Scene-Action Prompt Fusion for Coherent Text-to-Video Storytelling
Pith reviewed 2026-05-23 00:03 UTC · model grok-4.3
The pith
Scene-action prompt fusion produces temporally consistent long-form videos from discrete text prompts without extra training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
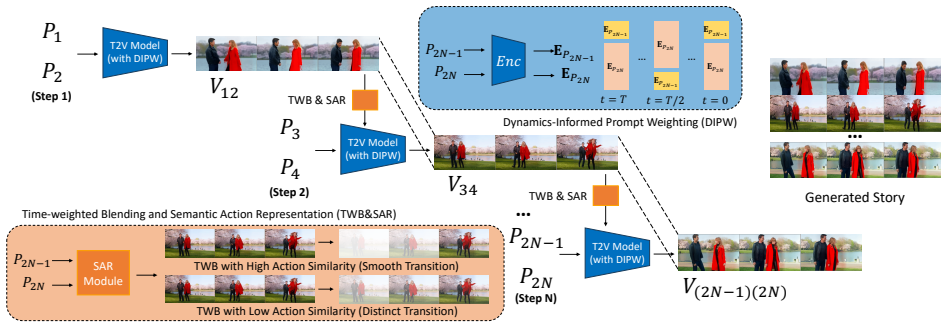
The method integrates three components—bidirectional time-weighted latent blending for temporal consistency, dynamics-informed prompt weighting that balances scene and action prompts based on CLIP alignment, narrative progression, and temporal smoothness, and semantic action representations that modulate transitions by action similarity—to enable fluid video narratives from discrete text prompts that reflect both scene context and action dynamics.
What carries the argument
Dynamics-informed prompt weighting (DIPW) mechanism that adaptively balances scene and action prompts at each diffusion timestep using CLIP-based alignment combined with narrative progression and temporal smoothness signals.
If this is right
- Latent-space blending with bidirectional temporal constraints prevents abrupt transitions between video segments.
- The method produces long-form videos that maintain semantic consistency and scene-action continuity.
- No additional training is required to achieve these results on top of existing diffusion models.
- Experiments show significant outperformance over baselines in temporal consistency and visual quality.
Where Pith is reading between the lines
- The blending strategy could be tested on other sequential generation tasks like multi-shot image sequences.
- If the weighting signals generalize, the approach might reduce reliance on fine-tuning for domain-specific video outputs.
- Extending the semantic action representation to handle more complex narrative structures could address longer stories.
Load-bearing premise
The dynamics-informed prompt weighting can reliably balance scene and action prompts at each step to enforce consistency across video segments.
What would settle it
Generated videos that exhibit abrupt scene changes, inconsistent actions, or loss of narrative progression when the prompt weighting is applied would show the balancing mechanism does not hold.
Figures



read the original abstract
Generating coherent long-form video sequences from discrete text prompts remains challenging due to difficulties in maintaining temporal coherence, semantic consistency, and scene-action continuity across segments. We propose a novel storytelling framework that integrates scene and action prompts through dynamics-inspired prompt mixing. Our approach combines three key components: (i) a bidirectional time-weighted latent blending strategy that enforces temporal consistency between consecutive video segments, (ii) a dynamics-informed prompt weighting (DIPW) mechanism that adaptively balances scene and action prompts at each diffusion timestep based on CLIP-based alignment, narrative progression, and temporal smoothness, and (iii) a semantic action representation that encodes high-level action semantics to modulate transitions according to action similarity. Latent-space blending preserves spatial coherence within scenes, while time-weighted blending introduces bidirectional temporal constraints to prevent abrupt transitions. Together, these components enable fluid and coherent video narratives that faithfully reflect both scene context and action dynamics. Extensive experiments demonstrate that our method significantly outperforms baselines, producing temporally consistent and visually compelling long-form videos without any additional training, thereby bridging the gap between short clips and extended text-driven video storytelling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to solve the problem of generating coherent long-form video sequences from discrete text prompts by proposing a framework that integrates scene and action prompts through dynamics-inspired prompt mixing. The method consists of three components: bidirectional time-weighted latent blending for temporal consistency, dynamics-informed prompt weighting (DIPW) that adaptively balances prompts using CLIP-based alignment, narrative progression, and temporal smoothness, and a semantic action representation for modulating transitions. It asserts that this enables fluid video narratives and that extensive experiments show significant outperformance over baselines without any additional training.
