EPS: Efficient Patch Sampling for Video Overfitting in Deep Super-Resolution Model Training
Pith reviewed 2026-05-23 16:44 UTC · model grok-4.3
The pith
An efficient patch sampling method uses DCT features to select only high-complexity patches for training overfitted video super-resolution models, cutting the number of patches by 75 to 92 percent while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
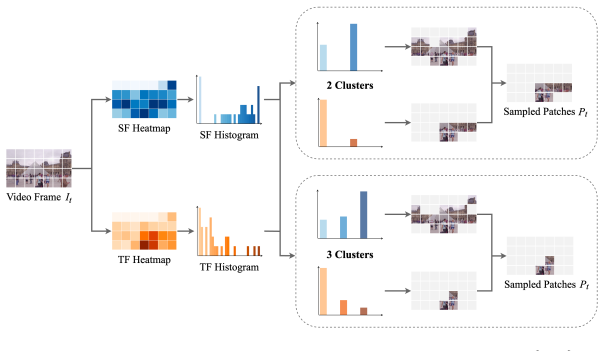
EPS computes two low-complexity DCT-based spatial-temporal features to score the complexity of each patch directly from video frames. It then analyzes the histogram distribution of these scores to form clusters and selects training patches exclusively from the cluster with the highest spatial-temporal information. The number of sampled patches is made adaptive to video content. The approach reduces training patches by 75.00% to 91.69% depending on resolution and cluster count, speeds sampling by up to 82.1x versus EMT, and preserves high video quality for the overfitted SR model.
What carries the argument
Two low-complexity DCT-based spatial-temporal features for patch complexity scoring, followed by histogram clustering to select patches only from the highest-information cluster.
If this is right
- Training an overfitted SR model for video delivery requires far fewer patches when limited to the highest-complexity cluster.
- Patch sampling time drops by as much as 82 times compared with earlier techniques such as EMT.
- The reduction in patch count scales with video resolution and the number of clusters chosen.
- High reconstruction quality is maintained even though 75 to 92 percent of possible patches are discarded.
- Training becomes efficient enough to support practical per-video model transmission in bandwidth-limited systems.
Where Pith is reading between the lines
- The same highest-cluster selection could reduce data needs for other per-video overfitting tasks such as denoising or frame interpolation.
- If the highest-complexity patches prove sufficient across content types, similar low-cost feature clustering might cut training data in broader DNN applications.
- Combining the DCT scores with additional cheap signals such as simple motion estimates could sharpen the separation between clusters.
- Experiments on a wider variety of video genres would show whether some scenes still require patches from lower clusters to reach target quality.
Load-bearing premise
That patches selected solely from the highest spatial-temporal DCT feature cluster contain enough information to train an overfitted super-resolution model without quality loss from excluding lower-complexity patches.
What would settle it
A side-by-side training run showing that an SR model trained on the EPS-selected high-complexity patches produces lower PSNR or visible quality loss on test video frames compared with a model trained on the full set of patches.
Figures





read the original abstract
Leveraging the overfitting property of deep neural networks (DNNs) is trending in video delivery systems to enhance video quality within bandwidth limits. Existing approaches transmit overfitted super-resolution (SR) model streams for low-resolution (LR) bitstreams, which are used to reconstruct high-resolution (HR) videos at the decoder. Although these approaches show promising results, the huge computational costs of training a large number of video frames limit their practical applications. To overcome this challenge, we propose an efficient patch sampling method named EPS for video SR network overfitting, which identifies the most valuable training patches from video frames. To this end, we first present two low-complexity Discrete Cosine Transform (DCT)-based spatial-temporal features to measure the complexity score of each patch directly. By analyzing the histogram distribution of these features, we then categorize all possible patches into different clusters and select training patches from the cluster with the highest spatial-temporal information. The number of sampled patches is adaptive based on the video content, addressing the trade-off between training complexity and efficiency. Our method reduces the number of training patches by 75.00% to 91.69%, depending on the resolution and number of clusters, while preserving high video quality and greatly improving training efficiency. Our method speeds up patch sampling by up to 82.1x compared to the state-of-the-art patch sampling technique (EMT).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EPS, an efficient patch sampling method for overfitting deep super-resolution networks on video. It computes low-complexity DCT-based spatial-temporal features per patch, analyzes their histogram to form clusters, and adaptively selects training patches only from the highest-complexity cluster. The central claims are a 75.00–91.69% reduction in training patches (resolution- and cluster-dependent) and up to 82.1× speedup versus EMT while preserving video quality.
