Fine-Grained Benchmark Generation for Comprehensive Evaluation of Foundation Models
Pith reviewed 2026-05-20 22:10 UTC · model grok-4.3
The pith
A framework generates fine-grained benchmarks from reference materials that achieve lower ground-truth error rates and distinguish model capabilities more clearly than MMLU or GSM8K.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
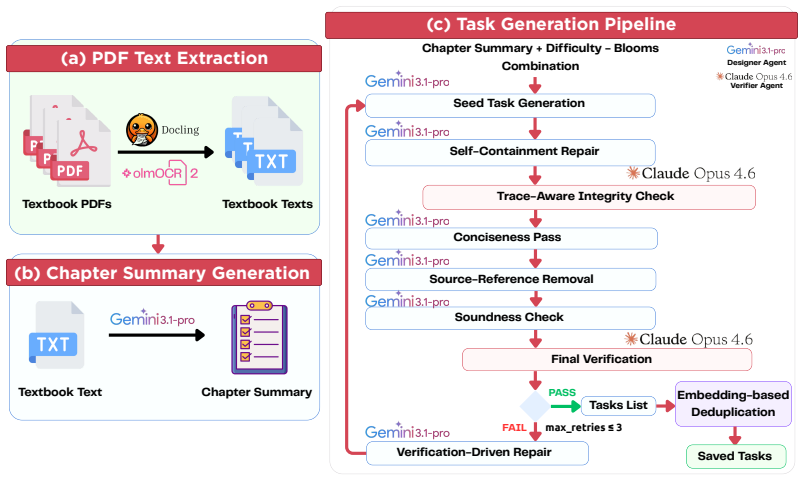
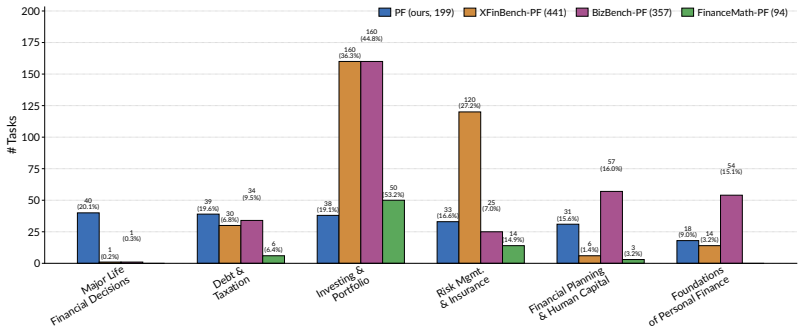
The authors develop an automated framework that creates fine-grained benchmarks grounded in reference materials. The pipeline employs a multi-agent architecture for problem generation and a solution-graph-driven strategy that improves the reliability of ground truth solutions. Using the framework, they produce three benchmarks in Machine Learning, Corporate Finance, and Personal Finance. Expert review finds a significantly lower ground-truth error rate than previous benchmarks such as MMLU and GSM8K. Evaluation of twelve commercial and open-source models shows that the benchmarks achieve near-uniform competency coverage and surface performance differences across models that existing tests do
What carries the argument
The multi-agent architecture for problem generation combined with the solution-graph-driven strategy for producing reliable ground truth solutions.
If this is right
- The benchmarks deliver near-uniform coverage across competencies with rich metadata for each question.
- Grounding problems in reference materials makes the benchmarks more robust to training-data contamination.
- Evaluations on twelve models reveal skill-specific performance differences that aggregate scores from prior benchmarks obscure.
- The framework can be applied to additional domains to create similarly detailed evaluation sets.
Where Pith is reading between the lines
- Similar automated generation could reduce reliance on manually curated benchmarks for new model capabilities.
- The approach may help pinpoint precise training gaps in foundation models by linking errors to specific competencies.
- Open-sourcing the pipeline would allow researchers to extend the method to specialized fields such as law or medicine.
Load-bearing premise
The multi-agent architecture and solution-graph strategy produce ground-truth solutions whose accuracy can be reliably confirmed by expert review without introducing systematic errors.
What would settle it
An independent expert review that finds a ground-truth error rate equal to or higher than MMLU or GSM8K on the generated benchmarks would undermine the reliability claim.