Significance. If the claims are substantiated, this would represent a meaningful advance in text-to-video generation by addressing temporal coherence and scene-action continuity in extended sequences, a major hurdle in the field. The training-free nature of the approach is a notable practical advantage that could facilitate broader adoption in storytelling applications.
major comments (2)
- [Abstract] Abstract: The central claim that 'Extensive experiments demonstrate that our method significantly outperforms baselines, producing temporally consistent and visually compelling long-form videos' is not accompanied by any quantitative metrics, baseline descriptions, ablation studies, or experimental details. This absence directly undermines the ability to assess the validity of the outperformance assertion, which is load-bearing for the paper's contribution.
- [Abstract] Abstract: The DIPW mechanism is presented as adaptively balancing scene and action prompts based on CLIP-based alignment, narrative progression, and temporal smoothness signals, but no mathematical formulation, algorithm, or specific implementation details are provided. This makes it impossible to evaluate whether the mechanism can reliably enforce consistency as claimed.
minor comments (1)
- The abstract uses several technical terms (e.g., 'bidirectional time-weighted latent blending', 'dynamics-informed prompt weighting') without brief explanations, which may reduce accessibility for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for these detailed comments on the abstract. We agree that the abstract would benefit from additional substantiation of the experimental claims and a higher-level reference to the DIPW formulation to improve readability and verifiability. We address each point below and will revise the abstract in the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Extensive experiments demonstrate that our method significantly outperforms baselines, producing temporally consistent and visually compelling long-form videos' is not accompanied by any quantitative metrics, baseline descriptions, ablation studies, or experimental details. This absence directly undermines the ability to assess the validity of the outperformance assertion, which is load-bearing for the paper's contribution.
Authors: We acknowledge that the abstract presents the performance claim at a summary level without metrics or experimental specifics. The full manuscript contains a dedicated Experiments section with quantitative metrics (e.g., temporal consistency scores, CLIP-based alignment measures), baseline comparisons, and ablation studies. To address the concern, we will revise the abstract to include a brief reference to key quantitative outcomes and direct readers to the Experiments section. revision: yes
-
Referee: [Abstract] Abstract: The DIPW mechanism is presented as adaptively balancing scene and action prompts based on CLIP-based alignment, narrative progression, and temporal smoothness signals, but no mathematical formulation, algorithm, or specific implementation details are provided. This makes it impossible to evaluate whether the mechanism can reliably enforce consistency as claimed.
Authors: We agree the abstract describes DIPW at a conceptual level. The manuscript provides the full mathematical formulation (including the adaptive weighting function combining CLIP similarity, narrative progression, and temporal smoothness terms) and algorithmic details in the Methods section. We will revise the abstract to incorporate a concise reference to the core weighting equation and a pointer to the detailed derivation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical assembly of three components (bidirectional time-weighted latent blending, DIPW mechanism, semantic action representation) whose performance claims rest on experimental outperformance rather than any derivation, equation, or prediction that reduces to fitted inputs or self-citations by construction. No equations, uniqueness theorems, ansatzes, or self-referential predictions appear in the provided text; the central claims are externally falsifiable via benchmarks and do not invoke load-bearing self-citations. This is the expected non-finding for a methods paper whose contributions are architectural and empirical.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Character-Centered Dialogue Generation from Scene-Level Prompts
A training-free framework generates expressive, character-grounded dialogue and speech from scene prompts using vision-language encoders, LLMs, and a recursive narrative memory bank for cross-scene consistency.
