Explaining the Explainers in Graph Neural Networks: a Comparative Study
Pith reviewed 2026-05-24 10:58 UTC · model grok-4.3
The pith
Systematic tests of ten explainers on eight GNN architectures and six datasets isolate the design choices that produce reliable interpretations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors establish through direct experiment that explainer success depends primarily on specific implementation details such as the treatment of graph structure and the selection of reference baselines rather than on the explainer's broad category, and they extract practical rules for avoiding pitfalls including metric instability and mismatch between explainer assumptions and dataset properties.
What carries the argument
The comparative experimental protocol that holds architectures and datasets fixed while varying explainers to isolate which components drive faithful explanations.
If this is right
- Explainers incorporating explicit graph-structure handling outperform generic adaptations in most tested node and graph classification settings.
- Recommendations allow selection of an explainer according to whether the task is node classification or whole-graph classification.
- Avoiding single-metric reliance and checking stability across similar inputs reduces the chance of accepting spurious explanations.
- The study leaves open the question of how these component-level insights scale to larger graphs and additional architectures.
Where Pith is reading between the lines
- The component-focused findings suggest that GNN training procedures could be modified to optimize directly for the identified successful explainer traits.
- Extending the same protocol to attention-based or message-passing variants not included in the original eight architectures would test whether the same components remain decisive.
- Domain scientists applying GNNs to chemistry or biology graphs may require additional validation steps before adopting the general selection rules.
Load-bearing premise
The ten chosen explainers, eight architectures, and six datasets are representative enough to support general recommendations about GNN explainability.
What would settle it
A new explainer or architecture outside the tested collection that produces explanations rated highly by the paper's metrics yet fails to align with model behavior on an additional dataset would falsify the generality of the derived recommendations.
Figures








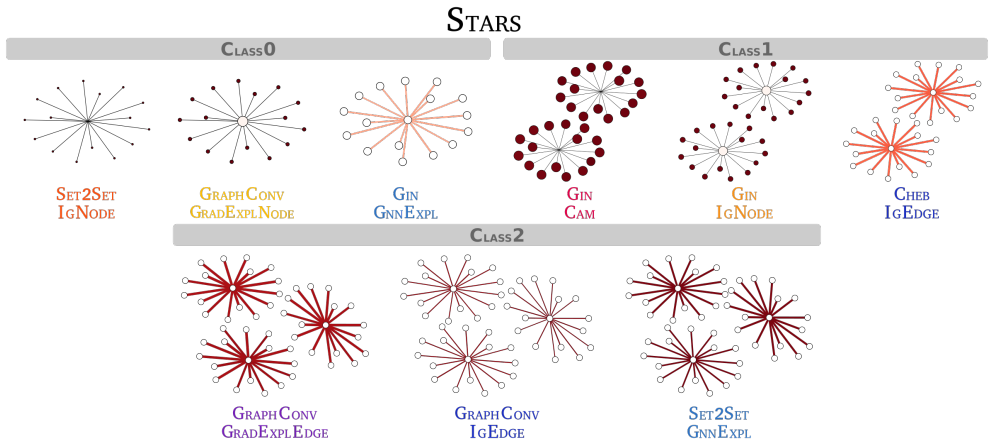















read the original abstract
Following a fast initial breakthrough in graph based learning, Graph Neural Networks (GNNs) have reached a widespread application in many science and engineering fields, prompting the need for methods to understand their decision process. GNN explainers have started to emerge in recent years, with a multitude of methods both novel or adapted from other domains. To sort out this plethora of alternative approaches, several studies have benchmarked the performance of different explainers in terms of various explainability metrics. However, these earlier works make no attempts at providing insights into why different GNN architectures are more or less explainable, or which explainer should be preferred in a given setting. In this survey, we fill these gaps by devising a systematic experimental study, which tests ten explainers on eight representative architectures trained on six carefully designed graph and node classification datasets. With our results we provide key insights on the choice and applicability of GNN explainers, we isolate key components that make them usable and successful and provide recommendations on how to avoid common interpretation pitfalls. We conclude by highlighting open questions and directions of possible future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a systematic experimental benchmark of ten GNN explainers applied to eight GNN architectures across six graph and node classification datasets. It claims to isolate key components that determine explainer success, supply actionable recommendations for explainer choice, and highlight open questions in GNN explainability.
