An SDP Relaxation for the Sparse Integer Least Squares Problem
Pith reviewed 2026-05-24 11:26 UTC · model grok-4.3
The pith
An l1-based SDP relaxation solves the sparse integer least squares problem exactly under sufficient data conditions and yields a randomized 1/T²-approximation algorithm when sparsity is much smaller than T.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
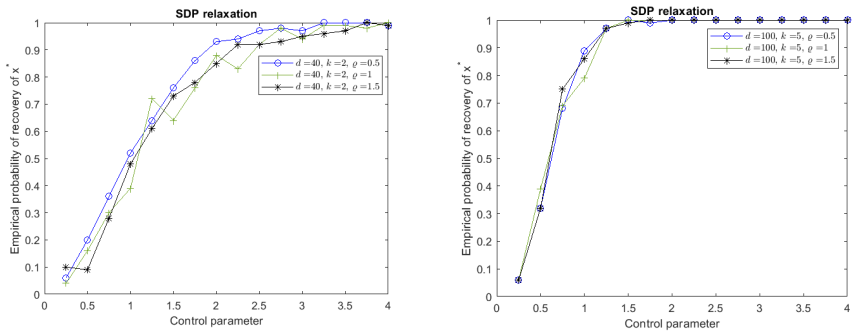
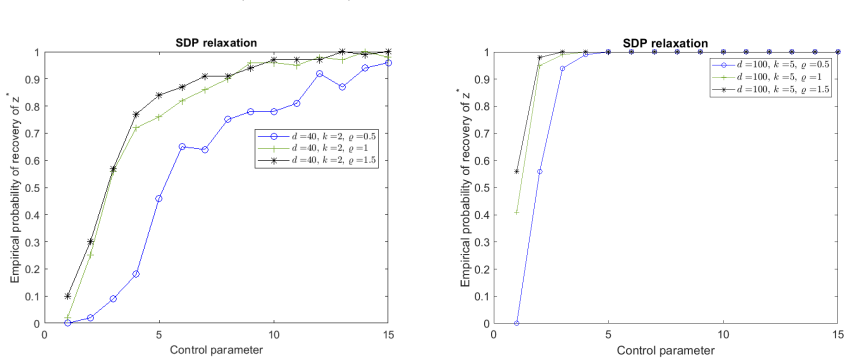
The central claim is that the proposed l1-based SDP relaxation, together with a randomized rounding procedure, recovers optimal or asymptotically 1/T²-approximate solutions to SILS; moreover, when the data matrix satisfies explicit sub-Gaussian or coherence conditions the SDP optimum coincides exactly with the SILS optimum.
What carries the argument
The l1-based SDP relaxation that replaces the cardinality and integrality constraints on the {0, ±1}-vector while preserving the quadratic objective.
If this is right
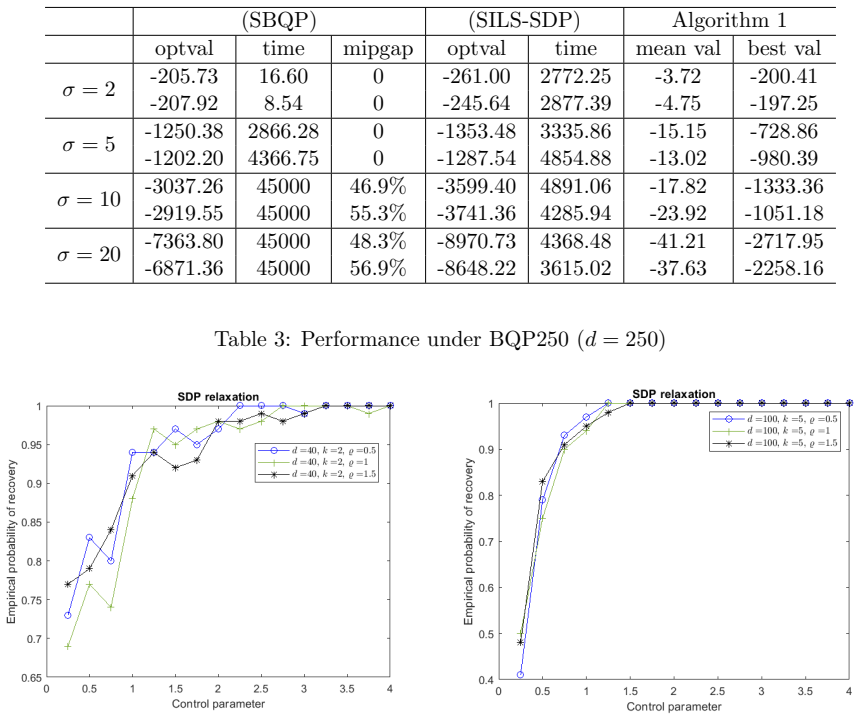
- The randomized algorithm scales to instances with dimension d = 10,000 while returning high-quality feasible points.
