Auto-Conditioned Frank-Wolfe Algorithms
Pith reviewed 2026-05-19 15:29 UTC · model grok-4.3
The pith
Frank-Wolfe methods converge with local Lipschitz estimates alone
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A general auto-conditioned framework for projection-free methods substitutes a local Lipschitz estimator, derived from first-order information along the iterates, for the global smoothness constant in step-size rules. This substitution preserves convergence analysis for the included class of methods, establishing convergence to stationary points in the nonconvex setting and recovering standard sublinear guarantees in the convex setting without requiring prior knowledge of a global smoothness constant.
What carries the argument
The local Lipschitz estimator computed from first-order information along the iterates, serving as a direct replacement for the global smoothness constant in closed-loop step-size selection.
If this is right
- The methods achieve convergence to stationary points for nonconvex objectives without any global smoothness knowledge.
- Standard sublinear convergence rates hold for convex objectives under the same local-estimator rule.
- The framework covers standard Frank-Wolfe, Matching Pursuit, pairwise Frank-Wolfe, and away-step Frank-Wolfe as special cases.
- Additional structural assumptions on particular variants yield accelerated rates within the same framework.
Where Pith is reading between the lines
- The local-adaptation approach could reduce the need for manual tuning of step-size parameters in large-scale constrained problems.
- Performance gains observed in experiments suggest the estimator may handle varying curvature better than fixed global constants.
- Similar local-estimator ideas might extend to other projection-free algorithms beyond the variants analyzed here.
Load-bearing premise
The local Lipschitz estimator computed from first-order information along the iterates must be accurate enough to serve as a drop-in replacement for the global smoothness constant while preserving the convergence analysis.
What would settle it
A smooth nonconvex test problem where the auto-conditioned iterates diverge or fail to approach a stationary point despite the existence of a finite global Lipschitz constant would falsify the claim.
Figures
read the original abstract
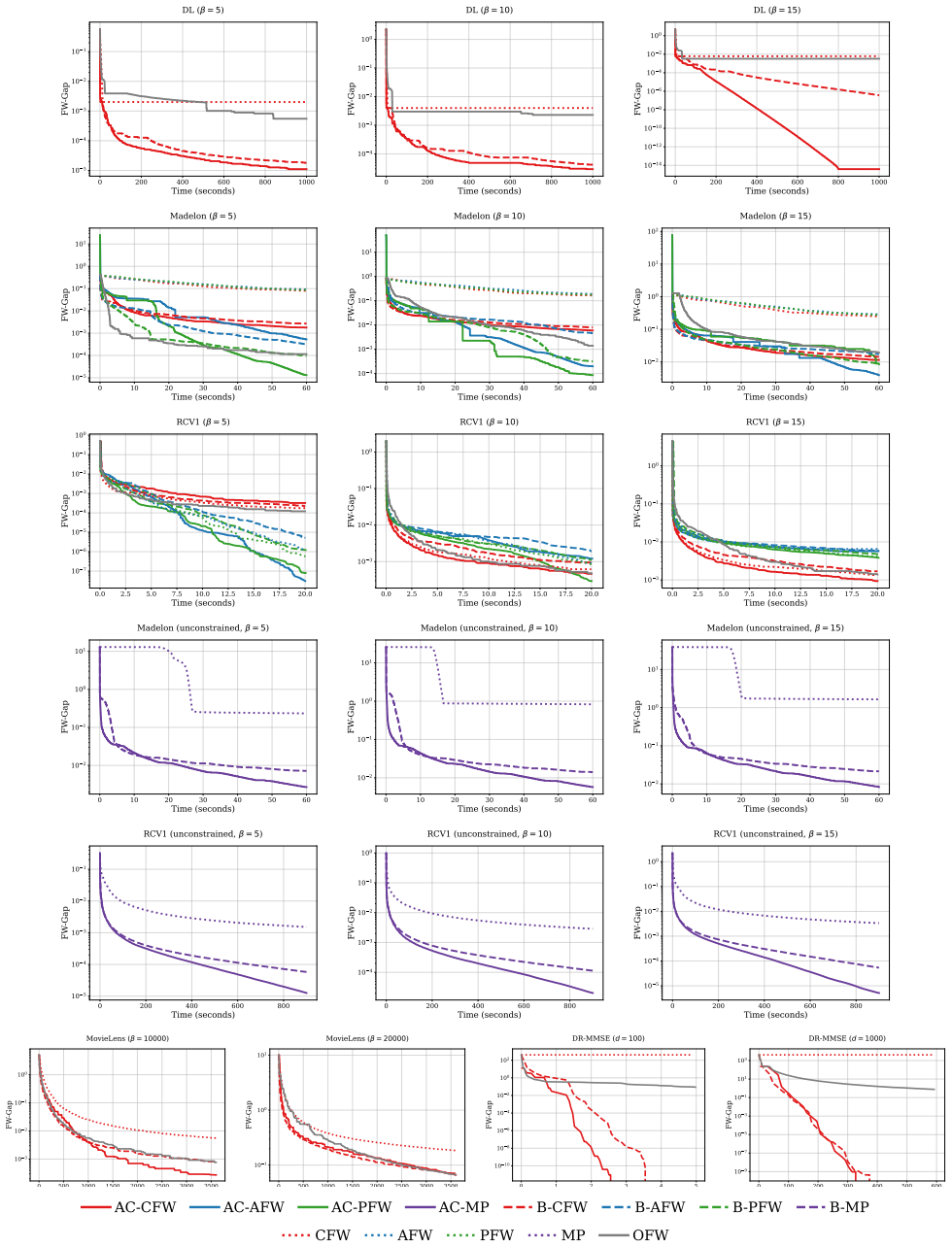
Frank-Wolfe methods are projection-free algorithms for constrained optimization whose practical performance often depends critically on the choice of step size. Classical closed-loop step-size rules typically require prior knowledge of a global smoothness constant, while line-search variants avoid this requirement at the cost of additional function evaluations and implementation overhead. In this paper, we develop a fully auto-conditioned framework for Frank-Wolfe-type methods. The framework replaces the global Lipschitz constant in closed-loop step sizes with a local Lipschitz