Evaluating Similitude and Robustness of Deep Image Denoising Models via Adversarial Attack
Pith reviewed 2026-05-24 07:58 UTC · model grok-4.3
The pith
Deep image denoising models from different families share nearly the same adversarial samples, indicating similar local behaviors near test images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Current mainstream non-blind denoising models (DnCNN, FFDNet, ECNDNet, BRDNet), blind denoising models (DnCNN-B, Noise2Noise, RDDCNN-B, FAN), plug-and-play (DPIR, CurvPnP) and unfolding denoising models (DeamNet) almost share the same adversarial sample set on both grayscale and color images, respectively. Shared adversarial sample set indicates that all these models are similar in term of local behaviors at the neighborhood of all the test samples. Non-blind denoising models are found to have high robustness similitude across each other, while hybrid-driven models are also found to have high robustness similitude with pure data-driven non-blind denoising models. Data-driven non-blind models
What carries the argument
The robustness similitude indicator, which quantifies local model similarity by measuring overlap of adversarial samples generated by the denoising-PGD attack.
If this is right
- Non-blind denoising models exhibit high robustness similitude with one another.
- Hybrid-driven models show high robustness similitude with pure data-driven non-blind models.
- Data-driven non-blind models rank as the most robust under the similitude-based assessment.
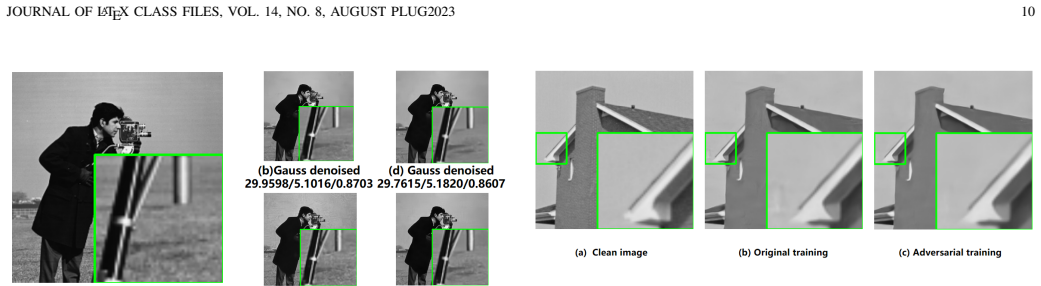
- Adversarial training can be applied to reduce vulnerability to the attack.
- The model-driven BM3D algorithm remains resistant to the proposed attack.
Where Pith is reading between the lines
- The observed behavioral convergence may allow robustness improvements developed for one model to transfer more readily to others in the same family.
- The shared-sample phenomenon could be tested on additional image-restoration tasks such as deblurring or super-resolution.
- Security-sensitive applications might favor classical non-learned methods when adversarial robustness is required.
- Further experiments could vary the attack strength or noise level to map how the similitude changes with input conditions.
Load-bearing premise
That identical adversarial samples across models imply the models behave similarly in the local neighborhood of test samples.
What would settle it
Run the denoising-PGD attack on a fresh test set and check whether the generated adversarial images differ substantially across the listed model families.
