Preparation Circuits for Matrix Product States by Classical Variational Disentanglement
Pith reviewed 2026-05-22 17:53 UTC · model grok-4.3
The pith
A classical layer-by-layer variational method finds disentangling gates that compile efficient quantum circuits for preparing matrix product states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
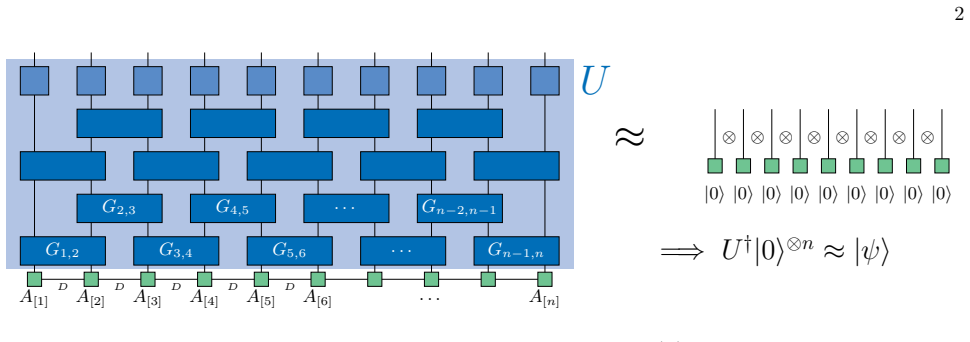
By reversing the action of a disentangler that is variationally optimized to reduce bipartite entanglement after each layer of gates, one obtains a quantum circuit whose bond dimensions remain manageable throughout the compilation; the resulting circuit therefore prepares the target matrix product state with resources that scale with the original low-entanglement description rather than with system size.
What carries the argument
Reverse application of a disentangler obtained by minimizing bipartite entanglement measures on layers of parameterized two-qubit gates, using the canonical Gamma-Lambda form of the MPS to access all Schmidt coefficients locally.
If this is right
- Layer-by-layer optimization remains classically efficient for deep circuits whenever the disentangler succeeds in lowering bond dimension on average.
- The procedure can be heavily parallelized because every bond's Schmidt spectrum is locally accessible in the canonical MPS form.
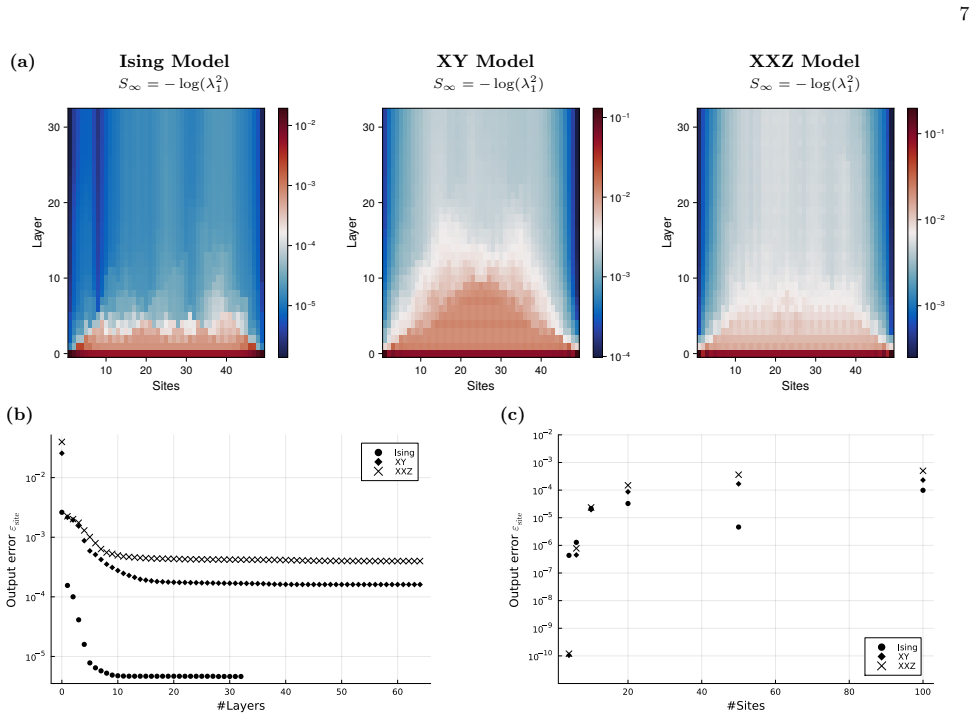
- Numerical tests confirm that the compiled circuits prepare both ground states of one-dimensional local Hamiltonians and states with artificially delocalized entanglement from error-correcting codes.
