Task-agnostic Low-rank Residual Adaptation for Efficient Federated Continual Fine-Tuning
Pith reviewed 2026-05-22 13:50 UTC · model grok-4.3
The pith
A single shared low-rank module with residual calibration lets federated clients continually adapt models to new tasks without parameter growth or task identities at inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Fed-TaLoRA continuously fine-tunes a single shared module across sequential tasks to avoid task-wise parameter growth, and further introduces a theoretically grounded residual weight update mechanism to calibrate the aggregated global model and improve aggregation fidelity.
What carries the argument
task-agnostic low-rank residual adaptation module combined with residual weight update for post-aggregation calibration
If this is right
- Avoids task-wise parameter growth by using one module for all tasks.
- Improves aggregation fidelity through residual calibration without task-specific info.
- Reduces communication and computation costs in federated continual settings.
- Demonstrates better performance than baselines on four benchmark datasets.
- Provides theoretical analysis of convergence and aggregation behavior.
Where Pith is reading between the lines
- The method might generalize to non-federated continual learning if residual updates help with other aggregation-like steps.
- Longer task sequences could be tested to see if the shared module remains effective without forgetting.
- Applications in mobile or edge AI where models update over time with new user data classes.
Load-bearing premise
The residual weight update mechanism can reliably correct aggregation inconsistency across heterogeneous clients without causing instability.
What would settle it
Observing no improvement or degradation in model performance when applying the residual update on highly non-IID client data with many sequential tasks would challenge the claim.
Figures




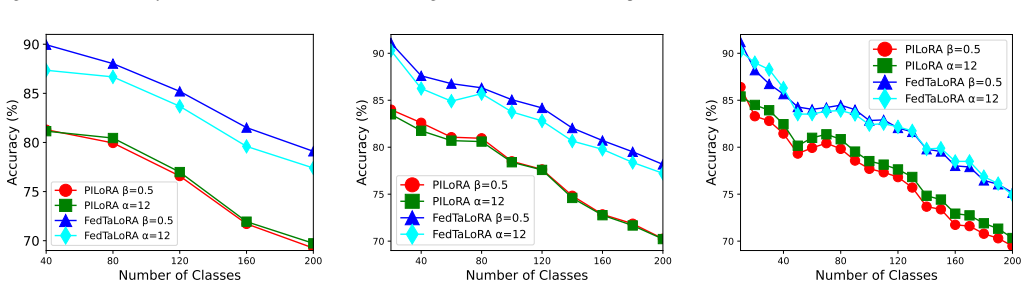








read the original abstract
Federated Parameter-Efficient Fine-Tuning (Fed-PEFT) enables lightweight adaptation of large pre-trained models in federated learning settings by updating only a small subset of parameters. However, Fed-PEFT methods typically assume a fixed label space and static downstream tasks, which is restrictive in realistic application scenarios where clients continuously encounter new classes over time. This leads to an emerging problem, known as \emph{Federated Continual Fine-Tuning} (FCFT). In FCFT, clients collaboratively fine-tune a pre-trained model over a sequence of tasks, where each client observes disjoint sets of new classes over time, and task identity is unavailable at inference time. FCFT is challenging because it simultaneously suffers from severe forgetting under non-IID client data distributions, parameter growth and task-specific inference caused by task-wise modules, and aggregation inconsistency across heterogeneous clients. To address these challenges, we propose Federated Task-agnostic Low-rank Residual Adaptation (Fed-TaLoRA), a novel approach for efficient FCFT built on task-agnostic adaptation, post-aggregation model calibration, and strategic low-rank adaptation placement. Fed-TaLoRA continuously fine-tunes a single shared module across sequential tasks to avoid task-wise parameter growth, and further introduces a theoretically grounded residual weight update mechanism to calibrate the aggregated global model and improve aggregation fidelity. We provide a theoretical analysis of the convergence and aggregation behavior of Fed-TaLoRA. Extensive experiments on four benchmark datasets demonstrate that Fed-TaLoRA consistently outperforms strong baselines while reducing communication and computation costs significantly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Fed-TaLoRA for Federated Continual Fine-Tuning (FCFT), where clients encounter sequential tasks with disjoint new classes under non-IID distributions and without task identity at inference. It introduces a single shared low-rank adaptation module for task-agnostic continual fine-tuning to avoid parameter growth, combined with a theoretically grounded residual weight update to calibrate the aggregated global model and mitigate aggregation inconsistency. The work includes a theoretical analysis of convergence and aggregation behavior, plus experiments on four benchmark datasets claiming consistent outperformance over baselines with reduced communication and computation costs.
