Measuring Maximum Activations in Open Large Language Models
Pith reviewed 2026-05-20 19:31 UTC · model grok-4.3
The pith
Maximum activation magnitude in open LLMs is a property of family and architecture rather than size alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
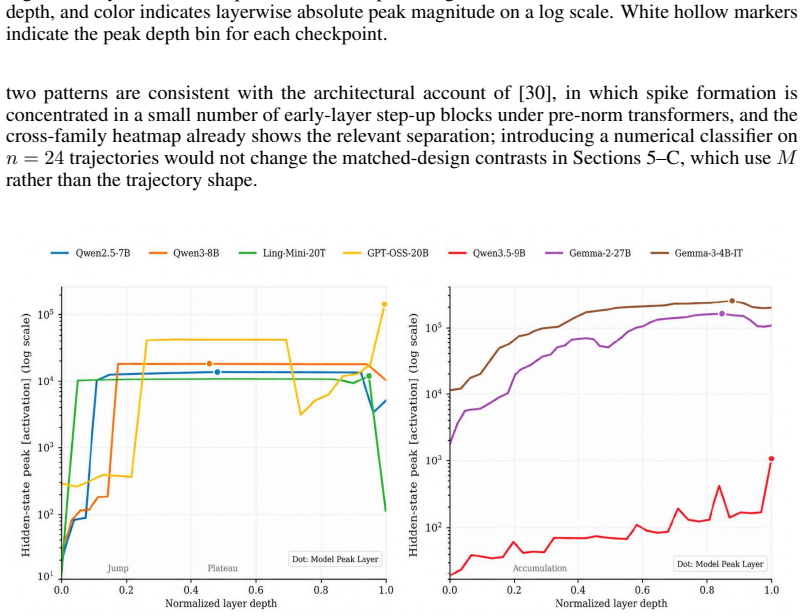
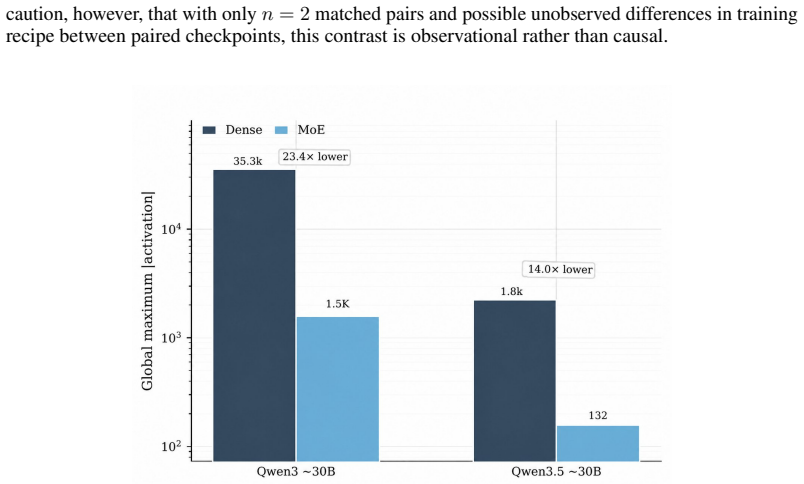
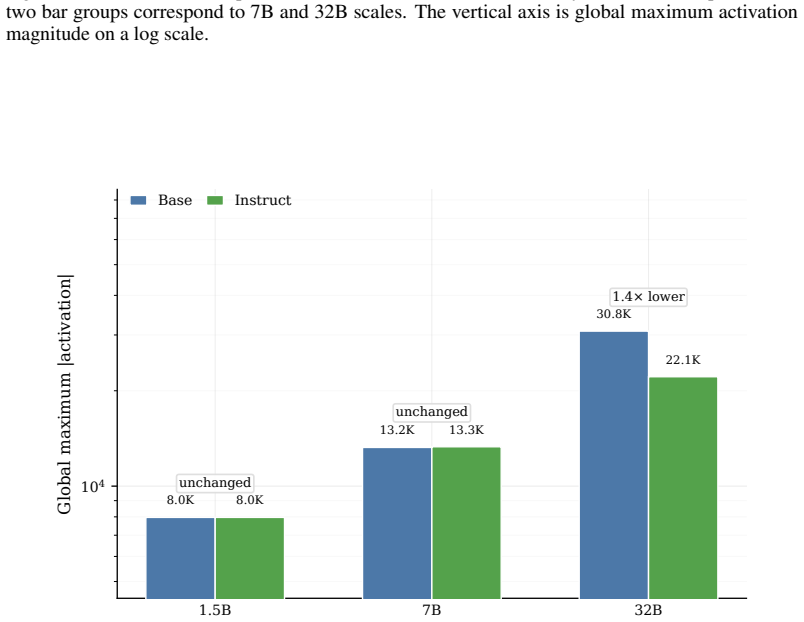
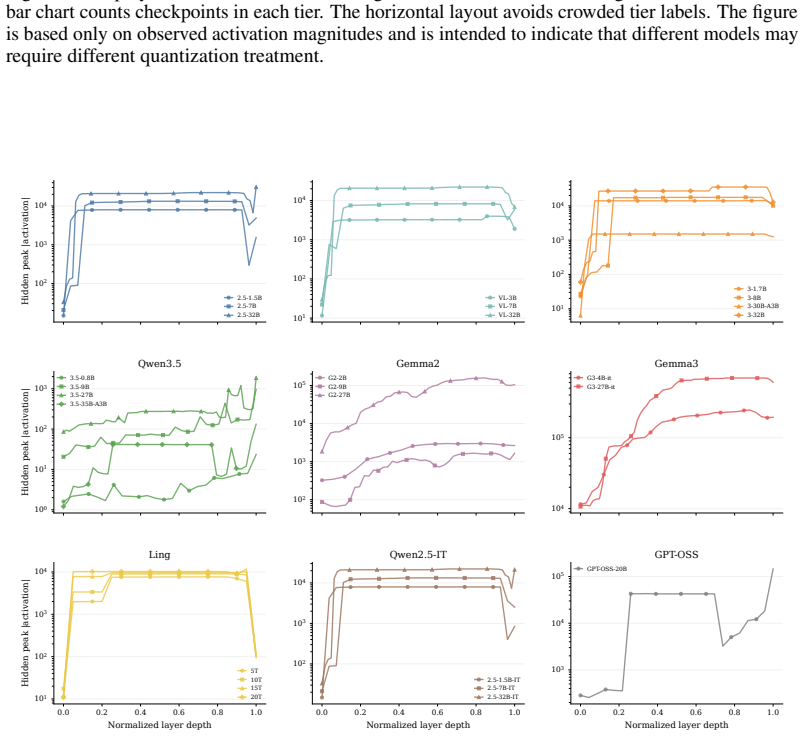
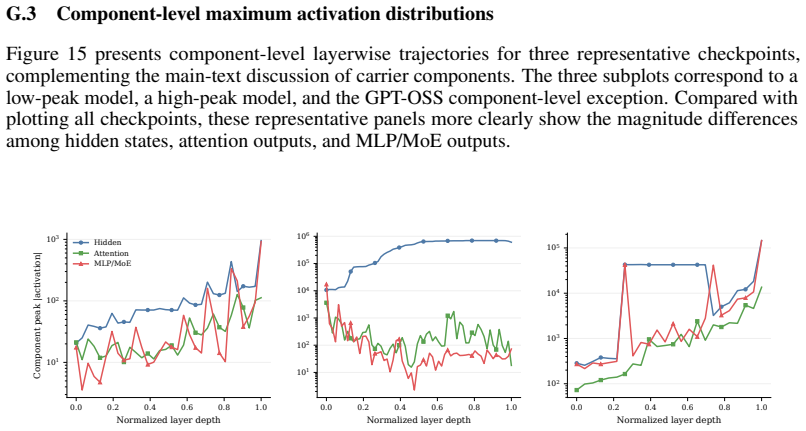
Global and layerwise maximum activations were recorded across 27 checkpoints from eight open families using a unified pipeline of 5,000 multi-domain samples and fixed hooks at embeddings, hidden states, attention, MLP or MoE, SwiGLU gates, and final norm. Maxima span almost four orders of magnitude at similar sizes, with Qwen3.5 and MoE models in the 10^2 to 10^3 range while Gemma3-27B-it reaches approximately 7 times 10^5. MoE checkpoints show 14.0 to 23.4 times lower peaks than matched dense models, and the residual stream carries the global maximum in 22 of 24 cases. These patterns establish that maximum activation magnitude is a model property tied to family, architecture, and training,
What carries the argument
The unified measurement pipeline that applies identical tokenization and layer hooks to record global and per-layer maximum activation values across model families and training stages.