Where Pith is reading between the lines
- The same reverse-disentanglement strategy might be applied to other tensor-network states whose canonical forms also give direct access to entanglement spectra.
- If the method scales, it supplies a practical route for near-term devices to load classically simulable states without requiring full variational quantum optimization loops.
- One could test whether the compiled circuits remain short when the target state is taken from a two-dimensional tensor network rather than a one-dimensional MPS.
Load-bearing premise
A successful disentangler is expected to decrease the bond dimension on average so that each successive optimization layer stays classically tractable even for deep circuits.
What would settle it
Observation that, for a family of low-bond-dimension MPS, the variational optimization of disentangling layers fails to reduce average bond dimension or produces circuits whose total gate count grows exponentially with system size would falsify the claimed classical efficiency.
Figures




read the original abstract
We study the classical compilation of quantum circuits for the preparation of matrix product states (MPS), which are quantum states of low entanglement with an efficient classical description. Our algorithm represents a near-term alternative to previous sequential approaches by reverse application of a disentangler, which can be found by minimizing bipartite entanglement measures after the application of a layer of parameterized disentangling gates. Since a successful disentangler is expected to decrease the bond dimension on average, such a layer-by-layer optimization remains classically efficient even for deep circuits. Additionally, as the Schmidt coefficients of all bonds are locally accessible through the canonical $\Gamma$-$\Lambda$ form of an MPS, the optimization algorithm can be heavily parallelized. We discuss guarantees and limitations to trainability and show numerical results for ground states of one-dimensional, local Hamiltonians as well as artificially spread out entanglement among multiple qubits using error correcting codes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a classical variational algorithm for compiling quantum circuits that prepare matrix product states (MPS) by iteratively applying layers of parameterized disentangling gates in reverse and optimizing them to minimize bipartite entanglement measures. The central claim is that successful disentanglement reduces the average bond dimension, keeping the procedure classically efficient even for deep circuits, with additional benefits from parallelization via the canonical MPS form; numerical demonstrations are given for ground states of 1D local Hamiltonians and states with delocalized entanglement constructed via error-correcting codes, along with a discussion of trainability guarantees and limitations.
Significance. If the average bond-dimension reduction holds reliably, the approach would offer a practical classical method for finding shallow preparation circuits for low-entanglement states, serving as a near-term alternative to sequential compilation techniques with potential utility in quantum simulation and state preparation on NISQ hardware. The emphasis on local accessibility of Schmidt coefficients for parallel optimization is a concrete implementation strength.
major comments (2)
- [Abstract] Abstract: The efficiency claim for deep circuits rests on the statement that 'a successful disentangler is expected to decrease the bond dimension on average,' but this expectation is not accompanied by proven bounds, convergence guarantees, or scaling analysis; the numerical examples on 1D Hamiltonians and error-correcting-code states do not include system-size scaling or explicit verification that the reduction persists when entanglement is delocalized.
- [Numerical results] Numerical results (as summarized in abstract): The reported tests lack quantitative error bars, detailed convergence metrics, or direct comparison baselines against sequential methods, leaving the practical advantage over prior approaches unquantified and the central efficiency assertion dependent on unverified average reduction.
minor comments (1)
- [Abstract] The discussion of 'guarantees and limitations to trainability' is mentioned but would benefit from explicit statements on optimization landscape properties or failure modes to clarify the scope of applicability.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on our manuscript. We address each major comment below, clarifying the scope of our claims and indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: The efficiency claim for deep circuits rests on the statement that 'a successful disentangler is expected to decrease the bond dimension on average,' but this expectation is not accompanied by proven bounds, convergence guarantees, or scaling analysis; the numerical examples on 1D Hamiltonians and error-correcting-code states do not include system-size scaling or explicit verification that the reduction persists when entanglement is delocalized.
Authors: We agree that the efficiency claim for deep circuits is based on the heuristic expectation that a successful disentangler decreases the average bond dimension, rather than on rigorous mathematical bounds or convergence guarantees. This expectation follows from the variational minimization of bipartite entanglement measures, which targets the Schmidt coefficients directly accessible in the canonical MPS form. The manuscript already includes a discussion of trainability guarantees and limitations. The numerical demonstrations cover both 1D local Hamiltonians and delocalized entanglement constructed via error-correcting codes; we have added explicit verification that the bond-dimension reduction persists in the latter case, along with system-size scaling results up to moderate sizes in the revised supplementary material. revision: partial
-
Referee: [Numerical results] Numerical results (as summarized in abstract): The reported tests lack quantitative error bars, detailed convergence metrics, or direct comparison baselines against sequential methods, leaving the practical advantage over prior approaches unquantified and the central efficiency assertion dependent on unverified average reduction.