Reference graph
Works this paper leans on
-
[1]
Mochi-1 preview.https://huggingface
Genmo AI. Mochi-1 preview.https://huggingface. co/genmo/mochi-1-preview, 2024. 1, 3, 6
work page 2024
-
[2]
Lumiere: A space-time diffu- sion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Her- rmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. Lumiere: A space-time diffu- sion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 3
work page 2024
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
8 Align your latents: High-resolution video synthesis with la- tent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dock- horn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. 8 Align your latents: High-resolution video synthesis with la- tent diffusion models. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22563–22575, 2023. 3
work page 2023
-
[5]
Stream- ing video diffusion: Online video editing with diffusion models, 2024
Feng Chen, Zhen Yang, Bohan Zhuang, and Qi Wu. Stream- ing video diffusion: Online video editing with diffusion models, 2024. 1
work page 2024
-
[6]
Control-a-video: Controllable text-to-video generation with diffusion models
Weifeng Chen, Yatai Ji, Jie Wu, Hefeng Wu, Pan Xie, Jiashi Li, Xin Xia, Xuefeng Xiao, and Liang Lin. Control-a-video: Controllable text-to-video generation with diffusion models. arXiv e-prints, pages arXiv–2305, 2023. 3
work page 2023
-
[7]
Seine: Short-to-long video diffu- sion model for generative transition and prediction
Xinyuan Chen, Yaohui Wang, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Seine: Short-to-long video diffu- sion model for generative transition and prediction. InThe Twelfth International Conference on Learning Representa- tions, 2023. 3
work page 2023
-
[8]
Mengyu Chu, You Xie, Jonas Mayer, Laura Leal-Taix ´e, and Nils Thuerey. Learning temporal coherence via self- supervision for gan-based video generation.ACM Transac- tions on Graphics (TOG), 39(4):75–1, 2020. 1
work page 2020
-
[9]
Dysen-vdm: Empowering dynamics-aware text-to-video diffusion with llms
Hao Fei, Shengqiong Wu, Wei Ji, Hanwang Zhang, and Tat-Seng Chua. Dysen-vdm: Empowering dynamics-aware text-to-video diffusion with llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7641–7653, 2024. 3
work page 2024
-
[10]
Preserve your own correlation: A noise prior for video diffusion models
Songwei Ge, Seungjun Nah, Guilin Liu, Tyler Poon, Andrew Tao, Bryan Catanzaro, David Jacobs, Jia-Bin Huang, Ming- Yu Liu, and Yogesh Balaji. Preserve your own correlation: A noise prior for video diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 22930–22941, 2023
work page 2023
-
[11]
Emu video: Factorizing text-to-video generation by explicit image conditioning
Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Du- val, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. Emu video: Factoriz- ing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709, 2023. 3
-
[12]
Huiguo He, Huan Yang, Zixi Tuo, Yuan Zhou, Qiuyue Wang, Yuhang Zhang, Zeyu Liu, Wenhao Huang, Hongyang Chao, and Jian Yin. Dreamstory: Open-domain story visualiza- tion by llm-guided multi-subject consistent diffusion.arXiv preprint arXiv:2407.12899, 2024. 1, 3
-
[13]
Latent Video Diffusion Models for High-Fidelity Long Video Generation
Yingqing He, Tianyu Yang, Yong Zhang, Ying Shan, and Qifeng Chen. Latent video diffusion models for high-fidelity long video generation.arXiv preprint arXiv:2211.13221,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Yingqing He, Menghan Xia, Haoxin Chen, Xiaodong Cun, Yuan Gong, Jinbo Xing, Yong Zhang, Xintao Wang, Chao Weng, Ying Shan, et al. Animate-a-story: Storytelling with retrieval-augmented video generation.arXiv preprint arXiv:2307.06940, 2023. 1, 3
-
[15]
Roberto Henschel, Levon Khachatryan, Daniil Hayrapetyan, Hayk Poghosyan, Vahram Tadevosyan, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Streamingt2v: Con- sistent, dynamic, and extendable long video generation from text.arXiv preprint arXiv:2403.14773, 2024. 3
-
[16]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 6
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[17]
CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
Wenyi Hong, Ming Ding, Wendi Zheng, Xinghan Liu, and Jie Tang. Cogvideo: Large-scale pretraining for text-to-video generation via transformers.arXiv preprint arXiv:2205.15868, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Text2video-zero: Text- to-image diffusion models are zero-shot video generators
