DiffSketcher: Text Guided Vector Sketch Synthesis through Latent Diffusion Models
Pith reviewed 2026-05-24 08:26 UTC · model grok-4.3
The pith
Pre-trained text-to-image diffusion models can optimize Bezier curves to generate text-guided vector sketches.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DiffSketcher optimizes a parametric vector generator consisting of Bezier curves by applying an extended Score Distillation Sampling loss derived from a pre-trained latent diffusion model, together with an attention-map-driven stroke initialization that accelerates convergence and maintains structural fidelity across different levels of sketch abstraction.
What carries the argument
Extended Score Distillation Sampling loss that treats the parameters of Bezier curves as the optimizable variables of a vector generator bridged to a raster diffusion prior.
If this is right
- Vector sketches can be produced directly from natural language without first generating and tracing a raster image.
- Sketches retain structural integrity and key visual details even as abstraction level changes.
- The same diffusion prior supports controllable output quality superior to previous text-to-sketch techniques.
- Stroke initialization from attention maps reduces the number of optimization steps required.
Where Pith is reading between the lines
- The same loss extension could be tested on other parametric representations such as closed paths or layered icons.
- If attention maps already encode stroke-like structure, similar initialization may transfer to non-sketch vector tasks.
- The approach opens a route to text-conditioned editing of existing vector drawings by freezing some curve parameters.
Load-bearing premise
The extended SDS loss can successfully optimize Bezier curve parameters to produce coherent sketches that respect the diffusion model's raster prior.
What would settle it
Run the method on a fixed set of text prompts and check whether the resulting vector paths consistently form recognizable subjects whose rendered appearance matches the prompt at least as well as raster baselines while remaining editable as separate strokes.
Figures
















read the original abstract
We demonstrate that pre-trained text-to-image diffusion models, despite being trained on raster images, possess a remarkable capacity to guide vector sketch synthesis. In this paper, we introduce DiffSketcher, a novel algorithm for generating vectorized free-hand sketches directly from natural language prompts. Our method optimizes a set of B\'ezier curves via an extended Score Distillation Sampling (SDS) loss, successfully bridging a raster-level diffusion prior with a parametric vector generator. To further accelerate the generation process, we propose a stroke initialization strategy driven by the diffusion model's intrinsic attention maps. Results show that DiffSketcher produces sketches across varying levels of abstraction while maintaining the structural integrity and essential visual details of the subject. Experiments confirm that our approach yields superior perceptual quality and controllability over existing methods. The code and demo are available at https://ximinng.github.io/DiffSketcher-project/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DiffSketcher, a method for text-guided vector sketch synthesis that optimizes a parametric generator consisting of Bézier curves using an extended Score Distillation Sampling (SDS) loss derived from a pre-trained latent text-to-image diffusion model. It additionally proposes an attention-map-driven stroke initialization strategy to accelerate convergence and claims that the resulting sketches maintain structural integrity across abstraction levels while outperforming prior methods in perceptual quality and controllability.
Significance. If the optimization is shown to be robust, the result would establish that raster-trained diffusion priors can be repurposed for sparse parametric vector outputs, a non-trivial bridge between implicit and explicit representations. The public release of code and a demo is a clear strength that supports reproducibility.
major comments (2)
- [Abstract, §3] Abstract and §3 (method): the central claim that an extended SDS loss successfully bridges the raster diffusion prior to a parametric Bézier generator rests on the unverified assumption that gradients back-propagate stably through differentiable rasterization to produce coherent, non-degenerate strokes. The paper itself notes that attention-map initialization is required to mitigate poor convergence; without an ablation that isolates the loss (e.g., random vs. attention initialization, or SDS-only vs. SDS+regularization) the claim that the diffusion model possesses a 'remarkable capacity' to guide vector synthesis remains load-bearing and unproven.
- [§4] §4 (experiments): the reported superiority in perceptual quality and controllability is asserted but the manuscript provides no quantitative comparison tables or statistical tests against the strongest vector-sketch baselines that also use diffusion priors; qualitative figures alone are insufficient to substantiate the cross-method claim when the optimization path is known to be sensitive to initialization.
minor comments (2)
- [§3] Notation for the extended SDS loss should be written explicitly (current form is described only at high level) so that readers can verify the precise gradient path through the rasterizer.