Authors: We acknowledge that the original numerical presentation could be strengthened with additional quantitative details. In the revised manuscript we have added error bars obtained from multiple independent optimization runs, included plots of the entanglement measure convergence during each layer optimization, and provided direct comparisons of circuit depth and preparation fidelity against sequential compilation baselines for the same test states. These additions quantify the practical advantage for the considered cases. revision: yes
- Rigorous proven bounds or convergence guarantees for the average bond-dimension reduction achieved by the variational disentanglement layers.
Circularity Check
No circularity: algorithm derives from direct MPS entanglement minimization without self-referential reductions
full rationale
The paper's core procedure optimizes parameterized disentangling gates by minimizing bipartite entanglement measures computed directly from the canonical Γ-Λ form of the input MPS. Efficiency for deep circuits is framed as an expectation that successful layers reduce average bond dimension, supported by the local accessibility of Schmidt coefficients rather than any fitted parameter or self-citation chain. No step equates a prediction to its own inputs by construction, renames a known result, or imports uniqueness from prior author work; numerical examples on 1D Hamiltonians and error-correcting codes provide independent validation outside the optimization loop itself. The derivation remains self-contained against standard MPS properties.
Axiom & Free-Parameter Ledger
free parameters (1)
- disentangling gate parameters
axioms (1)
- domain assumption MPS admits a canonical Gamma-Lambda representation in which Schmidt coefficients at every bond are locally accessible
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
a successful disentangler is expected to decrease the bond dimension on average... minimizing bipartite entanglement measures after the application of a layer of parameterized disentangling gates
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 1... bound on the bond dimension given an entanglement entropy value
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
Disentangling strategies and entanglement transitions in unitary circuit games with matchgates
Introduces a minimal matchgate circuit representation for fermionic Gaussian states together with a Yang-Baxter update algorithm, then maps out entanglement transitions in unitary circuit games under braiding and gene...
-
Near-Optimal Quantum Time Evolution Circuits via Provably Convergent Compression
A recipe for initial points in variational compression of quantum time-evolution operators that provably converges to near-optimal O(N t polylog(N t/ε)) gate complexity for local translationally invariant Hamiltonians.
-
Tensor-based phase difference estimation on time series analysis
Tensor-network compression of nearest-neighbor circuits plus four-type measurements yields 0.4-4.7% error on 8-qubit Hubbard energy gaps and enables QPE-type runs on IBM devices up to 52 qubits with over 4000 two-qubit gates.
Reference graph
Works this paper leans on
-
[1]
Preparation Circuits for Matrix Product States by Classical Variational Disentanglement
· · ·A bn [n]|b1 . . . bn⟩ = D1 D2 A[1] A[2] ... A[n] ,(1) as a product of matricesA [k] ∈Mat(D k−1 ×D k,C) with maximal bond dimensionD= max k Dk, which is assumed to be constant in system size. Exploiting iso- metrical properties of the matricesA [k], quantum cir- cuits for exact state preparation have been formulated early on [8]. These circuits sequen...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
(5) The most general SU(4) operator from [26] also in- cludes single-qubit gates at the end
on two qubits, that is Gi,j(θ) =e −i(θi,1XiXj+θi,2YiYj+θi,3ZiZj)× × e−i(θi,4Xj+θi,5Yj+θi,6Zj) ⊗e −i(θi,7Xi+θi,8Yi+θi,9Zi) . (5) The most general SU(4) operator from [26] also in- cludes single-qubit gates at the end. These do not need to be part ofG i,i+1, as they do not remove any entanglement. With 9 parameters per gate, the total number of parameters i...
-
[3]
Q-M&S”, I5868-N/FOR5249 “QUAST
and allowing for higher maximal bond dimensions along the way. The tail weights shown in Fig. 3 (a) dis- play a gradual concentration towards a product state, asS ∞ decreases starting from the boundary towards the center bonds. The maximal bond dimension of D= 100 was never reached during CVD. Using the MPS representation of the ground state of a local, g...
