Unlearning Isn't Deletion: Investigating Reversibility of Machine Unlearning in LLMs
Pith reviewed 2026-05-22 13:22 UTC · model grok-4.3
The pith
Task-level metrics mislead about unlearning success in LLMs because minimal fine-tuning restores original behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Unlearning methods in LLMs often produce reversible forgetting: the model shows reduced performance on the target data according to task metrics, yet its original behavior returns after minimal fine-tuning. This reversibility implies that the target information remains encoded rather than erased. A representation-level framework using PCA similarity and shift, centered kernel alignment, Fisher information, and mean PCA distance measures how much the internal encodings have changed, revealing four distinct forgetting regimes that differ in reversibility and in how much they harm the model's overall capabilities.
What carries the argument
Representation-level analysis framework that tracks representational drift through PCA similarity and shift, centered kernel alignment (CKA), Fisher information, and mean PCA distance to distinguish suppression from deletion.
If this is right
- Task-level metrics alone cannot confirm that unlearning has achieved genuine deletion.
- Unlearning outcomes fall into four regimes that combine different degrees of reversibility and damage to general model performance.
- Relearning speed depends on the source of the data used for recovery attempts.
- Irreversible and non-catastrophic forgetting is rare and difficult to produce.
Where Pith is reading between the lines
- Unlearning algorithms may need explicit mechanisms to resist small updates that restore suppressed knowledge.
- Representation metrics could be paired with recovery experiments to create stronger verification protocols.
- Similar reversibility patterns may appear in other model-editing settings that aim to remove specific capabilities.
Load-bearing premise
That the representation-level metrics reliably indicate whether information has been permanently deleted rather than merely suppressed in a form that small updates can overcome.
What would settle it
An unlearning method after which even extensive fine-tuning on recovery data fails to restore original performance while the mean PCA distance and related metrics remain large and stable.
Figures







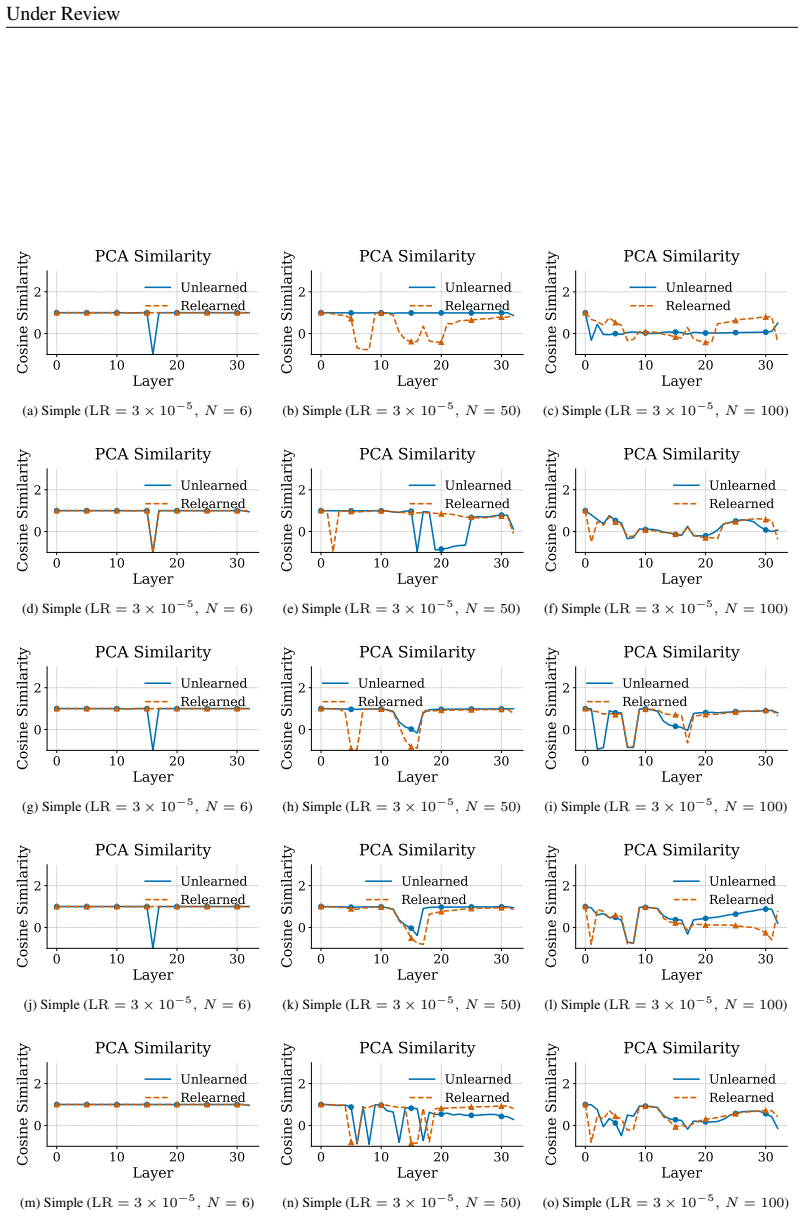


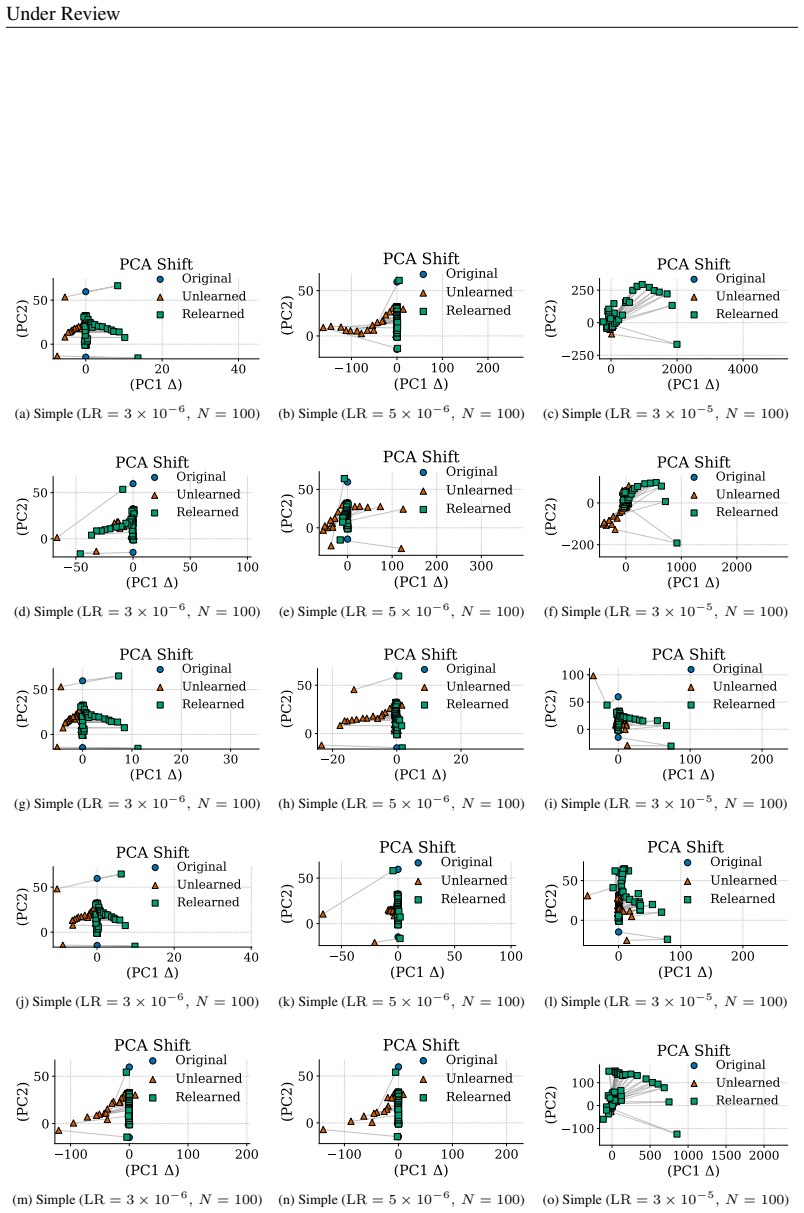

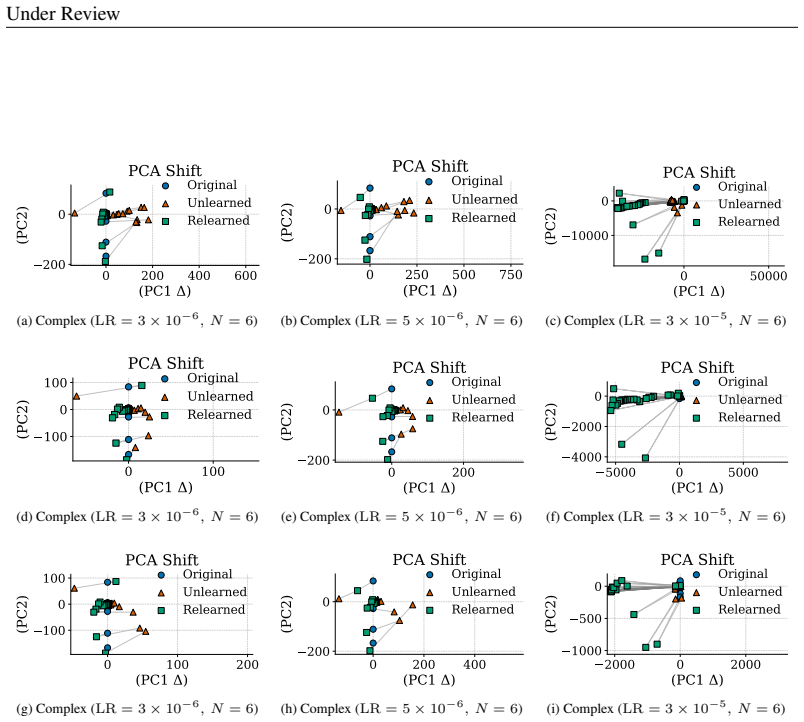
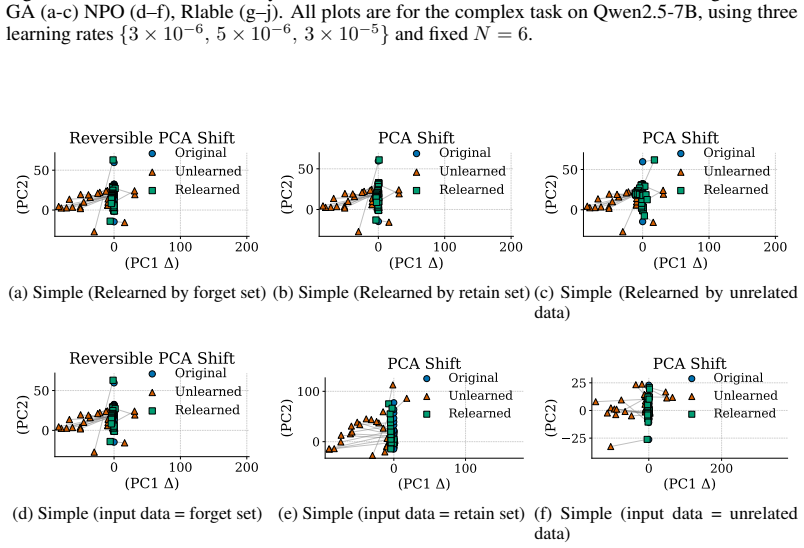











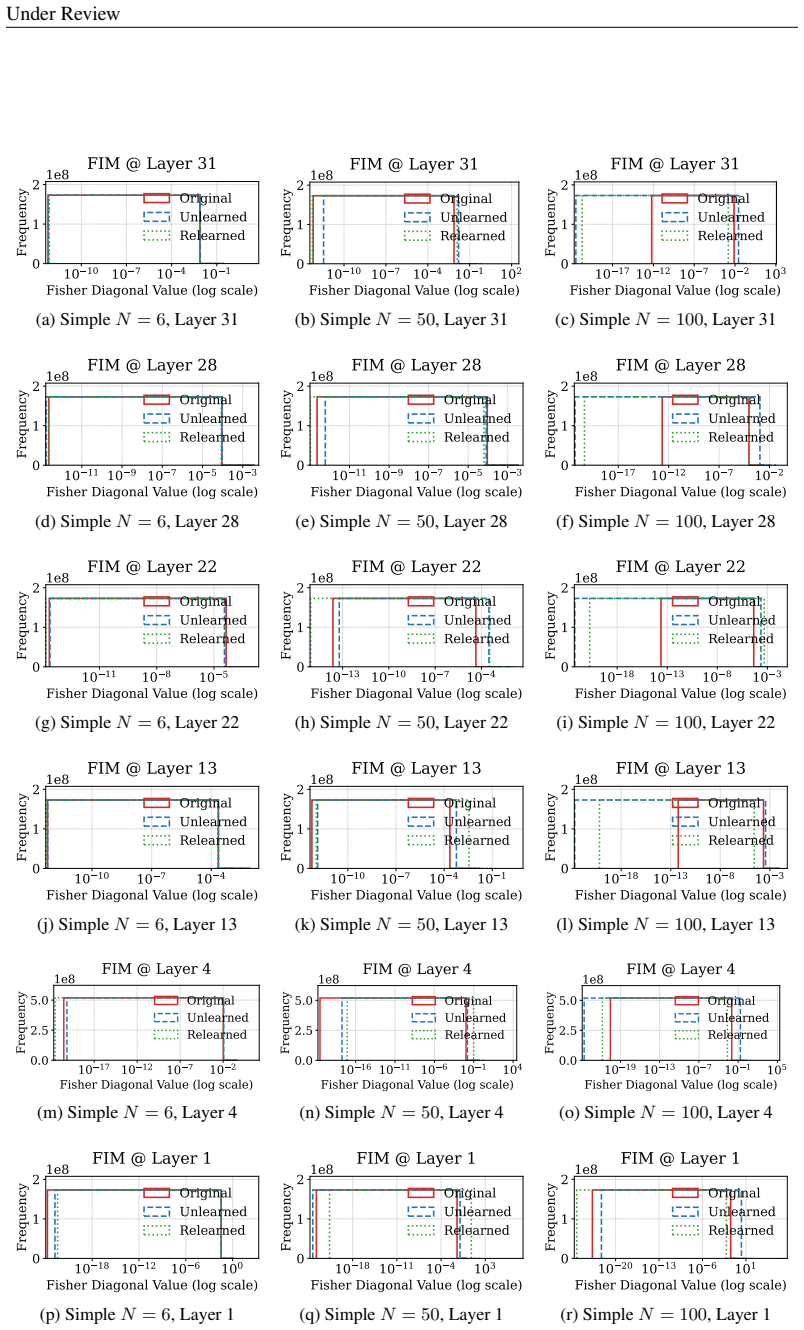