Significance. If the chosen experimental grid is representative, the work supplies a useful empirical map that goes beyond prior benchmarks by linking architectural properties to explainability outcomes and offering concrete guidance for practitioners. The systematic design and emphasis on isolating usable components are strengths.
major comments (2)
- [Section 3] Experimental setup (Section 3): the claim that the six datasets and eight architectures are 'representative' and 'carefully designed' to support general recommendations requires an explicit mapping showing coverage of homophily/heterophily, graph size, and feature-versus-structure signal regimes; without this mapping the isolated key components and resulting recommendations remain tied to the tested slice.
- [Results section (Tables 2-5)] Results section (Tables 2-5 and associated figures): performance differences used to derive recommendations are presented without reported standard deviations across random seeds or statistical significance tests, making it impossible to judge whether observed differences in explainer fidelity or stability are robust.
minor comments (2)
- [Abstract] Abstract: the summary of contributions mentions 'key insights' and 'recommendations' but does not preview any concrete quantitative outcomes or named pitfalls.
- [Section 2] Notation: the definitions of the explainability metrics (fidelity, stability, etc.) appear only after the experimental setup; moving a compact table of metric definitions to Section 2 would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help strengthen the clarity of our experimental design and the robustness of our results. We address each major comment point by point below, indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [Section 3] Experimental setup (Section 3): the claim that the six datasets and eight architectures are 'representative' and 'carefully designed' to support general recommendations requires an explicit mapping showing coverage of homophily/heterophily, graph size, and feature-versus-structure signal regimes; without this mapping the isolated key components and resulting recommendations remain tied to the tested slice.
Authors: We agree that an explicit mapping would better substantiate our claims of representativeness. Although the datasets and architectures were selected to span a range of homophily levels, sizes, and signal regimes (as described in the original Section 3), we did not include a consolidated table. In the revision we will add a new table (or subsection) in Section 3 that explicitly maps each of the six datasets and eight architectures to homophily/heterophily, graph size categories, and feature-versus-structure dominance, thereby clarifying the coverage and supporting the general recommendations. revision: yes
-
Referee: [Results section (Tables 2-5)] Results section (Tables 2-5 and associated figures): performance differences used to derive recommendations are presented without reported standard deviations across random seeds or statistical significance tests, making it impossible to judge whether observed differences in explainer fidelity or stability are robust.
Authors: We concur that standard deviations and statistical tests are necessary to establish robustness. The current tables report mean performance only. In the revised manuscript we will rerun the experiments with multiple random seeds, add standard deviations to Tables 2-5 (and associated figures), and include appropriate statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values) for the key explainer comparisons used to derive recommendations. revision: yes
Circularity Check
Empirical benchmark study with no derivation chain
full rationale
The paper performs a systematic experimental comparison of ten GNN explainers across eight architectures and six datasets, reporting performance metrics and deriving recommendations directly from those results. No mathematical derivations, parameter fittings, predictions, or uniqueness theorems are present that could reduce to inputs by construction. Self-citations (if any) are used only for background on prior benchmarks and do not bear the load of the central claims. The work is self-contained as an empirical study whose findings are externally falsifiable via replication on the same or additional datasets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected datasets and architectures capture the relevant variation in GNN explainability behavior.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we fill these gaps by devising a systematic experimental study, which tests ten explainers on eight representative architectures trained on six carefully designed graph and node classification datasets
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
GNNExplainer (Perturbation) [117]: ... PgExpl ... SubX ... RgExpl (Generation)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
xAI-Drop: Don't Use What You Cannot Explain
xAI-Drop introduces an explainability-based topological dropping regularizer for GNNs that outperforms state-of-the-art dropping methods in accuracy and explanation quality on real-world datasets.