- The same rounding procedure yields approximation guarantees for any binary quadratic program subject to a cardinality constraint.
- Exact recovery via the SDP holds for the feature-extraction and integer-sparse-recovery problems under the identified data regimes.
- The method supplies polynomial-time certificates of optimality for SILS when the data conditions are met.
Where Pith is reading between the lines
- The same SDP could be tested on other cardinality-constrained quadratic problems arising in combinatorial optimization beyond the two application domains named.
- If the data conditions can be verified from samples, the approach supplies a practical test for whether an instance is solved exactly by the relaxation.
- Extensions that replace the l1 term by other convex surrogates might enlarge the class of data matrices for which exactness holds.
Load-bearing premise
The input data matrix satisfies the stated sufficient conditions that make the SDP optimal solution coincide with the SILS optimum.
What would settle it
A concrete data matrix obeying the problem dimensions but violating the sub-Gaussian or coherence conditions for which the SDP optimum differs from the true SILS optimum.
Figures
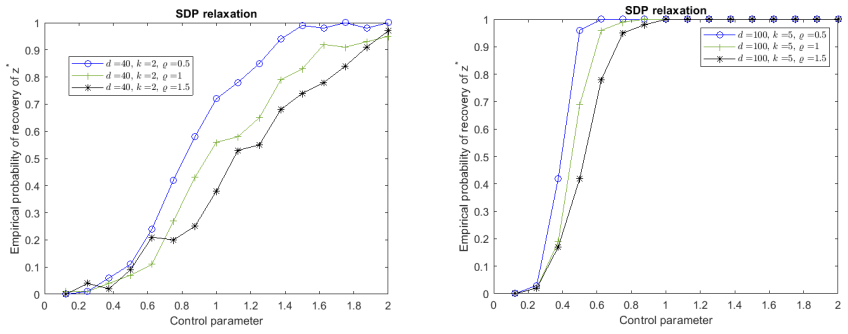
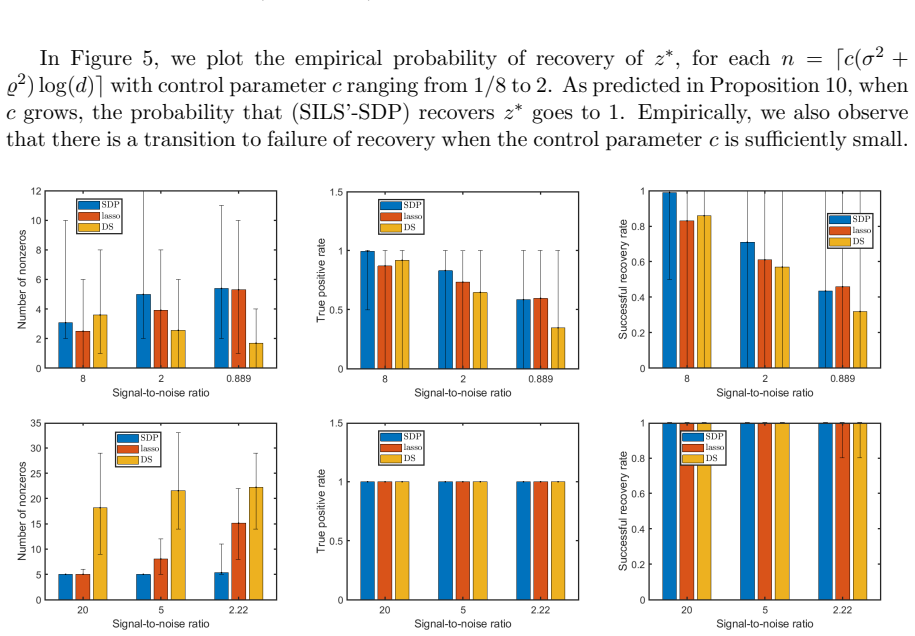
read the original abstract
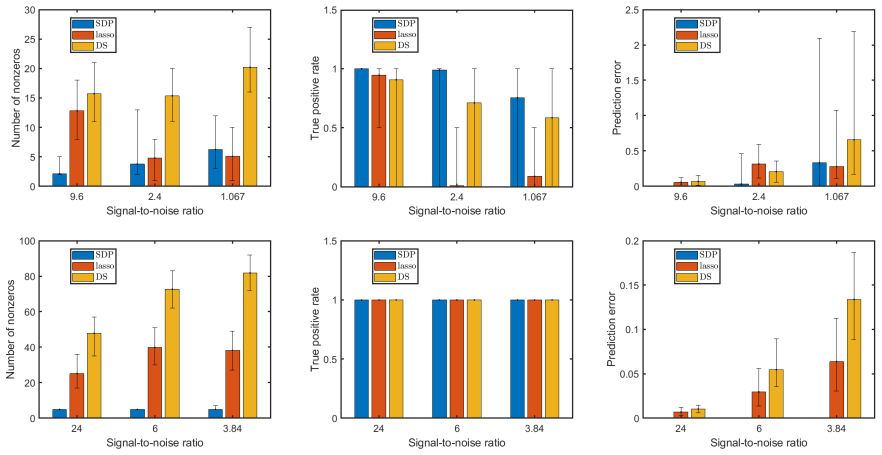
In this paper, we study the \emph{sparse integer least squares problem} (SILS), an NP-hard variant of least squares with sparse $\{0, \pm 1\}$-vectors. We propose an $\ell_1$-based SDP relaxation, and a randomized algorithm for SILS, which computes feasible solutions with high probability with an asymptotic approximation ratio $1/T^2$ as long as