Figures








read the original abstract
Evaluation of foundation models often rely on aggregate scores from benchmarks that lack comprehensive coverage and metadata for a fine-grained evaluation. We introduce a framework for automated benchmark generation. Our framework generates evaluation problems grounded in reference material, such as textbooks, producing benchmarks with broad coverage, rich metadata, and robustness to contamination. The pipeline employs a multi-agent architecture for problem generation and a solution-graph-driven strategy that significantly improves the reliability of ground truth solutions. Using the framework, we generate three benchmarks in Machine Learning, Corporate Finance, and Personal Finance. Expert review finds a significantly lower ground-truth error rate than previous benchmarks such as MMLU and GSM8K. Evaluation of 12 commercial and open-source models shows that our benchmarks achieve near-uniform competency coverage and surface performance differences across models that existing benchmarks fail to capture. We will open-source the framework and our curated benchmarks soon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an automated framework for generating fine-grained benchmarks for foundation models, grounded in reference materials like textbooks. It employs a multi-agent architecture for problem generation and a solution-graph-driven strategy to improve ground-truth reliability. The framework is used to create benchmarks in Machine Learning, Corporate Finance, and Personal Finance, which are claimed to have broad coverage, rich metadata, robustness to contamination, and a significantly lower ground-truth error rate than MMLU and GSM8K per expert review. Evaluation of 12 models demonstrates near-uniform competency coverage and the ability to reveal performance differences missed by existing benchmarks.
Significance. If the expert review findings and coverage claims hold under rigorous protocols, the work could advance benchmark design by addressing contamination risks and lack of granularity in current evaluations, providing a reproducible pipeline for domain-specific assessments that better differentiate model capabilities.
major comments (2)
- [Abstract] Abstract: The central claim of a significantly lower ground-truth error rate via expert review compared to MMLU and GSM8K is not supported by any quantitative error rates, inter-rater reliability statistics, or a description of the review protocol (e.g., blinding, sampling, or error definition criteria).
- [Abstract and Methods] Abstract and Methods: The comparison to MMLU and GSM8K does not report a side-by-side re-review using identical experts, criteria, and domain difficulty controls, leaving open the possibility that differences arise from reviewer familiarity, problem selection, or review intensity rather than the multi-agent + solution-graph pipeline.
minor comments (2)
- [Abstract] The abstract states that the framework and benchmarks will be open-sourced soon, but provides no repository link, timeline, or licensing details to support reproducibility claims.
- [Evaluation] The description of 'near-uniform competency coverage' would benefit from explicit metrics or tables quantifying coverage across competencies for the generated benchmarks versus baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. The comments highlight important areas for improving the clarity and rigor of our claims regarding the expert review process. We address each major comment below and will revise the manuscript to incorporate additional details and discussion where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a significantly lower ground-truth error rate via expert review compared to MMLU and GSM8K is not supported by any quantitative error rates, inter-rater reliability statistics, or a description of the review protocol (e.g., blinding, sampling, or error definition criteria).
Authors: We agree that the abstract would benefit from greater specificity on these points. The full manuscript (Methods section) describes the expert review protocol, including the use of domain experts, error categorization, and sampling from generated problems, along with reported error rates. To address the referee's concern directly, we will revise the abstract to include quantitative error rates from the expert review, inter-rater reliability metrics such as Cohen's kappa, and a concise summary of the protocol details including blinding procedures, sampling strategy, and error definition criteria. revision: yes
-
Referee: [Abstract and Methods] Abstract and Methods: The comparison to MMLU and GSM8K does not report a side-by-side re-review using identical experts, criteria, and domain difficulty controls, leaving open the possibility that differences arise from reviewer familiarity, problem selection, or review intensity rather than the multi-agent + solution-graph pipeline.
Authors: This observation is fair and points to a potential limitation in the strength of the comparative claim. Our expert review focused on the newly generated benchmarks, with comparisons drawn to error rates reported in the original MMLU and GSM8K publications rather than a controlled re-evaluation of those benchmarks by the same reviewers. In the revised manuscript, we will add an explicit limitations subsection discussing this issue, including how reviewer familiarity and problem selection could influence results, while elaborating on the standardization of our review criteria and the role of the solution-graph approach in reducing errors. We maintain that the pipeline contributes to improved reliability but will present the comparison more cautiously. revision: partial
Circularity Check
No circularity: empirical method with external validation
full rationale
The paper describes an empirical pipeline for benchmark generation via multi-agent architecture and solution-graph strategy, followed by expert review and model evaluation. No derivations, equations, fitted parameters, or first-principles results are present that could reduce to inputs by construction. Claims rest on reported expert error rates and performance differences versus MMLU/GSM8K, which are positioned as independent measurements rather than self-referential. No self-citations or uniqueness theorems are invoked in the provided text to support core results. This is a standard empirical contribution with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Multi-agent architectures can generate evaluation problems grounded in reference materials with broad coverage.
