Competitive plasticity to reduce the energetic costs of learning
Pith reviewed 2026-05-24 09:12 UTC · model grok-4.3
The pith
Two rules that restrict which synapses change cut most of the energy cost of learning while adding only a small amount of extra time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
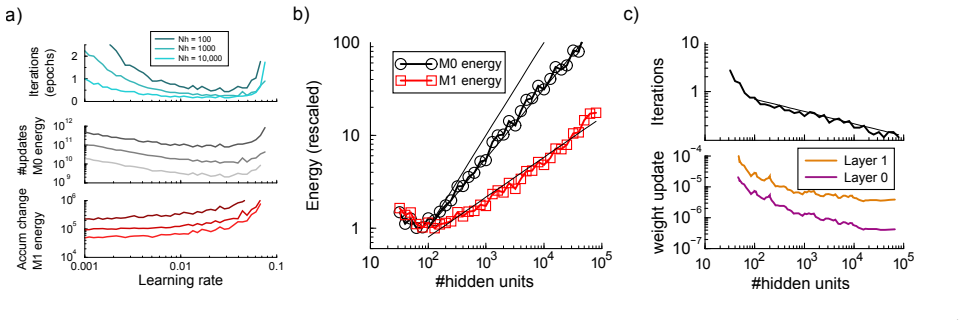
By competitively restricting plasticity—updating only synapses with large weight changes and limiting changes to path-forming subsets of synapses—learning proceeds with far fewer total synaptic modifications, yielding large energy savings at the cost of only a small increase in learning time, with the biggest gains appearing when the network is oversized relative to the task.
What carries the argument
Competitive plasticity restriction: thresholded large-update rule plus path-restricted synapse subsets.
If this is right
- Substantial reduction in the total number of synaptic updates required to reach target accuracy.
- Only a modest increase in the number of training epochs needed.
- Even larger energy savings when the network contains more synapses than the task strictly requires.
- Potential alignment of artificial learning dynamics with observed biological plasticity patterns.
- Direct applicability to hardware where memory writes are energetically expensive.
Where Pith is reading between the lines
- The same restrictions might explain why biological circuits often keep large numbers of unused synapses rather than pruning them.
- The rules could be tested for compatibility with online or continual learning settings where tasks arrive sequentially.
- Hardware accelerators that already gate memory access might adopt the large-update threshold as a simple control signal.
- The path-restriction idea suggests a possible link between sparse connectivity and energy-efficient learning that could be checked in recurrent architectures.
Load-bearing premise
Counting each synaptic update as carrying the same fixed energy cost accurately reflects the true metabolic expense of plasticity.
What would settle it
Measure the actual number of synaptic modifications and the corresponding energy use while training a network on a standard task, once with unrestricted updates and once with the two restrictions applied, and check whether the measured savings match the model's prediction.
Figures





read the original abstract
The brain is not only constrained by energy needed to fuel computation, but it is also constrained by energy needed to form memories. Experiments have shown that learning simple conditioning tasks already carries a significant metabolic cost. Yet, learning a task like MNIST to 95% accuracy appears to require at least 10^{8} synaptic updates. Therefore the brain has likely evolved to be able to learn using as little energy as possible. We explored the energy required for learning in feedforward neural networks. Based on a parsimonious energy model, we propose two plasticity restricting algorithms that save energy: 1) only modify synapses with large updates, and 2) restrict plasticity to subsets of synapses that form a path through the network. Combining these two methods leads to substantial energy savings while only incurring a small increase in learning time. In biology networks are often much larger than the task requires. In particular in that case, large savings can be achieved. Thus competitively restricting plasticity helps to save metabolic energy associated to synaptic plasticity. The results might lead to a better understanding of biological plasticity and a better match between artificial and biological learning. Moreover, the algorithms might also benefit hardware because in electronics memory storage is energetically costly as well.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes two algorithms to restrict plasticity in feedforward neural networks: (1) updating only synapses whose changes exceed a magnitude threshold and (2) limiting updates to subsets of synapses that form a path through the network. Using a parsimonious energy model that counts only the number of synaptic updates performed, the authors claim that the combination yields substantial energy savings at the cost of only a small increase in learning time, with larger relative savings in networks that are oversized relative to the task; implications are drawn for biological metabolic efficiency and hardware memory costs.
