A Survey on Deep Learning Techniques for Action Anticipation
Pith reviewed 2026-05-24 06:39 UTC · model grok-4.3
The pith
This survey classifies deep learning methods for anticipating human actions in daily-living scenarios by their primary contributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
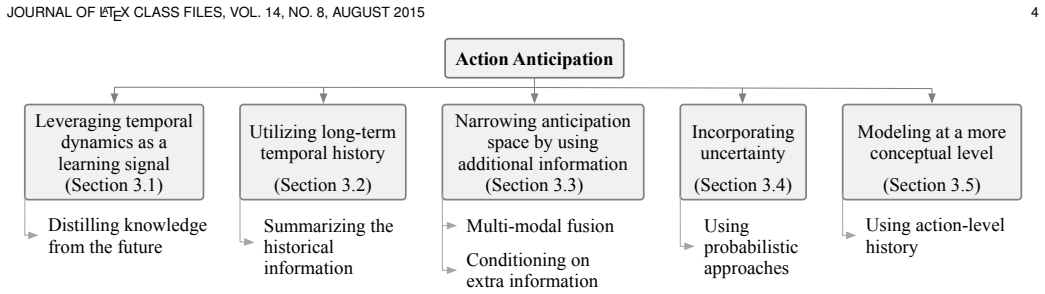
By classifying action anticipation algorithms according to their primary contributions and summarizing them in tables, the survey establishes a structured overview of recent deep learning advances focused on daily-living scenarios, along with common evaluation metrics, datasets, and directions for future research.
What carries the argument
Classification of methods by primary contributions, accompanied by tabular summaries of the reviewed approaches.
If this is right
- Researchers gain an at-a-glance comparison of how different techniques relate to one another.
- Standard practices for evaluation become clearer through the consolidated discussion of metrics and datasets.
- Future algorithm development can be guided by the identified gaps and suggested directions.
Where Pith is reading between the lines
- The same classification lens could be applied to neighboring tasks such as long-term action forecasting.
- Real-world deployment in human-robot interaction might prioritize methods from categories that handle partial observations well.
- New benchmarks could be constructed to test whether methods from one category generalize better than others across scenarios.
Load-bearing premise
The survey's selection of methods, datasets, and metrics accurately covers the current literature without major omissions or selection bias.
What would settle it
Identification of several prominent recent papers on action anticipation in daily-living settings that are absent from the classification tables.
Figures





read the original abstract
The ability to anticipate possible future human actions is essential for a wide range of applications, including autonomous driving and human-robot interaction. Consequently, numerous methods have been introduced for action anticipation in recent years, with deep learning-based approaches being particularly popular. In this work, we review the recent advances of action anticipation algorithms with a particular focus on daily-living scenarios. Additionally, we classify these methods according to their primary contributions and summarize them in tabular form, allowing readers to grasp the details at a glance. Furthermore, we delve into the common evaluation metrics and datasets used for action anticipation and provide future directions with systematical discussions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript is a survey reviewing recent deep learning-based methods for action anticipation, with a focus on daily-living scenarios. It classifies methods according to primary contributions, summarizes them in tables, discusses common evaluation metrics and datasets, and provides systematic discussions of future directions.
Significance. A well-organized survey with tabular summaries can help the computer vision community by consolidating the literature on action anticipation, clarifying trends in daily-living applications, and highlighting open problems; the tabular format and metric/dataset review are practical strengths for readers.
minor comments (3)
- [Abstract] Abstract: the claim of reviewing 'recent advances' would be strengthened by stating the publication years or number of papers covered to allow readers to gauge scope and potential selection bias.
- The classification scheme by 'primary contributions' should include a brief justification or decision criteria in the main text to make the taxonomy reproducible and less subjective.
- Ensure all tables include clear captions, column definitions, and references back to the corresponding sections discussing each method.
Simulated Author's Rebuttal
We thank the referee for the positive summary and significance assessment of our survey, as well as the recommendation for minor revision. No specific major comments were listed in the report.
