Entry-level guide to the use of large language models for medical research
Pith reviewed 2026-05-23 19:24 UTC · model grok-4.3
The pith
A structured workflow lets healthcare professionals adapt large language models to medical tasks while handling safety and compliance needs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
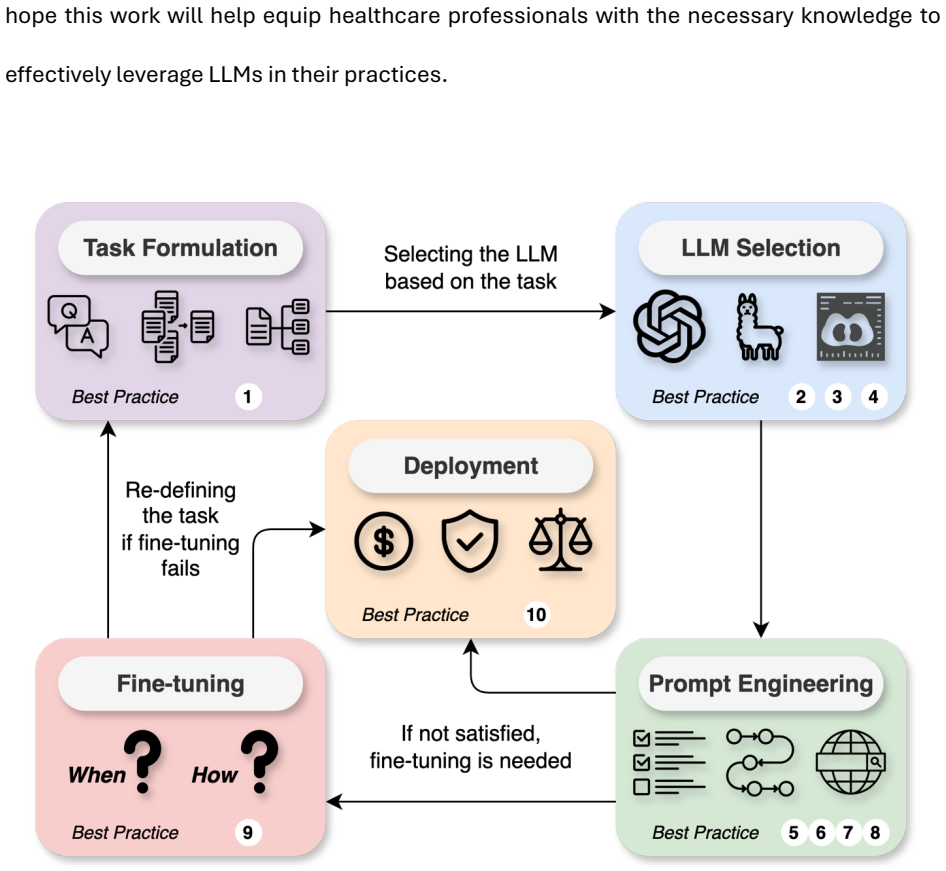
The paper claims that an overall workflow of task formulation, LLM selection based on task and data requirements, prompt engineering and fine-tuning for adaptation, plus deployment steps that include regulatory compliance, ethical guidelines, and ongoing bias monitoring provides healthcare professionals with the methodology needed to integrate LLMs into clinical practice in a safe, reliable, and impactful way.
What carries the argument
The overall workflow consisting of formulating the task, choosing LLMs, prompt engineering, fine-tuning, and model deployment.
If this is right
- Healthcare professionals can identify medical tasks that align with LLM core capabilities before starting any work.
- Models can be selected according to the specific task, available data, performance needs, and interface type.
- Standard LLMs can be adapted to specialized medical tasks through prompt engineering strategies and fine-tuning methods.
- Deployment must incorporate regulatory compliance, ethical guidelines, and continuous monitoring for fairness and bias.
- The resulting use of LLMs supports clinical documentation, trial matching, and medical question answering in a structured manner.
Where Pith is reading between the lines
- Widespread use of the guide could create demand for shared templates or checklists tailored to common medical specialties.
- The workflow might be extended by adding explicit checkpoints for measuring output accuracy against medical ground truth.
- Adoption could influence how medical training programs introduce AI tools to clinicians without computer science backgrounds.
- The emphasis on continuous monitoring suggests future needs for automated tools that track bias drift in deployed medical LLMs.
Load-bearing premise
The general best practices for prompt engineering, fine-tuning, and deployment are sufficient to ensure safe and reliable use across diverse medical tasks without additional empirical testing specific to each application.
What would settle it
A controlled test in which following every step of the guide for a task such as matching patients to clinical trials still produces outputs that violate fairness criteria or regulatory standards would show the methodology is not sufficient.