Significance. If the empirical claims hold, the work would meaningfully lower the training cost barrier for per-video overfitting SR in bandwidth-constrained delivery pipelines. The reliance on standard DCT and clustering makes the approach simple to implement and potentially reproducible.
major comments (2)
- [Abstract] Abstract: quantitative claims of 75.00–91.69% patch reduction, 82.1× sampling speedup, and quality preservation are stated without any accompanying experimental data, tables, figures, baselines (including EMT), quality metrics (PSNR/SSIM/VMAF), or error bars. The central empirical contribution therefore cannot be evaluated.
- [Abstract] Abstract / method description: the claim that selecting solely from the highest-DCT cluster suffices for quality-preserving overfitting is presented as the key design choice, yet no ablation, sensitivity analysis, or comparison against lower-cluster inclusion is referenced. This is load-bearing for the reduction claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment below with point-by-point responses and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: quantitative claims of 75.00–91.69% patch reduction, 82.1× sampling speedup, and quality preservation are stated without any accompanying experimental data, tables, figures, baselines (including EMT), quality metrics (PSNR/SSIM/VMAF), or error bars. The central empirical contribution therefore cannot be evaluated.
Authors: The abstract is intended as a concise summary of results that are fully detailed and supported in the experimental sections of the manuscript (Sections 4 and 5). These sections contain the requested elements: tables and figures reporting the 75.00–91.69% patch reductions (resolution- and cluster-dependent), up to 82.1× speedup versus the EMT baseline, quality metrics including PSNR/SSIM/VMAF, and associated error bars or variance measures. We agree that the abstract could better signpost these supporting results and will revise it to include brief references to the evaluation metrics and key experimental outcomes. revision: yes
-
Referee: [Abstract] Abstract / method description: the claim that selecting solely from the highest-DCT cluster suffices for quality-preserving overfitting is presented as the key design choice, yet no ablation, sensitivity analysis, or comparison against lower-cluster inclusion is referenced. This is load-bearing for the reduction claim.
Authors: The design choice to sample exclusively from the highest-DCT cluster is justified in the manuscript by the DCT-based spatial-temporal feature analysis and histogram clustering, which identify these patches as containing the highest information content most relevant for effective SR model overfitting. While the rationale is explained, we acknowledge that the manuscript does not include an explicit ablation or sensitivity study on including patches from lower-complexity clusters. We will add such an ablation study in the revised manuscript to quantify the trade-offs in quality preservation versus training efficiency. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines EPS via explicit DCT-based spatial-temporal features, histogram clustering, and selection from the highest-complexity cluster; these steps are standard signal-processing operations with no reduction to self-definition or fitted parameters. Quality preservation is asserted only via reported empirical measurements on video content, not by construction. No self-citation chains, uniqueness theorems, or ansatzes appear in the provided text. The central claim (patch reduction while maintaining quality) therefore rests on independent experimental content rather than circular input-output equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DCT-based spatial-temporal features accurately measure the complexity and value of patches for training super-resolution models
Reference graph
Works this paper leans on
-
[1]
A Survey on Energy Consumption and Environmental Impact of Video Streaming
Samira Afzal, Narges Mehran, Zoha Azimi Ourimi, Farzad Tashtarian, Hadi Amirpour, Radu Prodan, and Christian Tim- merer. A Survey on Energy Consumption and Environmental Impact of Video Streaming. 2024. Publisher: arXiv Version Number: 1. 2
work page 2024
-
[2]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. In The IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR) Workshops, July 2017. 6
work page 2017
-
[3]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. In2017 IEEE Conference on Computer Vision and Pattern Recogni- tion Workshops (CVPRW), pages 1122–1131, 2017. 6