Reference graph
Works this paper leans on
-
[1]
Evaluating explainability for graph neural networks
Chirag Agarwal, Owen Queen, Himabindu Lakkaraju, and Marinka Zitnik. Evaluating explainability for graph neural networks. arXiv preprint arXiv:2208.09339, 2022
-
[2]
Probing gnn explainers: A rigorous theoretical and empirical analysis of gnn explanation methods
Chirag Agarwal, Marinka Zitnik, and Himabindu Lakkaraju. Probing gnn explainers: A rigorous theoretical and empirical analysis of gnn explanation methods. In International Conference on Artificial Intelligence and Statistics, pages 8969–8996. PMLR, 2022
work page 2022
-
[3]
A two-stage gan for high-resolution retinal image generation and segmentation
Paolo Andreini, Giorgio Ciano, Simone Bonechi, Caterina Graziani, Veronica Lachi, Alessandro Mecocci, Andrea Sodi, Franco Scarselli, and Monica Bianchini. A two-stage gan for high-resolution retinal image generation and segmentation. Electronics, 11(1):60, 2021
work page 2021
-
[4]
Diffusion-convolutional neural networks
James Atwood and Don Towsley. Diffusion-convolutional neural networks. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, vol- ume 29. Curran Associates, Inc., 2016
work page 2016
-
[5]
Global explainability of gnns via logic combination of learned concepts
Steve Azzolin, Antonio Longa, Pietro Barbiero, Pietro Lio, and Andrea Passerini. Global explainability of gnns via logic combination of learned concepts. In The Eleventh International Conference on Learning Representations, 2022
work page 2022
-
[6]
David Baehrens, Timon Schroeter, Stefan Harmeling, Motoaki Kawanabe, Katja Hansen, and Klaus-Robert M¨ uller. How to explain individual classification decisions.The Journal of Machine Learning Research, 11:1803– 1831, 2010
work page 2010
-
[7]
Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[8]
Explainability Techniques for Graph Convolutional Networks
Federico Baldassarre and Hossein Azizpour. Explainability techniques for graph convolutional networks.arXiv preprint arXiv:1905.13686, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[9]
Emergence of scaling in random networks.science, 286(5439):509– 512, 1999
Albert-L´ aszl´ o Barab´ asi and R´ eka Albert. Emergence of scaling in random networks.science, 286(5439):509– 512, 1999
work page 1999
-
[10]
Equivariant mesh attention networks
Sourya Basu, Jose Gallego-Posada, Francesco Vigan` o, James Rowbottom, and Taco Cohen. Equivariant mesh attention networks. arXiv preprint arXiv:2205.10662, 2022
-
[11]
Spectral clustering with graph neural networks for graph pooling
Filippo Maria Bianchi, Daniele Grattarola, and Cesare Alippi. Spectral clustering with graph neural networks for graph pooling. In International Conference on Machine Learning, pages 874–883. PMLR, 2020
work page 2020
-
[12]
Protein function prediction via graph kernels
Karsten M Borgwardt, Cheng Soon Ong, Stefan Sch¨ onauer, SVN Vishwanathan, Alex J Smola, and Hans- Peter Kriegel. Protein function prediction via graph kernels. Bioinformatics, 21(suppl 1):i47–i56, 2005
work page 2005
-
[13]
Towards Sparse Hierarchical Graph Classifiers
C˘ at˘ alina Cangea, Petar Veliˇ ckovi´ c, Nikola Jovanovi´ c, Thomas Kipf, and Pietro Li` o. Towards sparse hierar- chical graph classifiers. arXiv preprint arXiv:1811.01287, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[14]
Khalil, Andrea Lodi, Christopher Morris, and Petar Veliˇ ckovi´ c
Quentin Cappart, Didier Ch´ etelat, Elias B. Khalil, Andrea Lodi, Christopher Morris, and Petar Veliˇ ckovi´ c. Combinatorial optimization and reasoning with graph neural networks. In Zhi-Hua Zhou, editor, Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 4348–4355. Inter- national Joint Conferences on...