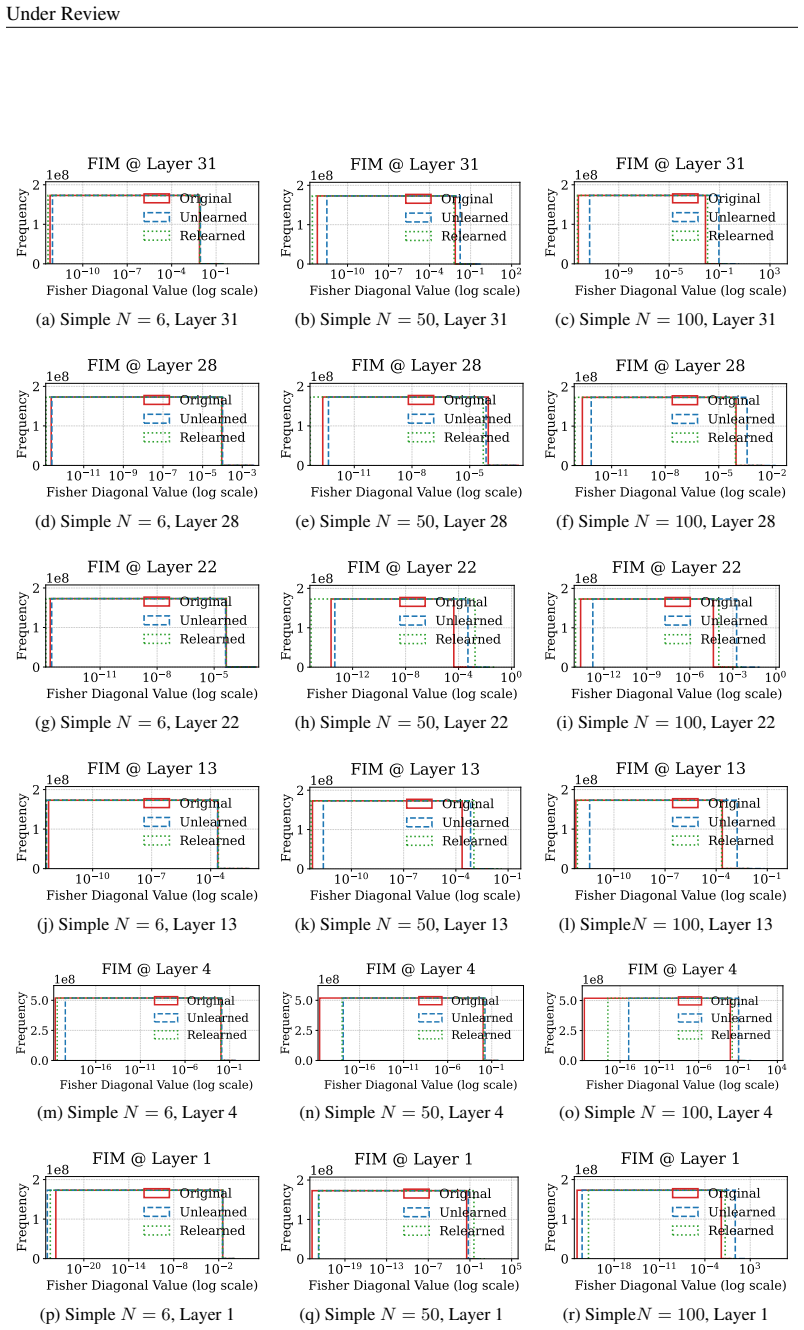

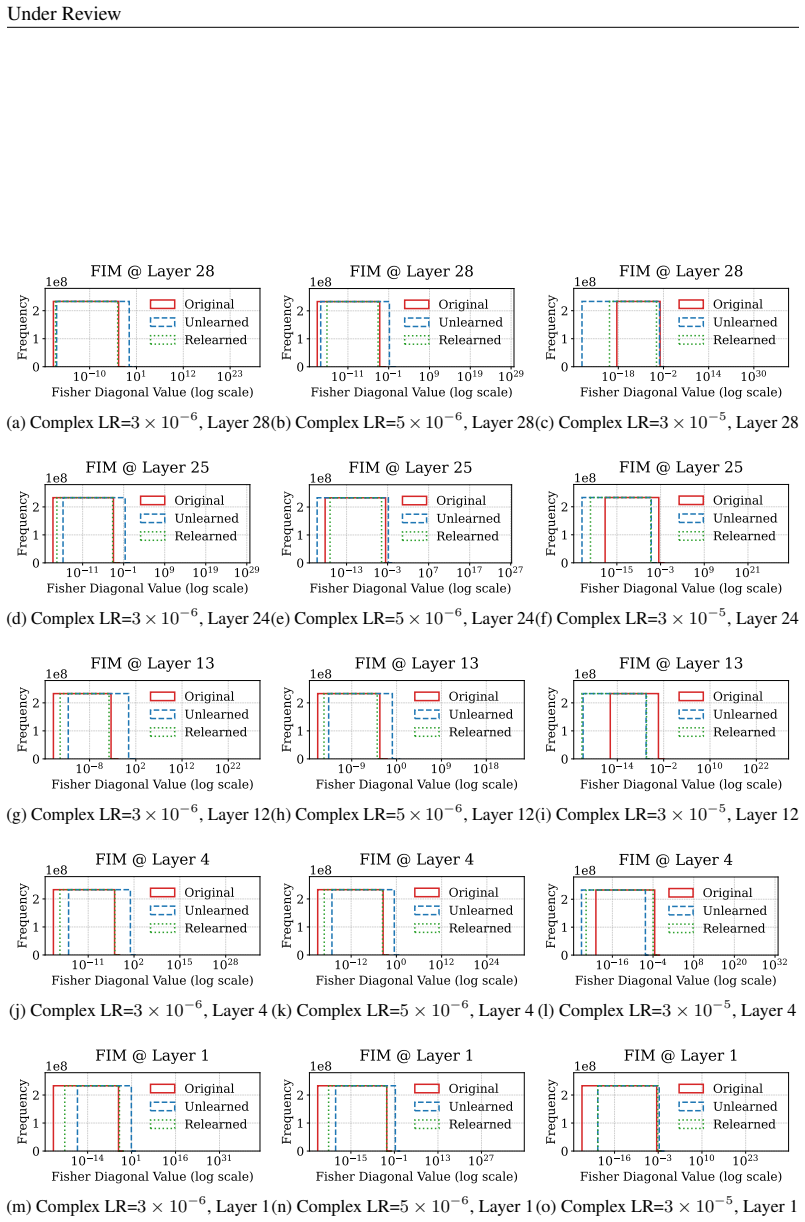







read the original abstract
Unlearning in large language models (LLMs) aims to remove specified data, but its efficacy is typically assessed with task-level metrics like accuracy and perplexity. We show that these metrics can be misleading, as models can appear to forget while their original behavior is easily restored through minimal fine-tuning. This \emph{reversibility} suggests that information is merely suppressed, not genuinely erased. To address this critical evaluation gap, we introduce a \emph{representation-level analysis framework}. Our toolkit comprises PCA similarity and shift, centered kernel alignment (CKA), and Fisher information, complemented by a summary metric, the mean PCA distance, to measure representational drift. Applying this framework across multiple unlearning methods, data domains, and LLMs, we identify four distinct forgetting regimes based on their \emph{reversibility} and \emph{catastrophicity}. We compare recovery strategies and show that relearning efficiency relies on the data source. We also find that irreversible, non-catastrophic forgetting is exceptionally challenging. By probing unlearning limits, we identify a case of seemingly irreversible, targeted forgetting, offering