estimator computed from first-order information along the iterates. We show that this abstraction captures several important projection-free subroutines, including standard Frank-Wolfe, Matching Pursuit, pairwise Frank-Wolfe, and away-step Frank-Wolfe. For the resulting general class of methods, we establish convergence to stationary points in the nonconvex setting and recover the standard sublinear convergence guarantees in the convex setting, without requiring prior knowledge of a global smoothness constant. We further show that, when specialized to particular Frank-Wolfe variants and combined with additional structural assumptions, the same auto-conditioned framework yields accelerated convergence rates. Numerical experiments demonstrate that the proposed methods provide substantial practical improvements over line-search-based alternatives, highlighting the benefits of adapting to local curvature while retaining the simplicity of closed-loop step-size rules.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a fully auto-conditioned framework for Frank-Wolfe-type methods that replaces the global Lipschitz constant in closed-loop step sizes with a local Lipschitz estimator computed from first-order information along the iterates. This framework is shown to encompass standard Frank-Wolfe, Matching Pursuit, pairwise Frank-Wolfe, and away-step Frank-Wolfe. Convergence to stationary points is established in the nonconvex setting, standard sublinear rates are recovered in the convex setting, and accelerated rates are derived under additional structural assumptions, all without requiring prior knowledge of a global smoothness constant. Numerical experiments are presented to demonstrate practical improvements over line-search alternatives.
Significance. If the central claims hold, the work would be a solid contribution to projection-free optimization by addressing the practical difficulty of knowing or estimating a global smoothness constant. The generality across multiple Frank-Wolfe variants and the recovery of standard rates are strengths. The numerical results provide evidence of practical benefit. However, the significance is limited by the need to confirm that the local estimator reliably supports the descent and gap arguments in nonconvex settings without additional assumptions.
major comments (2)
- [§4.1, Eq. (7) and Theorem 4.2] §4.1, Eq. (7) and Theorem 4.2: The convergence proof for nonconvex problems applies the standard descent lemma and gap decrease 1 - (gap)^2/(2 L D^2) using the local estimator L_k in place of L. The construction of L_k from first-order information at previous iterates (defined via a max over local differences) does not include an explicit argument that L_k ≥ L holds uniformly over the convex hull of all iterates visited so far. In the nonconvex case this upper-bound property is load-bearing; without it the claimed stationary-point convergence may fail if the estimator underestimates at any step.
