Revisiting 16-bit Neural Network Training: A Practical Approach for Resource-Limited Learning
Pith reviewed 2026-05-24 08:24 UTC · model grok-4.3
The pith
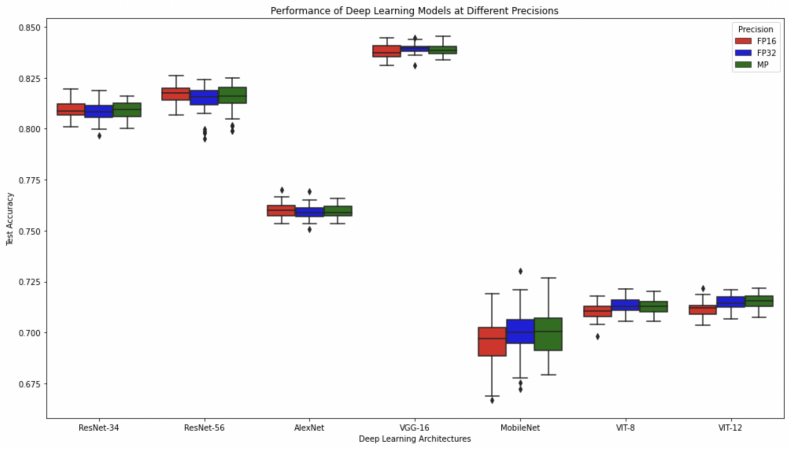
Standalone 16-bit neural networks match 32-bit accuracy while running faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that standalone 16-bit precision neural networks match 32-bit and mixed-precision in accuracy while boosting computational speed. This is shown through a theoretical formalization of floating-point errors and classification tolerance that explains when 16-bit can approximate 32-bit results, backed by extensive empirical evaluation.
What carries the argument
Theoretical formalization of floating-point errors and classification tolerance that identifies conditions for 16-bit to approximate 32-bit training outcomes.
If this is right
- 16-bit standalone training becomes a viable option for resource-limited practitioners without accuracy loss.
- Training speed increases due to lower precision computations across available GPUs.
- Practitioners can select precision based on hardware access rather than expected accuracy differences.
- The approach applies to a range of models because the error analysis is not tied to specific architectures.
Where Pith is reading between the lines
- If confirmed, frameworks could default more training routines to 16-bit to cut memory use in small-scale or educational settings.
- The result might reduce reliance on mixed-precision libraries when only basic hardware is present.
- It opens questions about whether the same tolerance holds when 16-bit is combined with other efficiency methods such as pruning.
Load-bearing premise
The theoretical formalization of floating-point errors and classification tolerance accurately captures the conditions under which 16-bit precision approximates 32-bit results in actual neural network training dynamics.
What would settle it
A controlled experiment on a standard benchmark where standalone 16-bit training produces clearly lower accuracy than 32-bit training under matched conditions would disprove the central claim.
Figures



read the original abstract
With the increasing complexity of machine learning models, managing computational resources like memory and processing power has become a critical concern. Mixed precision techniques, which leverage different numerical precisions during model training and inference to optimize resource usage, have been widely adopted. However, access to hardware that supports lower precision formats (e.g., FP8 or FP4) remains limited, especially for practitioners with hardware constraints. For many with limited resources, the available options are restricted to using 32-bit, 16-bit, or a combination of the two. While it is commonly believed that 16-bit precision can achieve results comparable to full (32-bit) precision, this study is the first to systematically validate this assumption through both rigorous theoretical analysis and extensive empirical evaluation. Our theoretical formalization of floating-point errors and classification tolerance provides new insights into the conditions under which 16-bit precision can approximate 32-bit results. This study fills a critical gap, proving for the first time that standalone 16-bit precision neural networks match 32-bit and mixed-precision in accuracy while boosting computational speed. Given the widespread availability of 16-bit across GPUs, these findings are especially valuable for machine learning practitioners with limited hardware resources to make informed decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standalone FP16 neural network training achieves accuracy matching FP32 and mixed-precision training, supported by a theoretical formalization of per-step floating-point rounding errors linked to classification tolerance, plus extensive empirical evaluations across models and datasets. It positions this as the first rigorous validation of the assumption that 16-bit precision suffices for resource-limited settings, with benefits in speed and memory.