Levon Khachatryan, Andranik Movsisyan, Vahram Tade- vosyan, Roberto Henschel, Zhangyang Wang, Shant Navasardyan, and Humphrey Shi. Text2video-zero: Text- to-image diffusion models are zero-shot video generators. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15954–15964, 2023. 3
work page 2023
-
[19]
Dahun Kim, Sanghyun Woo, Joon-Young Lee, and In So Kweon. Deep video inpainting. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5792–5801, 2019. 1
work page 2019
-
[20]
Divya Kothandaraman, Ming Lin, and Dinesh Manocha. Prompt mixing in diffusion models using the black scholes algorithm.arXiv preprint arXiv:2405.13685, 2024. 6
-
[21]
Storygan: A sequential conditional gan for story vi- sualization
Yitong Li, Zhe Gan, Yelong Shen, Jingjing Liu, Yu Cheng, Yuexin Wu, Lawrence Carin, David Carlson, and Jianfeng Gao. Storygan: A sequential conditional gan for story vi- sualization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6329–6338,
-
[22]
Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning
Han Lin, Abhay Zala, Jaemin Cho, and Mohit Bansal. Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning.arXiv preprint arXiv:2309.15091,
-
[23]
Adyasha Maharana, Darryl Hannan, and Mohit Bansal. Im- proving generation and evaluation of visual stories via se- mantic consistency.arXiv preprint arXiv:2105.10026, 2021. 1
-
[24]
Video frame in- terpolation via adaptive separable convolution
Simon Niklaus, Long Mai, and Feng Liu. Video frame in- terpolation via adaptive separable convolution. InProceed- ings of the IEEE international conference on computer vi- sion, pages 261–270, 2017. 1
work page 2017
-
[25]
Mevg: Multi-event video generation with text-to-video models
Gyeongrok Oh, Jaehwan Jeong, Sieun Kim, Wonmin Byeon, Jinkyu Kim, Sungwoong Kim, and Sangpil Kim. Mevg: Multi-event video generation with text-to-video models. In European Conference on Computer Vision, pages 401–418. Springer, 2024. 1, 3
work page 2024
-
[26]
Video generation models as world simula- tors.https : / / openai
OpenAI. Video generation models as world simula- tors.https : / / openai . com / index / video - generation - models - as - world - simulators/, 2024
work page 2024
-
[27]
Sampson, Shikai Li, Simone Parmeggiani, Steve Fine, Tara Fowler, Vladan Petro- vic, and Yuming Du
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih- Yao Ma, Ching-Yao Chuang, David Yan, Dhruv Choudhary, Dingkang Wang, Geet Sethi, Guan Pang, Haoyu Ma, Ishan Misra, Ji Hou, Jialiang Wang, Kiran Jagadeesh, Kunpeng Li, Luxin Zhang, Mannat Singh, Mary Williamson, Matt Le, Matthew Yu, Mitesh Kumar Sin...
work page 2025
-
[28]
Hier- archical spatio-temporal decoupling for text-to-video gener- ation
Zhiwu Qing, Shiwei Zhang, Jiayu Wang, Xiang Wang, Yujie Wei, Yingya Zhang, Changxin Gao, and Nong Sang. Hier- archical spatio-temporal decoupling for text-to-video gener- ation. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 6635–6645, 2024
work page 2024
-
[29]
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xin- tao Wang, Ying Shan, and Ziwei Liu. Freenoise: Tuning-free longer video diffusion via noise rescheduling.arXiv preprint arXiv:2310.15169, 2023. 1
-
[30]
Abhishek Sharma, Adams Yu, Ali Razavi, Andeep Toor, An- drew Pierson, Ankush Gupta, Austin Waters, A¨aron van den Oord, Daniel Tanis, Dumitru Erhan, Eric Lau, Eleni Shaw, Gabe Barth-Maron, Greg Shaw, Han Zhang, Henna Nand- wani, Hernan Moraldo, Hyunjik Kim, Irina Blok, Jakob Bauer, Jeff Donahue, Junyoung Chung, Kory Mathewson, Kurtis David, Lasse Espeholt...
work page 2024
-
[31]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792,
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Unsupervised learning of video representations using lstms
Nitish Srivastava, Elman Mansimov, and Ruslan Salakhudi- nov. Unsupervised learning of video representations using lstms. InInternational conference on machine learning, pages 843–852. PMLR, 2015. 1
work page 2015
-
[33]
Veo-Team, :, Agrim Gupta, Ali Razavi, Andeep Toor, Ankush Gupta, Dumitru Erhan, Eleni Shaw, Eric Lau, Frank Belletti, Gabe Barth-Maron, Gregory Shaw, Hakan Erdo- gan, Hakim Sidahmed, Henna Nandwani, Hernan Moraldo, Hyunjik Kim, Irina Blok, Jeff Donahue, Jos ´e Lezama, Kory Mathewson, Kurtis David, Matthieu Kim Lorrain, Marc van Zee, Medhini Narasimhan, Mi...