the sparsity constant $\sigma \ll T$. Our algorithm handles large-scale problems, delivering high-quality approximate solutions for dimensions up to $d = 10,000$. The proposed randomized algorithm applies broadly to binary quadratic programs with a cardinality constraint, even for non-convex objectives. For fixed sparsity, we provide sufficient conditions for our SDP relaxation to solve SILS, meaning that any optimal solution to the SDP relaxation yields an optimal solution to SILS. The class of data input which guarantees that SDP solves SILS is broad enough to cover many cases in real-world applications, such as privacy preserving identification and multiuser detection. We validate these conditions in two application-specific cases: the \emph{feature extraction problem}, where our relaxation solves the problem for sub-Gaussian data with weak covariance conditions, and the \emph{integer sparse recovery problem}, where our relaxation solves the problem in both high and low coherence settings under certain conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies the sparse integer least squares (SILS) problem and proposes an ℓ₁-based SDP relaxation together with a randomized rounding procedure. It claims that the randomized algorithm returns feasible solutions with high probability and achieves an asymptotic approximation ratio of 1/T² whenever the sparsity constant σ ≪ T; for fixed sparsity it supplies sufficient conditions (sub-Gaussian data with weak covariance, or bounded coherence) under which any optimal SDP solution is optimal for the original SILS instance. The method is shown to scale to dimension 10 000 and is illustrated on feature-extraction and integer-sparse-recovery tasks.