work page 2021
-
[15]
How faithful are self- explainable gnns? In The Second Learning on Graphs Conference, 2023
Marc Christiansen, Lea Villadsen, Zhiqiang Zhong, Stefano Teso, and Davide Mottin. How faithful are self- explainable gnns? In The Second Learning on Graphs Conference, 2023
work page 2023
-
[16]
High-Performance Neural Networks for Visual Object Classification
Dan C Cire¸ san, Ueli Meier, Jonathan Masci, Luca M Gambardella, and J¨ urgen Schmidhuber. High- performance neural networks for visual object classification. arXiv preprint arXiv:1102.0183, 2011. 31
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[17]
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[18]
Enyan Dai, Tianxiang Zhao, Huaisheng Zhu, Jun Xu, Zhimeng Guo, Hui Liu, Jiliang Tang, and Suhang Wang. A comprehensive survey on trustworthy graph neural networks: Privacy, robustness, fairness, and explainability. ArXiv, abs/2204.08570, 2022
-
[19]
Convolutional neural networks on graphs with fast localized spectral filtering
Micha¨ el Defferrard, Xavier Bresson, and Pierre Vandergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. Advances in neural information processing systems, 29, 2016
work page 2016
-
[20]
Eraser: A benchmark to evaluate rationalized nlp models
Jay DeYoung, Sarthak Jain, Nazneen Fatema Rajani, Eric Lehman, Caiming Xiong, Richard Socher, and Byron C Wallace. Eraser: A benchmark to evaluate rationalized nlp models. arXiv preprint arXiv:1911.03429, 2019
-
[21]
Higher-order clustering and pooling for graph neural networks
Alexandre Duval and Fragkiskos Malliaros. Higher-order clustering and pooling for graph neural networks. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, pages 426–435, 2022
work page 2022
-
[22]
A generalization of transformer networks to graphs
Vijay Prakash Dwivedi and Xavier Bresson. A generalization of transformer networks to graphs. arXiv preprint arXiv:2012.09699, 2020
-
[23]
On random graphs i.Publicationes mathematicae, 6(1):290–297, 1959
Paul Erd˝ os and Alfr´ ed R´ enyi. On random graphs i.Publicationes mathematicae, 6(1):290–297, 1959
work page 1959
-
[24]
Moghaddam, and Roger Wattenhofer
Lukas Faber, Amin K. Moghaddam, and Roger Wattenhofer. When comparing to ground truth is wrong: On evaluating gnn explanation methods. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 332–341, 2021
work page 2021
-
[25]
Simulate time-integrated coarse-grained molecular dynamics with geometric machine learning
Xiang Fu, Tian Xie, Nathan J Rebello, Bradley D Olsen, and Tommi Jaakkola. Simulate time-integrated coarse-grained molecular dynamics with geometric machine learning. arXiv preprint arXiv:2204.10348, 2022
-
[26]
Hard masking for explaining Graph Neural Networks, 2021
Thorben Funke, Megha Khosla, and Avishek Anand. Hard masking for explaining Graph Neural Networks, 2021
work page 2021
-
[27]
Z orro: Valid, sparse, and stable explanations in graph neural networks
Thorben Funke, Megha Khosla, Mandeep Rathee, and Avishek Anand. Z orro: Valid, sparse, and stable explanations in graph neural networks. IEEE Transactions on Knowledge and Data Engineering, 2022
work page 2022
-
[28]
Jianliang Gao, Jun Gao, Xiaoting Ying, Mingming Lu, and Jianxin Wang. Higher-order interaction goes neural: a substructure assembling graph attention network for graph classification. IEEE Transactions on Knowledge and Data Engineering, 2021
work page 2021
-
[29]
Diffusion improves graph learning, 2022
Johannes Gasteiger, Stefan Weißenberger, and Stephan G¨ unnemann. Diffusion improves graph learning, 2022
work page 2022
-
[30]
Neural bipartite matching, 2020
Dobrik Georgiev and Pietro Li` o. Neural bipartite matching, 2020
work page 2020
-
[31]
Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning - Volume 70, page 1263–1272, 2017
