Basis Pursuit Denoising via Recurrent Neural Network Applied to Super-resolving SAR Tomography
Pith reviewed 2026-05-24 09:12 UTC · model grok-4.3
The pith
A recurrent neural network with sparse minimal gated units solves basis pursuit denoising by preserving full information during optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
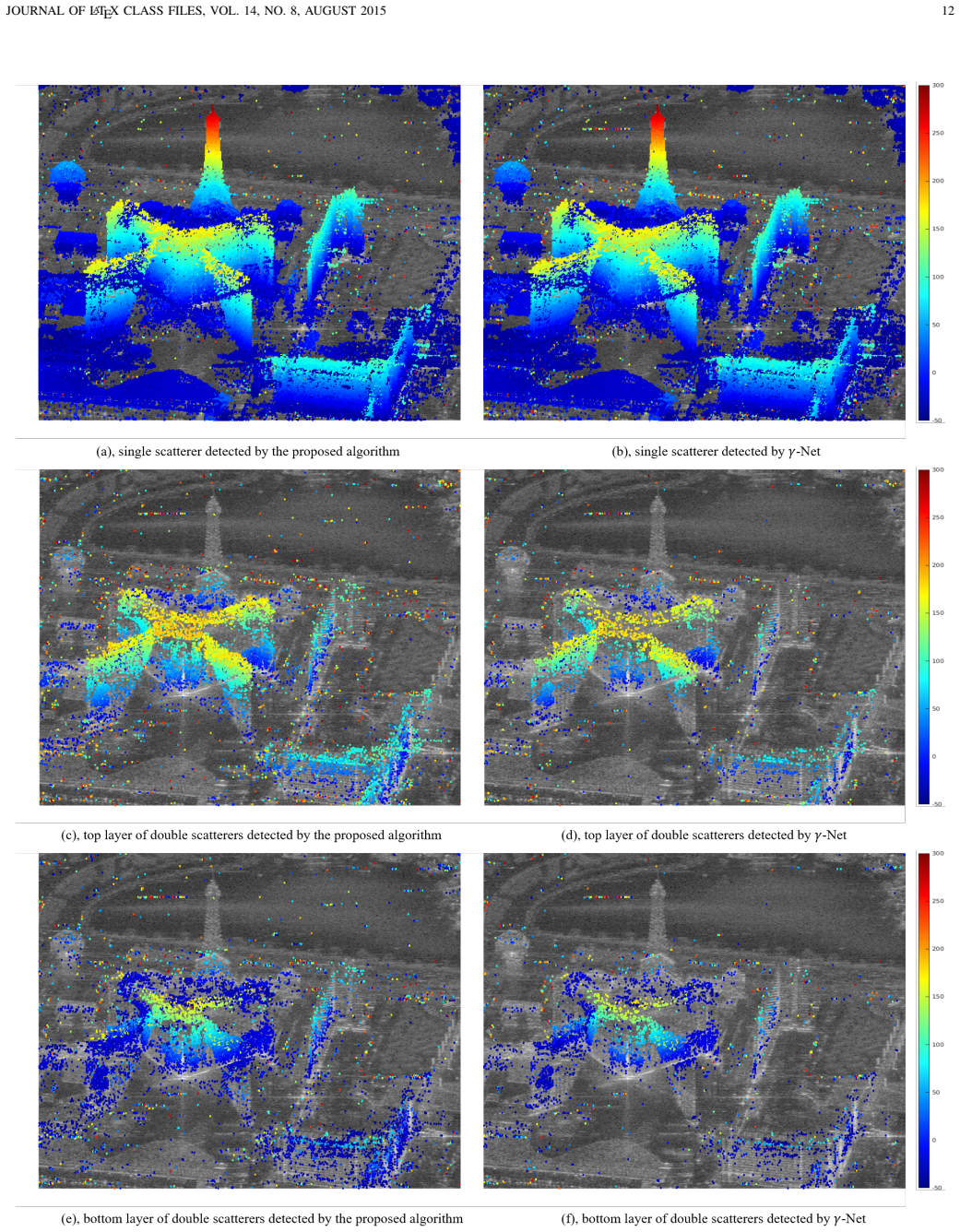
The authors claim that the shrinkage step in unrolled networks for basis pursuit denoising leads to unavoidable information loss in the network dynamics, degrading performance. They propose a recurrent neural network with novel sparse minimal gated units that incorporates historical information into the optimization process, thereby preserving full information in the final output. When applied to TomoSAR inversion, this yields superior super-resolution power and generalization ability, including 10% to 20% higher double scatterers detection rates and reduced sensitivity to phase and amplitude differences between scatterers, as demonstrated in simulations and real TerraSAR-X data.