Figures













read the original abstract
Deep neural networks (DNNs) have shown superior performance comparing to traditional image denoising algorithms. However, DNNs are inevitably vulnerable while facing adversarial attacks. In this paper, we propose an adversarial attack method named denoising-PGD which can successfully attack all the current deep denoising models while keep the noise distribution almost unchanged. We surprisingly find that the current mainstream non-blind denoising models (DnCNN, FFDNet, ECNDNet, BRDNet), blind denoising models (DnCNN-B, Noise2Noise, RDDCNN-B, FAN), plug-and-play (DPIR, CurvPnP) and unfolding denoising models (DeamNet) almost share the same adversarial sample set on both grayscale and color images, respectively. Shared adversarial sample set indicates that all these models are similar in term of local behaviors at the neighborhood of all the test samples. Thus, we further propose an indicator to measure the local similarity of models, called robustness similitude. Non-blind denoising models are found to have high robustness similitude across each other, while hybrid-driven models are also found to have high robustness similitude with pure data-driven non-blind denoising models. According to our robustness assessment, data-driven non-blind denoising models are the most robust. We use adversarial training to complement the vulnerability to adversarial attacks. Moreover, the model-driven image denoising BM3D shows resistance on adversarial attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a joint denoising-PGD adversarial attack that succeeds against a range of deep image denoising models (non-blind: DnCNN, FFDNet, ECNDNet, BRDNet; blind: DnCNN-B, Noise2Noise, RDDCNN-B, FAN; plug-and-play: DPIR, CurvPnP; unfolding: DeamNet) while keeping the added noise distribution nearly unchanged. It reports that these models share nearly identical adversarial sample sets on grayscale and color images, interprets this as evidence of similar local behaviors near test samples, and introduces a 'robustness similitude' metric to quantify such similarity. The authors conclude that data-driven non-blind models exhibit the highest robustness similitude and overall robustness, recommend adversarial training to address vulnerabilities, and note that the model-driven BM3D method resists the attacks.
Significance. If the shared adversarial samples reflect intrinsic model similarity rather than an artifact of the joint attack optimization, the robustness similitude metric could provide a useful new tool for comparing denoising architectures and assessing robustness. The empirical scope across multiple model categories and the inclusion of adversarial training plus BM3D comparison add practical relevance. However, the absence of implementation details, statistical validation, and controls for attack-induced commonality in the provided text limits the strength of these implications.
major comments (3)
- [Abstract] Abstract: The central claim that the listed models 'almost share the same adversarial sample set' is load-bearing for the robustness similitude metric and the conclusion that non-blind models are most robust, yet no quantitative measure of overlap (e.g., fraction of identical samples, Jaccard index), statistical test, or variance across runs is supplied. This prevents assessment of whether the observed sharing exceeds what would be expected by chance or attack construction.
- [Abstract] Abstract (paragraph beginning 'Shared adversarial sample set indicates...'): The interpretation that shared samples demonstrate similar local behaviors assumes the joint denoising-PGD optimization does not itself enforce commonality across models. No comparison to independent per-model PGD attacks is described, leaving open that the shared set is imposed by the joint success constraint rather than intrinsic gradient or loss-landscape similarity; this directly undermines the validity of the proposed similitude indicator.
- [Abstract] Abstract: The attack is stated to 'keep the noise distribution almost unchanged,' but no metric, distance measure, or verification procedure for this property is given, nor are dataset details, image counts, or noise levels specified. These omissions make it impossible to evaluate whether the attack succeeds on its own stated terms or whether the similitude findings are reproducible.
minor comments (1)
- [Abstract] Abstract contains minor grammatical issues ('comparing to' should be 'compared to'; 'in term of' should be 'in terms of') that affect readability but do not impact technical content.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the implications of our claims. We address each major comment below and will incorporate revisions to strengthen the quantitative support, controls, and reproducibility details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the listed models 'almost share the same adversarial sample set' is load-bearing for the robustness similitude metric and the conclusion that non-blind models are most robust, yet no quantitative measure of overlap (e.g., fraction of identical samples, Jaccard index), statistical test, or variance across runs is supplied. This prevents assessment of whether the observed sharing exceeds what would be expected by chance or attack construction.
Authors: We agree that explicit quantitative measures are required to substantiate the overlap claim. In the revised manuscript we will report the Jaccard index and fraction of identical adversarial samples between each pair of models, include a statistical test against a null model of random overlap, and report variance across independent runs of the attack to confirm the sharing is not attributable to chance or attack construction. revision: yes
-
Referee: [Abstract] Abstract (paragraph beginning 'Shared adversarial sample set indicates...'): The interpretation that shared samples demonstrate similar local behaviors assumes the joint denoising-PGD optimization does not itself enforce commonality across models. No comparison to independent per-model PGD attacks is described, leaving open that the shared set is imposed by the joint success constraint rather than intrinsic gradient or loss-landscape similarity; this directly undermines the validity of the proposed similitude indicator.