Significance. If the residual calibration mechanism and theoretical bounds hold under sequential class-disjoint shifts, the result would be significant for parameter-efficient federated learning in dynamic, non-stationary settings. It directly targets the triad of forgetting, task-specific modules, and aggregation drift that current Fed-PEFT methods leave unaddressed. The explicit provision of convergence analysis and multi-benchmark empirical validation, together with the task-agnostic inference property, would strengthen its contribution to efficient continual adaptation of large models in federated environments.
major comments (2)
- [Theoretical analysis] Theoretical analysis section: the residual weight update is presented as theoretically grounded to correct aggregation inconsistency, yet no explicit bound is derived that accounts for the expanding support of the label space across sequential non-IID class-disjoint tasks. The derivation appears to treat heterogeneity statistics as stationary, which risks the post-aggregation calibration amplifying rather than damping drift; a concrete test or lemma addressing growing label spaces is required to support the central claim.
- [Method] Method and aggregation sections: the claim that the residual mechanism improves aggregation fidelity while remaining task-agnostic at inference relies on the low-rank factors from prior tasks aligning with the current task's gradient subspace. Under the FCFT setting of disjoint classes, this alignment is not obviously guaranteed; an ablation isolating the residual term's contribution to forgetting reduction versus a plain low-rank baseline would be needed to establish load-bearing efficacy.
minor comments (2)
- [Abstract] Abstract: the description of 'strategic low-rank adaptation placement' is too terse; a single sentence clarifying the chosen layers or modules would improve clarity without lengthening the abstract.
- [Experiments] Experiments: while four benchmarks are cited, the manuscript should explicitly state the number of tasks, class-disjoint split protocol, and communication-round budget per task to allow direct reproduction of the reported cost reductions.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. We address each major comment below and have incorporated revisions to strengthen the theoretical grounding and empirical validation of the residual calibration mechanism.
read point-by-point responses
-
Referee: [Theoretical analysis] Theoretical analysis section: the residual weight update is presented as theoretically grounded to correct aggregation inconsistency, yet no explicit bound is derived that accounts for the expanding support of the label space across sequential non-IID class-disjoint tasks. The derivation appears to treat heterogeneity statistics as stationary, which risks the post-aggregation calibration amplifying rather than damping drift; a concrete test or lemma addressing growing label spaces is required to support the central claim.
Authors: We thank the referee for this observation. Our theoretical analysis derives convergence and aggregation bounds under bounded heterogeneity, but we acknowledge it does not explicitly address the non-stationary case of expanding label spaces across sequential class-disjoint tasks. In the revised manuscript we add a new lemma (Lemma 4) that extends the residual update analysis to growing label spaces. The lemma models the cumulative drift from new classes and shows that the post-aggregation calibration term still contracts the inconsistency term by a factor depending on the low-rank rank and the residual scaling coefficient, thereby preventing amplification of drift. A proof sketch and a brief numerical verification on synthetic expanding-label sequences are included in the appendix. revision: yes
-
Referee: [Method] Method and aggregation sections: the claim that the residual mechanism improves aggregation fidelity while remaining task-agnostic at inference relies on the low-rank factors from prior tasks aligning with the current task's gradient subspace. Under the FCFT setting of disjoint classes, this alignment is not obviously guaranteed; an ablation isolating the residual term's contribution to forgetting reduction versus a plain low-rank baseline would be needed to establish load-bearing efficacy.