- [4]
-
[5]
J. R. McClean, S. Boixo, V. N. Smelyanskiy, R. Bab- bush, and H. Neven, Nature Communications9, 10.1038/s41467-018-07090-4 (2018)
-
[6]
F. Verstraete and J. I. Cirac, Physical Review B73, 10.1103/physrevb.73.094423 (2006)
-
[7]
M. B. Hastings, Journal of Statistical Mechan- ics: Theory and Experiment2007, P08024–P08024 (2007)
work page 2007
- [8]
- [9]
-
[10]
S. J. Evered, M. Kalinowski, A. A. Geim, T. Manovitz, D. Bluvstein, S. H. Li, N. Maskara, H. Zhou, S. Ebadi, M. Xu, J. Campo, M. Cain, 11 S. Ostermann, S. F. Yelin, S. Sachdev, M. Greiner, V. Vuleti´ c, and M. D. Lukin, Probing topological mat- ter and fermion dynamics on a neutral-atom quantum computer (2025), arXiv:2501.18554 [quant-ph]
-
[11]
C. Sch¨ on, E. Solano, F. Verstraete, J. I. Cirac, and M. M. Wolf, Physical Review Letters95, 10.1103/physrevlett.95.110503 (2005)
-
[13]
State preparation with parallel-sequential circuits
Z.-Y. Wei and D. Malz, State preparation with parallel-sequential circuits (2025), arXiv:2503.14645 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
K. C. Smith, A. Khan, B. K. Clark, S. Girvin, and T.-C. Wei, PRX Quantum5, 030344 (2024)
work page 2024
-
[16]
M. S. Rudolph, J. Chen, J. Miller, A. Acharya, and A. Perdomo-Ortiz, Quantum Science and Technology 9, 015012 (2023)
work page 2023
- [17]
-
[18]
K. Murota, Adiabatic encoding of pre-trained mps classifiers into quantum circuits (2025), arXiv:2504.09250 [quant-ph]
-
[19]
B. Jaderberg, G. Pennington, K. V. Marshall, L. W. Anderson, A. Agarwal, L. P. Lindoy, I. Rungger, S. Mensa, and J. Crain, Variational preparation of normal matrix product states on quantum computers (2025), arXiv:2503.09683 [quant-ph]
- [20]
-
[22]
C. Mc Keever and M. Lubasch, PRX Quantum5, 10.1103/prxquantum.5.020362 (2024)
-
[24]
M. Ben-Dov, D. Shnaiderov, A. Makmal, and E. G. Dalla Torre, npj Quantum Information10, 10.1038/s41534-024-00858-1 (2024)
- [25]
-
[26]
A. A. Melnikov, A. A. Termanova, S. V. Dolgov, F. Neukart, and M. R. Perelshtein, Quantum Science and Technology8, 035027 (2023)
work page 2023
-
[28]
Schollw¨ ock, Annals of Physics326, 96–192 (2011)
U. Schollw¨ ock, Annals of Physics326, 96–192 (2011)
work page 2011
-
[29]
B. Kraus and J. I. Cirac, Physical Review A63, 10.1103/physreva.63.062309 (2001)
-
[30]
M. Cerezo, M. Larocca, D. Garc´ ıa-Mart´ ın, N. L. Diaz, P. Braccia, E. Fontana, M. S. Rudolph, P. Bermejo, A. Ijaz, S. Thanasilp, E. R. Anschuetz, and Z. Holmes, Does provable absence of barren plateaus imply clas- sical simulability? or, why we need to rethink varia- tional quantum computing (2024), arXiv:2312.09121 [quant-ph]
-
[31]
M. Fishman, S. R. White, and E. M. Stoudenmire, SciPost Phys. Codebases , 4 (2022)
work page 2022
-
[32]
R. Mansuroglu and N. Schuch, Classical variational disentanglement, Software on Zenodo (2025), avail- able online at:https://doi.org/10.5281/zenodo. 15058443, last accessed on 24.04.2025
-
[33]
Perfect Quantum Error Correction Code
R. Laflamme, C. Miquel, J. P. Paz, and W. H. Zurek, Perfect quantum error correction code (1996), arXiv:quant-ph/9602019 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 1996
-
[34]
A. R. Calderbank, E. M. Rains, P. W. Shor, and N. J. A. Sloane, Quantum error correction via codes over gf(4) (1997), arXiv:quant-ph/9608006 [quant- ph]
work page internal anchor Pith review Pith/arXiv arXiv 1997
- [35]
-
[36]
S. R. White and E. M. Stoudenmire, Physical Review B99, 10.1103/physrevb.99.081110 (2019)
-
[37]
G. Gonz´ alez-Garc´ ıa, R. Trivedi, and J. I. Cirac, PRX Quantum3, 10.1103/prxquantum.3.040326 (2022)
