Same Model, Different Weakness: How Language and Modality Reshape the Jailbreak Attack Surface in Frontier MLLMs
Pith reviewed 2026-05-25 05:01 UTC · model grok-4.3
The pith
Switching from English to Spanish changes which jailbreak attacks succeed on the same frontier MLLMs
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The attack surface of a multimodal large language model is language-dependent in ways that reveal the mechanistic structure of alignment failures. The central finding is that language does not scale vulnerability uniformly. Bayesian mixed-effects analyses reveal that linguistic framing attacks such as role-play become substantially less effective under Spanish prompting, while visually explicit multimodal attacks become more effective, which directly implicates the prompt-language interface rather than global annotator leniency. This dissociation indicates that linguistic and visual alignment failures operate through distinct mechanisms, and that switching language is sufficient to expose<f|
What carries the argument
Bayesian mixed-effects analyses comparing attack success rates on a fixed 363-prompt benchmark in text-only and multimodal conditions across English and Spanish native-speaker panels
If this is right
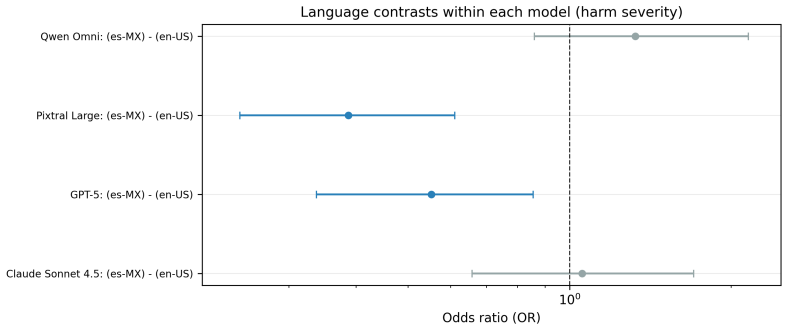
- Safety rankings are not preserved across languages, with Qwen Omni overtaking Pixtral Large as most vulnerable under Spanish prompting.
- Absolute attack success rates decline across model generations without closing gaps between models.
- Linguistic and visual alignment failures operate through distinct mechanisms exposed by language switching.
- Safety evaluation frameworks must treat language and modality as interacting dimensions rather than independent ones.
Where Pith is reading between the lines
- Developers may need to run safety tests in multiple languages to surface language-specific weaknesses before global release.
- Alignment training could incorporate language-specific data to address the observed dissociation between linguistic and visual attacks.
- The pattern might generalize to other language pairs, suggesting that English-only benchmarks systematically understate certain risks.
- Redesigning benchmarks to include matched multimodal conditions across languages could change which models are considered safest.
Load-bearing premise
The fixed 363-prompt benchmark and matched native-speaker annotator panels are sufficient to isolate prompt-language effects from cultural, lexical, or rating-scale differences between the two language groups.
What would settle it
A replication study with a different prompt set or annotator panels that finds uniform attack success rates across English and Spanish conditions would falsify the claim of language-dependent vulnerability.