insights for more robust erasure algorithms. Overall, our findings expose a gap in current evaluation and establish a representation-level foundation for trustworthy unlearning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that task-level metrics such as accuracy and perplexity are misleading for evaluating machine unlearning in LLMs, as models can recover original behavior via minimal fine-tuning, indicating suppression rather than deletion. It introduces a representation-level framework using PCA similarity/shift, CKA, Fisher information, and mean PCA distance to measure drift, identifies four forgetting regimes based on reversibility and catastrophicity across methods/domains/models, compares recovery strategies, and reports a case of seemingly irreversible targeted forgetting while noting the difficulty of irreversible non-catastrophic unlearning.
Significance. If the observations hold, the work is significant for exposing gaps in current unlearning evaluation and establishing a representation-level foundation that could improve robustness of erasure methods. The empirical breadth across methods, domains, and LLMs lends support to the regime taxonomy and reversibility findings. However, the framework's interpretive claims would be strengthened by addressing the lack of a positive control baseline.
major comments (2)
- [§3 and §4] §3 (Representation-Level Analysis Framework) and §4 (Experiments): The central claim that PCA/CKA/Fisher/mean-PCA-distance metrics distinguish genuine deletion from suppression because they track reversibility is load-bearing for the four-regime taxonomy, yet the paper provides no positive control by comparing unlearned models against an otherwise identical model trained from random initialization on data excluding the target set. Without this anchor, observed drifts could reflect unlearning optimizer artifacts rather than evidence of information removal, leaving the 'irreversible' regime interpretation underdetermined.
- [Abstract and §5] Abstract and §5 (Discussion): The identification of a 'seemingly irreversible, targeted forgetting' case and the broader claims about recovery efficiency relying on data source would benefit from explicit controls for confounding factors in the recovery experiments and reporting of error bars or statistical significance, as these directly support the reversibility observations and regime distinctions.
minor comments (2)
- [Abstract] The abstract would be clearer with a brief enumeration of the specific unlearning methods (e.g., gradient ascent, negative preference optimization) and model scales tested.