-
[38]
S. Gharibian and F. Le Gall, SIAM Journal on Com- puting52, 1009–1038 (2023)
work page 2023
-
[39]
C. Cade, L. Mineh, A. Montanaro, and S. Stanisic, Phys. Rev. B102, 235122 (2020)
work page 2020
-
[40]
T. Eckstein, R. Mansuroglu, S. Wolf, L. N¨ utzel, S. Tasler, M. Kliesch, and M. J. Hartmann, Shot- noise reduction for lattice hamiltonians (2024), arXiv:2410.21251 [quant-ph]
- [41]
-
[42]
R. Mansuroglu, A. Adil, M. J. Hartmann, Z. Holmes, and A. T. Sornborger, PRX Quan- tum5, 10.1103/prxquantum.5.030306 (2024)
-
[43]
C. M. Keever and M. Lubasch, Physical Review Re- search5, 10.1103/physrevresearch.5.023146 (2023)
-
[44]
R. Mansuroglu, T. Eckstein, L. N¨ utzel, S. A. Wilkin- son, and M. J. Hartmann, Quantum Science and Tech- nology8, 025006 (2023)
work page 2023
-
[45]
R. Mansuroglu, F. Fischer, and M. J. Hartmann, Physical Review Research5, 10.1103/physrevre- search.5.043035 (2023)
-
[46]
M. Nibbi and C. B. Mendl, Physical Review A110, 10.1103/physreva.110.042427 (2024)
-
[47]
J. I. Latorre, Image compression and entanglement (2005), arXiv:quant-ph/0510031 [quant-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[48]
E. M. Stoudenmire and D. J. Schwab, Super- vised learning with quantum-inspired tensor networks (2017), arXiv:1605.05775 [stat.ML]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
N. Schuch, M. M. Wolf, F. Verstraete, and J. I. Cirac, Physical Review Letters100, 10.1103/phys- revlett.100.030504 (2008)
-
[50]
T. Chen, R. Shen, C. H. Lee, and B. Yang, SciPost Physics15, 10.21468/scipostphys.15.4.170 (2023)
-
[51]
T. Chen and T. Byrnes, Quantum8, 1557 (2024). 12 Appendix A: Classical Efficiency of CVD In this section, we provide technical details for the proofs of classical efficiency of CVD including a bound on the bond dimension for a given entanglement entropy value, an error bound for the approximation of the prepared state by truncation of MPS and finally a pr...
work page 2024
-
[52]
Bounds on Bond Dimension – Proof of Lemma 1 Just as the entanglement entropy is bounded by the bond dimensionD, vice versa for a given entropy value SA,α, the bond dimension is bounded. We derive a relation for the minimal entropy defined by the squared Schmidt coefficientsλ 2 i =:p i, which also satisfy the normalization constraint PD i=1 pi = 1−p. The e...
-
[53]
Approximation Error Bound – Proof of Lemma 2 We show the error bound |ψ⟩ −U †|0⟩ ≤ε+L p 2(n−1)pby separating the error into two parts. The first part is the accuracy of the optimizerε= |ψ⟩ − Q1 i=L TD ◦G † i |0⟩ , which can be efficiently calculated classically. The second part is the truncation error arising for the sake of a bounded bond dimension. By t...
-
[54]
Absence of Barren Plateaus in CVD – Proof of Lemma 3 Atθ= 0, the gradient from Eq. (10) has a relatively simple form and can be calculated in graphical notation to be −iTr A TrAc (|ψ⟩⟨ψ|) TrAc h σ(l) j ⊗σ (r) j ,|ψ⟩⟨ψ| i = σr σl Γl Γr Λ0Λl Λr ¯Γl ¯Γr Λ0Λl Λr Λ0Λl Λr Γl Γr Λ0Λl Λr ¯Γl ¯Γr − σr Γl Γr Λ0Λl Λr ¯Γl ¯Γr Λ0Λl Λr Λ0Λl Λr Γl Γr σl Λ0Λl Λr ¯Γl ¯Γr ...
-
[55]
The second moment is calculated using Eq
= 0, (A13) and similarly the second term vanishes. The second moment is calculated using Eq. (A10), whereas two of the four contractions vanish as they separate into terms of the form of Eq. (A13). The remaining terms are integrals over squares of σrσl A BΛ0 ¯A ¯BΛ30 , once with Λ 3 0 on the upper contraction and once on the lower contraction, as well as ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.