work page 2017
-
[32]
Neural message passing for quantum chemistry
Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In International conference on machine learning, pages 1263–1272. PMLR, 2017
work page 2017
-
[33]
Towards training gnns using explanation directed message passing
Valentina Giunchiglia, Chirag Varun Shukla, Guadalupe Gonzalez, and Chirag Agarwal. Towards training gnns using explanation directed message passing. In Learning on Graphs Conference, pages 28–1. PMLR, 2022
work page 2022
-
[34]
node2vec: Scalable feature learning for networks
Aditya Grover and Jure Leskovec. node2vec: Scalable feature learning for networks. In Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, pages 855–864, 2016
work page 2016
-
[35]
A survey of methods for explaining black box models
Riccardo Guidotti, Anna Monreale, Salvatore Ruggieri, Franco Turini, Fosca Giannotti, and Dino Pedreschi. A survey of methods for explaining black box models. ACM computing surveys (CSUR), 51(5):1–42, 2018
work page 2018
-
[36]
Inductive representation learning on large graphs
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs. Advances in neural information processing systems, 30, 2017. 32
work page 2017
-
[37]
Wavelets on graphs via spectral graph theory
David K Hammond, Pierre Vandergheynst, and R´ emi Gribonval. Wavelets on graphs via spectral graph theory. Applied and Computational Harmonic Analysis, 30(2):129–150, 2011
work page 2011
-
[38]
Neural Networks, pages 389–416
Trevor Hastie, Robert Tibshirani, and Jerome Friedman. Neural Networks, pages 389–416. Springer New York, New York, NY, 2009
work page 2009
-
[39]
Convolution kernels on discrete structures
David Haussler et al. Convolution kernels on discrete structures. Technical report, Technical report, Depart- ment of Computer Science, University of California . . . , 1999
work page 1999
-
[40]
Sepp Hochreiter and J¨ urgen Schmidhuber. Long short-term memory. Neural Comput., 9(8):1735–1780, nov 1997
work page 1997
-
[41]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020
work page 2020
-
[42]
Graphlime: Local interpretable model explanations for graph neural networks
Qiang Huang, Makoto Yamada, Yuan Tian, Dinesh Singh, and Yi Chang. Graphlime: Local interpretable model explanations for graph neural networks. IEEE Transactions on Knowledge and Data Engineering, 2022
work page 2022
-
[43]
Learning equivariant energy based models with equivariant stein variational gradient descent
Priyank Jaini, Lars Holdijk, and Max Welling. Learning equivariant energy based models with equivariant stein variational gradient descent. Advances in Neural Information Processing Systems, 34:16727–16737, 2021
work page 2021
-
[44]
Information retrieval test collections
K Sparck Jones and Cornelis Joost Van Rijsbergen. Information retrieval test collections. Journal of documentation, 1976
work page 1976
-
[45]
A survey on explain- ability of graph neural networks
Jaykumar Kakkad, Jaspal Jannu, Kartik Sharma, Charu Aggarwal, and Sourav Medya. A survey on explain- ability of graph neural networks. arXiv preprint arXiv:2306.01958, 2023
-
[46]
Moldata, a molecular bench- mark for disease and target based machine learning
Arash Keshavarzi Arshadi, Milad Salem, Arash Firouzbakht, and Jiann Yuan. Moldata, a molecular bench- mark for disease and target based machine learning. Journal of Cheminformatics, 14, 03 2022
work page 2022
-
[47]
Privacy and transparency in graph machine learning: A unified perspective
Megha Khosla. Privacy and transparency in graph machine learning: A unified perspective. arXiv preprint arXiv:2207.10896, 2022
-
[48]
Pure transformers are powerful graph learners
Jinwoo Kim, Tien Dat Nguyen, Seonwoo Min, Sungjun Cho, Moontae Lee, Honglak Lee, and Seunghoon Hong. Pure transformers are powerful graph learners. arXiv preprint arXiv:2207.02505, 2022