If this is right
- Activation scaling and quantization choices must be tuned to the specific family rather than assumed from model size.
- Mixture-of-experts designs can support more aggressive low-bit formats because their activation peaks remain substantially smaller.
- The residual stream must be handled with care in any activation-management scheme since it holds the largest value in nearly all cases.
- Open-weight releases should include measured maximum activations to support informed low-bit deployment.
Where Pith is reading between the lines
- If peak magnitudes shift with training stage, repeated measurements during continued pretraining could reveal when and how activation growth occurs.
- Architectural differences such as gating or expert routing appear to control dynamic range and could be adjusted to reduce the need for large activation scales.
- Direct measurement of maxima provides a lightweight way to select per-model quantization scales that match observed reconstruction error.
Load-bearing premise
The 5,000-sample multi-domain corpus together with the chosen layer hooks is sufficient to capture the true global maximum activations for each model checkpoint.
What would settle it
Running any of the tested models on a substantially larger or more diverse input set and obtaining activation values several times higher than the reported maxima.
Figures









read the original abstract
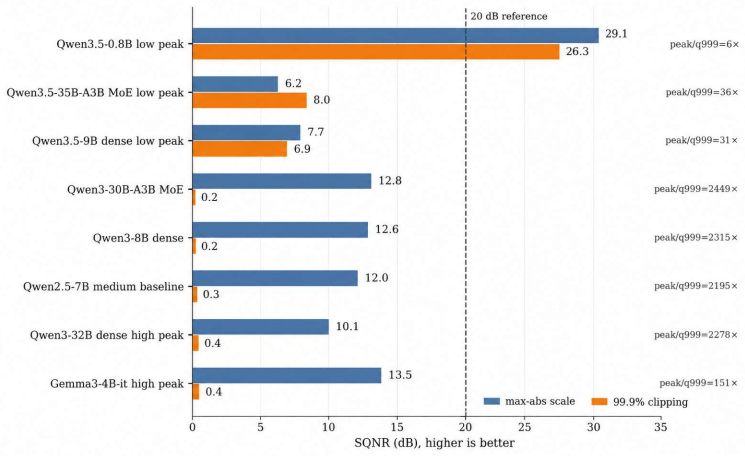
The dynamic range of activations is a first-order constraint for low-bit quantization, activation scaling, and stable LLM inference. Prior work characterized outlier features and massive activations on pre-2024 LLaMA-style models, and the downstream activation-quantization stack inherits that picture without revisiting it for the post-LLaMA open-model boom. We ask the deployment-oriented question: how large can activations get in modern open LLMs, and how does this magnitude vary across families, generations, and training stages? Under a unified pipeline (5,000-sample multi-domain corpus, family-specific tokenization, identical hooks across embeddings, hidden states, attention, MLP/MoE, SwiGLU gates, and final norm), we measure global and layerwise maxima on 27 checkpoints from 8 open families spanning dense, MoE, vision-language, intermediate-training, and instruction-tuned variants. We find that (i) global maxima span over nearly four orders of magnitude at comparable parameter counts, with Qwen3.5 and MoE checkpoints in the 10^2 to 10^3 range and Gemma3-27B-it reaching ~7 x 10^5; (ii) cross-family and cross-generation comparisons break simple monotonic scaling; and (iii) MoE checkpoints exhibit 14.0-23.4x lower peaks than matched-scale dense counterparts, while the residual stream carries the global maximum in 22/24 checkpoints. A lightweight INT-8 sanity check shows that measured maxima co-vary with low-bit reconstruction error via activation-scale selection. We conclude that maximum activation magnitude is a model property tied to family, architecture, and training stage - not a simple byproduct of size - and should be measured and reported alongside any open-weight release before low-bit deployment. The code is publicly available at https://github.com/clx1415926/Max_act_llm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a