What carries the argument
The recurrent neural network with sparse minimal gated units (SMGUs), which replace shrinkage functions to retain historical optimization information and prevent information loss.
If this is right
- The proposed method achieves 10% to 20% higher double scatterers detection rate in TomoSAR.
- It exhibits less sensitivity to phase and amplitude ratio differences between scatterers.
- It enables high-quality 3-D reconstruction from real TerraSAR-X spotlight images.
- The architecture maintains the computational efficiency of deep unrolling while improving descriptive power for BPDN.
Where Pith is reading between the lines
- This suggests recurrent structures could address similar information loss in other unrolled optimization networks for sparse problems.
- Extensions to other imaging modalities using basis pursuit might benefit from incorporating memory units.
- Further tests on varied real-world radar datasets could reveal the limits of generalization beyond synthetic training.
Load-bearing premise
That the observed information loss from shrinkage functions is the primary performance limiter and that recurrent memory resolves it without introducing optimization instabilities or overfitting.
What would settle it
A direct comparison experiment where a modified shrinkage-based network matches the RNN's double scatterers detection rate on the same synthetic TomoSAR dataset with varying phase and amplitude ratios would challenge the claim that shrinkage causes unavoidable loss.
Figures


















read the original abstract
Finding sparse solutions of underdetermined linear systems commonly requires the solving of L1 regularized least squares minimization problem, which is also known as the basis pursuit denoising (BPDN). They are computationally expensive since they cannot be solved analytically. An emerging technique known as deep unrolling provided a good combination of the descriptive ability of neural networks, explainable, and computational efficiency for BPDN. Many unrolled neural networks for BPDN, e.g. learned iterative shrinkage thresholding algorithm and its variants, employ shrinkage functions to prune elements with small magnitude. Through experiments on synthetic aperture radar tomography (TomoSAR), we discover the shrinkage step leads to unavoidable information loss in the dynamics of networks and degrades the performance of the model. We propose a recurrent neural network (RNN) with novel sparse minimal gated units (SMGUs) to solve the information loss issue. The proposed RNN architecture with SMGUs benefits from incorporating historical information into optimization, and thus effectively preserves full information in the final output. Taking TomoSAR inversion as an example, extensive simulations demonstrated that the proposed RNN outperforms the state-of-the-art deep learning-based algorithm in terms of super-resolution power as well as generalization ability. It achieved a 10% to 20% higher double scatterers detection rate and is less sensitive to phase and amplitude ratio differences between scatterers. Test on real TerraSAR-X spotlight images also shows a high-quality 3-D reconstruction of the test site.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that shrinkage operations in deep-unrolled networks for basis pursuit denoising (BPDN) cause unavoidable information loss that degrades performance on TomoSAR inversion. It introduces a recurrent architecture built around novel Sparse Minimal Gated Units (SMGUs) that incorporates historical information to preserve full signal content. On synthetic data the RNN is reported to achieve 10–20 % higher double-scatterer detection rates than prior deep-learning BPDN solvers while being less sensitive to phase and amplitude ratios; real TerraSAR-X spotlight data are described as yielding high-quality 3-D reconstructions.