-
[49]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[50]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6):84–90, 2017
work page 2017
-
[51]
Contributions to the Theory of Games (AM-28), Volume II
Harold William Kuhn and Albert William Tucker, editors. Contributions to the Theory of Games (AM-28), Volume II. Princeton University Press, Princeton, 1953
work page 1953
-
[52]
Junhyun Lee, Inyeop Lee, and Jaewoo Kang. Self-attention graph pooling. In International conference on machine learning, pages 3734–3743. PMLR, 2019
work page 2019
-
[53]
Improving semantic dependency parsing with higher-order information encoded by graph neural networks
Bin Li, Yunlong Fan, Yikemaiti Sataer, Zhiqiang Gao, and Yaocheng Gui. Improving semantic dependency parsing with higher-order information encoded by graph neural networks. Applied Sciences, 12(8):4089, 2022
work page 2022
-
[54]
Higher-order attribute-enhancing heterogeneous graph neural networks
Jianxin Li, Hao Peng, Yuwei Cao, Yingtong Dou, Hekai Zhang, Philip Yu, and Lifang He. Higher-order attribute-enhancing heterogeneous graph neural networks. IEEE Transactions on Knowledge and Data Engineering, 2021
work page 2021
-
[55]
Explainability in graph neural networks: An experimental survey
Peibo Li, Yixing Yang, Maurice Pagnucco, and Yang Song. Explainability in graph neural networks: An experimental survey. arXiv preprint arXiv:2203.09258, 2022
-
[56]
Rethinking graph neural networks for the graph coloring problem, 2022
Wei Li, Ruxuan Li, Yuzhe Ma, Siu On Chan, David Pan, and Bei Yu. Rethinking graph neural networks for the graph coloring problem, 2022
work page 2022
-
[57]
Dag matters! gflownets enhanced explainer for graph neural networks, 2023
Wenqian Li, Yinchuan Li, Zhigang Li, Jianye Hao, and Yan Pang. Dag matters! gflownets enhanced explainer for graph neural networks, 2023. 33
work page 2023
-
[58]
A survey of explainable graph neural networks: Taxonomy and evaluation metrics
Yiqiao Li, Jianlong Zhou, Sunny Verma, and Fang Chen. A survey of explainable graph neural networks: Taxonomy and evaluation metrics. arXiv preprint arXiv:2207.12599, 2022
-
[59]
Generative causal explanations for graph neural networks
Wanyu Lin, Hao Lan, and Baochun Li. Generative causal explanations for graph neural networks. In International Conference on Machine Learning, pages 6666–6679. PMLR, 2021
work page 2021
-
[60]
Orphicx: A causality-inspired latent variable model for interpreting graph neural networks
Wanyu Lin, Hao Lan, Hao Wang, and Baochun Li. Orphicx: A causality-inspired latent variable model for interpreting graph neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13729–13738, 2022
work page 2022
-
[61]
A survey of visual transformers
Yang Liu, Yao Zhang, Yixin Wang, Feng Hou, Jin Yuan, Jiang Tian, Yang Zhang, Zhongchao Shi, Jianping Fan, and Zhiqiang He. A survey of visual transformers. arXiv preprint arXiv:2111.06091, 2021
-
[62]
Graph neural networks for temporal graphs: State of the art, open challenges, and opportunities
Antonio Longa, Veronica Lachi, Gabriele Santin, Monica Bianchini, Bruno Lepri, Pietro Lio, franco scarselli, and Andrea Passerini. Graph neural networks for temporal graphs: State of the art, open challenges, and opportunities. Transactions on Machine Learning Research, 2023
work page 2023
-
[63]
Ter Hoeve, Gabriele Tolomei, Maarten De Rijke, and Fabrizio Silvestri
Ana Lucic, Maartje A. Ter Hoeve, Gabriele Tolomei, Maarten De Rijke, and Fabrizio Silvestri. Cf- gnnexplainer: Counterfactual explanations for graph neural networks. In Gustau Camps-Valls, Francisco J. R. Ruiz, and Isabel Valera, editors, Proceedings of The 25th International Conference on Artificial Intelligence and Statistics, volume 151 of Proceedings ...