Authors: We agree that an explicit ablation is necessary to isolate the residual term's contribution. The revised manuscript adds a dedicated ablation study (Section 5.4) comparing Fed-TaLoRA against a plain low-rank adaptation baseline that performs the same sequential updates but omits the residual calibration step. Results across all four benchmarks show that removing the residual term increases average forgetting by 4.2–7.8 percentage points while leaving communication cost unchanged, confirming that the calibration step is responsible for the observed aggregation fidelity gains. We also clarify in Section 3.2 that the shared low-rank placement in the attention and feed-forward layers captures sufficiently general feature directions, allowing reasonable subspace overlap even under class-disjoint shifts; the residual term then corrects the residual misalignment after aggregation. revision: yes
Circularity Check
No significant circularity; derivation remains self-contained
full rationale
The provided abstract and claims introduce Fed-TaLoRA via task-agnostic low-rank adaptation plus a residual weight update asserted to be theoretically grounded, with a separate theoretical analysis of convergence and aggregation behavior. No equations or steps are shown that reduce a claimed prediction or result to a fitted parameter or self-defined quantity by construction. No self-citation chains, uniqueness theorems imported from the same authors, or ansatzes smuggled via prior work appear in the text. The central performance claims rest on experimental outperformance on benchmark datasets rather than on any internal redefinition or statistical forcing. This is the normal case of an independent derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Clients observe disjoint sets of new classes over time and task identity is unavailable at inference time.
Reference graph
Works this paper leans on
-
[1]
Pre-trained models: Past, present and future,
X. Han, Z. Zhang, N. Ding, Y . Gu, X. Liu, Y . Huo, J. Qiu, Y . Yao, A. Zhang, L. Zhanget al., “Pre-trained models: Past, present and future,”AI Open, vol. 2, pp. 225–250, 2021
work page 2021
-
[2]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weis- senborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” inInternational Conference on Learning Representations, Oct. 2020
work page 2020
-
[3]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, “Bert: Pre-training of deep bidirectional trans- formers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Z. Zhang, Y . Yang, Y . Dai, Q. Wang, Y . Yu, L. Qu, and Z. Xu, “FedPETuning: When Federated Learning Meets the Parameter-Efficient Tuning Methods of Pre- trained Language Models,” inFindings of the Association for Computational Linguistics: ACL 2023, A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistic...
work page 2023
-
[5]
Towards building the federatedgpt: Federated instruction tuning,
J. Zhang, S. Vahidian, M. Kuo, C. Li, R. Zhang, T. Yu, G. Wang, and Y . Chen, “Towards building the federatedgpt: Federated instruction tuning,” inICASSP 11 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 6915–6919
work page 2024
-
[6]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.”Iclr, vol. 1, no. 2, p. 3, 2022
work page 2022
-
[7]
SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models,
S. Babakniya, A. R. Elkordy, Y . H. Ezzeldin, Q. Liu, K.- B. Song, M. EL-Khamy, and S. Avestimehr, “SLoRA: Federated Parameter Efficient Fine-Tuning of Language Models,” inInternational Workshop on Federated Learn- ing in the Age of Foundation Models in Conjunction with NeurIPS 2023, Oct. 2023
work page 2023
-
[8]
A comprehen- sive survey of continual learning: theory, method and application,
L. Wang, X. Zhang, H. Su, and J. Zhu, “A comprehen- sive survey of continual learning: theory, method and application,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[9]
Ode: An online data selection framework for federated learning with limited storage,
C. Gong, Z. Zheng, Y . Shao, B. Li, F. Wu, and G. Chen, “Ode: An online data selection framework for federated learning with limited storage,”IEEE/ACM Transactions on Networking, vol. 32, no. 4, pp. 2794–2809, 2024