Significance. If the claimed savings survive a more complete accounting of selection overhead, the work supplies a concrete, competitive mechanism that could link observed metabolic costs of conditioning to network-level plasticity rules and could inform low-energy hardware implementations. The approach directly engages the 10^8-update estimate for MNIST-level tasks and the biological constraint on memory-formation energy.
major comments (2)
- [Energy Model] Energy Model section: the parsimonious model tallies only the final synaptic updates. Both algorithms, however, require an explicit selection step (threshold comparison for large updates; path identification for the second rule) whose arithmetic, memory accesses, and routing scale with network width and depth; these costs are omitted from the reported savings and could erase the net reduction in the biological and hardware regimes invoked in the abstract.
- [Results] Results (quantitative claims): the abstract asserts 'substantial energy savings' and 'small increase in learning time' without reporting the precise ratios, network sizes, or baseline comparisons that would allow the reader to judge whether the savings remain load-bearing once selection overhead is restored; the central claim therefore rests on an unverified quantitative margin.
minor comments (1)
- [Abstract] Abstract: the figure 10^8 for MNIST updates should be accompanied by a brief derivation or citation in the main text so that the energy baseline is reproducible.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Energy Model] Energy Model section: the parsimonious model tallies only the final synaptic updates. Both algorithms, however, require an explicit selection step (threshold comparison for large updates; path identification for the second rule) whose arithmetic, memory accesses, and routing scale with network width and depth; these costs are omitted from the reported savings and could erase the net reduction in the biological and hardware regimes invoked in the abstract.
Authors: Our energy model is explicitly parsimonious, focusing on the number of synaptic updates as the primary cost, in line with estimates of memory-formation energy in the literature. The selection steps are part of the algorithm but their computational cost is not the focus of this study. We will revise the manuscript to include a brief discussion acknowledging the potential overhead of selection and noting that in many implementations these operations can be performed efficiently in parallel or with low energy cost. We maintain that the savings in update energy are the key contribution. revision: partial
-
Referee: [Results] Results (quantitative claims): the abstract asserts 'substantial energy savings' and 'small increase in learning time' without reporting the precise ratios, network sizes, or baseline comparisons that would allow the reader to judge whether the savings remain load-bearing once selection overhead is restored; the central claim therefore rests on an unverified quantitative margin.
Authors: While the abstract uses qualitative descriptors, the main text and figures provide quantitative results for specific network architectures and tasks, including comparisons to standard backpropagation. To improve clarity, we will update the abstract to report the key quantitative findings, such as the energy savings ratios for different network sizes. revision: yes
Circularity Check
No significant circularity; savings follow from explicit update-counting in proposed algorithms
full rationale
The paper introduces two explicit algorithms (large-update restriction and path-restricted plasticity) and evaluates energy via a stated parsimonious counting model. No equations reduce predictions to fitted inputs by construction, no self-citations serve as load-bearing uniqueness theorems, and no ansatz or renaming is smuggled in. The central claim rests on the model's assumptions and simulation outcomes rather than definitional equivalence, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- update magnitude threshold