Significance. If the reported gains are shown to be robust, attributable to the SMGU mechanism rather than training-distribution match or recurrence alone, and supported by quantitative controls, the work would provide a concrete architectural remedy for information loss in unrolled sparse-recovery networks and could improve super-resolution performance and generalization in TomoSAR and related inverse problems.
major comments (4)
- [Abstract] Abstract: the headline claim of 10–20 % higher double-scatterer detection rate is presented without naming the exact baseline algorithms, reporting error bars, or stating the number of Monte-Carlo trials; these omissions make it impossible to assess whether the improvement is statistically meaningful or reproducible.
- [Abstract] Abstract / Experiments: no ablation is described that replaces the SMGU with a vanilla GRU or LSTM (keeping the recurrent structure) while measuring detection rate; without this control the attribution of gains specifically to the sparse-gating mechanism versus recurrence or training distribution remains untested.
- [Abstract] Abstract: the discovery that shrinkage induces information loss is asserted on the basis of experiments, yet no quantitative proxy (mutual information, per-iteration reconstruction-error decomposition, or gradient-flow analysis) is supplied to measure that loss or to demonstrate that SMGUs mitigate it.
- [Abstract] Real-data results: the claim of “high-quality 3-D reconstruction” on TerraSAR-X images is stated qualitatively only; no detection-rate, RMSE, or visual-comparison metrics against competing methods are provided, weakening the generalization argument.
minor comments (2)
- Notation for the SMGU update equations should be introduced with explicit definitions of all gates and the sparsity constraint before the first use.
- The manuscript should include a table or figure that directly compares the proposed RNN against at least the two most-cited unrolled baselines (LISTA and its variants) on the same synthetic TomoSAR test set with identical training protocols.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 10–20 % higher double-scatterer detection rate is presented without naming the exact baseline algorithms, reporting error bars, or stating the number of Monte-Carlo trials; these omissions make it impossible to assess whether the improvement is statistically meaningful or reproducible.
Authors: We agree that the abstract should be more self-contained. In the revision we will name the exact baseline algorithms (LISTA and variants), report error bars from the Monte-Carlo runs, and state the number of trials. These details already appear in Section IV but will be added to the abstract. revision: yes
-
Referee: [Abstract] Abstract / Experiments: no ablation is described that replaces the SMGU with a vanilla GRU or LSTM (keeping the recurrent structure) while measuring detection rate; without this control the attribution of gains specifically to the sparse-gating mechanism versus recurrence or training distribution remains untested.
Authors: The referee correctly notes the absence of this control. While the paper compares against non-recurrent unrolled networks, it does not ablate SMGU versus standard GRU/LSTM inside the recurrent structure. We will add the requested ablation study in the revised experiments section to isolate the contribution of the sparse-gating mechanism. revision: yes
-
Referee: [Abstract] Abstract: the discovery that shrinkage induces information loss is asserted on the basis of experiments, yet no quantitative proxy (mutual information, per-iteration reconstruction-error decomposition, or gradient-flow analysis) is supplied to measure that loss or to demonstrate that SMGUs mitigate it.
Authors: The performance gap observed in the experiments is presented as evidence of information loss, but we acknowledge that a direct quantitative proxy is not supplied. We will incorporate a per-iteration reconstruction-error decomposition analysis in the revised manuscript to quantify the loss and show how SMGUs reduce it. revision: yes
-
Referee: [Abstract] Real-data results: the claim of “high-quality 3-D reconstruction” on TerraSAR-X images is stated qualitatively only; no detection-rate, RMSE, or visual-comparison metrics against competing methods are provided, weakening the generalization argument.