Significance. If the stated approximation guarantee and the exact-recovery conditions are rigorously established, the work supplies a practical, theoretically supported approach to a class of NP-hard cardinality-constrained quadratic programs that arises in signal processing and privacy applications. The explicit large-scale numerical demonstration and the breadth of the data classes covered are concrete strengths.
minor comments (3)
- The abstract states that the randomized algorithm 'computes feasible solutions with high probability'; the precise probability bound and its dependence on T and σ should be stated explicitly in the theorem that establishes the 1/T² ratio.
- The sufficient conditions for exact SDP recovery are described as 'broad enough to cover many cases in real-world applications'; a short paragraph quantifying how often the sub-Gaussian/weak-covariance or coherence assumptions are expected to hold in the cited application domains would improve readability.
- Notation for the scaling parameter T and the sparsity constant σ is introduced without an explicit forward reference to the section that defines them; adding a sentence in the introduction that points to their definitions would help readers.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the paper, recognition of its significance, and recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The derivation chain rests on an SDP relaxation whose tightness is proven under external sufficient conditions on the input matrix (sub-Gaussian with weak covariance, or bounded coherence). The randomized rounding procedure's 1/T² asymptotic ratio is stated to hold when σ ≪ T; both results are derived from analysis of the stated data assumptions rather than by fitting parameters to the target quantities or by self-referential definitions. No load-bearing self-citation, ansatz smuggling, or renaming of known results appears in the abstract or described claims. The paper is therefore self-contained against its external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- sparsity constant σ
- scaling parameter T
axioms (1)
- domain assumption Data matrix satisfies sub-Gaussian or bounded-coherence conditions sufficient for SDP optimality
Reference graph
Works this paper leans on
-
[1]
Closest point search in lattices
Erik Agrell, Thomas Eriksson, Alexander Vardy, and Kenneth Zeger. Closest point search in lattices. IEEE Transactions on Information Theory , 48(8):2201–2214, 2002. 43
work page 2002
-
[2]
High-dimensional analysis of semidefinite relax- ations for sparse principal components
Arash A Amini and Martin J Wainwright. High-dimensional analysis of semidefinite relax- ations for sparse principal components. In IEEE International Symposium on Information Theory, pages 2454–2458, 2008
work page 2008
-
[3]
The MOSEK optimization toolbox for MATLAB manual
MOSEK ApS. The MOSEK optimization toolbox for MATLAB manual. Version 9.2., 2020
work page 2020
-
[4]
Nonuniform Sparse Recovery with Subgaussian Matrices
Ula¸ s Ayaz and Holger Rauhut. Nonuniform sparse recovery with subgaussian matrices. arXiv preprint arXiv:1007.2354 , 2010
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[5]
Sparsity-aware sphere decoding: Algorithms and com- plexity analysis
Somsubhra Barik and Haris Vikalo. Sparsity-aware sphere decoding: Algorithms and com- plexity analysis. IEEE Transactions on Signal Processing , 62(9):2212–2225, 2014
work page 2014
-
[6]
Or-library: distributing test problems by electronic mail
John E Beasley. Or-library: distributing test problems by electronic mail. Journal of the operational research society, 41(11):1069–1072, 1990
work page 1990
-
[7]
Best subset selection via a modern optimization lens