work page 2024
-
[10]
A ug fl: Augmenting federated learning with pretrained models,
S. Yue, Z. Qin, Y . Deng, J. Ren, Y . Zhang, and J. Zhang, “A ug fl: Augmenting federated learning with pretrained models,”IEEE Transactions on Networking, 2025
work page 2025
-
[11]
Class-incremental learning: A survey,
D.-W. Zhou, Q.-W. Wang, Z.-H. Qi, H.-J. Ye, D.-C. Zhan, and Z. Liu, “Class-incremental learning: A survey,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024
work page 2024
-
[12]
Federated Class-Incremental Learning,
J. Dong, L. Wang, Z. Fang, G. Sun, S. Xu, X. Wang, and Q. Zhu, “Federated Class-Incremental Learning,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA, USA: IEEE, Jun. 2022, pp. 10 154–10 163
work page 2022
-
[13]
Fed- erated continual learning for edge-ai: A comprehensive survey,
Z. Wang, F. Wu, F. Yu, Y . Zhou, J. Hu, and G. Min, “Fed- erated continual learning for edge-ai: A comprehensive survey,”arXiv preprint arXiv:2411.13740, 2024
-
[14]
Improving lora in privacy-preserving federated learning,
Y . Sun, Z. Li, Y . Li, and B. Ding, “Improving lora in privacy-preserving federated learning,”arXiv preprint arXiv:2403.12313, 2024
-
[15]
Fed- cprompt: Contrastive prompt for rehearsal-free federated continual learning,
G. Bagwe, X. Yuan, M. Pan, and L. Zhang, “Fed- cprompt: Contrastive prompt for rehearsal-free federated continual learning,”arXiv preprint arXiv:2307.04869, 2023
-
[16]
Continual adaptation of vision transformers for federated learning,
S. Halbe, J. S. Smith, J. Tian, and Z. Kira, “Continual adaptation of vision transformers for federated learning,” arXiv preprint arXiv:2306.09970, 2023
-
[17]
C. Liu, X. Qu, J. Wang, and J. Xiao, “FedET: A Communication-Efficient Federated Class-Incremental Learning Framework Based on Enhanced Transformer,” inProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence. Macau, SAR China: International Joint Conferences on Artificial In- telligence Organization, Aug. 2023, pp. 3984–3992
work page 2023
-
[18]
Pilora: Prototype guided incremental lora for federated class-incremental learning,
H. Guo, F. Zhu, W. Liu, X.-Y . Zhang, and C.-L. Liu, “Pilora: Prototype guided incremental lora for federated class-incremental learning,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 141–159
work page 2024
-
[19]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inArtificial intelligence and statistics. Pmlr, 2017, pp. 1273–1282
work page 2017
-
[20]
Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations,
Z. Wang, Z. Shen, Y . He, G. Sun, H. Wang, L. Lyu, and A. Li, “Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations,”arXiv preprint arXiv:2409.05976, 2024
-
[21]
Fedtune: A deep dive into efficient federated fine-tuning with pre-trained transformers,
J. Chen, W. Xu, S. Guo, J. Wang, J. Zhang, and H. Wang, “Fedtune: A deep dive into efficient federated fine-tuning with pre-trained transformers,”arXiv preprint arXiv:2211.08025, 2022
-
[22]
Flora: Low-rank adapters are secretly gradient compressors,
Y . Hao, Y . Cao, and L. Mou, “Flora: Low-rank adapters are secretly gradient compressors,”arXiv preprint arXiv:2402.03293, 2024
-
[23]
Fedex-lora: Exact aggregation for federated and efficient fine-tuning of large language models,
R. Singhal, K. Ponkshe, and P. Vepakomma, “Fedex-lora: Exact aggregation for federated and efficient fine-tuning of large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 1316– 1336
work page 2025
-
[24]
No One Left Behind: Real-World Federated Class-Incremental Learning,
J. Dong, H. Li, Y . Cong, G. Sun, Y . Zhang, and L. V . Gool, “No One Left Behind: Real-World Federated Class-Incremental Learning,”IEEE Transactions on Pat- tern Analysis and Machine Intelligence, vol. 46, no. 04, pp. 2054–2070, Apr. 2024
work page 2054
-
[25]
M. K. Nori, I.-M. Kim, and G. Wang, “Federated class- incremental learning: A hybrid approach using latent exemplars and data-free techniques to address local and global forgetting,”arXiv preprint arXiv:2501.15356, 2025
-
[26]
TARGET: Federated Class-Continual Learning via Exemplar-Free Distillation,