Authors: Quantitative metrics such as detection rate or RMSE cannot be computed on real TerraSAR-X data because ground truth is unavailable. We will nevertheless strengthen the real-data section by adding side-by-side visual comparisons against the competing methods and any feasible proxy indicators. revision: partial
Circularity Check
No circularity: new RNN architecture and empirical gains are independent of fitted inputs or self-citations
full rationale
The paper identifies an information-loss issue in shrinkage-based unrolled networks via experiments, then introduces a distinct RNN with SMGUs to incorporate historical information. All performance claims (10-20% higher detection rates, better generalization) are presented as outcomes of new simulations and real-data tests rather than reductions of any equation or parameter to its own inputs. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no prediction is statistically forced by a prior fit. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- RNN weights and gates
axioms (1)
- domain assumption Shrinkage operations in unrolled networks cause unavoidable information loss that degrades final reconstruction quality
invented entities (1)
-
Sparse Minimal Gated Unit (SMGU)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Atomic decomposition by basis pursuit,
S. S. Chen, D. L. Donoho, and M. A. Saunders, “Atomic decomposition by basis pursuit,” SIAM Rev., vol. 43, no. 1, p. 129159, Jan. 2001
work page 2001
-
[2]
A sparse image fusion algorithm with application to pan-sharpening,
X. X. Zhu and R. Bamler, “A sparse image fusion algorithm with application to pan-sharpening,” IEEE Transactions on Geoscience and Remote Sensing, vol. 51, no. 5, pp. 2827–2836, 2013
work page 2013
-
[3]
Joint sparsity model for multilook hyperspectral image unmixing,
J. Bieniarz, E. Aguilera, X. X. Zhu, R. Mller, and P. Reinartz, “Joint sparsity model for multilook hyperspectral image unmixing,” IEEE Geoscience and Remote Sensing Letters , vol. 12, no. 4, pp. 696–700, 2015
work page 2015
-
[4]
Sparse microwave imaging: Principles and applications,
B. Zhang, W. Hong, and Y . Wu, “Sparse microwave imaging: Principles and applications,” Science China Information Sciences , vol. 55, no. 08, p. 33, 2012
work page 2012
-
[5]
Tomographic sar inversion by l1 -norm regularizationthe compressive sensing approach,
X. X. Zhu and R. Bamler, “Tomographic sar inversion by l1 -norm regularizationthe compressive sensing approach,” IEEE Transactions on Geoscience and Remote Sensing , vol. 48, no. 10, pp. 3839–3846, 2010
work page 2010
-
[6]
D. L. Donoho, “Compressed sensing,” IEEE Transactions on Informa- tion Theory, vol. 52, no. 4, pp. 1289–1306, 2006
work page 2006
-
[7]
R. G. Baraniuk, “Compressive sensing,” IEEE Signal Processing Mag- azine, vol. 24, no. 4, pp. 118–121, 2007
work page 2007
-
[8]
An introduction to compressive sampling,
E. J. Candes and M. B. Wakin, “An introduction to compressive sampling,” IEEE Signal Processing Magazine, vol. 25, no. 2, pp. 21–30, 2008
work page 2008
-
[9]
An iterative thresholding algorithm for linear inverse problems with a sparsity constraint,
I. Daubechies, M. Defrise, and C. De Mol, “An iterative thresholding algorithm for linear inverse problems with a sparsity constraint,” Com- munications on Pure and Applied Mathematics , vol. 57, no. 11, pp. 1413–1457, 2004
work page 2004
-
[10]
Y . Li and S. Osher, “Coordinate descent optimization forl1 minimization with application to compressed sensing; a greedy algorithm,” Inverse Problems and Imaging , vol. 3, no. 3, pp. 487–503, 2009
work page 2009
-
[11]