- [§3.2] Notation for the summary metric 'mean PCA distance' could be formalized with an equation in §3.2 to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful review. We appreciate the acknowledgment of the paper's significance in exposing limitations of task-level metrics for machine unlearning evaluation and the value of the representation-level framework. We address the major comments point by point below, providing clarifications and indicating planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Representation-Level Analysis Framework) and §4 (Experiments): The central claim that PCA/CKA/Fisher/mean-PCA-distance metrics distinguish genuine deletion from suppression because they track reversibility is load-bearing for the four-regime taxonomy, yet the paper provides no positive control by comparing unlearned models against an otherwise identical model trained from random initialization on data excluding the target set. Without this anchor, observed drifts could reflect unlearning optimizer artifacts rather than evidence of information removal, leaving the 'irreversible' regime interpretation underdetermined.
Authors: We thank the referee for highlighting this point. Our framework measures representational drift and reversibility relative to the original model, which directly tests whether unlearning suppresses or deletes information by checking if fine-tuning restores original behavior. The consistency of distinct regimes across multiple unlearning methods, domains, and LLMs suggests the metrics capture genuine differences rather than generic optimizer artifacts. A model trained from random initialization on excluded data would provide an additional anchor for 'complete absence of target information,' but it would not isolate the effects of the unlearning optimization trajectory from a pre-trained starting point. We will revise §3 to explicitly discuss this baseline choice and its rationale, add a limitations paragraph in §4 and §5 acknowledging the value of such a positive control, and include a small-scale experiment if compute permits. This addresses the interpretive concern while preserving the core multi-method evidence for the taxonomy. revision: partial
-
Referee: [Abstract and §5] Abstract and §5 (Discussion): The identification of a 'seemingly irreversible, targeted forgetting' case and the broader claims about recovery efficiency relying on data source would benefit from explicit controls for confounding factors in the recovery experiments and reporting of error bars or statistical significance, as these directly support the reversibility observations and regime distinctions.
Authors: We agree that additional statistical rigor would strengthen the recovery results. The experiments already control for key factors including fine-tuning steps, learning rate, and data source (original vs. alternative corpora) to isolate efficiency differences. For the irreversible case, we used fixed evaluation protocols. In the revision we will: (1) report error bars from multiple random seeds in all relevant figures and tables, (2) add explicit discussion in §5 of potential confounders such as hyperparameter sensitivity and data overlap, and (3) include statistical significance tests where appropriate. These changes will better support the reversibility claims and regime distinctions without altering the main findings. revision: yes
Circularity Check
No significant circularity: representation metrics and regime taxonomy remain independent of target claims
full rationale
The paper applies standard, off-the-shelf representation similarity tools (PCA similarity/shift, CKA, Fisher information, mean PCA distance) to quantify drift between pre- and post-unlearning activations. These metrics are computed directly from model internals and are not fitted or redefined using the recovery or accuracy outcomes they are later correlated with. The four forgetting regimes are labeled after the fact from two independently measured axes—reversibility (ease of restoring original behavior via minimal fine-tuning) and catastrophicity (task performance drop)—without any equation or definition that makes one quantity a function of the other by construction. No load-bearing self-citation, uniqueness theorem, or ansatz smuggling is present in the provided derivation chain. The central claim that task-level metrics can mislead therefore rests on observable experimental outcomes rather than tautological re-labeling of inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Task-level metrics such as accuracy and perplexity are insufficient to confirm genuine data deletion in unlearning.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce a representation-level analysis framework... PCA similarity and shift, centered kernel alignment (CKA), and Fisher information... mean PCA distance... four distinct forgetting regimes based on their reversibility and catastrophicity.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We theoretically analyze weight perturbations... Neumann-series expansion... Davis–Kahan theorem for PCA similarity.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
"The Whole Is Greater Than the Sum of Its Parts": A Compatibility-Aware Multi-Teacher CoT Distillation Framework
COMPACT adaptively fuses multi-teacher CoT supervisions using graph-based consensus, mutual-information adaptability, and loss-based difficulty metrics to improve small language model reasoning performance while mitig...