Figures
read the original abstract
Frontier large language models (LLMs), such as GPT-5, Claude 4.5, Gemini 3, Llama 4, and DeepSeek-R1, represent a transformative class of AI tools capable of revolutionizing various aspects of healthcare by generating human-like responses across diverse contexts and adapting to novel tasks following human instructions. Their potential application spans a broad range of medical tasks, such as clinical documentation, matching patients to clinical trials, and answering medical questions. In this paper, we propose an actionable guideline to help healthcare professionals more effectively and efficiently utilize LLMs in their work, along with a set of best practices. The overall workflow consists of several main phases, including formulating the task, choosing LLMs, prompt engineering, fine-tuning, and model deployment. We start with the discussion of critical considerations in identifying medical tasks that align with the core capabilities of LLMs and selecting models based on the selected task and data, performance requirements, and model interface. We then review the strategies, such as prompt engineering and fine-tuning, to adapt standard LLMs to specialized medical tasks. Deployment considerations, including regulatory compliance, ethical guidelines, and continuous monitoring for fairness and bias, are also discussed. By providing a structured step-by-step methodology, this entry-level tutorial aims to equip healthcare professionals with the tools necessary to effectively integrate LLMs into clinical practice, ensuring that these powerful technologies are applied in a safe, reliable, and impactful manner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an entry-level workflow for healthcare professionals to use frontier LLMs (e.g., GPT-5, Claude 4.5) in medical tasks such as clinical documentation, trial matching, and question answering. The workflow comprises five phases—task formulation, model selection, prompt engineering, fine-tuning, and deployment with regulatory/ethical/bias-monitoring checks—and claims that following this structured methodology equips users to integrate LLMs 'in a safe, reliable, and impactful manner.'
Significance. If the outlined practices accurately synthesize current LLM usage guidelines, the paper could function as a concise introductory resource for non-AI specialists. However, it introduces no new methods, empirical results, or validated protocols, so its contribution is limited to compilation rather than advancing technical understanding or demonstrating safety in high-stakes medical settings.
major comments (3)
- [Abstract] Abstract: The central claim that the workflow 'ensures' safe and reliable use is unsupported. The manuscript contains no empirical validation, case studies, ablation experiments, or outcome metrics showing that the described phases reduce risks such as hallucination or bias in medical applications.
- [Deployment considerations] Deployment considerations section: The discussion of 'continuous monitoring for fairness and bias' is stated at a high level without concrete protocols, thresholds, or medical-task-specific examples (e.g., diagnostic error rates or fairness metrics for trial matching), leaving the sufficiency claim ungrounded.
- [Prompt engineering and fine-tuning] Prompt engineering and fine-tuning sections: General strategies are reviewed, yet the text provides no evidence or references demonstrating that these generic techniques transfer to medical tasks without per-application testing, contrary to the safety assurance in the abstract.
minor comments (2)
- [Abstract] The list of example models (GPT-5, Claude 4.5, etc.) should include version dates or access dates to reflect the rapidly changing landscape.
- Workflow diagram or numbered steps would improve clarity of the five-phase structure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight opportunities to better align the manuscript's claims with its scope as an entry-level tutorial rather than an empirical study. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] The central claim that the workflow 'ensures' safe and reliable use is unsupported. The manuscript contains no empirical validation, case studies, ablation experiments, or outcome metrics showing that the described phases reduce risks such as hallucination or bias in medical applications.
Authors: We agree the word 'ensures' is too strong and unsupported by new evidence in a compilation-style guide. We will revise the abstract to state that the workflow 'aims to support' safe and reliable use and will add an explicit disclaimer that the guide does not replace task-specific validation or regulatory review. revision: yes
-
Referee: [Deployment considerations] Deployment considerations section: The discussion of 'continuous monitoring for fairness and bias' is stated at a high level without concrete protocols, thresholds, or medical-task-specific examples (e.g., diagnostic error rates or fairness metrics for trial matching), leaving the sufficiency claim ungrounded.
Authors: The section is intentionally concise for an entry-level audience. We will add references to standard fairness metrics (e.g., demographic parity and equalized odds) and one illustrative example for trial matching, plus pointers to external resources for full protocols. This keeps the paper within its stated scope while addressing the request for concreteness. revision: partial
-
Referee: [Prompt engineering and fine-tuning] Prompt engineering and fine-tuning sections: General strategies are reviewed, yet the text provides no evidence or references demonstrating that these generic techniques transfer to medical tasks without per-application testing, contrary to the safety assurance in the abstract.
Authors: We will insert citations to medical-domain applications (e.g., prompt engineering for clinical QA and fine-tuning on datasets such as MIMIC-III or MedQA) to illustrate transfer. The deployment section already notes the necessity of per-application testing; we will cross-reference this more explicitly to avoid implying automatic safety. revision: yes
Circularity Check
Descriptive tutorial contains no derivations or predictions that reduce to inputs
full rationale
The paper is an entry-level workflow guide consisting of narrative sections on task formulation, model selection, prompt engineering, fine-tuning, and deployment considerations. It contains no equations, no fitted parameters, no predictions of quantitative outcomes, and no uniqueness theorems. All content is prescriptive advice drawn from general LLM literature; the central claim that the outlined phases equip users for safe use is a statement of intent rather than a derived result that collapses to its own inputs by construction. No self-citation is used to establish a load-bearing mathematical fact. The document is therefore self-contained as descriptive guidance with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Providing explanations; 2. Improving performance Hard to parse (mitigated by structured output) MedPrompt13 Retrieval-augmented generation A knowledge base or document collection
-
[2]
Providing up-to-date knowledge; 2. Reducing hallucinations Depends on the quality of the retrieved documents Almanac68, MedRAG54 Fine-tuning Data annotations and compute 1. Improving performance 2. Shorten the prompt Costly and resource intensive MEDITRON52, PMC-LlaMA51 Few-shot learning (FSL) As shown in Fig. 4a, FSL includes a few examples (i.e., “shots...