Authors: This concern is valid and directly affects the interpretation of the similitude metric. We will add a control experiment that runs independent PGD attacks on each model separately and compares the resulting overlap to the overlap obtained under the joint attack. The revised text will present both results side-by-side so readers can assess whether the observed commonality exceeds what the joint optimization alone would produce. revision: yes
-
Referee: [Abstract] Abstract: The attack is stated to 'keep the noise distribution almost unchanged,' but no metric, distance measure, or verification procedure for this property is given, nor are dataset details, image counts, or noise levels specified. These omissions make it impossible to evaluate whether the attack succeeds on its own stated terms or whether the similitude findings are reproducible.
Authors: We acknowledge these omissions limit reproducibility. The revised manuscript will specify the distance measure (e.g., KL divergence between noise histograms) used to verify that the added noise distribution remains nearly unchanged, together with the exact datasets, number of images, and noise levels employed in all experiments. revision: yes
Circularity Check
No circularity: claims rest on experimental attack outcomes without reduction to inputs or self-citations
full rationale
The paper introduces denoising-PGD as an attack method, applies it experimentally to multiple models, observes shared adversarial samples, and defines robustness similitude as a new indicator based on those observations. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The derivation chain consists of empirical results that remain falsifiable through the attack procedure rather than any self-definitional equivalence or imported uniqueness theorem. This matches the default case of a non-circular experimental paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Nonlinear total variation based noise removal algorithms,
L. I. Rudin, S. Osher, and E. Fatemi, “Nonlinear total variation based noise removal algorithms,” Physica D Nonlinear Phenomena , vol. 60, no. 1-4, pp. 259–268, 1992. I
work page 1992
-
[2]
Scale-space and edge detection using anisotropic diffusion,
P. Perona and J. Malik, “Scale-space and edge detection using anisotropic diffusion,” IEEE Transactions on Pattern Analysis and Machine Intelligence, no. 7, 1990. I
work page 1990
-
[3]
Image denoising by sparse 3-d transform-domain collaborative filtering,
K. Dabov, A. Foi, V . Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-d transform-domain collaborative filtering,” IEEE Trans Image Process, vol. 16, no. 8, pp. 2080–95, 2007. [Online]. Available: https://www.ncbi.nlm.nih.gov/pubmed/17688213 I
-
[4]
Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,
Z. Kai, W. Zuo, Y . Chen, D. Meng, and Z. Lei, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,” pp. 3142– 3155, 2016. I, II-A, II-B
work page 2016
-
[5]
Ffdnet: Toward a fast and flexible solution for cnn-based image denoising,
K. Zhang, W. Zuo, and L. Zhang, “Ffdnet: Toward a fast and flexible solution for cnn-based image denoising,” IEEE Transactions on Image Processing, vol. 27, no. 9, pp. 4608–4622, 2018. I, II-A
work page 2018
-
[6]
Enhanced CNN for image denoising,
C. Tian, Y . Xu, L. Fei, J. Wang, J. Wen, and N. Luo, “Enhanced CNN for image denoising,” CAAI Transactions on Intelligence Technology , vol. 4, no. 1, pp. 17–23, mar 2019. I, II-A
work page 2019
-
[7]
Image denoising using deep cnn with batch renormalization,
C. Tian, Y . xu, and W. Zuo, “Image denoising using deep cnn with batch renormalization,” Neural Networks, vol. 121, pp. 461–473, 01 2020. I, II-A
work page 2020
-
[8]
Noise2Noise: Learning Image Restoration without Clean Data
J. Lehtinen, J. Munkberg, J. Hasselgren, S. Laine, T. Karras, M. Aittala, and T. Aila, “Noise2noise: Learning image restoration without clean data,” CoRR, vol. abs/1803.04189, 2018. I, II-B