Reference graph
Works this paper leans on
-
[1]
Open problems in machine unlearning for ai safety
Fazl Barez, Tingchen Fu, Ameya Prabhu, Stephen Casper, Amartya Sanyal, Adel Bibi, Aidan O’Gara, Robert Kirk, Ben Bucknall, Tim Fist, Luke Ong, Philip Torr, Kwok-Yan Lam, Robert Trager, David Krueger, Sören Mindermann, José Hernández-Orallo, Mor Geva, and Yarin Gal. Open problems in machine unlearning for AI safety. arXiv:2501.04952, 2025
-
[2]
Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot
Lucas Bourtoule, Varun Chandrasekaran, Christopher A. Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. Machine unlearning. InS&P, pp. 141–159, 2021
work page 2021
-
[3]
Towards robust and cost-efficient knowledge unlearning for large language models
Sungmin Cha, Sungjun Cho, Dasol Hwang, and Moontae Lee. Towards robust and cost-efficient knowledge unlearning for large language models. InICLR, 2025
work page 2025
-
[4]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[5]
The rotation of eigenvectors by a perturbation
Chandler Davis and William Morton Kahan. The rotation of eigenvectors by a perturbation. iii. SIAM Journal on Numerical Analysis, 7(1):1–46, 1970
work page 1970
-
[6]
Erasing conceptual knowl- edge from language models
Rohit Gandikota, Sheridan Feucht, Samuel Marks, and David Bau. Erasing conceptual knowl- edge from language models. arXiv:2410.02760, 2024
-
[7]
On large language model continual unlearning
Chongyang Gao, Lixu Wang, Kaize Ding, Chenkai Weng, Xiao Wang, and Qi Zhu. On large language model continual unlearning. InICLR, 2025
work page 2025
-
[8]
Guan, Gregory Valiant, and James Zou
Antonio Ginart, Melody Y . Guan, Gregory Valiant, and James Zou. Making AI forget you: Data deletion in machine learning. InNeurIPS, pp. 3513–3526, 2019
work page 2019
-
[9]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InNeurIPS Datasets and Benchmarks, 2021
work page 2021
-
[10]
Language model compression with weighted low-rank factorization
Yen-Chang Hsu, Ting Hua, Sungen Chang, Qian Lou, Yilin Shen, and Hongxia Jin. Language model compression with weighted low-rank factorization. InICLR, 2022
work page 2022
-
[11]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InICLR, 2022
work page 2022
-
[12]
Knowledge unlearning for mitigating privacy risks in language models
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. Knowledge unlearning for mitigating privacy risks in language models. In ACL, pp. 14389–14408, 2023
work page 2023
-
[13]
WAGLE: strategic weight attribution for effective and modular unlearning in large language models
Jinghan Jia, Jiancheng Liu, Yihua Zhang, Parikshit Ram, Nathalie Baracaldo, and Sijia Liu. WAGLE: strategic weight attribution for effective and modular unlearning in large language models. InNeurIPS, 2024
work page 2024
-
[14]
Copyright violations and large language models
Antonia Karamolegkou, Jiaang Li, Li Zhou, and Anders Søgaard. Copyright violations and large language models. InEMNLP, pp. 7403–7412, 2023. 10 Under Review
work page 2023
-
[15]
Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A
James Kirkpatrick, Razvan Pascanu, Neil C. Rabinowitz, Joel Veness, Guillaume Desjardins, An- drei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks. arXiv:1612.00796, 2016
-
[16]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey E. Hinton. Similarity of neural network representations revisited. InICML, pp. 3519–3529, 2019
work page 2019
-
[17]
Dohyun Lee, Daniel Rim, Minseok Choi, and Jaegul Choo. Protecting privacy through ap- proximating optimal parameters for sequence unlearning in language models. InACL, pp. 15820–15839, 2024
work page 2024
-
[18]
Jia LI, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Costa Huang, Kashif Rasul, Longhui Yu, Albert Jiang, Ziju Shen, Zihan Qin, Bin Dong, Li Zhou, Yann Fleureau, Guillaume Lample, and Stanislas Polu. Numi- namath. [https://huggingface.co/AI-MO/NuminaMath-1.5](https: //github.com/project-numina/aimo-progress-prize/blob/main/ report...
work page 2024
-
[19]
Single image unlearning: Efficient machine unlearning in multimodal large language models
Jiaqi Li, Qianshan Wei, Chuanyi Zhang, Guilin Qi, Miaozeng Du, Yongrui Chen, Sheng Bi, and Fan Liu. Single image unlearning: Efficient machine unlearning in multimodal large language models. InNeurIPS, 2024
work page 2024
-
[20]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew B. Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Ariel Herbert-V oss, Cort B. Breuer, Andy ...