Dimitris Bertsimas, Angela King, and Rahul Mazumder. Best subset selection via a modern optimization lens. The annals of statistics , 44(2):813–852, 2016
work page 2016
-
[8]
Stephen Boyd, Stephen P Boyd, and Lieven Vandenberghe. Convex optimization . Cam- bridge university press, 2004
work page 2004
-
[9]
The dantzig selector: Statistical estimation when p is much larger than n
Emmanuel Candes and Terence Tao. The dantzig selector: Statistical estimation when p is much larger than n. Annals of statistics , 35(6):2313–2351, 2007
work page 2007
-
[10]
Decoding by linear programming
Emmanuel J Candes and Terence Tao. Decoding by linear programming. IEEE Transac- tions on Information Theory , 51(12):4203–4215, 2005
work page 2005
-
[11]
Direct convex relaxations of sparse svm
Antoni B Chan, Nuno Vasconcelos, and Gert RG Lanckriet. Direct convex relaxations of sparse svm. In Proceedings of the 24th international conference on Machine learning, pages 145–153, 2007
work page 2007
-
[12]
Maximizing quadratic programs: Extending grothendieck’s inequality
Moses Charikar and Anthony Wirth. Maximizing quadratic programs: Extending grothendieck’s inequality. In 45th Annual IEEE Symposium on Foundations of Computer Science, pages 54–60. IEEE, 2004
work page 2004
-
[13]
Guangjin Chen, Jincheng Dai, Kai Niu, and Chao Dong. Sparsity-inspired sphere decoding (si-sd): A novel blind detection algorithm for uplink grant-free sparse code multiple access. IEEE Access, 5:19983–19993, 2017
work page 2017
-
[14]
Atomic decomposition by basis pursuit
Scott Shaobing Chen, David L Donoho, and Michael A Saunders. Atomic decomposition by basis pursuit. SIAM review, 43(1):129–159, 2001
work page 2001
-
[15]
A review of sparse recovery algorithms
Elaine Crespo Marques, Nilson Maciel, L´ ırida Naviner, Hao Cai, and Jun Yang. A review of sparse recovery algorithms. IEEE Access, 7:1300–1322, 2019
work page 2019
-
[16]
David L Donoho. Compressed sensing. IEEE Transactions on information theory , 52(4):1289–1306, 2006
work page 2006
-
[17]
Optimally sparse representation in general (nonorthog- onal) dictionaries via ℓ1 minimization
David L Donoho and Michael Elad. Optimally sparse representation in general (nonorthog- onal) dictionaries via ℓ1 minimization. Proceedings of the National Academy of Sciences , 100(5):2197–2202, 2003
work page 2003
-
[18]
Hidden integrality of sdp relaxations for sub-gaussian mix- ture models
Yingjie Fei and Yudong Chen. Hidden integrality of sdp relaxations for sub-gaussian mix- ture models. In Conference On Learning Theory, pages 1931–1965. PMLR, 2018
work page 1931
-
[19]
Promp: A sparse recovery approach to lattice-valued signals
Axel Flinth and Gitta Kutyniok. Promp: A sparse recovery approach to lattice-valued signals. Applied and Computational Harmonic Analysis , 45(3):668–708, 2018. 44
work page 2018
-
[20]
Michael R. Garey and David S. Johnson. Computers and Intractability; A Guide to the Theory of NP-Completeness . W. H. Freeman & Co., USA, 1990
work page 1990
-
[21]
The dantzig selector: recovery of signal viaℓ1 -αℓ2 minimization
Huanmin Ge and Peng Li. The dantzig selector: recovery of signal viaℓ1 -αℓ2 minimization. Inverse Problems, 38(1):015006, 2021
work page 2021
-
[22]
Some modified matrix eigenvalue problems
Gene H Golub. Some modified matrix eigenvalue problems. Siam Review, 15(2):318–334, 1973
work page 1973
-
[23]
CVX: Matlab software for disciplined convex program- ming, version 2.1, March 2014
Michael Grant and Stephen Boyd. CVX: Matlab software for disciplined convex program- ming, version 2.1, March 2014
work page 2014
-
[24]
Gurobi Optimizer Reference Manual, 2022
Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2022
work page 2022
-
[25]
Achieving exact cluster recovery threshold via semidefinite programming