Circularity Check
No circularity: survey paper with no derivations or predictions
full rationale
This is a literature survey that reviews, classifies, and tabulates existing action anticipation methods without presenting any original derivations, equations, fitted parameters, or predictions. The abstract and description explicitly frame the work as classification and summarization of prior literature, with no self-citation chains or ansatzes invoked as load-bearing premises. No steps match any of the enumerated circularity patterns because the paper makes no claims that reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Slowfast networks for video recognition,
C. Feichtenhofer, H. Fan, J. Malik, and K. He, “Slowfast networks for video recognition,” in ICCV, 2019, pp. 6202–6211
work page 2019
-
[2]
Z. Liu, J. Ning, Y. Cao, Y. Wei, Z. Zhang, S. Lin, and H. Hu, “Video swin transformer,” in CVPR, 2022, pp. 3202–3211
work page 2022
-
[3]
P . Philipp, ¨Uber die Formalisierung und Analyse medizinischer Prozesse im Kontext von Expertenwissen und k¨ unstlicher Intelligenz. KIT Scientific Publishing, 2023
work page 2023
-
[4]
Anticipating visual representations from unlabeled video,
C. Vondrick, H. Pirsiavash, and A. Torralba, “Anticipating visual representations from unlabeled video,” in CVPR, 2016, pp. 98– 106
work page 2016
-
[5]
Temporal Aggregate Repre- sentations for Long-Range Video Understanding,
F. Sener, D. Singhania, and A. Yao, “Temporal Aggregate Repre- sentations for Long-Range Video Understanding,” inECCV, 2020
work page 2020
-
[6]
MeMViT: Memory-Augmented Multiscale Vi- sion Transformer for Efficient Long-Term Video Recognition,
C.-Y. Wu, Y. Li, K. Mangalam, H. Fan, B. Xiong, J. Malik, and C. Feichtenhofer, “MeMViT: Memory-Augmented Multiscale Vi- sion Transformer for Efficient Long-Term Video Recognition,” in CVPR, 2022
work page 2022
-
[7]
Scaling egocentric vision: The epic-kitchens dataset,
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price et al. , “Scaling egocentric vision: The epic-kitchens dataset,” in ECCV, 2018, pp. 720–736
work page 2018
-
[8]
Temporal action segmentation: An analysis of modern technique,
G. Ding, F. Sener, and A. Yao, “Temporal action segmentation: An analysis of modern technique,” arXiv preprint arXiv:2210.10352 , 2022
-
[9]
Deep learning-based action detection in untrimmed videos: A survey,
E. Vahdani and Y. Tian, “Deep learning-based action detection in untrimmed videos: A survey,” TP AMI, 2022
work page 2022
-
[10]
A Review on Deep Learning Techniques for Video Prediction,
S. Oprea, P . Martinez-Gonzalez, A. Garcia-Garcia, J. A. Castro- Vargas, S. Orts-Escolano, J. Garcia-Rodriguez, and A. Argyros, “A Review on Deep Learning Techniques for Video Prediction,” TP AMI, no. 6, 2020
work page 2020
-
[11]
Human motion trajectory prediction: A sur- vey,
A. Rudenko, L. Palmieri, M. Herman, K. M. Kitani, D. M. Gavrila, and K. O. Arras, “Human motion trajectory prediction: A sur- vey,” The International Journal of Robotics Research , vol. 39, no. 8, pp. 895–935, 2020
work page 2020
-
[12]
3d human motion prediction: A survey,
K. Lyu, H. Chen, Z. Liu, B. Zhang, and R. Wang, “3d human motion prediction: A survey,” Neurocomputing, vol. 489, pp. 345– 365, 2022. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 17
work page 2022
-
[13]
Convolutional lstm network: A machine learning ap- proach for precipitation nowcasting,
X. Shi, Z. Chen, H. Wang, D.-Y. Yeung, W.-K. Wong, and W.- c. Woo, “Convolutional lstm network: A machine learning ap- proach for precipitation nowcasting,” in NeurIPS, vol. 28, 2015
work page 2015
-
[14]
Price prediction strategies for market-based scheduling,