S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, “Distributed optimization and statistical learning via the alternating direction method of multipliers,” Foundations and Trends in Machine Learning, vol. 3, no. 1, pp. 1–122, 2011. [Online]. Available: http://dx.doi.org/10.1561/2200000016
-
[12]
S. J. Wright, Primal-Dual Interior-Point Methods . USA: Society for Industrial and Applied Mathematics, 1997
work page 1997
-
[13]
X. Zhu and R. Bamler, “Super-resolution power and robustness of compressive sensing for spectral estimation with application to space- borne tomographic sar,” IEEE Transactions on Geoscience and Remote Sensing, vol. 50, no. 1, pp. 247–258, 2012
work page 2012
-
[14]
Very high resolution spaceborne sar tomography in urban environment,
X. Zhu and R. Bamler, “Very high resolution spaceborne sar tomography in urban environment,” IEEE Transactions on Geoscience and Remote Sensing, vol. 48, no. 12, pp. 4296–4308, 2010, 00125. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 15 Fig. 20: Illustration the learning architecture of a K-layer γ-Net
work page 2010
-
[15]
Three-dimensional focusing with multipass sar data,
G. Fornaro, F. Serafino, and F. Soldovieri, “Three-dimensional focusing with multipass sar data,” IEEE Transactions on Geoscience and Remote Sensing, vol. 41, no. 3, pp. 507–517, 2003
work page 2003
-
[16]
Deep unfolding: Model-based inspiration of novel deep architectures,
J. Hershey, J. Le Roux, and F. Weninger, “Deep unfolding: Model-based inspiration of novel deep architectures,” Computer Science, 2014
work page 2014
-
[17]
Learning fast approximations of sparse coding,
K. Gregor and Y . LeCun, “Learning fast approximations of sparse coding,” in Proceedings of the 27th International Conference on In- ternational Conference on Machine Learning , ser. ICML’10. Madison, WI, USA: Omnipress, 2010, p. 399406
work page 2010
-
[18]
Admm-csnet: A deep learning approach for image compressive sensing,
Y . Yang, J. Sun, H. Li, and Z. Xu, “Admm-csnet: A deep learning approach for image compressive sensing,” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 42, no. 3, pp. 521–538, 2020
work page 2020
-
[19]
Csr-net: A novel complex-valued network for fast and precise 3-d microwave sparse reconstruction,
M. Wang, S. Wei, J. Shi, Y . Wu, Q. Qu, Y . Zhou, X. Zeng, and B. Tian, “Csr-net: A novel complex-valued network for fast and precise 3-d microwave sparse reconstruction,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , vol. 13, pp. 4476– 4492, 2020
work page 2020
-
[20]
Af- ampnet: A deep learning approach for sparse aperture isar imaging and autofocusing,
S. Wei, J. Liang, M. Wang, J. Shi, X. Zhang, and J. Ran, “Af- ampnet: A deep learning approach for sparse aperture isar imaging and autofocusing,” IEEE Transactions on Geoscience and Remote Sensing , vol. 60, pp. 1–14, 2022
work page 2022
-
[21]
Fast super-resolution 3d sar imaging using an unfolded deep network,
J. Gao, B. Deng, Y . Qin, H. Wang, and X. Li, “Fast super-resolution 3d sar imaging using an unfolded deep network,” 2018
work page 2018
-
[22]
Vector approximate message passing,
S. Rangan, P. Schniter, and A. Fletcher, “Vector approximate message passing,”IRE Professional Group on Information Theory, vol. 65, no. 10, pp. 6664–6684, 2019
work page 2019
-
[23]
γ-net: Superresolving sar tomographic inversion via deep learning,
K. Qian, Y . Wang, Y . Shi, and X. X. Zhu, “ γ-net: Superresolving sar tomographic inversion via deep learning,” IEEE Transactions on Geoscience and Remote Sensing , vol. 60, pp. 1–16, 2022
work page 2022
-
[24]
Theoretical Linear Convergence of Unfolded ISTA and its Practical Weights and Thresholds
X. Chen, J. Liu, Z. Wang, and W. Yin, “Theoretical linear convergence of unfolded ista and its practical weights and thresholds,” arXiv preprint arXiv:1808.10038, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[25]