Bruce Hajek, Yihong Wu, and Jiaming Xu. Achieving exact cluster recovery threshold via semidefinite programming. IEEE Transactions on Information Theory , 62(5):2788–2797, 2016
work page 2016
-
[26]
Mixon, Jesse Peterson, and Soledad Villar
Takayuki Iguchi, Dustin G. Mixon, Jesse Peterson, and Soledad Villar. On the tightness of an sdp relaxation of k-means, 2015
work page 2015
-
[27]
Compressed sensing for finite-valued signals
Sandra Keiper, Gitta Kutyniok, Dae Gwan Lee, and G¨ otz E Pfander. Compressed sensing for finite-valued signals. Linear Algebra and its Applications , 532:570–613, 2017
work page 2017
-
[28]
Harold W Kuhn and Albert W Tucker. Nonlinear programming. In Traces and emergence of nonlinear programming, pages 247–258. Springer, 2014
work page 2014
-
[29]
Semidefinite programming and integer programming
Monique Laurent and Franz Rendl. Semidefinite programming and integer programming. In K. Aardal, G. Nemhauser, and R. Weismantel, editors,Handbook on Discrete Optimization, pages 393–514. Elsevier B.V., December 2005
work page 2005
-
[30]
Signal recovery under mutual incoherence property and oracle inequalities
Peng Li and Wengu Chen. Signal recovery under mutual incoherence property and oracle inequalities. Frontiers of Mathematics in China , 13(6):1369–1396, 2018
work page 2018
-
[31]
Zang Li and W. Trappe. Collusion-resistant fingerprints from wbe sequence sets. pages 1336 – 1340 Vol. 2, 06 2005
work page 2005
-
[32]
Statistical consistency and asymptotic normality for high-dimensional robust m-estimators
Po-Ling Loh. Statistical consistency and asymptotic normality for high-dimensional robust m-estimators. The Annals of Statistics , 45(2):866–896, 2017
work page 2017
-
[33]
Sup-norm convergence rate and sign concentration property of lasso and dantzig estimators
Karim Lounici. Sup-norm convergence rate and sign concentration property of lasso and dantzig estimators. Electronic Journal of statistics , 2:90–102, 2008
work page 2008
-
[34]
Subset selection in regression
Alan Miller. Subset selection in regression. CRC Press, 2002
work page 2002
-
[35]
Michael Mitzenmacher and Eli Upfal. Probability and computing: Randomization and probabilistic techniques in algorithms and data analysis . Cambridge university press, 2017
work page 2017
-
[36]
Optimal variable selection and adaptive noisy compressed sensing
Mohamed Ndaoud and Alexandre B Tsybakov. Optimal variable selection and adaptive noisy compressed sensing. IEEE Transactions on Information Theory , 66(4):2517–2532, 2020
work page 2020
-
[37]
Richard Obermeier and Jose Angel Martinez-Lorenzo. Sensing matrix design via mu- tual coherence minimization for electromagnetic compressive imaging applications. IEEE Transactions on Computational Imaging , 3(2):217–229, 2017
work page 2017
-
[38]
Simon J. D. Prince. Computer Vision: Models, Learning, and Inference . Cambridge University Press, USA, 1st edition, 2012. 45
work page 2012
-
[39]
Privacy preserving identification using sparse approximation with ambiguization
Behrooz Razeghi, Slava Voloshynovskiy, Dimche Kostadinov, and Olga Taran. Privacy preserving identification using sparse approximation with ambiguization. In 2017 IEEE Workshop on Information Forensics and Security (WIFS) , pages 1–6. IEEE, 2017
work page 2017
-
[40]
The all-or-nothing phenomenon in sparse linear regression
Galen Reeves, Jiaming Xu, and Ilias Zadik. The all-or-nothing phenomenon in sparse linear regression. In Conference on Learning Theory, pages 2652–2663. PMLR, 2019
work page 2019
-
[41]
Multivariate calibration maintenance and transfer through robust fused lasso
M Ross Kunz and Yiyuan She. Multivariate calibration maintenance and transfer through robust fused lasso. Journal of Chemometrics , 27(9):233–242, 2013
work page 2013
-
[42]