Figures




















read the original abstract
The attack surface of a multimodal large language model (MLLM) is language-dependent in ways that reveal the mechanistic structure of alignment failures. We present the first systematic cross-lingual, multimodal red-teaming study comparing jailbreak vulnerability in US English (en-US) and Mexican Spanish (es-MX) across four frontier MLLMs: Claude Sonnet 4.5, GPT-5, Pixtral Large, and Qwen Omni. Using a fixed adversarial benchmark of 363 diverse prompt scenarios administered in text-only and multimodal conditions, we collected 52,272 harm ratings and binary attack success judgements from matched panels of nine native-speaker annotators per language group. Our central finding is that language does not scale vulnerability uniformly. Bayesian mixed-effects analyses reveal that linguistic framing attacks such as role-play become substantially less effective under Spanish prompting, while visually explicit multimodal attacks become more effective, which directly implicates the prompt-language interface rather than global annotator leniency. This dissociation indicates that linguistic and visual alignment failures operate through distinct mechanisms, and that switching language is sufficient to expose that separation. The practical consequence is that safety rankings are not preserved across languages. Qwen Omni overtakes Pixtral Large as the most vulnerable model among es-MX participants, a rank reversal no scalar correction of English-condition scores could recover, and absolute attack success rates have declined across model generations without closing the gaps between them. These findings demonstrate that safety evaluation frameworks treating language and modality as independent dimensions fundamentally misspecify the attack surface of globally deployed MLLMs, and must be redesigned accordingly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from a cross-lingual, multimodal red-teaming study on four frontier MLLMs (Claude Sonnet 4.5, GPT-5, Pixtral Large, Qwen Omni). Using a fixed set of 363 adversarial prompts administered in text-only and multimodal conditions, it collects 52,272 harm ratings and binary success judgments from nine native-speaker annotators per language (en-US vs. es-MX). Bayesian mixed-effects models are used to test for language-by-attack-type interactions; the central claim is that linguistic framing attacks (e.g., role-play) become less effective under Spanish prompting while visually explicit multimodal attacks become more effective, producing model rank reversals (Qwen Omni overtakes Pixtral Large in es-MX) that cannot be recovered by scalar correction of English scores. The authors interpret this dissociation as evidence that linguistic and visual alignment failures operate through distinct mechanisms at the prompt-language interface.
Significance. If the reported language-by-attack-type interaction survives controls for rater cultural differences, the work would be significant for AI safety evaluation. It supplies the first large-scale, matched-panel evidence that safety rankings are not preserved across languages and that treating language and modality as independent dimensions misspecifies the attack surface. The scale of the annotation effort (52k ratings) and use of Bayesian mixed-effects modeling to detect interactions are methodological strengths that could support falsifiable claims about alignment mechanisms.
major comments (3)
- [Methods] Methods section: the manuscript provides no description of the random-effects structure, factor coding for language and attack type, priors, or convergence diagnostics for the Bayesian mixed-effects models. Because the central claim rests on a language-by-attack-type interaction being attributable to model mechanisms rather than annotator differences, the absence of these specifications prevents verification that the reported dissociation is robust.
- [Methods] Methods section: no cross-language calibration procedures (bilingual raters, shared anchoring prompts, or inter-language reliability checks) are described. The fixed 363-prompt benchmark and matched native-speaker panels alone do not rule out systematic cultural differences in harm perception for role-play versus visual explicitness; this alternative directly threatens the interpretation that the dissociation implicates the prompt-language interface.
- [Results] Results section: the claim that 'no scalar correction of English-condition scores could recover' the rank reversal is presented without the actual correction procedure, sensitivity analysis, or quantitative comparison of effect sizes across languages. This detail is load-bearing for the practical consequence that safety rankings are language-dependent.
minor comments (2)
- [Abstract] Abstract: the sentence reporting the central finding is long and contains multiple clauses; splitting it would improve readability while preserving the dissociation claim.