On the momentum term in gradient descent learning algo- rithms,
N. Qian, “On the momentum term in gradient descent learning algo- rithms,” Neural Networks, vol. 12, no. 1, pp. 145–151, 1999
work page 1999
-
[26]
Adadelta: An adaptive learning rate method,
M. D. Zeiler, “Adadelta: An adaptive learning rate method,” 2012
work page 2012
-
[27]
Adaptive subgradient methods for online learning and stochastic optimization,
J. Duchi, E. Hazan, and Y . Singer, “Adaptive subgradient methods for online learning and stochastic optimization,” J. Mach. Learn. Res. , vol. 12, no. null, p. 21212159, jul 2011
work page 2011
-
[28]
Sc2net: Sparse lstms for sparse coding,
J. T. Zhou, K. Di, J. Du, X. Peng, H. Yang, S. J. Pan, I. W. Tsang, Y . Liu, Z. Qin, and R. S. M. Goh, “Sc2net: Sparse lstms for sparse coding,” in Proceedings of the 32th AAAI Conference on Artificial Intelligence . New Orleans, Louisiana: AAAI, Feb. 2018, pp. 4588–4595
work page 2018
-
[29]
Empirical evaluation of gated recurrent neural networks on sequence modeling,
J. Chung, C. Gulcehre, K. Cho, and Y . Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” in NIPS 2014 Workshop on Deep Learning, December 2014
work page 2014
-
[30]
An empirical exploration of recurrent network architectures,
R. Jozefowicz, W. Zaremba, and I. Sutskever, “An empirical exploration of recurrent network architectures,” in Proceedings of the 32nd Interna- tional Conference on International Conference on Machine Learning - Volume 37, ser. ICML’15, 2015, pp. 2342–2350
work page 2015
-
[31]
K. Greff, R. K. Srivastava, J. Koutnk, B. R. Steunebrink, and J. Schmid- huber, “Lstm: A search space odyssey,” IEEE Transactions on Neural Networks and Learning Systems , vol. 28, no. 10, pp. 2222–2232, 2017
work page 2017
-
[32]
Empirical evaluation of gated recurrent neural networks on sequence modeling,
J. Chung, C. Gulcehre, K. Cho, and Y . Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” in NIPS 2014 Workshop on Deep Learning , 2014
work page 2014
-
[33]
Minimal gated unit for recurrent neural networks,
G.-B. Zhou, J. Wu, C.-L. Zhang, and Z.-H. Zhou, “Minimal gated unit for recurrent neural networks,” Int. J. Autom. Comput. , vol. 13, no. 3, p. 226234, jun 2016
work page 2016
-
[34]
Learning phrase representations using rnn encoder-decoder for statistical machine translation,
K. Cho, B. van Merrienboer, C. Gulcehre, F. Bougares, H. Schwenk, and Y . Bengio, “Learning phrase representations using rnn encoder-decoder for statistical machine translation,” in Conference on Empirical Methods in Natural Language Processing (EMNLP) , 2014
work page 2014
-
[35]
Pytorch: An imperative style, high- performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “Pytorch: An imperative style, high- performance deep learning library,” in Advances in Neural Information Processing ...
work page 2019
-
[36]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2017
work page 2017
-
[37]
F. Rodriguez Gonzalez, N. Adam, A. Parizzi, and R. Brcic, “The Integrated Wide Area Processor (IW AP): A Processor for Wide Area Persistent Scatterer Interferometry,” Edinburgh, UK, Sep. 2013, 00000. Kun Qian received double B.Sc. degree in Re- mote Sensing and Information Engineering from Wuhan University, Wuhan, China and Aerospace En- gineering and Geo...
work page 2013
-
[38]
He is a Member of the IEEE. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 16 Peter Jung (Member IEEE) received the Dipl.- Phys. degree in high energy physics from Humboldt University, Berlin, Germany, in 2000, in cooperation with DESY Hamburg, and the Dr.-rer.nat (Ph.D.) degree in WeylHeisenberg representations in com- munication theory with t...
work page 2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.