Significance. If the central claim holds, the work would offer practical value for practitioners without access to specialized low-precision hardware, confirming that FP16 can be used standalone without accuracy degradation. The empirical component appears extensive, but the theoretical contribution is limited by its scope.
major comments (1)
- [Theoretical Analysis] Theoretical section: the analysis derives bounds on rounding error for a single forward/backward pass and connects them to classification tolerance, but provides no inductive argument, Lyapunov-style bound, or analysis of error accumulation over the full training trajectory (thousands of optimizer steps in non-convex landscapes). This is load-bearing for the claim that final accuracy remains unaffected.
minor comments (2)
- [Abstract] Abstract and introduction: the claim of being 'the first to systematically validate' should be supported by a more explicit comparison to prior mixed-precision and low-precision training literature.
- [Theoretical Analysis] Notation: clarify whether the classification tolerance parameter is derived from data statistics or treated as a hyperparameter, as this affects the generality of the theoretical result.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment point by point below, providing an honest assessment of the theoretical scope while highlighting the supporting empirical evidence.
read point-by-point responses
-
Referee: [Theoretical Analysis] Theoretical section: the analysis derives bounds on rounding error for a single forward/backward pass and connects them to classification tolerance, but provides no inductive argument, Lyapunov-style bound, or analysis of error accumulation over the full training trajectory (thousands of optimizer steps in non-convex landscapes). This is load-bearing for the claim that final accuracy remains unaffected.
Authors: We agree that the theoretical analysis is limited to deriving per-step bounds on floating-point rounding errors and linking them to classification tolerance, without an inductive argument, Lyapunov-style stability bound, or explicit analysis of error accumulation across the full non-convex training trajectory. This is a genuine limitation of the current theoretical contribution, as a complete characterization of long-term error propagation remains an open challenge in optimization theory. Our manuscript positions the per-step formalization as providing new insights into when 16-bit precision can approximate 32-bit results, with the primary validation coming from the extensive empirical evaluations across models and datasets. We do not claim the theory alone proves invariance over thousands of steps. In revision, we will add an explicit discussion paragraph acknowledging this scope limitation and noting that the empirical results serve as the main support for the practical claim of comparable final accuracy. This constitutes a partial revision focused on clarifying the theoretical boundaries rather than extending the analysis. revision: partial
Circularity Check
No circularity: claims rest on empirical validation and single-pass error bounds without self-referential reduction
full rationale
The abstract and provided context contain no equations, derivations, or self-citations that reduce a claimed result to its own inputs by construction. The theoretical formalization of per-step floating-point error and classification tolerance is presented as an independent analysis, and the central accuracy-matching claim is tied to extensive empirical evaluation rather than any fitted parameter or ansatz smuggled via prior self-work. No load-bearing step matches the enumerated circularity patterns; the skeptic concern about accumulation bounds is a completeness issue, not a circularity reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Floating-point errors in 16-bit precision can be formalized relative to classification tolerance in neural network training.
Reference graph
Works this paper leans on
-
[1]
IEEE P3109: Standard for arithmetic formats for machine learning,
IEEE Standards Association. IEEE P3109: Standard for arithmetic formats for machine learning,
-
[2]
Available at: https://standards.ieee.org/ieee/3109/11010/. Accessed: May 30, 2024
work page 2024
-
[3]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-V oss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott G...