unified measurement pipeline using a fixed 5,000-sample multi-domain corpus, family-specific tokenization, and identical layer hooks to compute global and layerwise maximum activation magnitudes across 27 checkpoints from 8 open LLM families (dense, MoE, vision-language, intermediate and instruction-tuned). It reports that these maxima span nearly four orders of magnitude at comparable scales (Qwen3.5/MoE in 10^2–10^3 vs. Gemma3-27B-it at ~7×10^5), that cross-family and cross-generation trends break simple size-based scaling, that MoE models show 14–23× lower peaks than matched dense counterparts, and that the residual stream carries the global maximum in most cases. A lightweight INT-8 check links the measured maxima to quantization reconstruction error. The central conclusion is that maximum activation magnitude is an intrinsic model property tied to family, architecture, and training stage rather than parameter count alone; code is released publicly.
Significance. If the measured values are representative of true global maxima, the work is significant for low-bit quantization, activation scaling, and stable inference: it shows that activation dynamic range is not uniform across the post-LLaMA open-model landscape and must be measured per release. The public code and the INT-8 sanity check are concrete strengths that allow direct reproduction and practical validation. The four-order-of-magnitude spread and the MoE-vs-dense gap, if robust, would be useful empirical facts for the deployment community.
major comments (1)
- [unified pipeline description] The central claim that maximum activation magnitude is a model property independent of size rests on the 5,000-sample corpus actually capturing (or closely approximating) the global maximum for each checkpoint. The manuscript describes the corpus and hooks but provides no ablation on sample size, no saturation analysis, and no comparison against high-entropy or targeted inputs known from prior outlier-feature literature to elicit larger peaks. This omission directly affects the validity of the reported four-order spread and the 14–23× MoE gap.
minor comments (2)
- [methods] The abstract and methods would benefit from an explicit statement of how many tokens or sequences were actually processed per model after tokenization, to allow readers to judge coverage.
- [results] Table or figure showing per-family maxima should include error bars or min/max across multiple random seeds of the corpus if any subsampling was performed.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting an important methodological consideration. We address the major comment point by point below and outline concrete revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [unified pipeline description] The central claim that maximum activation magnitude is a model property independent of size rests on the 5,000-sample corpus actually capturing (or closely approximating) the global maximum for each checkpoint. The manuscript describes the corpus and hooks but provides no ablation on sample size, no saturation analysis, and no comparison against high-entropy or targeted inputs known from prior outlier-feature literature to elicit larger peaks. This omission directly affects the validity of the reported four-order spread and the 14–23× MoE gap.