Multiuser detection based on map estimation with sum-of-absolute-values relaxation
Hampei Sasahara, Kazunori Hayashi, and Masaaki Nagahara. Multiuser detection based on map estimation with sum-of-absolute-values relaxation. IEEE Transactions on Signal Processing, 65(21):5621–5634, 2017
work page 2017
-
[43]
Efficient recovery algorithm for discrete valued sparse signals using an admm approach
Nuno MB Souto and Hugo Andr´ e Lopes. Efficient recovery algorithm for discrete valued sparse signals using an admm approach. IEEE Access, 5:19562–19569, 2017
work page 2017
-
[44]
Adapting compressed sensing algorithms to dis- crete sparse signals
Susanne Sparrer and Robert FH Fischer. Adapting compressed sensing algorithms to dis- crete sparse signals. In WSA 2014; 18th International ITG Workshop on Smart Antennas , pages 1–8. VDE, 2014
work page 2014
-
[45]
Soft-feedback omp for the recovery of discrete- valued sparse signals
Susanne Sparrer and Robert FH Fischer. Soft-feedback omp for the recovery of discrete- valued sparse signals. In 2015 23rd European Signal Processing Conference (EUSIPCO) , pages 1461–1465. IEEE, 2015
work page 2015
-
[46]
Chapter 9 - sparsity-aware learning: Concepts and theoretical foun- dations
Sergios Theodoridis. Chapter 9 - sparsity-aware learning: Concepts and theoretical foun- dations. In Sergios Theodoridis, editor, Machine Learning, pages 403–448. Academic Press, Oxford, 2015
work page 2015
-
[47]
Lieven Vandenberghe and Stephen Boyd. Semidefinite programming. SIAM review , 38(1):49–95, 1996
work page 1996
-
[48]
Roman Vershynin. How close is the sample covariance matrix to the actual covariance matrix? Journal of Theoretical Probability, 25, 04 2010
work page 2010
-
[49]
High-dimensional probability: An introduction with applications in data science, volume 47
Roman Vershynin. High-dimensional probability: An introduction with applications in data science, volume 47. Cambridge university press, 2018
work page 2018
-
[50]
Martin J Wainwright. Sharp thresholds for high-dimensional and noisy sparsity recovery using ℓ1 -constrained quadratic programming (lasso). IEEE Transactions on Information Theory, 55(5):2183–2202, 2009
work page 2009
-
[51]
Robust face recognition via sparse representation
John Wright, Allen Y Yang, Arvind Ganesh, S Shankar Sastry, and Yi Ma. Robust face recognition via sparse representation. IEEE transactions on pattern analysis and machine intelligence, 31(2):210–227, 2008
work page 2008
-
[52]
A novel illumination-robust local descriptor based on sparse linear regres- sion
Zuodong Yang, Yong Wu, Wenteng Zhao, Yicong Zhou, Zongqing Lu, Weifeng Li, and Qingmin Liao. A novel illumination-robust local descriptor based on sparse linear regres- sion. Digital Signal Processing, 48:269–275, 2016
work page 2016
-
[53]
Tarik Yardibi, Jian Li, Peter Stoica, and Louis N. Cattafesta III. Sparse representations and sphere decoding for array signal processing. Digital Signal Processing, 22(2):253–262, 2012
work page 2012
-
[54]
Adaptive forward-backward greedy algorithm for learning sparse representa- tions
Tong Zhang. Adaptive forward-backward greedy algorithm for learning sparse representa- tions. IEEE transactions on information theory , 57(7):4689–4708, 2011. 46
work page 2011
-
[55]
On model selection consistency of lasso
Peng Zhao and Bin Yu. On model selection consistency of lasso. The Journal of Machine Learning Research, 7:2541–2563, 2006
work page 2006
-
[56]
A Theoretical Analysis of Sparse Recovery Stability of Dantzig Selector and LASSO
Yun-Bin Zhao and Duan Li. A theoretical analysis of sparse recovery stability of dantzig selector and lasso. arXiv preprint arXiv:1711.03783 , 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
- [57]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.