work page 2017
-
[4]
Fast, accurate, and lightweight super-resolution with cascading residual network
Namhyuk Ahn, Byungkon Kang, and Kyung-Ah Sohn. Fast, accurate, and lightweight super-resolution with cascading residual network. In Computer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part X , page 256–272, Berlin, Heidel- berg, 2018. Springer-Verlag. 5
work page 2018
-
[5]
DeepStream: Video Streaming Enhancements using Compressed Deep Neural Networks
Hadi Amirpour, Mohammad Ghanbari, and Christian Tim- merer. DeepStream: Video Streaming Enhancements using Compressed Deep Neural Networks. IEEE Transactions on Circuits and Systems for Video Technology, pages 1–1, 2022. 2, 3
work page 2022
-
[6]
Benjamin Bross, Ye-Kui Wang, Yan Ye, Shan Liu, Jianle Chen, Gary J. Sullivan, and Jens-Rainer Ohm. Overview of the Versatile Video Coding (VVC) Standard and its Applica- tions. IEEE Transactions on Circuits and Systems for Video Technology, 31(10):3736–3764, Oct. 2021. 1
work page 2021
-
[7]
Deepcoder: A deep neural network based video compression
Tong Chen, Haojie Liu, Qiu Shen, Tao Yue, Xun Cao, and Zhan Ma. Deepcoder: A deep neural network based video compression. In 2017 IEEE Visual Communications and Im- age Processing (VCIP), pages 1–4, 2017. 2
work page 2017
-
[8]
An overview of coding tools in av1: the first video codec from the alliance for open media
Yue Chen, Debargha Mukherjee, Jingning Han, Adrian Grange, Yaowu Xu, Sarah Parker, Cheng Chen, Hui Su, Ur- vang Joshi, Ching-Han Chiang, and et al. An overview of coding tools in av1: the first video codec from the alliance for open media. APSIPA Transactions on Signal and Infor- mation Processing, 9:e6, 2020. 1
work page 2020
-
[9]
Acceler- ating the super-resolution convolutional neural network
Chao Dong, Chen Change Loy, and Xiaoou Tang. Acceler- ating the super-resolution convolutional neural network. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling, edi- tors, Computer Vision – ECCV 2016, pages 391–407, Cham,
work page 2016
-
[10]
Springer International Publishing. 5
-
[11]
A. Dosovitskiy, P. Fischer, E. Ilg, P. Hausser, C. Hazirbas, V . Golkov, P. Smagt, D. Cremers, and T. Brox. Flownet: Learning optical flow with convolutional networks. In 2015 IEEE International Conference on Computer Vision (ICCV), pages 2758–2766, Los Alamitos, CA, USA, dec 2015. IEEE Computer Society. 2
work page 2015
-
[12]
A. Habibian, T. Rozendaal, J. Tomczak, and T. Cohen. Video compression with rate-distortion autoencoders. In 2019 IEEE/CVF International Conference on Computer Vi- sion (ICCV) , pages 7032–7041, Los Alamitos, CA, USA, nov 2019. IEEE Computer Society. 2
work page 2019
- [13]
-
[14]
IEEE Computer Society. 2, 3
-
[15]
Neural-enhanced live streaming: Improv- ing live video ingest via online learning
Jaehong Kim, Youngmok Jung, Hyunho Yeo, Juncheol Ye, and Dongsu Han. Neural-enhanced live streaming: Improv- ing live video ingest via online learning. In Proceedings of the Annual conference of the ACM Special Interest Group on Data Communication on the applications, technologies, architectures, and protocols for computer communication , pages 107–125, 2...
work page 2020
-
[16]
A new energy function for segmentation and compression
Michael King, Zinovi Tauber, and Ze-Nian Li. A new energy function for segmentation and compression. In 2007 IEEE International Conference on Multimedia and Expo , pages 1647–1650, 2007. 3
work page 2007
-
[17]
ClassSR: A general framework to accelerate super- resolution networks by data characteristic
Xiangtao Kong, Hengyuan Zhao, Yu Qiao, and Chao Dong. ClassSR: A general framework to accelerate super- resolution networks by data characteristic. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12016–12025, 2021. 3
work page 2021
-
[18]
G. Li, J. Ji, M. Qin, W. Niu, B. Ren, F. Afghah, L. Guo, and X. Ma. Towards high-quality and efficient video super-resolution via spatial-temporal data overfitting. In 2023 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 10259–10269, Los Alami- tos, CA, USA, jun 2023. IEEE Computer Society. 3
work page 2023
-
[19]
Efficient meta-tuning for content-aware neural video delivery
Xiaoqi Li, Jiaming Liu, Shizun Wang, Cheng Lyu, Ming Lu, Yurong Chen, Anbang Yao, Yandong Guo, and Shanghang Zhang. Efficient meta-tuning for content-aware neural video delivery. In Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceed- ings, Part XVIII , page 308–324, Berlin, Heidelberg, 2022. Springer-Verl...