axioms (1)
- domain assumption Metabolic cost of learning is proportional to the number of synaptic weight updates performed.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a generic model for the metabolic energy M of synaptic plasticity ... M_α = ∑_{i,t} |δw_i(t)|^α ... we concentrate on M0 and M1.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
only modify synapses with large updates, and 2) restrict plasticity to subsets of synapses that form a path through the network
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
W. C. Abraham, B. Logan, J. M. Greenwood, and M. Dragunow. I nduction and E xperience- D ependent C onsolidation of S table L ong- T erm P otentiation L asting M onths in the H ippocampus. J Neurosci, 22: 0 9626--9634, 2002
work page 2002
-
[2]
D. Attwell and S. B. Laughlin. An Energy Budget for Signaling in the Grey Matter of the Brain . J. of Cerebral Blood Flow & Metabolism , 21 0 (10): 0 1133--1145, 2001
work page 2001
-
[3]
A. B. Barrett, G. O. Billings, R. G. M. Morris, and M. C. W. van Rossum. S tate based model of long-term potentiation and synaptic tagging and capture. PLoS Comput Biol, 5 0 (1): 0 e1000259, 2009
work page 2009
-
[4]
J. Cichon and W.-B. Gan. Branch-specific dendritic ca-2+ spikes cause persistent synaptic plasticity. Nature, 520: 0 180--185, 2015
work page 2015
-
[5]
R. M. Fitzsimonds, H. J. Song, and M. M. Poo. Propagation of activity-dependent synaptic depression in simple neural networks. Nature, 388: 0 439--448, 1997
work page 1997
-
[6]
R. Fonseca, U. N \"a gerl, R. Morris, and T. Bonhoeffer. Competing for memory hippocampal LTP under regimes of reduced protein synthesis. Neuron, 44: 0 1011--1020, 2004
work page 2004
-
[7]
U. Frey and R. G. Morris. S ynaptic tagging and long-term potentiation. Nature, 385 0 (6616): 0 533--536, 1997
work page 1997
- [8]
- [9]
-
[10]
D. Grytskyy and R. B. Jolivet. A learning rule balancing energy consumption and information maximization in a feed-forward neuronal network, 2021. URL https://arxiv.org/abs/2103.06562
-
[11]
S. Han, X. Liu, H. Mao, J. Pu, A. Pedram, M. A. Horowitz, and W. J. Dally. Eie: Efficient inference engine on compressed deep neural network. ACM SIGARCH Computer Architecture News, 44 0 (3): 0 243--254, 2016
work page 2016
-
[12]
J. J. Harris, R. Jolivet, and D. Attwell. Synaptic energy use and supply. Neuron, 75 0 (5): 0 762--777, 2012
work page 2012
-
[13]
C. D. Harvey and K. Svoboda. L ocally dynamic synaptic learning rules in pyramidal neuron dendrites. Nature, 450 0 (7173): 0 1195--1200, 2007
work page 2007
-
[14]
M. O. Hill. Diversity and evenness: A unifying notation and its consequences. Ecology, 54: 0 427--432, 1973
work page 1973
- [15]
-
[16]
Y. Jeong, H.-Y. Cho, M. Kim, J.-P. Oh, M. S. Kang, M. Yoo, H.-S. Lee, and J.-H. Han. Synaptic plasticity-dependent competition rule influences memory formation. Nature communications, 12: 0 3915, 2021
work page 2021
- [17]
-
[18]
S. Klug, G. M. Godbersen, L. Rischka, W. Wadsak, V. Pichler, M. Klöbl, M. Hacker, R. Lanzenberger, and A. Hahn. Learning induces coordinated neuronal plasticity of metabolic demands and functional brain networks. Communications biology, 5: 0 428, 2022
work page 2022
-
[19]
E. A. Kram \'a r, A. H. Babayan, C. F. Gavin, C. D. Cox, M. Jafari, C. M. Gall, G. Rumbaugh, and G. Lynch. Synaptic evidence for the efficacy of spaced learning. Proc. Natl. Acad. Sci., 109 0 (13): 0 5121--5126, 2012
work page 2012
-
[20]
J. Lee, L. Xiao, S. Schoenholz, Y. Bahri, R. Novak, J. Sohl-Dickstein, and J. Pennington. Wide neural networks of any depth evolve as linear models under gradient descent. Advances in neural information processing systems, 32, 2019