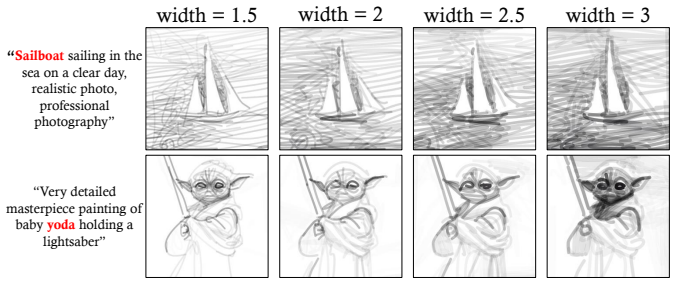
- [Abstract, §3] The abstract states that sketches are produced 'across varying levels of abstraction'; the manuscript should define how abstraction level is controlled (e.g., number of curves, stroke width schedule) and report it as a controllable parameter.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the central claim that an extended SDS loss successfully bridges the raster diffusion prior to a parametric Bézier generator rests on the unverified assumption that gradients back-propagate stably through differentiable rasterization to produce coherent, non-degenerate strokes. The paper itself notes that attention-map initialization is required to mitigate poor convergence; without an ablation that isolates the loss (e.g., random vs. attention initialization, or SDS-only vs. SDS+regularization) the claim that the diffusion model possesses a 'remarkable capacity' to guide vector synthesis remains load-bearing and unproven.
Authors: We appreciate the referee's point regarding the role of initialization and the need for clearer isolation of the loss contribution. The attention-map initialization is presented as an essential component of the method precisely because random starts frequently produce degenerate results; the extended SDS loss then refines the strokes from this informed starting point. To address the concern directly, the revised manuscript will include an ablation study that compares (i) random versus attention-map initialization and (ii) the full extended SDS objective versus SDS alone or with removed regularization terms. These results will provide empirical support for the diffusion prior's guidance capacity under the proposed pipeline. revision: yes
-
Referee: [§4] §4 (experiments): the reported superiority in perceptual quality and controllability is asserted but the manuscript provides no quantitative comparison tables or statistical tests against the strongest vector-sketch baselines that also use diffusion priors; qualitative figures alone are insufficient to substantiate the cross-method claim when the optimization path is known to be sensitive to initialization.
Authors: We agree that quantitative evidence would make the superiority claims more robust, especially given the known sensitivity to initialization. The current experiments rely primarily on qualitative comparisons because standard pixel-level metrics are less meaningful for sparse vector sketches. In the revision we will add a user study with statistical analysis (preference scores and significance tests) against the strongest diffusion-prior baselines, together with any applicable quantitative proxies such as CLIP-based similarity where they can be meaningfully computed for vector outputs. revision: yes
Circularity Check
No circularity; method extends external SDS loss with independent components
full rationale
The paper's derivation consists of applying an extended SDS loss (from external prior work) to optimize Bezier curve parameters via differentiable rasterization and backpropagation through a pre-trained diffusion UNet, plus attention-map initialization also drawn from the same external model. No equation or claim reduces by construction to a fitted input, self-definition, or self-citation chain; the central claim of guiding vector sketches is an empirical extension whose validity rests on reported experiments rather than tautological equivalence to inputs. The approach is self-contained against external benchmarks and does not invoke load-bearing uniqueness theorems or ansatzes from the authors' own prior work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained diffusion models trained on raster images can be used to guide vector graphics synthesis through loss optimization.