Authors: We agree that explicit validation of corpus saturation would strengthen the central claim. Our 5,000-sample multi-domain corpus was assembled to maximize input diversity across domains, and the observed consistency of trends across 27 checkpoints from eight families provides supporting evidence that the reported relative differences are robust. Nevertheless, we did not include sample-size ablations or direct comparisons to high-entropy prompts in the submitted version. In the revision we will add (i) a saturation plot showing measured maxima as a function of corpus size (up to 20,000 samples) for one representative model per family and (ii) a targeted comparison using a small set of high-entropy inputs drawn from the outlier-feature literature. These results will be reported in a new appendix, the main claims will be qualified accordingly, and the public code will be updated to reproduce the new checks. We expect these additions to address the concern while preserving the core empirical observations. revision: yes
Circularity Check
No circularity: direct empirical measurements with no derivations or self-referential steps
full rationale
The paper performs direct empirical measurements of maximum activation magnitudes across 27 checkpoints using a fixed 5,000-sample multi-domain corpus, family-specific tokenization, and identical layer hooks. No mathematical derivations, fitted parameters, equations, or self-citations are used to derive the central claim; the reported variations (e.g., four-order-of-magnitude spread, MoE vs. dense gaps) are presented as observed outcomes from the measurement pipeline. The analysis is self-contained against external benchmarks because the results are falsifiable by re-running the same hooks on the same or expanded corpora, with no load-bearing step reducing to a definition or prior self-result by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 5,000-sample multi-domain corpus and identical hooks across layers capture representative global maxima
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We measure global and layerwise maxima on 27 checkpoints from 8 open families... under a unified pipeline (5,000-sample multi-domain corpus, family-specific tokenization, identical hooks across embeddings, hidden states, attention, MLP/MoE, SwiGLU gates, and final norm)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Systematic outliers in large language models
Yongqi An, Xu Zhao, Tao Yu, Ming Tang, and Jinqiao Wang. Systematic outliers in large language models. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[2]
Mitigating attention sinks and massive activations in audio-visual speech recognition with LLMs
Anand, Umberto Cappellazzo, Stavros Petridis, and Maja Pantic. Mitigating attention sinks and massive activations in audio-visual speech recognition with LLMs. InIEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2026
work page 2026
-
[3]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. QuaRot: Outlier-free 4-bit inference in rotated llms, 2024
work page 2024
-
[4]
Qwen2.5-VL technical report, 2025
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-VL technical report, 2025
work page 2025
-
[5]
Quantizable transformers: Removing outliers by helping attention heads do nothing
Yelysei Bondarenko, Markus Nagel, and Tijmen Blankevoort. Quantizable transformers: Removing outliers by helping attention heads do nothing. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[6]
PrefixQuant: Static quantization beats dynamic through prefixed outliers in LLMs, 2024
Mengzhao Chen, Yuxuan Liu, Jiahao Wang, Yi Bin, Wenqi Shao, and Ping Luo. PrefixQuant: Static quantization beats dynamic through prefixed outliers in LLMs, 2024
work page 2024
-
[7]
Yinjie Chen, Zipeng Yan, Chong Zhou, Bo Dai, and Andrew F. Luo. Vision transformers with self-distilled registers. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
-
[8]
Vision transformers need registers
Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[9]
Insights into DeepSeek-V3: Scaling challenges and reflections on hardware for AI architectures, 2025
DeepSeek-AI. Insights into DeepSeek-V3: Scaling challenges and reflections on hardware for AI architectures, 2025
work page 2025
-
[10]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
work page 2025
-
[11]
LLM.int8(): 8-bit matrix multiplication for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit matrix multiplication for transformers at scale. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[12]
GPTQ: Accurate post-training quantization for generative pre-trained transformers
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. GPTQ: Accurate post-training quantization for generative pre-trained transformers. InICLR, 2023