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
A robust deformed convolutional neural network (cnn) for image denoising,
Q. Zhang, J. Xiao, C. Tian, C.-W. Lin, and S. Zhang, “A robust deformed convolutional neural network (cnn) for image denoising,” CAAI Transactions on Intelligence Technology , pp. n/a–n/a, 06 2022. I, II-B
work page 2022
-
[10]
Frequency attention network: Blind noise removal for real images,
H. Mo, J. Jiang, Q. Wang, D. Yin, P. Dong, and J. Tian, “Frequency attention network: Blind noise removal for real images,” in Computer Vision – ACCV 2020, H. Ishikawa, C.-L. Liu, T. Pajdla, and J. Shi, Eds. Cham: Springer International Publishing, 2021, pp. 168–184. I, II-B
work page 2020
-
[11]
Plug-and-play priors for model based reconstruction,
S. V . Venkatakrishnan, C. A. Bouman, and B. Wohlberg, “Plug-and-play priors for model based reconstruction,” in 2013 IEEE Global Conference on Signal and Information Processing , 2013, pp. 945–948. I
work page 2013
-
[12]
Learning deep cnn denoiser prior for image restoration,
Z. Kai, W. Zuo, S. Gu, and Z. Lei, “Learning deep cnn denoiser prior for image restoration,” IEEE, 2017. I
work page 2017
-
[13]
Learning proximal operators: Using denoising networks for regularizing inverse imaging problems,
T. Meinhardt, M. Moeller, C. Hazirbas, and D. Cremers, “Learning proximal operators: Using denoising networks for regularizing inverse imaging problems,” IEEE Computer Society , 2017. I JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST PLUG2023 13
work page 2017
-
[14]
Plug- and-play image restoration with deep denoiser prior,
K. Zhang, Y . Li, W. Zuo, L. Zhang, L. Van Gool, and R. Timofte, “Plug- and-play image restoration with deep denoiser prior,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 10, pp. 6360– 6376, 2022. I, II-C
work page 2022
-
[15]
Curvpnp: Plug-and-play blind image restoration with deep curvature denoiser,
Y . Li and Y . Duan, “Curvpnp: Plug-and-play blind image restoration with deep curvature denoiser,” 2022. I, II-C
work page 2022
-
[16]
Adaptive consistency prior based deep network for image denoising,
C. Ren, X. He, C. Wang, and Z. Zhao, “Adaptive consistency prior based deep network for image denoising,” in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , 2021, pp. 8592–
work page 2021
-
[17]
Intriguing properties of neural networks,
C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, “Intriguing properties of neural networks,” 2014. I
work page 2014
-
[18]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” 2015. I, II-D
work page 2015
-
[19]
Deepfool: A simple and accurate method to fool deep neural networks,
S.-M. Moosavi-Dezfooli, A. Fawzi, and P. Frossard, “Deepfool: A simple and accurate method to fool deep neural networks,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2016, pp. 2574–2582. I
work page 2016
-
[20]
One pixel attack for fooling deep neural networks,
J. Su, D. V . Vargas, and K. Sakurai, “One pixel attack for fooling deep neural networks,” IEEE Transactions on Evolutionary Computation , vol. 23, no. 5, pp. 828–841, 2019. I
work page 2019
-
[21]
Spark: Spatial-aware online incremental attack against visual tracking,
Q. Guo, X. Xie, F. Juefei-Xu, L. Ma, Z. Li, W. Xue, W. Feng, and Y . Liu, “Spark: Spatial-aware online incremental attack against visual tracking,” 2020. I
work page 2020
-
[22]
M. F. A. Hady and F. Schwenker, Semi-supervised Learning . Berlin, Heidelberg: Springer Berlin Heidelberg, 2013, pp. 215–239. I
work page 2013
-
[23]
The space of transferable adversarial examples,
F. Tram `er, N. Papernot, I. Goodfellow, D. Boneh, and P. McDaniel, “The space of transferable adversarial examples,” 2017. I
work page 2017
-
[24]
Universal adversarial perturbations,
S. M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, “Universal adversarial perturbations,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2017. I
work page 2017
-
[25]
Delving into transferable adversarial examples and black-box attacks,