Reference graph
Works this paper leans on
-
[1]
Doodleformer: Creative sketch drawing with transformers
Ankan Kumar Bhunia, Salman Khan, Hisham Cholakkal, Rao Muhammad Anwer, Fahad Shah- baz Khan, Jorma Laaksonen, and Michael Felsberg. Doodleformer: Creative sketch drawing with transformers. In Proceedings of the European conference on computer vision (ECCV), pages 338–355, 2022
work page 2022
-
[2]
A computational approach to edge detection
John Canny. A computational approach to edge detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, PAMI-8(6):679–698, 1986
work page 1986
-
[3]
Learning to generate line drawings that convey geometry and semantics
Caroline Chan, Frédo Durand, and Phillip Isola. Learning to generate line drawings that convey geometry and semantics. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7915–7925, June 2022
work page 2022
-
[4]
Deepfacedrawing: Deep generation of face images from sketches
Shu-Yu Chen, Wanchao Su, Lin Gao, Shihong Xia, and Hongbo Fu. Deepfacedrawing: Deep generation of face images from sketches. In ACM Transactions on Graphics (TOG), volume 39, pages 72–1. ACM New York, NY , USA, 2020
work page 2020
-
[5]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems (NIPS) , volume 34, pages 8780–8794, 2021
work page 2021
-
[6]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (NIPS), pages 12873–12883, 2021
work page 2021
-
[7]
CLIPDraw: Exploring text-to-drawing synthesis through language-image encoders
Kevin Frans, Lisa Soros, and Olaf Witkowski. CLIPDraw: Exploring text-to-drawing synthesis through language-image encoders. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems (NIPS), 2022
work page 2022
-
[8]
Songwei Ge, Vedanuj Goswami, Larry Zitnick, and Devi Parikh. Creative sketch generation. In International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[9]
A neural representation of sketch drawings
David Ha and Douglas Eck. A neural representation of sketch drawings. In International Conference on Learning Representations (ICLR), 2018
work page 2018
-
[10]
Prompt-to-prompt image editing with cross-attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-or. Prompt-to-prompt image editing with cross-attention control. In The Eleventh International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[11]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems (NIPS) , volume 33, pages 6840–6851, 2020
work page 2020
-
[12]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models
Ajay Jain, Amber Xie, and Pieter Abbeel. Vectorfusion: Text-to-svg by abstracting pixel-based diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
work page 2023
-
[14]
Rethinking style transfer: From pixels to parameterized brushstrokes
Dmytro Kotovenko, Matthias Wright, Arthur Heimbrecht, and Bjorn Ommer. Rethinking style transfer: From pixels to parameterized brushstrokes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12196–12205, 2021
work page 2021
-
[15]
Photo-sketching: Inferring contour drawings from images
Mengtian Li, Zhe Lin, Radomir Mech, Ersin Yumer, and Deva Ramanan. Photo-sketching: Inferring contour drawings from images. In 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1403–1412. IEEE, 2019
work page 2019
-
[16]
Differentiable vector graphics rasterization for editing and learning
Tzu-Mao Li, Michal Lukáˇc, Gharbi Michaël, and Jonathan Ragan-Kelley. Differentiable vector graphics rasterization for editing and learning. ACM Trans. Graph. (Proc. SIGGRAPH Asia), 39(6):193:1–193:15, 2020
work page 2020
-
[17]
Free-hand sketch synthesis with deformable stroke models
Yi Li, Yi-Zhe Song, Timothy M Hospedales, and Shaogang Gong. Free-hand sketch synthesis with deformable stroke models. International Journal of Computer Vision, 122:169–190, 2017. 12
work page 2017
-
[18]
Unsupervised sketch to photo synthesis
Runtao Liu, Qian Yu, and Stella X Yu. Unsupervised sketch to photo synthesis. In Com- puter Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, pages 36–52. Springer, 2020
work page 2020
-
[19]
Towards layer-wise image vectorization
Xu Ma, Yuqian Zhou, Xingqian Xu, Bin Sun, Valerii Filev, Nikita Orlov, Yun Fu, and Humphrey Shi. Towards layer-wise image vectorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16314–16323, 2022
work page 2022
-
[20]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[21]
Clip-clop: Clip-guided collage and photomontage
Piotr Mirowski, Dylan Banarse, Mateusz Malinowski, Simon Osindero, and Chrisantha Fer- nando. Clip-clop: Clip-guided collage and photomontage. arXiv preprint arXiv:2205.03146, 2022
-
[22]
Differentiable image parameterizations
Alexander Mordvintsev, Nicola Pezzotti, Ludwig Schubert, and Chris Olah. Differentiable image parameterizations. Distill, 2018. https://distill.pub/2018/differentiable-parameterizations
work page 2018
-
[23]
GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models
Alexander Quinn Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob Mcgrew, Ilya Sutskever, and Mark Chen. GLIDE: Towards photorealistic image generation and editing with text-guided diffusion models. In Proceedings of the 39th International Conference on Machine Learning (ICML), volume 162 of Proceedings of Machine Learning Resear...