J. K. MacKie-Mason, A. V . Osepayshvili, D. M. Reeves, and M. P . Wellman, “Price prediction strategies for market-based scheduling,” in International Conference on Automated Planning and Scheduling, 2004
work page 2004
-
[15]
T. Petkovi ´c, D. Puljiz, I. Markovi ´c, and B. Hein, “Human In- tention Estimation based on Hidden Markov Model Motion Validation for Safe Flexible Robotized Warehouses,” Robotics and Computer-Integrated Manufacturing, 2019
work page 2019
-
[16]
Anticipating Human Activi- ties Using Object Affordances for Reactive Robotic Response,
H. S. Koppula and A. Saxena, “Anticipating Human Activi- ties Using Object Affordances for Reactive Robotic Response,” TP AMI, no. 1, 2016
work page 2016
-
[17]
Car that Knows Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models,
A. Jain, H. S. Koppula, B. Raghavan, S. Soh, and A. Saxena, “Car that Knows Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models,” in ICCV, 2015
work page 2015
-
[18]
Pedestrian Action Anticipation using Contextual Feature Fusion in Stacked RNNs,
A. Rasouli, I. Kotseruba, and J. K. Tsotsos, “Pedestrian Action Anticipation using Contextual Feature Fusion in Stacked RNNs,” in BMVC, 2019
work page 2019
-
[19]
Help by predicting what to do,
E. Alati, L. Mauro, V . Ntouskos, and F. Pirri, “Help by predicting what to do,” in ICIP, 2019
work page 2019
-
[20]
Anticipating the Start of User Interaction for Service Robot in the Wild,
K. Ito, Q. Kong, S. Horiguchi, T. Sumiyoshi, and K. Nagamatsu, “Anticipating the Start of User Interaction for Service Robot in the Wild,” in ICRA, 2020
work page 2020
-
[21]
P . Schydlo, M. Rakovic, L. Jamone, and J. Santos-Victor, “Antici- pation in human-robot cooperation: A recurrent neural network approach for multiple action sequences prediction,” in ICRA, 2018, pp. 5909–5914
work page 2018
-
[22]
Using gaze patterns to predict task intent in collaboration,
C.-M. Huang, S. Andrist, A. Saupp ´e, and B. Mutlu, “Using gaze patterns to predict task intent in collaboration,” Frontiers in psychology, vol. 6, p. 1049, 2015
work page 2015
-
[23]
Generating notifications for missing actions: Don’t forget to turn the lights off!
B. Soran, A. Farhadi, and L. Shapiro, “Generating notifications for missing actions: Don’t forget to turn the lights off!” in ICCV, 2015, pp. 4669–4677
work page 2015
-
[24]
Agent-Centric Risk Assessment: Accident Anticipation and Risky Region Localization,
K.-H. Zeng, S.-H. Chou, F.-H. Chan, J. C. Niebles, and M. Sun, “Agent-Centric Risk Assessment: Accident Anticipation and Risky Region Localization,” in CVPR, 2017
work page 2017
-
[25]
Anticipating traffic accidents with adaptive loss and large-scale incident db,
T. Suzuki, H. Kataoka, Y. Aoki, and Y. Satoh, “Anticipating traffic accidents with adaptive loss and large-scale incident db,” in CVPR, 2018, pp. 3521–3529
work page 2018
-
[26]
A comprehensive survey on human activity prediction,
N. P . Trong, H. Nguyen, K. Kazunori, and B. Le Hoai, “A comprehensive survey on human activity prediction,” in ICCSA, 2017, pp. 411–425
work page 2017
-
[27]
Deep learning for vision-based prediction: A sur- vey,
A. Rasouli, “Deep learning for vision-based prediction: A sur- vey,” arXiv preprint arXiv:2007.00095, 2020
-
[28]
Human action recognition and prediction: A survey,
Y. Kong and Y. Fu, “Human action recognition and prediction: A survey,” IJCV, vol. 130, no. 5, pp. 1366–1401, 2022
work page 2022
-
[29]
Pre- dicting the future from first person (egocentric) vision: A survey,
I. Rodin, A. Furnari, D. Mavroeidis, and G. M. Farinella, “Pre- dicting the future from first person (egocentric) vision: A survey,” Computer Vision and Image Understanding, vol. 211, p. 103252, 2021
work page 2021
-
[30]
Online human action detection and anticipation in videos: A survey,