Y . Liu, X. Chen, C. Liu, and D. Song, “Delving into transferable adversarial examples and black-box attacks,” 2017. I
work page 2017
-
[26]
Evolving architectures with gradient misalignment toward low adversarial transferability,
K. R. G. Operiano, W. Pora, H. Iba, and H. Kera, “Evolving architectures with gradient misalignment toward low adversarial transferability,”IEEE Access, vol. 9, pp. 164 379–164 393, 2021. I
work page 2021
-
[27]
N. Papernot, P. McDaniel, and I. Goodfellow, “Transferability in ma- chine learning: from phenomena to black-box attacks using adversarial samples,” 2016. I
work page 2016
-
[28]
Disrupting adversarial transferability in deep neural networks,
C. Wiedeman and G. Wang, “Disrupting adversarial transferability in deep neural networks,” Patterns, vol. 3, no. 5, p. 100472, 2022. I
work page 2022
-
[29]
Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,
A. Nguyen, J. Yosinski, and J. Clune, “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , 2015, pp. 427–436. I
work page 2015
-
[30]
Evasion attacks against machine learning at test time,
B. Biggio, I. Corona, D. Maiorca, B. Nelson, Nedim, P. Laskov, G. Giacinto, and F. Roli, “Evasion attacks against machine learning at test time,” in Advanced Information Systems Engineering . Springer Berlin Heidelberg, 2013, pp. 387–402. I
work page 2013
-
[31]
Regulariz- ing deep networks using efficient layerwise adversarial training,
S. Sankaranarayanan, A. Jain, R. Chellappa, and S. N. Lim, “Regulariz- ing deep networks using efficient layerwise adversarial training,” 2018. I
work page 2018
-
[32]
Defense against adversarial attacks using high-level representation guided denoiser,
F. Liao, M. Liang, Y . Dong, T. Pang, X. Hu, and J. Zhu, “Defense against adversarial attacks using high-level representation guided denoiser,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2018, pp. 1778–1787. I
work page 2018
-
[33]
Distillation as a defense to adversarial perturbations against deep neural networks,
N. Papernot, P. McDaniel, X. Wu, S. Jha, and A. Swami, “Distillation as a defense to adversarial perturbations against deep neural networks,” in 2016 IEEE Symposium on Security and Privacy (SP) , 2016, pp. 582–
work page 2016
-
[34]
Pasadena: Perceptually aware and stealthy adversarial denoise attack,
Y . Cheng, Q. Guo, F. Juefei-Xu, W. Feng, S.-W. Lin, W. Lin, and Y . Liu, “Pasadena: Perceptually aware and stealthy adversarial denoise attack,”
-
[35]
Solving inverse problems with deep neural networks – robustness included?
M. Genzel, J. Macdonald, and M. M ¨arz, “Solving inverse problems with deep neural networks – robustness included?” IEEE Transactions on Pattern Analysis and Machine Intelligence , vol. 45, no. 1, pp. 1119– 1134, 2023. I
work page 2023
-
[36]
Adversarial examples in the physical world,
A. Kurakin, I. Goodfellow, and S. Bengio, “Adversarial examples in the physical world,” 2017. II-D
work page 2017
-
[37]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” 2019. II-D, II-D
work page 2019
-
[38]
Nesterov accelerated gradient and scale invariance for adversarial attacks,
J. Lin, C. Song, K. He, L. Wang, and J. E. Hopcroft, “Nesterov accelerated gradient and scale invariance for adversarial attacks,” 2020. II-D
work page 2020
-
[39]
Towards adversarially robust deep image denoising,
H. Yan, J. Zhang, J. Feng, M. Sugiyama, and V . Y . F. Tan, “Towards adversarially robust deep image denoising,” 2022. II-D
work page 2022
-
[40]
Scene categorization towards urban tunnel traffic by image quality assessment,
H. Zhou and S. Zhou, “Scene categorization towards urban tunnel traffic by image quality assessment,” Journal of Visual Communication and Image Representation, vol. 65, p. 102655, 2019. IV JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST PLUG2023 14 VII. B IOGRAPHY SECTION Jie Ning Jie Ning received the B.S. degree in information and computing science...
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.