work page 2022
-
[20]
Overfitting the data: Compact neu- ral video delivery via content-aware feature modulation
Jiaming Liu, Ming Lu, Kaixin Chen, Xiaoqi Li, Shizun Wang, Zhaoqing Wang, Enhua Wu, Yurong Chen, Chuang Zhang, and Ming Wu. Overfitting the data: Compact neu- ral video delivery via content-aware feature modulation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4631–4640, 2021. 2
work page 2021
-
[21]
Content adaptive and error propagation aware deep video compression
Guo Lu, Chunlei Cai, Xiaoyun Zhang, Li Chen, Wanli Ouyang, Dong Xu, and Zhiyong Gao. Content adaptive and error propagation aware deep video compression. In Com- puter Vision–ECCV 2020: 16th European Conference, Glas- gow, UK, August 23–28, 2020, Proceedings, Part II 16, pages 456–472. Springer, 2020. 2
work page 2020
-
[22]
Dvc: An end-to-end deep video com- pression framework
Guo Lu, Wanli Ouyang, Dong Xu, Xiaoyun Zhang, Chunlei Cai, and Zhiyong Gao. Dvc: An end-to-end deep video com- pression framework. In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 11006–11015, 2019. 2 9
work page 2019
-
[23]
VCA: Video Complexity Analyzer
Vignesh V Menon, Christian Feldmann, Hadi Amirpour, Mohammad Ghanbari, and Christian Timmerer. VCA: Video Complexity Analyzer. In Proceedings of the 13th ACM Mul- timedia Systems Conference, pages 259–264, June 2022. 3
work page 2022
-
[24]
Vmaf reproducibility: Validating a perceptual practical video quality metric
Reza Rassool. Vmaf reproducibility: Validating a perceptual practical video quality metric. In 2017 IEEE International Symposium on Broadband Multimedia Systems and Broad- casting (BMSB), pages 1–2, 2017. 5
work page 2017
-
[25]
Oren Rippel, Sanjay Nair, Carissa Lew, Steve Branson, Alexander G Anderson, and Lubomir Bourdev. Learned video compression. In Proceedings of the IEEE/CVF Inter- national Conference on Computer Vision, pages 3454–3463,
-
[26]
W. Shi, J. Caballero, F. Huszar, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang. Real-time single im- age and video super-resolution using an efficient sub-pixel convolutional neural network. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1874–1883, Los Alamitos, CA, USA, jun 2016. IEEE Com- puter Society. 5
work page 2016
-
[27]
Adapool: Expo- nential adaptive pooling for information-retaining downsam- pling
Alexandros Stergiou and Ronald Poppe. Adapool: Expo- nential adaptive pooling for information-retaining downsam- pling. IEEE Transactions on Image Processing, 32:251–266,
-
[28]
An empirical study of example forget- ting during deep neural network learning
Mariya Toneva, Alessandro Sordoni, Remi Tachet des Combes, Adam Trischler, Yoshua Bengio, and Geof- frey J Gordon. An empirical study of example forget- ting during deep neural network learning. arXiv preprint arXiv:1812.05159, 2018. 3
-
[29]
Tongzhou Wang, Jun-Yan Zhu, Antonio Torralba, and Alexei A Efros. Dataset distillation. arXiv preprint arXiv:1811.10959, 2018. 6
work page internal anchor Pith review arXiv 2018
-
[30]
CAMixerSR: Only Details Need More” Attention”
Yan Wang, Yi Liu, Shijie Zhao, Junlin Li, and Li Zhang. CAMixerSR: Only Details Need More” Attention”. In Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 25837–25846, 2024. 3
work page 2024
-
[31]
Video compression through image interpolation
Chao-Yuan Wu, Nayan Singhal, and Philipp Kr ¨ahenb¨uhl. Video compression through image interpolation. In ECCV,
-
[32]
Hyunho Yeo, Sunghyun Do, and Dongsu Han. How will deep learning change internet video delivery? In Proceed- ings of the 16th ACM Workshop on Hot Topics in Networks, HotNets ’17, page 57–64, New York, NY , USA, 2017. Asso- ciation for Computing Machinery. 6, 7
work page 2017
-
[33]
Neural adaptive content-aware internet video delivery
Hyunho Yeo, Youngmok Jung, Jaehong Kim, Jinwoo Shin, and Dongsu Han. Neural adaptive content-aware internet video delivery. In 13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), pages 645– 661, 2018. 2, 3, 6, 7
work page 2018
-
[34]
Wide Activation for Efficient and Accurate Image Super-Resolution
Jiahui Yu, Yuchen Fan, Jianchao Yang, Ning Xu, Xinchao Wang, and Thomas S Huang. Wide activation for effi- cient and accurate image super-resolution. arXiv preprint arXiv:1808.08718, 2018. 5
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Mest: Accurate and fast memory-economic sparse training framework on the edge
Geng Yuan, Xiaolong Ma, Wei Niu, Zhengang Li, Zhenglun Kong, Ning Liu, Yifan Gong, Zheng Zhan, Chaoyang He, Qing Jin, et al. Mest: Accurate and fast memory-economic sparse training framework on the edge. Advances in Neural Information Processing Systems, 34:20838–20850, 2021. 3
work page 2021
-
[36]
Galaxy: Graph-based active learning at the extreme
Jifan Zhang, Julian Katz-Samuels, and Robert Nowak. Galaxy: Graph-based active learning at the extreme. In In- ternational Conference on Machine Learning, pages 26223– 26238. PMLR, 2022. 6 10
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.