J. Zhang, C. Chen, W. Zhuang, and L. Lyu, “TARGET: Federated Class-Continual Learning via Exemplar-Free Distillation,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, 2023, pp. 4782– 4793
work page 2023
-
[27]
X. Gao, X. Yang, H. Yu, Y . Kang, and T. Li, “Fedprok: Trustworthy federated class-incremental learning via pro- totypical feature knowledge transfer,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4205–4214
work page 2024
-
[28]
Closed-form merging of parameter-efficient modules for federated continual learning,
R. Salami, P. Buzzega, M. Mosconi, J. Bonato, L. Sabetta, and S. Calderara, “Closed-form merging of parameter-efficient modules for federated continual learning,”arXiv preprint arXiv:2410.17961, 2024
-
[29]
pfedmxf: Personalized federated class- incremental learning with mixture of frequency aggrega- tion,
Y . Zhang, H. Zhu, A. Z. Tan, D. Yu, L. Huang, and H. Yu, “pfedmxf: Personalized federated class- incremental learning with mixture of frequency aggrega- tion,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 30 640–30 650
work page 2025
-
[30]
Parameter-Efficient Fine-Tuning without Introducing New Latency,
B. Liao, Y . Meng, and C. Monz, “Parameter-Efficient Fine-Tuning without Introducing New Latency,” inPro- ceedings of the 61st Annual Meeting of the Associ- ation for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 4242–4260
work page 2023
-
[31]
Sd-lora: Scalable decou- pled low-rank adaptation for class incremental learning,
Y . Wu, H. Piao, L.-K. Huang, R. Wang, W. Li, H. Pfister, D. Meng, K. Ma, and Y . Wei, “Sd-lora: Scalable decou- pled low-rank adaptation for class incremental learning,” 12 inThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[32]
Slca++: Unleash the power of sequential fine-tuning for continual learning with pre-training,
G. Zhang, L. Wang, G. Kang, L. Chen, and Y . Wei, “Slca++: Unleash the power of sequential fine-tuning for continual learning with pre-training,”arXiv preprint arXiv:2408.08295, 2024
-
[33]
LoRA: Low-Rank Adaptation of Large Language Models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen, “Lora: Low-rank adaptation of large language models,”arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
V . Fomenko, H. Yu, J. Lee, S. Hsieh, and W. Chen, “A note on lora,”arXiv preprint arXiv:2404.05086, 2024
-
[35]
Tracking meets lora: Faster training, larger model, stronger performance,
L. Lin, H. Fan, Z. Zhang, Y . Wang, Y . Xu, and H. Ling, “Tracking meets lora: Faster training, larger model, stronger performance,” inEuropean Conference on Com- puter Vision. Springer, 2024, pp. 300–318
work page 2024
-
[36]
Mtlora: Low-rank adaptation approach for efficient multi-task learning,
A. Agiza, M. Neseem, and S. Reda, “Mtlora: Low-rank adaptation approach for efficient multi-task learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16 196–16 205
work page 2024
-
[37]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,”Proceedings of Machine learning and sys- tems, vol. 2, pp. 429–450, 2020
work page 2020
-
[38]
Tighter theory for local sgd on identical and heterogeneous data,
A. Khaled, K. Mishchenko, and P. Richt ´arik, “Tighter theory for local sgd on identical and heterogeneous data,” inInternational conference on artificial intelligence and statistics. PMLR, 2020, pp. 4519–4529
work page 2020
-
[39]
A. Fallah, A. Mokhtari, and A. Ozdaglar, “Personalized federated learning with theoretical guarantees: A model- agnostic meta-learning approach,”Advances in neural information processing systems, vol. 33, pp. 3557–3568, 2020
work page 2020
-
[40]
Learning multiple layers of features from tiny images,
A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” University of Toronto, Toronto, ON, Canada, Tech. Rep., 2009
work page 2009
-
[41]
Tiny imagenet visual recognition challenge,
Y . Le and X. Yang, “Tiny imagenet visual recognition challenge,”CS 231N, vol. 7, no. 7, p. 3, 2015
work page 2015
-
[42]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition. Ieee, 2009, pp. 248–255
work page 2009
-
[43]
Distilling causal effect of data in class-incremental learning,