X. Hu, J. Dai, M. Li, C. Peng, Y. Li, and S. Du, “Online human action detection and anticipation in videos: A survey,” Neurocom- puting, vol. 491, pp. 395–413, 2022
work page 2022
-
[31]
An outlook into the future of egocentric vision,
C. Plizzari, G. Goletto, A. Furnari, S. Bansal, F. Ragusa, G. M. Farinella, D. Damen, and T. Tommasi, “An outlook into the future of egocentric vision,” arXiv preprint arXiv:2308.07123, 2023
-
[32]
Modeling Complex Temporal Compo- sition of Actionlets for Activity Prediction,
K. Li, J. Hu, and Y. Fu, “Modeling Complex Temporal Compo- sition of Actionlets for Activity Prediction,” in ECCV, vol. 7572, 2012, pp. 286–299
work page 2012
-
[33]
Prediction of Human Activity by Discovering Temporal Sequence Patterns,
K. Li and Y. Fu, “Prediction of Human Activity by Discovering Temporal Sequence Patterns,” TP AMI, vol. 36, no. 8, pp. 1644– 1657, 2014
work page 2014
-
[34]
First-person activity forecasting with online inverse reinforcement learning,
N. Rhinehart and K. M. Kitani, “First-person activity forecasting with online inverse reinforcement learning,” in ICCV, 2017, pp. 3696–3705
work page 2017
-
[35]
A poisson process model for activity forecasting,
T. Mahmud, M. Hasan, A. Chakraborty, and A. K. Roy- Chowdhury, “A poisson process model for activity forecasting,” in ICIP, 2016, pp. 3339–3343
work page 2016
-
[36]
Predicting Human Activities Using Stochastic Grammar,
S. Qi, S. Huang, P . Wei, and S.-C. Zhu, “Predicting Human Activities Using Stochastic Grammar,” in ICCV, 2017
work page 2017
-
[37]
Very deep convolutional net- works for large-scale image recognition,
K. Simonyan and A. Zisserman, “Very deep convolutional net- works for large-scale image recognition,” in ICLR, 2015
work page 2015
-
[38]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR, 2016, pp. 770–778
work page 2016
-
[39]
Temporal Segment Networks: Towards Good Prac- tices for Deep Action Recognition,
L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and L. Van Gool, “Temporal Segment Networks: Towards Good Prac- tices for Deep Action Recognition,” in ECCV, 2016
work page 2016
-
[40]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” in ICLR, 2021
work page 2021
-
[41]
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,
J. Carreira and A. Zisserman, “Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,” in CVPR, 2017
work page 2017
-
[42]
Two-stream convolutional net- works for action recognition in videos,
K. Simonyan and A. Zisserman, “Two-stream convolutional net- works for action recognition in videos,” in NeurIPS, vol. 27, 2014
work page 2014
-
[43]
A closer look at spatiotemporal convolutions for action recogni- tion,
D. Tran, H. Wang, L. Torresani, J. Ray, Y. LeCun, and M. Paluri, “A closer look at spatiotemporal convolutions for action recogni- tion,” in CVPR, 2018, pp. 6450–6459
work page 2018
-
[44]
Mvitv2: Improved multiscale vision trans- formers for classification and detection,
Y. Li, C.-Y. Wu, H. Fan, K. Mangalam, B. Xiong, J. Malik, and C. Feichtenhofer, “Mvitv2: Improved multiscale vision trans- formers for classification and detection,” in CVPR, 2022, pp. 4804–4814
work page 2022
-
[45]
RED: Reinforced Encoder- Decoder Networks for Action Anticipation,
J. Gao, Z. Yang, and R. Nevatia, “RED: Reinforced Encoder- Decoder Networks for Action Anticipation,” in BMVC, 2017
work page 2017
-
[46]
When will you do what? - Anticipating Temporal Occurrences of Activities,
Y. A. Farha, A. Richard, and J. Gall, “When will you do what? - Anticipating Temporal Occurrences of Activities,” inCVPR, 2018
work page 2018
-
[47]
Ego4D: Around the World in 3,000 Hours of Egocentric Video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar et al. , “Ego4D: Around the World in 3,000 Hours of Egocentric Video,” in CVPR, 2022