-
[3]
Effective prompt design can significantly enhance the performance of LLMs
Prompt engineering: Prompt engineering involves crafting inputs or "prompts" that guide large language models to generate desired outputs without changing their parameters. Effective prompt design can significantly enhance the performance of LLMs. 9. Few-shot learning: Few-shot learning refers to the ability of a model to learn a new task from a very limi...
-
[4]
HIPAA-compliance: HIPAA-compliant systems adhere to HIPAA (Health Insurance Portability and Accountability Act) regulations, ensuring they meet the required standards to protect patient health information. HIPAA sets national standards for the protection of health information in the United States. It ensures the privacy and security of individually identi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Capabilities of GPT-4 on Medical Challenge Problems
Brown, T., et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020). 6. Ouyang, L. et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 35, 27730-27744 (2022). 7. Mukherjee, P., Hou, B., Lanfredi, R.B. & Summers, R.M. Feasibility of Using the Privacy-preservin...
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[6]
Hu, X. et al. Interpretable medical image visual question answering via multi-modal relationship graph learning. Med. Image Anal. 97, 103279 (2024). 16. Jin, Q., et al. Matching Patients to Clinical Trials with Large Language Models. arXiv (2024). 17. Wong, C., et al. Scaling clinical trial matching using large language models: A case study in oncology. M...
-
[7]
Hu, Y. et al. Improving large language models for clinical named entity recognition via prompt engineering. J. Am. Med. Inform. Assoc. 31, 1812-1820 (2024). 26. Wang, L. et al. Prompt engineering in consistency and reliability with the evidence-based guideline for LLMs. NPJ Digit. Med 7, 41 (2024). 27. Jin, Q. et al. Hidden flaws behind expert-level accur...
work page internal anchor Pith review arXiv 2024
-
[8]
Peng, Y., Rousseau, J.F., Shortliffe, E.H. & Weng, C. AI-generated text may have a role in evidence-based medicine. Nat. Med. 29, 1593–1594 (2023). 36. Papineni, K., Roukos, S., Ward, T. & Zhu, W.-J. Bleu: a method for automatic evaluation of machine translation. Proc. Assoc. Comput. Linguist. 311–318 (2002). 37. Lin, C.-Y. Rouge: A package for automatic ...
work page 2023
-
[9]
Wang, H., Gao, C., Dantona, C., Hull, B. & Sun, J. DRG-LLaMA: tuning LLaMA model to predict diagnosis-related group for hospitalized patients. NPJ Digit. Med. 7, 16 (2024). 45. Dagdelen, J., et al. Structured information extraction from scientific text with large language models. Nat. Commun. 15, 1418 (2024). 46. Topol, E.J. As artificial intelligence goe...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Xiong, G., Jin, Q., Lu, Z. & Zhang, A. Benchmarking retrieval-augmented generation for medicine. Findings of the Association for Computational Linguistics: ACL 6233-6251 (2024). 55. Shi, W. et al. MedAdapter: Efficient Test-Time Adaptation of Large Language Models towards Medical Reasoning. arXiv preprint arXiv:2405.03000 (2024). 56. Pal, A. & Sankarasubb...
-
[11]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Ji, Z. et al. Survey of hallucination in natural language generation. ACM Computing Surveys 55, 1-38 (2023). 72. Wang, X. et al. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022). 73. Hou, W. & Ji, Z. Assessing GPT-4 for cell type annotation in single-cell RNA-seq analysis. Nat. Methods (2024)....
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Zhang, K. et al. A generalist vision-language foundation model for diverse biomedical tasks. Nat. Med. (2024). 83. Hu, E.J., et al. LoRA: Low-Rank Adaptation of Large Language Models. International Conference on Learning Representations (2021). 84. Dettmers, T., et al. Qlora: Efficient finetuning of quantized llms. Adv. Neural Inf. Process. Syst. 36 (2024...
-
[13]
TrustLLM: Trustworthiness in Large Language Models
Omiye, J.A., Lester, J.C., Spichak, S., Rotemberg, V. & Daneshjou, R. Large language models propagate race-based medicine. NPJ Digit. Med. 6, 195 (2023). 93. Zhang, G. et al. Leveraging generative AI for clinical evidence synthesis needs to ensure trustworthiness. J Biomed Inform 153, 104640 (2024). 94. Sun, L. et al. Trustllm: Trustworthiness in large la...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.