SAM 2++: Tracking Anything at Any Granularity
Pith reviewed 2026-05-21 19:46 UTC · model grok-4.3
The pith
SAM 2++ creates a single model for video tracking at mask, box, or point granularity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
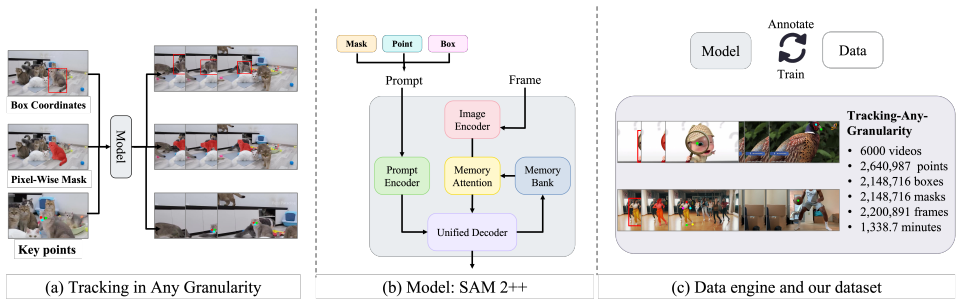
SAM 2++ unifies video tracking tasks at different granularities through task-specific prompts, a Unified Decoder, and a task-adaptive memory mechanism that unifies memory while preserving distinct state semantics, together with the new Tracking-Any-Granularity dataset, achieving state of the art across tasks.
What carries the argument
task-adaptive memory mechanism that unifies memory representations across granularities while preserving distinct state semantics to avoid interference
If this is right
- Multi-task training data from different granularities can be combined without separate models.
- Model design and parameter counts become less redundant across tracking tasks.
- Performance reaches state of the art on benchmarks for masks, boxes, and points.
- A single robust framework replaces task-specific trackers for video tracking.
Where Pith is reading between the lines
- The shared components could extend to other video tasks that mix coarse and fine outputs.
- The new dataset offers a way to study how granularity choice affects tracking accuracy in practice.
- Real-time systems could maintain one model instead of switching between multiple granularity-specific versions.
Load-bearing premise
The task-adaptive memory mechanism can unify memory representations across granularities while preserving distinct state semantics and avoiding interference from full parameter sharing.
What would settle it
A controlled test that removes the task-adaptive memory and shows equal or higher accuracy on all three granularities would indicate the adaptation is not required.
Figures








read the original abstract
Due to the varying granularity of target states across different tasks, most existing trackers are tailored to a single task, which specificity limits their generalization, preventing them from effectively utilizing multi-task training data and leading to redundancy in both model design and parameters. Although recent unified vision models share partial architectures across tasks, they usually retain task-specific interfaces and overlook the common tracking principle behind different granularities, leaving a gap for truly unified video tracking. To unify video tracking tasks, we present SAM 2++, a unified framework that can handle target states at different granularities, including masks, boxes, and points, through an integrated design of prompt encoding, output decoding, and memory representation. First, to handle different target granularities, we design task-specific prompts that map diverse task inputs into general prompt embeddings, together with a Unified Decoder that produces task results in a common output form without redesigning the overall pipeline. Next, to satisfy memory matching, the core operation of tracking, we introduce a task-adaptive memory mechanism that unifies memory across different granularities while preserving their distinct state semantics, preventing full parameter sharing from causing interference across granularities. Finally, we introduce Tracking-Any-Granularity, the first large and diverse video tracking dataset with rich annotations at three granularities. It is constructed through a customized data engine with phased manual annotation and model-assisted completion, providing a comprehensive resource for training, benchmarking, and analyzing unified tracking models. Comprehensive experiments confirm that SAM 2++ sets a new state of the art across diverse tracking tasks at different granularities, establishing a unified and robust tracking framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAM 2++, a unified video tracking framework that handles targets at varying granularities (masks, boxes, points) via task-specific prompt mapping into general embeddings, a Unified Decoder producing common outputs, and a task-adaptive memory mechanism that unifies memory representations while preserving distinct state semantics and avoiding cross-granularity interference. It further contributes the Tracking-Any-Granularity dataset constructed via a phased annotation engine and reports state-of-the-art results across diverse tracking tasks.