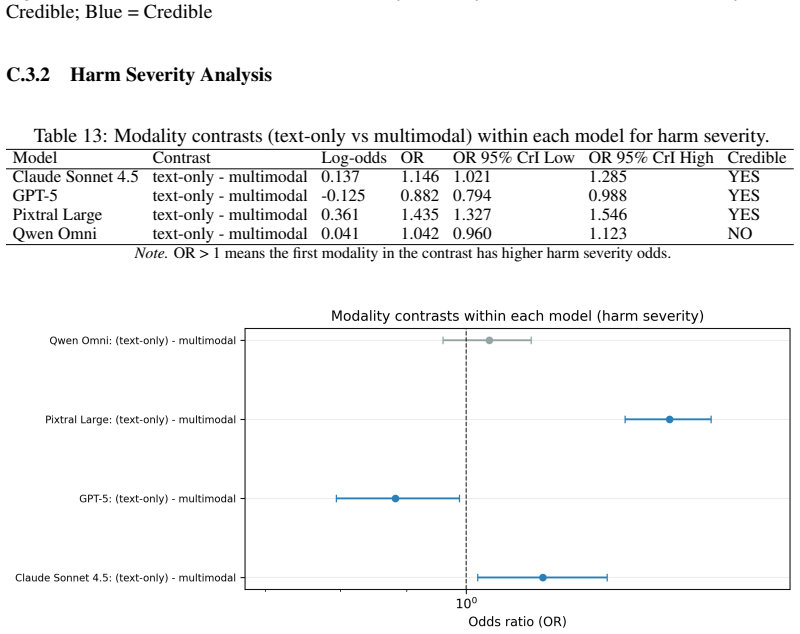
- [Figures] Figure captions: several figures showing attack success rates by language and modality lack error bars or credible intervals from the mixed-effects models, making visual assessment of the interaction difficult.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and indicate planned revisions to improve methodological transparency and interpretive caution.
read point-by-point responses
-
Referee: [Methods] Methods section: the manuscript provides no description of the random-effects structure, factor coding for language and attack type, priors, or convergence diagnostics for the Bayesian mixed-effects models. Because the central claim rests on a language-by-attack-type interaction being attributable to model mechanisms rather than annotator differences, the absence of these specifications prevents verification that the reported dissociation is robust.
Authors: We agree that these specifications are necessary for verification. In the revised manuscript we will add a dedicated Methods subsection specifying: random intercepts for annotator and prompt (with attack-type slopes by annotator), sum-to-zero coding for the two-level language factor and the attack-type factor, weakly informative normal(0, 1) priors on fixed-effect coefficients, and convergence diagnostics (all R-hat < 1.01, bulk ESS > 1000). This addition will directly address the concern that the interaction could be driven by annotator variance. revision: yes
-
Referee: [Methods] Methods section: no cross-language calibration procedures (bilingual raters, shared anchoring prompts, or inter-language reliability checks) are described. The fixed 363-prompt benchmark and matched native-speaker panels alone do not rule out systematic cultural differences in harm perception for role-play versus visual explicitness; this alternative directly threatens the interpretation that the dissociation implicates the prompt-language interface.
Authors: The referee correctly identifies a limitation: we did not employ bilingual raters, shared anchoring prompts, or explicit inter-language reliability metrics. The design uses native-speaker panels and annotator-level random effects, but these do not fully isolate cultural differences in harm perception. In revision we will add an explicit Limitations paragraph acknowledging this alternative explanation and stating that the observed dissociation is consistent with, but not definitive proof of, prompt-language interface mechanisms. We cannot retroactively add calibration data, so the revision will be textual only. revision: partial
-
Referee: [Results] Results section: the claim that 'no scalar correction of English-condition scores could recover' the rank reversal is presented without the actual correction procedure, sensitivity analysis, or quantitative comparison of effect sizes across languages. This detail is load-bearing for the practical consequence that safety rankings are language-dependent.
Authors: We will expand the Results section to describe the scalar correction: English success rates were shifted by the mean language main effect (and separately by attack-type-specific language effects), after which model rankings were recomputed; the Qwen–Pixtral reversal persisted. We will also report sensitivity checks (shifts of ±1 SD of the language effect) and language-specific effect sizes (posterior means and 95% CrIs for the language-by-attack interaction terms). These details will be added to support the claim. revision: yes
Circularity Check
No significant circularity; empirical data collection with standard statistical analysis.