work page 2019
-
[21]
W. B. Levy and R. A. Baxter. Energy efficient neural codes. Neural Computation, 8 0 (3): 0 531--543, 1996
work page 1996
- [22]
-
[23]
F. Mery and T. J. Kawecki. A cost of long-term memory in drosophila. Science, 308 0 (5725): 0 1148, 2005
work page 2005
-
[24]
A. Pache and M. van Rossum. Lazy learning: a biologically-inspired plasticity rule for fast and energy efficient synaptic plasticity. eprint, arXiv:2303.16067, 2023
-
[25]
C. C. H. Petersen, R. C. Malenka, R. A. Nicoll, and J. J. Hopfield. A ll-or-none potentiation at CA3-CA1 synapses. Proc. Natl. Acad. Sci., 95: 0 4732--4737, 1998
work page 1998
-
[26]
P.-Y. Pla c ais and T. Preat. To favor survival under food shortage, the brain disables costly memory. Science, 339 0 (6118): 0 440--442, 2013
work page 2013
-
[27]
W. B. Potter, K. J. O'Riordan , D. Barnett, S. M. Osting, M. Wagoner, C. Burger, and A. Roopra. Metabolic regulation of neuronal plasticity by the energy sensor AMPK . PloS one, 5 0 (2): 0 e8996, 2010
work page 2010
-
[28]
R. L. Redondo and R. G. M. Morris. Making memories last: the synaptic tagging and capture hypothesis. Nat Rev Neurosci, 12 0 (1): 0 17--30, 2011
work page 2011
-
[29]
M. S. Rioult-Pedotti, D. Friedman, and J. P. Donoghue. Learning-induced LTP in neocortex. Science, 290 0 (5491): 0 533--536, 2000
work page 2000
-
[30]
J. Sacramento, A. Wichert, and M. C. W. van Rossum. Energy efficient sparse connectivity from imbalanced synaptic plasticity rules. PLoS Comput Biol, 11 0 (6): 0 e1004265, 2015
work page 2015
-
[31]
J. Sacramento, R. P. Costa, Y. Bengio, and W. Senn. Dendritic cortical microcircuits approximate the backpropagation algorithm. In Advances in neural information processing systems, pages 8721--8732, 2018
work page 2018
-
[32]
S. Sajikumar, R. G. Morris, and M. Korte. Competition between recently potentiated synaptic inputs reveals a winner-take-all phase of synaptic tagging and capture. Proc. Natl. Acad. Sci., 111 0 (33): 0 12217--12221, 2014
work page 2014
-
[33]
A. Salvetti, B. M. Wilamowski, and C. Dagli. Introducing stochastic process within the backpropagation algorithm for improved convergence. In Proc. of Artifiical Neural Network in Engineering. ANNIE, 1994
work page 1994
-
[34]
W. F. Schmidt, M. A. Kraaijveld, R. P. Duin, et al. Feed forward neural networks with random weights. In International conference on pattern recognition, pages 1--1. IEEE Computer Society Press, 1992
work page 1992
-
[35]
E. Sezener, A. Grabska-Barwi \'n ska, D. Kostadinov, M. Beau, S. Krishnagopal, D. Budden, M. Hutter, J. Veness, M. Botvinick, C. Clopath, et al. A rapid and efficient learning rule for biological neural circuits. BioRxiv, pages 2021--03, 2021
work page 2021
-
[36]
M. A. Smith, L. M. Riby, J. A. M. van Eekelen, and J. K. Foster. Glucose enhancement of human memory: a comprehensive research review of the glucose memory facilitation effect. Neuroscience & Biobehavioral Reviews, 35 0 (3): 0 770--783, 2011
work page 2011
-
[37]
H. Tao, L. I. Zhang, G. Bi, and M. Poo. Selective presynaptic propagation of long-term potentiation in defined neural networks. Journal of neuroscience, 20: 0 3233--3243, 2000
work page 2000
-
[38]
J. Triesch, A. D. Vo, and A.-S. Hafner. Competition for synaptic building blocks shapes synaptic plasticity. eLife, 7: 0 e37836, 2018
work page 2018
- [39]
-
[40]
J. von Oswald, D. Zhao, S. Kobayashi, S. Schug, M. Caccia, N. Zucchet, and J. Sacramento. Learning where to learn: Gradient sparsity in meta and continual learning. Arxiv, page 2110.14402, 2021
-
[41]
J. S. Wiegert, M. Pulin, C. E. Gee, and T. G. Oertner. The fate of hippocampal synapses depends on the sequence of plasticity-inducing events. Elife, 7: 0 e39151, 2018
work page 2018
- [42]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.