work page 2022
-
[48]
Uncertainty-Aware Anticipation of Activities,
Y. Abu Farha and J. Gall, “Uncertainty-Aware Anticipation of Activities,” in ICCV Workshop, 2019
work page 2019
-
[49]
On diverse asynchronous activity anticipation,
H. Zhao and R. P . Wildes, “On diverse asynchronous activity anticipation,” in ECCV, 2020, pp. 781–799
work page 2020
-
[50]
Weakly supervised action learning with rnn based fine-to-coarse modeling,
A. Richard, H. Kuehne, and J. Gall, “Weakly supervised action learning with rnn based fine-to-coarse modeling,” in CVPR, 2017, pp. 754–763
work page 2017
-
[51]
Ms-tcn: Multi-stage temporal convo- lutional network for action segmentation,
Y. A. Farha and J. Gall, “Ms-tcn: Multi-stage temporal convo- lutional network for action segmentation,” in CVPR, 2019, pp. 3575–3584
work page 2019
-
[52]
Weakly-supervised dense action anticipation,
H. Zhang, F. Chen, and A. Yao, “Weakly-supervised dense action anticipation,” in BMVC, 2021
work page 2021
-
[53]
A Variational Auto-Encoder Model for Stochastic Point Pro- cesses,
N. Mehrasa, A. A. Jyothi, T. Durand, J. He, L. Sigal, and G. Mori, “A Variational Auto-Encoder Model for Stochastic Point Pro- cesses,” in CVPR, 2019
work page 2019
-
[54]
Faster r-cnn: Towards real- time object detection with region proposal networks,
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-cnn: Towards real- time object detection with region proposal networks,” inNeurIPS, vol. 28, 2015
work page 2015
-
[55]
K. He, G. Gkioxari, P . Doll ´ar, and R. Girshick, “Mask r-cnn,” in ICCV, 2017, pp. 2961–2969
work page 2017
-
[56]
Imagenet classi- fication with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classi- fication with deep convolutional neural networks,” in NeurIPS, 2012
work page 2012
-
[57]
High five: Recognising human interactions in tv shows
A. Patron-Perez, M. Marszalek, A. Zisserman, and I. Reid, “High five: Recognising human interactions in tv shows.” in BMVC, vol. 1, no. 2, 2010, p. 33
work page 2010
-
[58]
Detecting activities of daily living in first-person camera views,
H. Pirsiavash and D. Ramanan, “Detecting activities of daily living in first-person camera views,” in CVPR, 2012, pp. 2847– 2854
work page 2012
-
[59]
Thumos challenge: Action recognition with a large number of classes,
Y.-G. Jiang, J. Liu, A. R. Zamir, G. Toderici, I. Laptev, M. Shah, and R. Sukthankar, “Thumos challenge: Action recognition with a large number of classes,” 2014
work page 2014
-
[60]
Visual forecasting by imitating dynamics in natural sequences,
K.-H. Zeng, W. B. Shen, D.-A. Huang, M. Sun, and J. Car- los Niebles, “Visual forecasting by imitating dynamics in natural sequences,” in ICCV, 2017, pp. 2999–3008
work page 2017
-
[61]
CUHK & ETHZ & SIAT Submission to ActivityNet Challenge 2016
Y. Xiong, L. Wang, Z. Wang, B. Zhang, H. Song, W. Li, D. Lin, Y. Qiao, L. Van Gool, and X. Tang, “Cuhk & ethz & siat submission to activitynet challenge 2016,” arXiv preprint arXiv:1608.00797, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[62]
R. D. Geest, E. Gavves, A. Ghodrati, Z. Li, C. Snoek, and T. Tuyte- laars, “Online action detection,” in ECCV, 2016, pp. 269–284
work page 2016
-
[63]
Unsupervised learning for forecast- ing action representations,
Y. Zhong and W.-S. Zheng, “Unsupervised learning for forecast- ing action representations,” in ICIP, 2018, pp. 1073–1077
work page 2018
-
[64]
Knowledge distillation for human action anticipation,
V . Tran, Y. Wang, Z. Zhang, and M. Hoai, “Knowledge distillation for human action anticipation,” in ICIP, 2021, pp. 2518–2522
work page 2021
-
[65]