- domain assumption Solution-graph-driven verification produces ground truths with significantly lower error rates than existing benchmarks.
Reference graph
Works this paper leans on
-
[1]
Identify: - Core concepts - Definitions - Theorems or rules - Procedures - Algorithms - Derived relationships - Subtle constraints or caveats
-
[2]
Construct (internally) a dependency graph of how concepts rely on each other. OUTPUT RULES: - Output VALID JSON ONLY. - Do NOT include any markdown fences. - Do NOT include any commentary outside JSON. Respond EXACTLY in the following format, including the JSON start and end markers: { "core_concepts": [{"name": "...", "description": "..."}], "definitions...
-
[3]
Requires multiple non-trivial reasoning steps
-
[4]
Combines two or more distinct concepts or results from different parts of the provided chapter
-
[5]
Includes at least one of the following: - A non-obvious dependency - A hidden constraint - A delayed-use intermediate result - A reasoning-mode shift (e.g., conceptual -> algebraic -> conceptual)
-
[6]
Has at least one plausible but incorrect alternative reasoning path
-
[7]
The trace must be logically correct and lead to a unique final answer
Cannot be solved by a single direct formula lookup. The trace must be logically correct and lead to a unique final answer. You must ensure: - Every step is justified using only the provided source. - The trace is internally consistent. - No external knowledge beyond the provided source is required. Phase 2 - Design the Problem From the Trace Now construct...
-
[8]
Solving the problem correctly requires following the designed trace (or an equally complex equivalent)
-
[9]
The problem statement: - Does NOT reference any section numbers, subsections, example numbers, or explicit mentions of the chapter structure. - Does NOT say "according to the chapter" or similar phrases. - Is fully self-contained. - Defines all necessary notation. - Includes all required assumptions
-
[10]
The problem cannot be solved by trivial pattern matching
-
[11]
Phase 3 - Construct High-Quality Answer Choices The problem must have exactly 5 answer options: A
The reasoning chain is necessary for correctness. Phase 3 - Construct High-Quality Answer Choices The problem must have exactly 5 answer options: A. B. 29 C. D. E. None of the above. Requirements for answer choices:
-
[12]
Exactly one option must be correct
-
[13]
- Based on common misunderstandings of the material
Distractors must be: - Derived from realistic but incorrect reasoning paths. - Based on common misunderstandings of the material. - Close in structure or value to the correct answer. - Not trivially eliminable
-
[14]
"None of the above" must be a viable option (i.e., the other options should not trivially rule it out)
-
[15]
Avoid obviously absurd or dimensionally inconsistent distractors
-
[16]
Phase 4 - Internal Verification Before outputting:
Do not include meta-commentary in the options. Phase 4 - Internal Verification Before outputting:
-
[17]
Independently verify the solution step-by-step
-
[18]
- The answer is uniquely correct
Check that: - The problem is unambiguous. - The answer is uniquely correct. - No shortcut makes the problem trivial. - The reasoning genuinely requires multiple structured steps
-
[19]
Required Output: Output must contain the following sections in order:
Ensure the problem depends only on the provided source. Required Output: Output must contain the following sections in order:
-
[20]
The constructed solution graph specifying nodes and edges
-
[21]
The Problem (Provide the complete, self-contained multiple-choice problem here.)
-
[22]
Answer Choices A. B. C. D. E. None of the above
-
[23]
Correct Answer (Provide only the letter.)
-
[24]
Option E MUST remain EXACTLY: "None of the above". Provide a fully rigorous, step-by-step solution that follows the intended reasoning trace. Do NOT reference any section numbers or structural elements of the source in the solution. Difficulty Requirements The problem must: - Require at least 4-6 logically connected reasoning steps. - Combine multiple con...
-
[25]
Example verbs: calculate, demonstrate, use, implement
Apply - Use knowledge or methods in new but familiar situations. Example verbs: calculate, demonstrate, use, implement
-
[26]
Example verbs: differentiate, compare, examine, infer
Analyze - Break information into parts and examine relationships or patterns. Example verbs: differentiate, compare, examine, infer
-
[27]
Example verbs: justify, critique, assess, argue
Evaluate - Make judgments based on criteria and standards. Example verbs: justify, critique, assess, argue
-
[28]
Example verbs: design, compose, formulate, generate
Create - Combine elements to form a new pattern, structure, or product. Example verbs: design, compose, formulate, generate. H.3 Refinement Stage Prompts Below we provide the Refinement Stage prompts. 31 H.3.1 Self-Containment Repair Below we provide the Prompt for Self-Containment Repair. Prompt for Self-Containment Repair You will be given a question in...