work page 2023
-
[13]
Gemma 2: Improving open language models at a practical size, 2024
Gemma Team. Gemma 2: Improving open language models at a practical size, 2024
work page 2024
- [14]
-
[15]
When attention sink emerges in language models: An empirical view
Xiangming Gu, Tianyu Pang, Chao Du, Qian Liu, Fengzhuo Zhang, Cunxiao Du, Ye Wang, and Min Lin. When attention sink emerges in language models: An empirical view. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[16]
From attention to activation: Unravelling the enigmas of large language models
Prannay Kaul, Chengcheng Ma, Ismail Elezi, and Jiankang Deng. From attention to activation: Unravelling the enigmas of large language models. InInternational Conference on Learning Representations (ICLR), 2025
work page 2025
-
[17]
DuQuant: Distributing outliers via dual transformation makes stronger quantized LLMs
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. DuQuant: Distributing outliers via dual transformation makes stronger quantized LLMs. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[18]
AWQ: Activation-aware weight quantization for on-device llm compression and acceleration
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. AWQ: Activation-aware weight quantization for on-device llm compression and acceleration. InMLSys, 2024
work page 2024
-
[19]
Every FLOP counts: Scaling a 300b mixture-of-experts LING llm without premium gpus, 2025
Ling Team. Every FLOP counts: Scaling a 300b mixture-of-experts LING llm without premium gpus, 2025
work page 2025
-
[20]
Towards greater leverage: Scaling laws for efficient mixture-of-experts language models, 2025
Ling Team. Towards greater leverage: Scaling laws for efficient mixture-of-experts language models, 2025
work page 2025
-
[21]
SpinQuant: Llm quantization with learned rotations, 2024
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. SpinQuant: Llm quantization with learned rotations, 2024
work page 2024
-
[22]
KIVI: A tuning-free asymmetric 2bit quantization for KV cache
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Vladimir Braverman, Beidi Chen, and Xia Hu. KIVI: A tuning-free asymmetric 2bit quantization for KV cache. In International Conference on Machine Learning (ICML), 2024
work page 2024
-
[23]
Not a nuisance but a useful heuristic: Outlier dimensions favor frequent tokens in language models
Iuri Macocco, Nora Graichen, Gemma Boleda, and Marco Baroni. Not a nuisance but a useful heuristic: Outlier dimensions favor frequent tokens in language models. InProceedings of the 8th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, 2025
work page 2025
-
[24]
gpt-oss-120b & gpt-oss-20b model card, 2025
OpenAI. gpt-oss-120b & gpt-oss-20b model card, 2025
work page 2025
-
[25]
Attention sinks and compression valleys in LLMs are two sides of the same coin, 2026
Enrique Queipo-de Llano, Álvaro Arroyo, Federico Barbero, Xiaowen Dong, Michael Bronstein, Yann LeCun, and Ravid Shwartz-Ziv. Attention sinks and compression valleys in LLMs are two sides of the same coin, 2026
work page 2026
- [26]
- [27]
-
[28]
Slimpajama-dc: Understanding data combinations for llm training, 2024
Zhiqiang Shen, Tianhua Tao, Liqun Ma, Willie Neiswanger, Zhengzhong Liu, Hongyi Wang, Bowen Tan, Joel Hestness, Natalia Vassilieva, Daria Soboleva, and Eric Xing. Slimpajama-dc: Understanding data combinations for llm training, 2024
work page 2024
-
[29]
Mingjie Sun, Xinlei Chen, J. Zico Kolter, and Zhuang Liu. Massive activations in large language models. InConference on Language Modeling (COLM), 2024. 11
work page 2024
-
[30]
The spike, the sparse and the sink: Anatomy of massive activations and attention sinks, 2026
Shangwen Sun, Alfredo Canziani, Yann LeCun, and Jiachen Zhu. The spike, the sparse and the sink: Anatomy of massive activations and attention sinks, 2026
work page 2026
-
[31]
FlatQuant: Flatness matters for LLM quantization
Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Tiancheng Li, Chenghua Chen, Xin Hu, Chen Yu, Lu Hou, Chun Yuan Tu, Yuen-Hin Yeung, Yu Xu, Qi Tian, and Wulong Liu. FlatQuant: Flatness matters for LLM quantization. InInternational Conference on Machine Learning (ICML), 2025
work page 2025
-
[32]
Xiuying Wei, Yunchen Zhang, Yuhang Li, Xiangguo Zhang, Ruihao Gong, Jinyang Guo, and Xianglong Liu. Outlier suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling. InEMNLP, 2023
work page 2023
-
[33]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning (ICML), 2023. 12 A Supplementary Experiments Model Details Table 2: The 24 checkpoints included in the main analysis. Gemma3 uses publicly re...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.