work page 1901
-
[4]
FxpNet: Training a deep convolu- tional neural network in fixed-point representation
Xi Chen, Xiaolin Hu, Hucheng Zhou, and Ningyi Xu. FxpNet: Training a deep convolu- tional neural network in fixed-point representation. In Proceedings of the International Joint Conference on Neural Networks, 2017
work page 2017
-
[5]
Pact: Parameterized clipping activation for quantized neural networks
Jungwook Choi, Zhiwei Wang, Swagath Venkataramani, Puneet Chuang, Vijayalakshmi Srini- vasa, and Kailash Gopalakrishnan. Pact: Parameterized clipping activation for quantized neural networks. In International Conference on Learning Representations, 2018
work page 2018
-
[6]
Xception: Deep learning with depthwise separable convolutions
Francois Chollet. Xception: Deep learning with depthwise separable convolutions. In Proceed- ings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1251–1258, 2017
work page 2017
-
[7]
IEEE standard for floating-point arithmetic
IEEE Computer Society. IEEE standard for floating-point arithmetic. IEEE Std 754-2019 (Revision of IEEE 754-2008), pages 1–84, 2019
work page 2019
-
[8]
BinaryConnect: Training deep neural networks with binary weights during propagations
Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. BinaryConnect: Training deep neural networks with binary weights during propagations. In Proceedings of Neural Information Processing Systems, 2015
work page 2015
-
[9]
Binaryconnect: Training deep neural networks with binary weights during propagations
Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in neural information processing systems, pages 3123–3131, 2015
work page 2015
-
[10]
Trainable fixed-point quantization for deep learning acceleration on fpgas
Dingyi Dai, Yichi Zhang, Jiahao Zhang, Zhanqiu Hu, Yaohui Cai, Qi Sun, and Zhiru Zhang. Trainable fixed-point quantization for deep learning acceleration on fpgas. Arxiv Preprint, 2024
work page 2024
-
[11]
Mixed precision training of convolutional neural networks using integer operations
Dipankar Das, Naveen Mellempudi, Dheevatsa Mudigere, Dhiraj Kalamkar, Sasikanth Avancha, Kunal Banerjee, Srinivas Sridharan, Karthik Vaidyanathan, Bharat Kaul, Evangelos Georganas, Alexander Heinecke, Pradeep Dubey, Jesus Corbal, Nikita Shustrov, Roma Dubtsov, Evarist Fomenko, and Vadim Pirogov. Mixed precision training of convolutional neural networks us...
work page 2018
-
[12]
Understanding and optimizing asynchronous low-precision stochastic gradient descent
Christopher De Sa, Matthew Feldman, Christopher Ré, and Kunle Olukotun. Understanding and optimizing asynchronous low-precision stochastic gradient descent. In Proceedings of International Symposium on Computer Architecture, 2017
work page 2017
-
[13]
LLM.int8(): 8-bit matrix multiplication for transformers at scale
Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. LLM.int8(): 8-bit matrix multiplication for transformers at scale. In Advances in Neural Information Processing Systems, 2024
work page 2024
-
[14]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021
work page 2021
-
[15]
FriendliAI. Meta-llama-3-70b-fp8. Hugging Face, 2024. Available at:https://huggingface. co/meta-llama/Meta-Llama-3-70B-fp8 . Accessed: 2024-05-30. 14
work page 2024
-
[16]
The state of sparsity in deep neural networks
Trevor Gale, Erich Elsen, and Sara Hooker. The state of sparsity in deep neural networks. In International Conference on Learning Representations, 2019
work page 2019
-
[17]
Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, and Kurt Keutzer. A survey of quantization methods for efficient neural network inference. Arxiv Preprint, 2021
work page 2021
-
[18]
Ian Goodfellow, Yoshua Bengio, and Aaron Courville. Deep Learning. MIT Press, 2016
work page 2016
-
[19]
Mixed precision training guide, 2023
Google. Mixed precision training guide, 2023. Available at: https://www.tensorflow. org/guide/mixed_precision. Accessed: Aug 15, 2023
work page 2023
-
[20]
Deep learning with limited numerical precision
Suyog Gupta, Ankur Agrawal, Kailash Gopalakrishnan, and Pritish Narayanan. Deep learning with limited numerical precision. In Proceedings of International Conference on Machine Learning, 2015
work page 2015
-
[21]
Learning both weights and connections for efficient neural network
Song Han, Jeff Pool, John Tran, and William Dally. Learning both weights and connections for efficient neural network. In Advances in Neural Information Processing Systems, pages 1135–1143, 2015