-
[29]
- No missing jumps or unjustified claims
Trace validity: - Each step/node follows from prior steps/nodes and the described operation. - No missing jumps or unjustified claims. - The final answer implied by the trace is explicit
-
[30]
Option consistency: 32 - Exactly ONE option among A-E matches the trace’s final answer. - correct_answer must point to that uniquely matching option. - All other options must NOT match the trace final answer. Option E rule: - Option E MUST remain EXACTLY: "None of the above". - If any of A-D matches the trace final answer, then E must be incorrect. - If n...
-
[31]
Bloom’s alignment: - The revised question must still match the requested Bloom’s level. - Do not simplify the task into a lower-level cognitive action. - If the candidate drifts away from the requested Bloom’s level, minimally revise it so the final MCQ matches the target. ------------------------- WHAT TO DO IF ISSUES EXIST ------------------------- A) I...
-
[32]
solution_graph (with nodes and edges)
-
[33]
question (the MCQ stem)
-
[34]
options (A, B, C, D, E)
-
[35]
correct_answer (one of A, B, C, D, E)
-
[36]
complete_solution (the rigorous step-by-step solution text) Respond EXACTLY in the following format, including the JSON start and end markers: { "solution_graph": { "nodes": [{"id": "V1", "content": "..."}, {"id": "V2", "content": "..."}], "edges": [{"from": "V1", "to": "V2", "operation": "..."}] }, "question": "<self-contained MCQ stem>", "options": { "A...
-
[37]
Multiple-Choice Integrity. For the question: - Exactly **five** options (A, B, C, D, E) are present and non-empty strings. - Option "E" is labeled as "None of the above". - Distractors are plausible (reflect common misconceptions or near-misses) yet unambiguously incorrect if the concept is understood
-
[38]
Constraint Compliance. - Avoid vague absolutes ("always," "never," "most likely") unless explicitly required by the blueprint. - If LaTeX appears, ensure escaped backslashes are used inside JSON strings ( e.g., "$\\frac{1}{2}$"). - Must NOT explicitly refer to any section/theorem/lemma identifiers (e.g., " Section 2.1", "Theorem 2.1.1", "Lemma 2.1.1"). - ...
-
[39]
- Check whether the question genuinely matches the requested Bloom’s level
Bloom’s Alignment. - Check whether the question genuinely matches the requested Bloom’s level. - Use the following operational definitions: - Apply: requires selecting and using taught methods in a concrete but non- trivial situation. - Analyze: requires breaking the situation into parts, tracing relationships, comparing cases, or inferring structure. - E...
-
[40]
Output Format (Strict). - STRICTLY ensure that the candidate output must be valid JSON and follow the expected structure: - Top-level is a single JSON object (NOT a list) - It has: - "question" (string) - "options" (object with keys A-E) - "correct_answer" (one of "A","B","C","D","E") - Any missing key, wrong key (e.g., "questio"), wrong count, duplicate ...
-
[41]
Previous Candidate Output: an MCQ that may be malformed JSON (or valid JSON but wrong formatting)
-
[42]
Verifier LLM Feedback: indicates formatting/JSON issues
-
[43]
The original MCQ content must be preserved exactly. YOUR GOAL Fix ONLY the JSON formatting so that the output is valid JSON and can be parsed by a standard JSON parser. WHAT YOU MUST DO - Produce a single valid JSON object that matches the intended schema. - Preserve the question text, all option texts, and the correct answer EXACTLY as they appear in the...
-
[44]
Previous Candidate Output: a single MCQ in JSON (may be imperfect)
-
[45]
Verifier LLM Feedback: issues to fix (MCQ correctness, integrity, ambiguity, constraints, etc.)
-
[46]
chapter_material: textbook chapter excerpt that constrains scope and facts
-
[47]
chapter_knowledge_text: structured knowledge summary of the chapter
-
[48]
solution_trace: the reasoning trace/solution graph associated with the question
-
[49]
previous_questions: a list of previously generated questions for this chapter (anti-dup). YOUR GOAL Repair the MCQ so it is fully consistent with the provided solution_trace and grounded ONLY in chapter_material and chapter_knowledge_text. 38 The solution_trace is the strongest constraint: the revised question must be solvable via the trace, and the corre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.