work page 2024
-
[21]
Shen, Meghdad Kurmanji, Xinchi Qiu, Dongqi Cai, Chao Wu, and Nicholas D
Zexi Li, Xiangzhu Wang, William F. Shen, Meghdad Kurmanji, Xinchi Qiu, Dongqi Cai, Chao Wu, and Nicholas D. Lane. Editing as unlearning: Are knowledge editing methods strong baselines for large language model unlearning? arXiv:2505.19855, 2025
-
[22]
Funu: Boosting machine unlearning efficiency by filtering unnecessary unlearning
Zitong Li, Qingqing Ye, and Haibo Hu. Funu: Boosting machine unlearning efficiency by filtering unnecessary unlearning. arXiv:2501.16614, 2025
-
[23]
Large language model unlearning via embedding-corrupted prompts
Chris Yuhao Liu, Yaxuan Wang, Jeffrey Flanigan, and Yang Liu. Large language model unlearning via embedding-corrupted prompts. InNeurIPS, 2024
work page 2024
-
[24]
Michelle Lo, Fazl Barez, and Shay B. Cohen. Large language models relearn removed concepts. InFindings of ACL, pp. 8306–8323, 2024
work page 2024
-
[25]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InICLR, 2019
work page 2019
-
[26]
URL https://openreview.net/forum?id= J5IRyTKZ9s
Aengus Lynch, Phillip Guo, Aidan Ewart, Stephen Casper, and Dylan Hadfield-Menell. Eight methods to evaluate robust unlearning in llms. arXiv:2402.16835, 2024
-
[27]
Pratyush Maini, Zhili Feng, Avi Schwarzschild, Zachary C. Lipton, and J. Zico Kolter. TOFU: A task of fictitious unlearning for llms. InCOLM, 2024
work page 2024
-
[28]
Scalable Extraction of Training Data from (Production) Language Models
Milad Nasr, Nicholas Carlini, Jonathan Hayase, Matthew Jagielski, A. Feder Cooper, Daphne Ippolito, Christopher A. Choquette-Choo, Eric Wallace, Florian Tramèr, and Katherine Lee. Scalable extraction of training data from (production) language models. arXiv:2311.17035, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
In-context unlearning: Language models as few-shot unlearners
Martin Pawelczyk, Seth Neel, and Himabindu Lakkaraju. In-context unlearning: Language models as few-shot unlearners. InICML, 2024. 11 Under Review
work page 2024
-
[30]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: singular vector canonical correlation analysis for deep learning dynamics and interpretability. InNeurIPS, pp. 6076–6085, 2017
work page 2017
-
[31]
Detecting pretraining data from large language models
Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. InICLR, 2024
work page 2024
-
[32]
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A. Smith, and Chiyuan Zhang. MUSE: machine unlearning six-way evaluation for language models. InICLR, 2025
work page 2025
-
[33]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. InNAACL, pp. 4149–4158, 2019
work page 2019
-
[34]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Harts...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Unveiling the implicit toxicity in large language models
Jiaxin Wen, Pei Ke, Hao Sun, Zhexin Zhang, Chengfei Li, Jinfeng Bai, and Minlie Huang. Unveiling the implicit toxicity in large language models. InEMNLP, pp. 1322–1338, 2023
work page 2023
-
[36]
Adaptive localization of knowledge negation for continual llm unlearning
Abudukelimu Wuerkaixi, Qizhou Wang, Sen Cui, Wutong Xu, Bo Han, Gang Niu, Masashi Sugiyama, and Changshui Zhang. Adaptive localization of knowledge negation for continual llm unlearning. InICML, 2025
work page 2025
-
[37]
Obliviate: Robust and practical machine unlearning for large language models
Xiaoyu Xu, Minxin Du, Qingqing Ye, and Haibo Hu. Obliviate: Robust and practical machine unlearning for large language models. InEMNLP, 2025
work page 2025
-
[38]
Unlearning Isn't Deletion: Investigating Reversibility of Machine Unlearning in LLMs
Xiaoyu Xu, Xiang Yue, Yang Liu, Qingqing Ye, Haibo Hu, and Minxin Du. Unlearning isn’t deletion: Investigating reversibility of machine unlearning in llms. arXiv:2505.16831, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tian- hao Li, Tingyu...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Machine unlearning of pre-trained large language models
Jin Yao, Eli Chien, Minxin Du, Xinyao Niu, Tianhao Wang, Zezhou Cheng, and Xiang Yue. Machine unlearning of pre-trained large language models. InACL, pp. 8403–8419, 2024
work page 2024
-
[41]
Yi: Open Foundation Models by 01.AI
Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, Kaidong Yu, Peng Liu, Qiang Liu, Shawn Yue, Senbin Yang, Shiming Yang, Tao Yu, Wen Xie, Wenhao Huang, Xiaohui Hu, Xiaoyi Ren, Xinyao Niu, Pengcheng Nie, Yuchi Xu, Yudong Liu, Yue Wang, Yuxuan Cai, Zhenyu Gu, Zhiyuan Liu, and Zonghong D...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
A closer look at machine unlearning for large language models
Xiaojian Yuan, Tianyu Pang, Chao Du, Kejiang Chen, Weiming Zhang, and Min Lin. A closer look at machine unlearning for large language models. InICLR, 2025. 12 Under Review
work page 2025
-
[43]
Negative Preference Optimization: From Catastrophic Collapse to Effective Unlearning
Ruiqi Zhang, Licong Lin, Yu Bai, and Song Mei. Negative preference optimization: From catastrophic collapse to effective unlearning. arXiv:2404.05868, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Catastrophic failure of LLM unlearning via quantization
Zhiwei Zhang, Fali Wang, Xiaomin Li, Zongyu Wu, Xianfeng Tang, Hui Liu, Qi He, Wenpeng Yin, and Suhang Wang. Catastrophic failure of LLM unlearning via quantization. InICLR, 2025
work page 2025
-
[45]
Spurious forgetting in continual learning of language models
Junhao Zheng, Xidi Cai, Shengjie Qiu, and Qianli Ma. Spurious forgetting in continual learning of language models. InICLR, 2025
work page 2025
-
[46]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, J. Zico Kolter, and Matt Fredrikson. Universal and transferable adversarial attacks on aligned language models. arXiv:2307.15043, 2023. 13 Under Review A APPENDIX A.1 LIMITATIONS Our experiments target two LLMs and a handful of tasks and unlearning methods; although our diagnostic framework is model-agnostic and designed to scale, em...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.