work page 2015
-
[22]
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian. Sun. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, 2016
work page 2016
-
[23]
Nicholas J. Higham. Accuracy and Stability of Numerical Algorithms. Society for Industrial and Applied Mathematics, second edition, 2002
work page 2002
-
[24]
Neural networks for machine learning, 2018
Geoffrey Hinton. Neural networks for machine learning, 2018. Lecture 6a: Overview of mini-batch gradient descent
work page 2018
-
[25]
Distilling the knowledge in a neural network
Geoffrey Hinton, Oriol Vinyals, and Jeffrey Dean. Distilling the knowledge in a neural network. In NIPS Deep Learning and Representation Learning Workshop, 2015
work page 2015
-
[26]
Densely connected convolutional networks
Gao Huang, Zhuang Liu, Laurens Van Der Maaten, and Kilian Q Weinberger. Densely connected convolutional networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4700–4708, 2017
work page 2017
-
[27]
Quantization and training of neural networks for efficient integer-arithmetic-only inference
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017
work page 2017
-
[28]
Howard, Hartwig Adam, and Dmitry Kalenichenko
Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew G. Howard, Hartwig Adam, and Dmitry Kalenichenko. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
work page 2018
-
[29]
Diederik P. Kingma and Jimmy Lei Ba. Adam: A method for stochastic optimization. In Proceedings of International Conference on Learning Representations, 2015
work page 2015
-
[30]
Bf16: Revisiting bf16 training
Ulrich Koster et al. Bf16: Revisiting bf16 training. Proceedings of the International Conference on Machine Learning, 2020
work page 2020
-
[31]
A. Krizhevsky and G Hinton. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[32]
Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25:1097– 1105, 2012
work page 2012
-
[33]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. ImageNet classification with deep convolutional neural networks. In Proceedings of Neural Information Processing Systems, 2012
work page 2012
-
[34]
Webb, Xin Wang, Marcel Nassar, Arjun K
Urs Köster, Tristan J. Webb, Xin Wang, Marcel Nassar, Arjun K. Bansal, William H. Constable, O˘guz H. Elibol, Scott Gray, Stewart Hall, Luke Hornof, Amir Khosrowshahi, Carey Kloss, Ruby J. Pai, and Naveen Rao. Flexpoint: An adaptive numerical format for efficient training of deep neural networks. In Proceedings of Neural Information Processing Systems, 2017
work page 2017
- [35]
-
[36]
ApiQ: Finetuning of 2-bit quantized large language model
Baohao Liao and Christof Monz. ApiQ: Finetuning of 2-bit quantized large language model. Arxiv Preprint, 2024. 15
work page 2024
-
[37]
Darryl D. Lin, Sachin S. Talathi, and V . Sreekanth Annapureddy. Fixed point quantization of deep convolutional networks. In Proceedings of the International Conference on Machine Learning, 2016
work page 2016
-
[38]
The era of 1-bit llms: All large language models are in 1.58 bits
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit llms: All large language models are in 1.58 bits. Arxiv Preprint, 2024
work page 2024
-
[39]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. Mixed precision training. In Proceedings of International Conference on Learning Representations, 2018
work page 2018
-
[40]
NVIDIA ampere ga102 gpu architecture, 2020
NVIDIA. NVIDIA ampere ga102 gpu architecture, 2020. Available at: https://www.nvidia. com/en-us/geforce/technologies/ampere-architecture/. Accessed: Sep 27, 2024
work page 2020
-
[41]
Train with mixed precision, 2023
NVIDIA. Train with mixed precision, 2023. Available at: https://docs.nvidia.com/ deeplearning/performance/mixed-precision-training/index.html. Accessed: Aug 15, 2023
work page 2023
-
[42]
NVIDIA. Tensor cores, 2024. Available at: https://www.nvidia.com/en-gb/ data-center/tensor-cores/. Accessed: 2024-09-27
work page 2024
-
[43]
Tuning cuda applications for nvidia ampere gpu architecture, 2024
NVIDIA. Tuning cuda applications for nvidia ampere gpu architecture, 2024. Available at: https://docs.nvidia.com/cuda/ampere-tuning-guide/index.html. Accessed: Sept 27, 2024
work page 2024
-
[44]
Wayne T. Padgett and David V . Anderson.Fixed-Point Signal Processing. Synthesis Lectures on Signal Processing. Springer Cham, 1 edition, 2009