Anticipating human actions by cor- relating past with the future with Jaccard similarity measures,
B. Fernando and S. Herath, “Anticipating human actions by cor- relating past with the future with Jaccard similarity measures,” in CVPR, 2021
work page 2021
-
[66]
The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities,
H. Kuehne, A. Arslan, and T. Serre, “The Language of Actions: Recovering the Syntax and Semantics of Goal-Directed Human Activities,” in CVPR, 2014. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2015 18
work page 2014
-
[67]
Anticipative Video Transformer,
R. Girdhar and K. Grauman, “Anticipative Video Transformer,” in ICCV, 2021
work page 2021
-
[68]
Rescaling egocentric vision: Collection, pipeline and challenges for epic- kitchens-100,
D. Damen, H. Doughty, G. M. Farinella, A. Furnari, E. Kazakos, J. Ma, D. Moltisanti, J. Munro, T. Perrett, W. Priceet al., “Rescaling egocentric vision: Collection, pipeline and challenges for epic- kitchens-100,” IJCV, pp. 1–23, 2022
work page 2022
-
[69]
In the eye of beholder: Joint learning of gaze and actions in first person video,
Y. Li, M. Liu, and J. M. Rehg, “In the eye of beholder: Joint learning of gaze and actions in first person video,” in ECCV, 2018, pp. 619–635
work page 2018
-
[70]
S. Stein and S. J. McKenna, “Combining embedded accelerom- eters with computer vision for recognizing food preparation activities,” in UbiComp, 2013, pp. 729–738
work page 2013
-
[71]
Learning To Anticipate Future With Dynamic Context Removal,
X. Xu, Y.-L. Li, and C. Lu, “Learning To Anticipate Future With Dynamic Context Removal,” in CVPR, 2022
work page 2022
-
[72]
Tsm: Temporal shift module for efficient video understanding,
J. Lin, C. Gan, and S. Han, “Tsm: Temporal shift module for efficient video understanding,” in ICCV, 2019, pp. 7083–7093
work page 2019
-
[73]
Latency mat- ters: Real-time action forecasting transformer,
H. Girase, N. Agarwal, C. Choi, and K. Mangalam, “Latency mat- ters: Real-time action forecasting transformer,” in CVPR, 2023, pp. 18 759–18 769
work page 2023
-
[74]
Fore- casting future action sequences with neural memory networks,
H. Gammulle, S. Denman, S. Sridharan, and C. Fookes, “Fore- casting future action sequences with neural memory networks,” in BMVC, 2019
work page 2019
-
[75]
Temporal recurrent networks for online action detection,
M. Xu, M. Gao, Y.-T. Chen, L. S. Davis, and D. J. Crandall, “Temporal recurrent networks for online action detection,” in ICCV, 2019, pp. 5532–5541
work page 2019
-
[76]
TTPP: Tempo- ral Transformer with Progressive Prediction for Efficient Action Anticipation,
W. Wang, X. Peng, Y. Su, Y. Qiao, and J. Cheng, “TTPP: Tempo- ral Transformer with Progressive Prediction for Efficient Action Anticipation,” Neurocomputing, 2020
work page 2020
-
[77]
Lap-net: Adaptive features sampling via learning action progression for online action detection,
S. Qu, G. Chen, D. Xu, J. Dong, F. Lu, and A. Knoll, “Lap-net: Adaptive features sampling via learning action progression for online action detection,” arXiv preprint arXiv:2011.07915, 2020
-
[78]
Learning to Anticipate Egocentric Actions by Imagination,
Y. Wu, L. Zhu, X. Wang, Y. Yang, and F. Wu, “Learning to Anticipate Egocentric Actions by Imagination,” TIP, 2021
work page 2021
-
[79]
Long short-term transformer for online action detection,
M. Xu, Y. Xiong, H. Chen, X. Li, W. Xia, Z. Tu, and S. Soatto, “Long short-term transformer for online action detection,” in NeurIPS, vol. 34, 2021, pp. 1086–1099
work page 2021
-
[80]
Oadtr: Online action detection with transformers,
X. Wang, S. Zhang, Z. Qing, Y. Shao, Z. Zuo, C. Gao, and N. Sang, “Oadtr: Online action detection with transformers,” in ICCV, 2021
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.