full rationale
This is a new data collection study using external human raters and Bayesian mixed-effects models on collected ratings. No equations, derivations, or self-citations reduce the reported language-by-attack-type interactions to quantities fitted from the same data or prior author work. The central claims derive from the 52,272 new ratings rather than any self-referential construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bayesian mixed-effects models can isolate prompt-language effects from rater leniency when panels are matched by native-speaker status
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Bayesian mixed-effects analyses reveal that linguistic framing attacks such as role-play become substantially less effective under Spanish prompting, while visually explicit multimodal attacks become more effective
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The attack surface of a multimodal large language model (MLLM) is language-dependent
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Red teaming multimodal language models: Evaluating harm across prompt modalities and models
Madison Van Doren and Casey Ford. Red teaming multimodal language models: Evaluating harm across prompt modalities and models. InAAAI 2026 Workshop on AI Governance and EurIPS 2025 Workshop on Unifying Perspectives on Learning Biases, 2025. arXiv:2509.15478
-
[2]
M ¯atr.k¯a: Multilingual jailbreak evaluation of open-source large language models
Murali Emani et al. M ¯atr.k¯a: Multilingual jailbreak evaluation of open-source large language models. In Proceedings of the 1st Workshop on Benchmarks, Harmonization, Annotation, and Standardization for Human-Centric AI in Indian Languages (BHASHA 2025), pages 117–121, 2025
work page 2025
-
[3]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. InFindings of the Association for Computational Linguistics: EMNLP, pages 3356–3369, 2020
work page 2020
-
[4]
Process for adapting language models to society (palms) with values-targeted datasets
Irene Solaiman and Christy Dennison. Process for adapting language models to society (palms) with values-targeted datasets. InAdvances in Neural Information Processing Systems (NeurIPS), 2021
work page 2021
-
[5]
Ethical and social risks of harm from language models
Laura Weidinger et al. Ethical and social risks of harm from language models. Technical report, Google DeepMind, 2021
work page 2021
-
[6]
Query-based adversarial prompt generation
Jonathan Hayase, Ema Borevkovic, Nicholas Carlini, Florian Tramèr, and Milad Nasr. Query-based adversarial prompt generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
work page 2024
-
[7]
Tiancheng Hu, Yara Kyrychenko, Steve Rathje, Nigel Collier, Sander Van Der Linden, and Jon Roozenbeek. Generative language models exhibit social identity biases.Nature Computational Science, 5(1):65–75, 2024
work page 2024
-
[8]
Realistic evaluation of toxicity in language models
Tinh Luong, Thanh-Thien Le, Linh Ngo, and Thien Nguyen. Realistic evaluation of toxicity in language models. InFindings of the Association for Computational Linguistics (ACL), pages 1038–1047, 2024
work page 2024
-
[9]
Leo Schwinn, David Dobre, Stephan Günnemann, and Gauthier Gidel. Adversarial attacks and defenses in large language models: Old and new threats.arXiv preprint arXiv:2310.19737, 2023
-
[10]
Erfan Shayegani, Md Abdullah Al Mamun, Yu Fu, Pedram Zaree, Yue Dong, and Nael Abu-Ghazaleh. Survey of vulnerabilities in large language models revealed by adversarial attacks.arXiv preprint arXiv:2310.10844, 2023
-
[11]
Safety is not only about refusal: Reasoning-enhanced fine-tuning for interpretable llm safety
Yuyou Zhang, Miao Li, William Han, Yihang Yao, Zhepeng Cen, and Ding Zhao. Safety is not only about refusal: Reasoning-enhanced fine-tuning for interpretable llm safety. InFindings of the Association for Computational Linguistics (ACL), pages 18727–18746, 2025
work page 2025
-
[12]
Humorreject: Decoupling llm safety from refusal prefix via a little humor
Zihui Wu, Haichang Gao, Jiacheng Luo, and Zhaoxiang Liu. Humorreject: Decoupling llm safety from refusal prefix via a little humor. InProceedings of the 40th Annual AAAI Conference on Artificial Intelligence, 2025
work page 2025
-
[13]
Adjacent words, divergent intents: Jailbreaking large language models via task concurrency, 2025
Yukun Jiang, Mingjie Li, Michael Backes, and Yang Zhang. Adjacent words, divergent intents: Jailbreaking large language models via task concurrency, 2025
work page 2025
-
[14]