work page 2024
-
[34]
Phenaki: Variable Length Video Generation From Open Domain Textual Description
Ruben Villegas, Mohammad Babaeizadeh, Pieter-Jan Kin- dermans, Hernan Moraldo, Han Zhang, Mohammad Taghi Saffar, Santiago Castro, Julius Kunze, and Dumitru Erhan. Phenaki: Variable length video generation from open domain textual description.arXiv preprint arXiv:2210.02399, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
Fu-Yun Wang, Wenshuo Chen, Guanglu Song, Han-Jia Ye, Yu Liu, and Hongsheng Li. Gen-l-video: Multi-text to long video generation via temporal co-denoising.arXiv preprint arXiv:2305.18264, 2023. 1
-
[36]
ModelScope Text-to-Video Technical Report
Jiuniu Wang, Hangjie Yuan, Dayou Chen, Yingya Zhang, Xiang Wang, and Shiwei Zhang. Modelscope text-to-video technical report.arXiv preprint arXiv:2308.06571, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Yaohui Wang, Xinyuan Chen, Xin Ma, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, et al. Lavie: High-quality video generation with cascaded latent diffusion models.International Journal of Computer Vision, pages 1–20, 2024. 3
work page 2024
-
[38]
Zun Wang, Jialu Li, Han Lin, Jaehong Yoon, and Mohit Bansal. Dreamrunner: Fine-grained storytelling video gen- eration with retrieval-augmented motion adaptation.arXiv preprint arXiv:2411.16657, 2024. 1, 3, 8
-
[39]
Art-v: Auto-regressive text-to- video generation with diffusion models
Wenming Weng, Ruoyu Feng, Yanhui Wang, Qi Dai, Chunyu Wang, Dacheng Yin, Zhiyuan Zhao, Kai Qiu, Jian- min Bao, Yuhui Yuan, et al. Art-v: Auto-regressive text-to- video generation with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7395–7405, 2024. 3
work page 2024
-
[40]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Shengming Yin, Chenfei Wu, Huan Yang, Jianfeng Wang, Xiaodong Wang, Minheng Ni, Zhengyuan Yang, Linjie Li, Shuguang Liu, Fan Yang, et al. Nuwa-xl: Diffusion over diffusion for extremely long video generation.arXiv preprint arXiv:2303.12346, 2023. 1, 3
-
[42]
David Junhao Zhang, Jay Zhangjie Wu, Jia-Wei Liu, Rui Zhao, Lingmin Ran, Yuchao Gu, Difei Gao, and Mike Zheng Shou. Show-1: Marrying pixel and latent diffusion models for text-to-video generation.International Journal of Com- puter Vision, pages 1–15, 2024
work page 2024
-
[43]
Yabo Zhang, Yuxiang Wei, Dongsheng Jiang, Xiaopeng Zhang, Wangmeng Zuo, and Qi Tian. Controlvideo: Training-free controllable text-to-video generation.arXiv preprint arXiv:2305.13077, 2023. 3
-
[44]
Canyu Zhao, Mingyu Liu, Wen Wang, Weihua Chen, Fan Wang, Hao Chen, Bo Zhang, and Chunhua Shen. Moviedreamer: Hierarchical generation for coherent long vi- sual sequence.arXiv preprint arXiv:2407.16655, 2024. 1, 3
-
[45]
Sixiao Zheng and Yanwei Fu. Temporalstory: Enhancing consistency in story visualization using spatial-temporal at- tention.arXiv e-prints, pages arXiv–2407, 2024. 1 10
work page 2024
-
[46]
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou. Storydiffusion: Consistent self- attention for long-range image and video generation.Ad- vances in Neural Information Processing Systems, 37: 110315–110340, 2025. 3
work page 2025
-
[47]
Shaobin Zhuang, Kunchang Li, Xinyuan Chen, Yaohui Wang, Ziwei Liu, Yu Qiao, and Yali Wang. Vlogger: Make your dream a vlog. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 8806–8817, 2024. 1, 3, 6 11 A. Supplementary Materials A.1. Ethics Statement Ethics Statement All names, characters, and events appearing in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.