work page 2022
-
[24]
Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion. In The Eleventh International Conference on Learning Representations (ICLR), 2023
work page 2023
-
[25]
Thomas Porter and Tom Duff. Compositing digital images. In Proceedings of Conference on Computer Graphics and Interactive Techniques, SIGGRAPH ’84, page 253–259, 1984
work page 1984
-
[26]
Sketchlat- tice: Latticed representation for sketch manipulation
Yonggang Qi, Guoyao Su, Pinaki Nath Chowdhury, Mingkang Li, and Yi-Zhe Song. Sketchlat- tice: Latticed representation for sketch manipulation. 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 933–941, 2021
work page 2021
-
[27]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[28]
Hierarchical Text-Conditional Image Generation with CLIP Latents
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Im2vec: Synthesizing vector graphics without vector supervision
Pradyumna Reddy, Michael Gharbi, Michal Lukac, and Niloy J Mitra. Im2vec: Synthesizing vector graphics without vector supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7342–7351, 2021
work page 2021
-
[30]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022
work page 2022
-
[31]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. In Advances in Neural Information Processing Systems (NIPS), volume 35, pages 36479–36494, 2022
work page 2022
-
[32]
Styleclipdraw: Coupling content and style in text-to-drawing synthesis
Peter Schaldenbrand, Zhixuan Liu, and Jean Oh. Styleclipdraw: Coupling content and style in text-to-drawing synthesis. arXiv preprint arXiv:2111.03133, 2021
-
[33]
Christoph Schuhmann. Improved aesthetic predictor. https://github.com/ christophschuhmann/improved-aesthetic-predictor, 2022. 13
work page 2022
-
[34]
LAION-5B: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion- 5b: An open large-scale dataset for training next generation image-text models. arXiv preprint arXiv:2210.08402, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Grad-cam: Visual explanations from deep networks via gradient-based localization
Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision (ICCV), pages 618–626, 2017
work page 2017
-
[36]
Clipgen: A deep generative model for clipart vectorization and synthesis
I-Chao Shen and Bing-Yu Chen. Clipgen: A deep generative model for clipart vectorization and synthesis. IEEE Transactions on Visualization and Computer Graphics, 28(12):4211–4224, 2021
work page 2021
-
[37]
Deep unsu- pervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsu- pervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning (ICML), volume 37, pages 2256–2265, 2015
work page 2015
-
[38]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[39]
Generative modeling by estimating gradients of the data distribution
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems (NIPS), volume 32, 2019
work page 2019
-
[40]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[41]
Modern evolution strategies for creativity: Fitting concrete images and abstract concepts
Yingtao Tian and David Ha. Modern evolution strategies for creativity: Fitting concrete images and abstract concepts. In Artificial Intelligence in Music, Sound, Art and Design, pages 275–291. Springer, 2022
work page 2022
-
[42]
Sketch generation with drawing process guided by vector flow and grayscale
Zhengyan Tong, Xuanhong Chen, Bingbing Ni, and Xiaohang Wang. Sketch generation with drawing process guided by vector flow and grayscale. In Proceedings of the Conference on Artificial Intelligence (AAAI), volume 35, pages 609–616, 2021
work page 2021
-
[43]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems (NIPS), 30, 2017
work page 2017
-
[44]
Clipascene: Scene sketching with different types and levels of abstraction
Yael Vinker, Yuval Alaluf, Daniel Cohen-Or, and Ariel Shamir. Clipascene: Scene sketching with different types and levels of abstraction. arXiv preprint arXiv:2211.17256, 2022
-
[45]
Clipasso: Semantically-aware object sketching
Yael Vinker, Ehsan Pajouheshgar, Jessica Y Bo, Roman Christian Bachmann, Amit Haim Bermano, Daniel Cohen-Or, Amir Zamir, and Ariel Shamir. Clipasso: Semantically-aware object sketching. ACM Transactions on Graphics (TOG), 41(4):1–11, 2022
work page 2022
-
[46]
Holistically-nested edge detection
Saining Xie and Zhuowen Tu. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), pages 1395–1403, 2015
work page 2015
-
[47]
Electronic board style buildings at new york city silhouette
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 14 Supplementary Overview This supplementary material is organized into several sections that provide additional details and ...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.