- [§5, Assumption 5.1 and Theorem 5.3] §5, Assumption 5.1 and Theorem 5.3: The accelerated-rate claims under additional structural assumptions (e.g., restricted strong convexity or smoothness) rely on the same auto-conditioned step-size rule. It is unclear how the variability introduced by the local estimator interacts with these assumptions to preserve the improved rate; a separate error term or bound on the estimator deviation should be derived.
minor comments (2)
- [Abstract] The abstract states 'substantial practical improvements' but does not quantify the gains (e.g., iteration counts or objective values) or specify the test problems; adding a brief numerical summary would strengthen the claim.
- [§3] Notation for the local estimator (e.g., L_k versus hat L_k) is used inconsistently between the general framework and the specialized variants; a single consistent symbol would improve readability.
Simulated Author's Rebuttal
We thank the referee for their detailed and insightful comments on our manuscript. The feedback has helped us identify areas where the proofs can be strengthened with additional arguments. Below we address each major comment point by point, indicating the revisions we plan to make.
read point-by-point responses
-
Referee: [§4.1, Eq. (7) and Theorem 4.2] The convergence proof for nonconvex problems applies the standard descent lemma and gap decrease 1 - (gap)^2/(2 L D^2) using the local estimator L_k in place of L. The construction of L_k from first-order information at previous iterates (defined via a max over local differences) does not include an explicit argument that L_k ≥ L holds uniformly over the convex hull of all iterates visited so far. In the nonconvex case this upper-bound property is load-bearing; without it the claimed stationary-point convergence may fail if the estimator underestimates at any step.
Authors: We thank the referee for this important observation. We acknowledge that the manuscript would benefit from an explicit proof that the local estimator L_k satisfies the required upper-bound property L_k ≥ L over the convex hull. We will revise Section 4.1 by adding a new lemma that provides this argument, leveraging the definition of L_k via the maximum over local gradient differences and the fact that the iterates remain within a compact set. With this addition, the application of the descent lemma in the proof of Theorem 4.2 will be fully justified. We plan to make this change in the revised manuscript. revision: yes
-
Referee: [§5, Assumption 5.1 and Theorem 5.3] The accelerated-rate claims under additional structural assumptions (e.g., restricted strong convexity or smoothness) rely on the same auto-conditioned step-size rule. It is unclear how the variability introduced by the local estimator interacts with these assumptions to preserve the improved rate; a separate error term or bound on the estimator deviation should be derived.
Authors: We thank the referee for this suggestion. The interaction between the varying L_k and the structural assumptions is indeed not fully detailed in the current version. In the revision, we will derive a bound on the deviation |L_k - L| under Assumption 5.1, showing that L_k converges to the true parameter at a sufficient rate. This will allow us to introduce an additive error term in the convergence analysis of Theorem 5.3, which does not affect the accelerated rate but only the constant factors. We will revise the statement of Theorem 5.3 to include this refined analysis. revision: yes
Circularity Check
No significant circularity; derivation uses standard analysis with local estimator
full rationale
The paper introduces a local Lipschitz estimator computed from first-order information along iterates to replace the global smoothness constant in closed-loop step sizes for Frank-Wolfe variants. Convergence to stationary points (nonconvex) and sublinear rates (convex) follow from adapting the standard descent lemma and gap analysis to this estimator, without any reduction of the claimed rates to fitted parameters by construction or load-bearing self-citations. The framework is presented as capturing existing subroutines via the same abstraction, with the analysis remaining independent of the target result and externally falsifiable via the estimator's explicit first-order construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The objective function admits a local Lipschitz constant estimable from first-order information along the sequence of iterates.
- standard math Standard assumptions for Frank-Wolfe convergence (compact convex set, continuous differentiability) continue to hold.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.