work page 2022
-
[64]
Param- eterized explainer for graph neural network
Dongsheng Luo, Wei Cheng, Dongkuan Xu, Wenchao Yu, Bo Zong, Haifeng Chen, and Xiang Zhang. Param- eterized explainer for graph neural network. Advances in neural information processing systems, 33:19620– 19631, 2020
work page 2020
-
[65]
On data-aware global explainability of graph neural networks
Ge Lv and Lei Chen. On data-aware global explainability of graph neural networks. Proc. VLDB Endow., 16(11):3447–3460, aug 2023
work page 2023
-
[66]
On glocal explainability of graph neural networks
Ge Lv, Lei Chen, and Caleb Chen Cao. On glocal explainability of graph neural networks. In Database Systems for Advanced Applications: 27th International Conference, DASFAA 2022, Virtual Event, April 11–14, 2022, Proceedings, Part I, page 648–664, Berlin, Heidelberg, 2022. Springer-Verlag
work page 2022
-
[67]
Encoding concepts in graph neural networks
Lucie Charlotte Magister, Pietro Barbiero, Dmitry Kazhdan, Federico Siciliano, Gabriele Ciravegna, Fabrizio Silvestri, Mateja Jamnik, and Pietro Lio. Encoding concepts in graph neural networks. arXiv preprint arXiv:2207.13586, 2022
-
[68]
Gcexplainer: Human-in-the-loop concept-based explanations for graph neural networks, 2021
Lucie Charlotte Magister, Dmitry Kazhdan, Vikash Singh, and Pietro Li` o. Gcexplainer: Human-in-the-loop concept-based explanations for graph neural networks, 2021
work page 2021
-
[69]
Interpretable and generalizable graph learning via stochastic attention mechanism
Siqi Miao, Mia Liu, and Pan Li. Interpretable and generalizable graph learning via stochastic attention mechanism. In International Conference on Machine Learning, pages 15524–15543. PMLR, 2022
work page 2022
-
[70]
Discrete-time dynamic graph echo state networks
Alessio Micheli and Domenico Tortorella. Discrete-time dynamic graph echo state networks. Neurocomputing, 496:85–95, 2022
work page 2022
-
[71]
Weisfeiler and leman go neural: Higher-order graph neural networks
Christopher Morris, Martin Ritzert, Matthias Fey, William L Hamilton, Jan Eric Lenssen, Gaurav Rattan, and Martin Grohe. Weisfeiler and leman go neural: Higher-order graph neural networks. In Proceedings of the AAAI conference on artificial intelligence, volume 33, pages 4602–4609, 2019
work page 2019
-
[72]
Graphchef: Decision-tree recipes to explain graph neural networks
Peter M¨ uller, Lukas Faber, Karolis Martinkus, and Roger Wattenhofer. Graphchef: Decision-tree recipes to explain graph neural networks. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[73]
Globally interpretable graph learning via distribution matching
Yi Nian, Yurui Chang, Wei Jin, and Lu Lin. Globally interpretable graph learning via distribution matching. In Proceedings of the ACM on Web Conference 2024, pages 992–1002, 2024
work page 2024
-
[74]
Review of tools and algorithms for network motif discovery in biological networks
Sabyasachi Patra and Anjali Mohapatra. Review of tools and algorithms for network motif discovery in biological networks. IET systems biology, 14(4):171–189, 2020
work page 2020
-
[75]
Explainability methods for graph convolutional neural networks
Phillip E Pope, Soheil Kolouri, Mohammad Rostami, Charles E Martin, and Heiko Hoffmann. Explainability methods for graph convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10772–10781, 2019. 34
work page 2019
-
[76]
Marcelo Prates, Pedro H. C. Avelar, Henrique Lemos, Luis C. Lamb, and Moshe Y. Vardi. Learning to solve np-complete problems: A graph neural network for decision tsp. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence and Thirty-First Innovative Applications of Artificial Intelligence Conference and Ninth AAAI Symposium on Educa...
work page 2019
-
[77]
Frame averaging for invariant and equivariant network design
Omri Puny, Matan Atzmon, Heli Ben-Hamu, Edward J Smith, Ishan Misra, Aditya Grover, and Yaron Lipman. Frame averaging for invariant and equivariant network design. arXiv preprint arXiv:2110.03336, 2021
-
[78]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140):1–67, 2020
work page 2020
-
[79]
Prototype-based interpretable graph neural net- works
Alessio Ragno, Biagio La Rosa, and Roberto Capobianco. Prototype-based interpretable graph neural net- works. IEEE Transactions on Artificial Intelligence, 5(4):1486–1495, 2022
work page 2022
-
[80]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.