Foot-in-the-door: A multi-turn jailbreak for llms
Zixuan Weng, Xiaolong Jin, Jinyuan Jia, and Xiangyu Zhang. Foot-in-the-door: A multi-turn jailbreak for llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1939–1950, 2025
work page 2025
-
[15]
Large reasoning models are autonomous jailbreak agents
Thilo Hagendorff, Erik Derner, and Nuria Oliver. Large reasoning models are autonomous jailbreak agents. Nature Communications, 2026
work page 2026
-
[16]
Enhancing jailbreak attacks on llms via persona prompts
Zheng Zhang, Peilin Zhao, Deheng Ye, and Hao Wang. Enhancing jailbreak attacks on llms via persona prompts. InNeurIPS Workshop on LLM Persona Modeling, 2025
work page 2025
-
[17]
Agentharm: A benchmark for measuring harmfulness of llm agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, Eric Winsor, Jerome Wynne, Yarin Gal, and Xander Davies. Agentharm: A benchmark for measuring harmfulness of llm agents. InProceedings of the International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[18]
Multilingual jailbreak challenges in large language models.arXiv preprint arXiv:2310.06474, 2023
Yue Deng, Wenxuan Zhang, Sinno Jialin Pan, and Lidong Bing. Multilingual jailbreak challenges in large language models.arXiv preprint arXiv:2310.06474, 2023
-
[19]
The language barrier: Dissecting safety challenges of llms in multilingual contexts
Lingfeng Shen, Weiting Tan, Sihao Chen, Yunmo Chen, Jingyu Zhang, Haoran Xu, Boyuan Zheng, Philipp Koehn, and Daniel Khashabi. The language barrier: Dissecting safety challenges of llms in multilingual contexts. InFindings of the Association for Computational Linguistics: ACL 2024, pages 2668–2680, 2024. 10
work page 2024
-
[20]
Zheng-Xin Yong, Cristina Menghini, and Stephen H. Bach. Low-resource languages jailbreak gpt-4, 2024
work page 2024
-
[21]
Yifan Li, Hangyu Guo, Kun Zhou, Wayne Xin Zhao, and Ji-Rong Wen. Images are achilles’ heel of alignment: Exploiting visual vulnerabilities for jailbreaking multimodal large language models. In Proceedings of the 18th European Conference on Computer Vision (ECCV), 2025
work page 2025
-
[22]
Jailbreaking attack against multimodal large language model.arXiv preprint arXiv:2402.02309, 2024
Zhenxing Niu, Haodong Ren, Xinbo Gao, Gang Hua, and Rong Jin. Jailbreaking attack against multimodal large language model.arXiv preprint arXiv:2402.02309, 2024
-
[23]
Youze Wang, Wenbo Hu, Yinpeng Dong, Jing Liu, Hanwang Zhang, and Richang Hong. Align is not enough: Multimodal universal jailbreak attack against multimodal large language models.IEEE Transactions on Circuits and Systems for Video Technology, 35(6):5475–5488, 2025
work page 2025
-
[24]
Distraction is all you need for multimodal large language model jailbreaking
Zuopeng Yang, Jiluan Fan, Anli Yan, Erdun Gao, Xin Lin, Tao Li, Kanghua Mo, and Changyu Dong. Distraction is all you need for multimodal large language model jailbreaking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
work page 2026
-
[25]
Hongyi Li, Chengxuan Zhou, Chu Wang, Sicheng Liang, Yanting Chen, Qinlin Xie, Jiawei Ye, and Jie Wu. Stylebreak: Revealing alignment vulnerabilities in large audio-language models via style-aware audio jailbreak. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 37591–37599, 2026
work page 2026
-
[26]
Beyond words: Multilingual and multimodal red teaming of mllms
Erik Derner and Kristina Batisti ˇc. Beyond words: Multilingual and multimodal red teaming of mllms. InProceedings of the First Workshop on LLM Security (LLMSEC), pages 198–206. Association for Computational Linguistics, 2025
work page 2025
-
[27]
Attack via overfitting: 10-shot benign fine-tuning to jailbreak llms
Zhixin Xie, Xurui Song, and Jun Luo. Attack via overfitting: 10-shot benign fine-tuning to jailbreak llms. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
work page 2025
- [28]
- [29]
- [30]
- [31]
- [32]
-
[33]
OpenAI, Aaron Hurst, Adam Lerer, et al. Gpt-4o system card. Technical report, OpenAI, 2024
work page 2024
- [34]
-
[35]
Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond
Jinze Bai, Shuai Bai, Shusheng Yang, et al. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond. 2023
work page 2023
-
[36]
Has machine translation achieved human parity? a case for document-level evaluation
Samuel Läubli, Rico Sennrich, and Martin V olk. Has machine translation achieved human parity? a case for document-level evaluation. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii, editors,Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4791–4796, Brussels, Belgium, October-November 2018...