work page 2009
-
[45]
Accelerating llama3 fp8 inference with triton kernels
PyTorch. Accelerating llama3 fp8 inference with triton kernels. PyTorch Blog, 2024. Available at: https://pytorch.org/blog/accelerating-llama3-fp8-inference/ . Accessed: May 30, 2024
work page 2024
-
[46]
A method for speeding up the convergence of back-propagation learning
Ning Qian. A method for speeding up the convergence of back-propagation learning. Neural Networks, 6(4):861–867, 1999
work page 1999
-
[47]
XNOR-Net: Ima- genet classification using binary convolutional neural networks
Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. XNOR-Net: Ima- genet classification using binary convolutional neural networks. In European Conference on Computer Vision, pages 525–542, 2016
work page 2016
-
[48]
Sascha Ristov, Erez Malkin, and Zeljko Zilic. Efficient deep learning inference on embedded systems using fixed-point arithmetic on fpgas.Journal of Signal Processing Systems, 91(1):1–13, 2019
work page 2019
-
[49]
A. Sabbagh Molahosseini, L. Sousa, A.A. Emrani Zarandi, and H. Vandierendonck. Low- precision floating-point formats: From general-purpose to application-specific. In W. Liu and F. Lombardi, editors, Approximate Computing, pages 109–130. Springer, Cham, 2022
work page 2022
-
[50]
Mobilenetv2: Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zhmoginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018
work page 2018
-
[51]
Bit Fusion: Bit-level dynamically composable archi- tecture for accelerating deep neural networks
Hardik Sharma, Jongse Park, Naveen Suda, Liangzhen Lai, Benson Chau, Joon Kyung Kim, Vikas Chandra, and Hadi Esmaeilzadeh. Bit Fusion: Bit-level dynamically composable archi- tecture for accelerating deep neural networks. In Proceedings of International Symposium on Computer Architecture, 2017
work page 2017
-
[52]
Very deep convolutional networks for large-scale image recognition
Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In Proceedings of International Conference on Learning Representations, 2015
work page 2015
-
[53]
Training data-efficient image transformers and distillation through attention
Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Training data-efficient image transformers and distillation through attention. International Conference on Machine Learning, 2021
work page 2021
-
[54]
Training deep neural networks with 8-bit floating point numbers
Naigang Wang, Jungwook Choi, Daniel Brand, Chia-Yu Chen, and Kailash Gopalakrishnan. Training deep neural networks with 8-bit floating point numbers. In Proceedings of the Interna- tional Conference on Neural Information Processing Systems, page 7686–7695, 2018. 16
work page 2018
-
[55]
Training and inference with integers in deep neural networks
Shuang Wu, Guoqi Li, Feng Chen, and Luping Shi. Training and inference with integers in deep neural networks. In Proceedings of International Conference on Learning Representations, 2018
work page 2018
-
[56]
Training transformers with 4-bit integers
Haocheng Xi, Changhao Li, Jianfei Chen, and Jun Zhu. Training transformers with 4-bit integers. In Advances in Neural Information Processing Systems, 2024
work page 2024
-
[57]
SmoothQuant: accurate and efficient post-training quantization for large language models
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. SmoothQuant: accurate and efficient post-training quantization for large language models. In Proceedings of the International Conference on Machine Learning, 2023
work page 2023
-
[58]
Dan Zafrir, Guy Boudoukh, Peter Izsak, and Moshe Wasserblat. Q8BERT: Quantized 8bit BERT. In Proceedings of the 5th Workshop on Energy Efficient Machine Learning and Cognitive Computing-NeurIPS 2019, pages 36–39, 2019
work page 2019
-
[59]
Ternarybert: Distillation-aware ultra-low bit bert
Wei Zhang, Canwen Liu, Yuwei Ma, Fuwei Zhang, Shuai Li, and Yue Zhang. Ternarybert: Distillation-aware ultra-low bit bert. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, pages 509–521, 2020
work page 2020
-
[60]
DoReFa-Net: Training low bitwidth convolutional neural networks with low bitwidth gradients
Shuchang Zhou, Yuxin Wu, Zekun Ni, Xinyu Zhou, He Wen, and Yuheng Zou. DoReFa-Net: Training low bitwidth convolutional neural networks with low bitwidth gradients. In Arxiv Preprint, 2016. 17
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.