility, and indistinguishability properties used to evaluate synthetic data. We study iterative reward-guided post-training for tabular language models through a generate--score--align protocol, where a generator samples synthetic rows, a task-specified reward ranks them, and the model is updated relative to a fixed supervised reference. Within this protocol, we propose \textbf{TabGRAA} (\textbf{Tab}ular \textbf{G}roup-\textbf{R}elative \textbf{A}dvantage \textbf{A}lignment), a group-relative alignment method that compares high- and low-reward generated groups using group-averaged policy/reference log-ratios rather than one-to-one preference pairs. Across five mixed-type benchmarks, TabGRAA improves a GReaT backbone beyond additional supervised fine-tuning and achieves the strongest average trade-off among adapted DPO, KTO, and NPO baselines on fidelity and downstream utility, while maintaining empirical privacy diagnostics near the supervised baseline. Ablations show that the gains depend on meaningful reward ranking and stable group-level updates rather than extra training alone. Reward-substitution and scorer-separation studies further show that the post-training loop can use both classifier-based and classifier-free rewards, and that proper scorer separation is important for preserving the fidelity--utility--privacy trade-off. These results position TabGRAA as a self-improving post-training method for tabular language-model generators, complementary to strong static tabular synthesizers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TabGRAA, a group-relative advantage alignment method for iterative reward-guided post-training of tabular language models. Using a generate-score-align protocol, a GReaT backbone generates synthetic rows that are ranked by a task-specified reward; the model is then updated via group-averaged policy/reference log-ratios rather than pairwise preferences. Across five mixed-type benchmarks, TabGRAA is reported to outperform additional supervised fine-tuning as well as adapted DPO, KTO, and NPO baselines on fidelity and downstream utility while keeping empirical privacy diagnostics comparable to the supervised baseline. Ablations attribute the gains to meaningful reward ranking and stable group-level updates rather than extra training alone, and further studies examine classifier-based versus classifier-free rewards and the importance of scorer separation.
Significance. If the empirical gains prove robust and reproducible, the work offers a practical self-improving post-training loop that directly optimizes the distributional, utility, and privacy properties used to evaluate synthetic tabular data. This is a useful complement to static tabular synthesizers and demonstrates that alignment-style techniques can be adapted to tabular generators without collapsing fidelity or privacy.
major comments (2)
- The central empirical claim rests on benchmark improvements and ablations, yet the manuscript provides neither the precise mathematical definition of the group-averaged advantage (including group construction and log-ratio averaging) nor the full training hyperparameters and iteration schedule. Without these, it is impossible to verify that the reported gains arise from the proposed group-relative mechanism rather than from unstated implementation choices or reward design.
- No statistical significance tests, confidence intervals, or variance estimates across random seeds are reported for the fidelity, utility, or privacy metrics. Given the known sensitivity of tabular synthesis benchmarks to data splits and initialization, the absence of these diagnostics weakens the claim that TabGRAA achieves the strongest average trade-off.
minor comments (3)
- The abstract and results sections should explicitly state the number of iterations, the size of each generated group, and the exact reward models used in the main experiments.
- Notation for the reference policy and the scorer-separation protocol is introduced without a dedicated equation or pseudocode block; adding one would improve clarity for readers implementing the method.
- The privacy diagnostics are described as 'near the supervised baseline' but lack a quantitative table or figure showing the exact values; a compact comparison table would strengthen the privacy claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and will revise the paper to incorporate clarifications and additional analyses where appropriate.
read point-by-point responses
-
Referee: The central empirical claim rests on benchmark improvements and ablations, yet the manuscript provides neither the precise mathematical definition of the group-averaged advantage (including group construction and log-ratio averaging) nor the full training hyperparameters and iteration schedule. Without these, it is impossible to verify that the reported gains arise from the proposed group-relative mechanism rather than from unstated implementation choices or reward design.
Authors: We agree that the current presentation would benefit from greater mathematical precision. We will add an explicit formal definition of the group-averaged advantage in Section 3.2, including the precise construction of high- and low-reward groups (via reward thresholding on generated samples) and the group-level averaging of policy-to-reference log-ratios. We will also move a consolidated table of all training hyperparameters and the complete iteration schedule (including number of generate-score-align cycles and convergence criteria) into the main text, with full pseudocode. These additions will make the group-relative mechanism fully verifiable from the manuscript alone. revision: yes
-
Referee: No statistical significance tests, confidence intervals, or variance estimates across random seeds are reported for the fidelity, utility, or privacy metrics. Given the known sensitivity of tabular synthesis benchmarks to data splits and initialization, the absence of these diagnostics weakens the claim that TabGRAA achieves the strongest average trade-off.
Authors: We acknowledge that the lack of multi-seed statistics is a limitation given the sensitivity of tabular benchmarks. In the revised manuscript we will rerun the primary experiments across five random seeds, report mean and standard deviation for all fidelity, utility, and privacy metrics, and include pairwise statistical comparisons (e.g., paired t-tests or Wilcoxon tests with p-values) against the strongest baselines. These results will be added to the main results tables and discussed in the experimental section. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents TabGRAA as an empirical generate-score-align post-training method for tabular LMs, with claims of improved fidelity-utility trade-offs supported by direct comparisons to external adapted baselines (DPO, KTO, NPO) and ablations on reward ranking and group updates across five independent benchmarks. Evaluation metrics (fidelity, downstream utility, privacy diagnostics) are defined separately from the training loop and do not reduce to quantities fitted or defined within the same procedure; no load-bearing mathematical derivation, self-definitional construction, or self-citation chain is invoked to justify the central results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A task-specified reward function exists that ranks generated rows in a way that correlates with fidelity, utility, and privacy goals.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
we leverage a key insight: distinguishability attack classifiers naturally capture the multi-dimensional quality of tabular samples... scls(˜x) = 1−2|0.5−ϕ t(˜x)|
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GRAA loss... LGRAA(θ) = σ(¯rlow_θ − ¯rhigh_θ) with group-averaged implicit rewards
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mixed-type tabular data synthesis with score-based diffusion in latent space
Curran Associates, Inc., 2019. Zhang, H., Zhang, J., Srinivasan, B., Shen, Z., Qin, X., Faloutsos, C., Rangwala, H., and Karypis, G. Mixed-type tabular data synthesis with score-based diffusion in latent space.arXiv preprint arXiv:2310.09656, 2023. Zhang, R., Lin, L., Bai, Y ., and Mei, S. Negative preference optimization: From catastrophic collapse to ef...
-
[2]
doi: https://doi.org/10.1016/j.ress.2026.112674. URL https://www.sciencedirect.com/ science/article/pii/S0951832026004862. Zhao, Z., Kunar, A., Birke, R., Van der Scheer, H., and Chen, L. Y . Ctab-gan+: Enhancing tabular data synthesis. Frontiers in Big Data, 6:1296508, 2024. 12 Title Suppressed Due to Excessive Size A. Background A.1. Problem Setup Tabul...
-
[3]
<col1> is <val1>; <col2> is <val2>
Trend (Pair-wise Column Correlation)We evaluate pair-wise column association via Pairwise Column Correlation (PCC) error, which quantifies how well linear and categorical dependencies are retained. • Numerical Features (Pearson Correlation Dissimilarity): We compute the Pearson Correlation Coefficient (ρ) for all pairs of numerical columns in both real an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.