X. Hu, K. Tang, C. Miao, X.-S. Hua, and H. Zhang, “Distilling causal effect of data in class-incremental learning,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2021, pp. 3957–3966
work page 2021
-
[44]
Py- CIL: A Python Toolbox for Class-Incremental Learning,
D.-W. Zhou, F.-Y . Wang, H.-J. Ye, and D.-C. Zhan, “Py- CIL: A Python Toolbox for Class-Incremental Learning,” Science China Information Sciences, vol. 66, no. 9, pp. 197 101, s11 432–022–3600–y, Sep. 2023
work page 2023
-
[45]
Federated Learning on Non-IID Data Silos: An Experimental Study,
Q. Li, Y . Diao, Q. Chen, and B. He, “Federated Learning on Non-IID Data Silos: An Experimental Study,” in2022 IEEE 38th International Conference on Data Engineer- ing (ICDE), May 2022, pp. 965–978
work page 2022
-
[46]
Overcoming catastrophic forgetting in neural networks,
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ra- malho, A. Grabska-Barwinska, D. Hassabis, C. Clopath, D. Kumaran, and R. Hadsell, “Overcoming catastrophic forgetting in neural networks,”Proceedings of the Na- tional Academy of Sciences, vol. 114, no. 13, pp. 3521– 3526, Mar. 2017
work page 2017
-
[47]
Z. Li and D. Hoiem, “Learning without Forgetting,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 12, pp. 2935–2947, Dec. 2018
work page 2018
-
[48]
ICaRL: Incremental classifier and representation learning,
S.-A. Rebuffi, A. Kolesnikov, G. Sperl, and C. H. Lam- pert, “ICaRL: Incremental classifier and representation learning,” in2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu, HI: IEEE, Jul. 2017, pp. 5533–5542
work page 2017
-
[49]
Learning to Prompt for Continual Learning,
Z. Wang, Z. Zhang, C.-Y . Lee, H. Zhang, R. Sun, X. Ren, G. Su, V . Perot, J. Dy, and T. Pfister, “Learning to Prompt for Continual Learning,” in2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA, USA: IEEE, Jun. 2022, pp. 139–149
work page 2022
-
[50]
Inflora: Interference-free low- rank adaptation for continual learning,
Y .-S. Liang and W.-J. Li, “Inflora: Interference-free low- rank adaptation for continual learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 23 638–23 647
work page 2024
-
[51]
Guiding the last layer in federated learning with pre-trained models,
G. Legate, N. Bernier, L. Page-Caccia, E. Oyallon, and E. Belilovsky, “Guiding the last layer in federated learning with pre-trained models,”Advances in Neural Information Processing Systems, vol. 36, 2024
work page 2024
-
[52]
Pytorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga et al., “Pytorch: An imperative style, high-performance deep learning library,”Advances in neural information processing systems, vol. 32, 2019
work page 2019
-
[53]
Emerging Proper- ties in Self-Supervised Vision Transformers,
M. Caron, H. Touvron, I. Misra, H. Jegou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging Proper- ties in Self-Supervised Vision Transformers,” in2021 IEEE/CVF International Conference on Computer Vision (ICCV), Oct. 2021, pp. 9630–9640
work page 2021
-
[54]
What would elsa do? freezing layers during transformer fine-tuning,
J. Lee, R. Tang, and J. Lin, “What would elsa do? freezing layers during transformer fine-tuning,”arXiv preprint arXiv:1911.03090, 2019
-
[55]
Surgical fine-tuning im- proves adaptation to distribution shifts,
Y . Lee, A. S. Chen, F. Tajwar, A. Kumar, H. Yao, P. Liang, and C. Finn, “Surgical fine-tuning im- proves adaptation to distribution shifts,”arXiv preprint arXiv:2210.11466, 2022
-
[56]
Federated Learning with Non-IID Data
Y . Zhao, M. Li, L. Lai, N. Suda, D. Civin, and V . Chandra, “Federated learning with non-iid data,”arXiv preprint arXiv:1806.00582, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[57]
Asymmetry in low- rank adapters of foundation models,
J. Zhu, K. Greenewald, K. Nadjahi, H. S. d. O. Borde, R. B. Gabrielsson, L. Choshen, M. Ghassemi, M. Yurochkin, and J. Solomon, “Asymmetry in low- rank adapters of foundation models,”arXiv preprint arXiv:2402.16842, 2024. 13 APPENDIX A. PROOF OF THE CONVERGENCE In this section, we give the detailed proofs of Lemma 1 and Theorem 1 in Section V. Lemma 1(One...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.