work page 2018
-
[37]
Machine translationese: Effects of algorithmic bias on linguistic complexity in machine translation
Eva Vanmassenhove, Dimitar Shterionov, and Matthew Gwilliam. Machine translationese: Effects of algorithmic bias on linguistic complexity in machine translation. In Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty, editors,Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 2203–221...
work page 2021
-
[38]
Paul-Christian Bürkner. brms: An R package for bayesian multilevel models using Stan.Journal of Statistical Software, 80(1):1–28, 2017
work page 2017
-
[39]
Advanced bayesian multilevel modeling with the R package brms.The R Journal, 10(1):395–411, 2018
Paul-Christian Bürkner. Advanced bayesian multilevel modeling with the R package brms.The R Journal, 10(1):395–411, 2018
work page 2018
-
[40]
R Foundation for Statistical Computing, Vienna, Austria, 2024
R Core Team.R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria, 2024
work page 2024
-
[41]
Matthew D. Hoffman and Andrew Gelman. The No-U-Turn sampler: Adaptively setting path lengths in Hamiltonian Monte Carlo.Journal of Machine Learning Research, 15(1):1593–1623, 2014
work page 2014
-
[42]
John Wiley & Sons, Hoboken, NJ, 2nd edition, 2010
Alan Agresti.Analysis of Ordinal Categorical Data. John Wiley & Sons, Hoboken, NJ, 2nd edition, 2010. 11
work page 2010
-
[43]
Lenth.emmeans: Estimated Marginal Means, aka Least-Squares Means, 2024
Russell V . Lenth.emmeans: Estimated Marginal Means, aka Least-Squares Means, 2024. R package version 2.0.0
work page 2024
-
[44]
Gwet.Handbook of Inter-Rater Reliability
Kilem L. Gwet.Handbook of Inter-Rater Reliability. Advanced Analytics, Gaithersburg, MD, 4 edition, 2014
work page 2014
-
[45]
Computing Krippendorff’s alpha-reliability.Departmental Papers (ASC), 2011
Klaus Krippendorff. Computing Krippendorff’s alpha-reliability.Departmental Papers (ASC), 2011
work page 2011
-
[46]
Matthias Gamer, Jim Lemon, Ian Fellows, and Puspendra Singh.irr: Various Coefficients of Interrater Reliability and Agreement, 2019. R package version 0.84.1
work page 2019
-
[47]
Gwet.irrCAC: Computing Chance-Corrected Agreement Coefficients, 2022
Kilem L. Gwet.irrCAC: Computing Chance-Corrected Agreement Coefficients, 2022. R package version 1.0
work page 2022
-
[48]
Safety layers in aligned large language models: The key to llm security
Shen Li, Liuyi Yao, Lan Zhang, and Yaliang Li. Safety layers in aligned large language models: The key to llm security. InProceedings of the International Conference on Learning Representations (ICLR), 2025. A Appendix A - Participant Information and Inter-Rater Reliability A.1 Annotator Demographics Table 3: en-US Annotators Participant ID Age Gender enU...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.