Significance. If the central unification claims hold with supporting evidence, the work would offer a meaningful step toward reducing task-specific redundancy in trackers and enabling effective multi-task training. The new dataset would serve as a useful benchmark resource for analyzing granularity-agnostic tracking.
major comments (1)
- [Description of task-adaptive memory mechanism] The task-adaptive memory mechanism is load-bearing for the unification claim, yet the manuscript provides no ablation studies or quantitative comparisons demonstrating that full parameter sharing causes measurable interference or degradation across mask/box/point granularities. No details are given on the adaptation implementation (conditioning vectors, adapters, or state disentanglement) that would allow verification that distinct semantics are preserved during memory matching. This directly affects the robustness of the core tracking operation.
minor comments (1)
- [Abstract] The abstract states that comprehensive experiments confirm SOTA results but does not reference specific baselines, data splits, or error bars; if these details appear only in later sections, cross-referencing them in the abstract would strengthen the high-level claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below and outline the revisions we will make to strengthen the evidence for the task-adaptive memory mechanism.
read point-by-point responses
-
Referee: [Description of task-adaptive memory mechanism] The task-adaptive memory mechanism is load-bearing for the unification claim, yet the manuscript provides no ablation studies or quantitative comparisons demonstrating that full parameter sharing causes measurable interference or degradation across mask/box/point granularities. No details are given on the adaptation implementation (conditioning vectors, adapters, or state disentanglement) that would allow verification that distinct semantics are preserved during memory matching. This directly affects the robustness of the core tracking operation.
Authors: We agree that the current manuscript would be strengthened by explicit ablation studies and expanded implementation details for the task-adaptive memory. The design is intended to unify memory representations across granularities while using task-specific adaptation to preserve distinct state semantics and prevent interference, but we acknowledge that quantitative comparisons against a fully shared baseline are not reported. In the revised version, we will add ablation experiments that measure performance degradation from cross-granularity interference under full parameter sharing, along with concrete details on the adaptation implementation including conditioning vectors, adapter modules, and the state disentanglement process used during memory matching. These additions will directly support the robustness claims for the core tracking operation. revision: yes
Circularity Check
No circularity: claims rest on new mechanisms, dataset, and experiments without reduction to fitted inputs or self-citations
full rationale
The abstract and provided text describe an integrated design of prompt encoding, output decoding, and task-adaptive memory for unifying mask/box/point tracking granularities, plus a new Tracking-Any-Granularity dataset constructed via a data engine. No equations, parameter-fitting steps, or derivations are presented that would make any 'prediction' equivalent to its inputs by construction. No self-citation load-bearing arguments, uniqueness theorems imported from the same authors, or ansatzes smuggled via prior work appear in the given material. The SOTA claims are tied to comprehensive experiments on the new dataset rather than tautological redefinitions or forced statistical outcomes from subsets of prior data. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- task-specific prompt mapping parameters
axioms (1)
- domain assumption There exists a common tracking principle behind different granularities that permits a shared architecture without task-specific redesign of the overall pipeline.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we introduce a task-adaptive memory mechanism that unifies memory across different granularities while preserving their distinct state semantics, preventing full parameter sharing from causing interference across granularities
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SAM 2++ sets a new state of the art across diverse tracking tasks at different granularities
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Burst: A benchmark for unifying object recognition, segmentation and tracking in video
Ali Athar, Jonathon Luiten, Paul V oigtlaender, Tarasha Khu- rana, Achal Dave, Bastian Leibe, and Deva Ramanan. Burst: A benchmark for unifying object recognition, segmentation and tracking in video. InProceedings of the IEEE/CVF Win- ter Conference on Applications of Computer Vision (WACV), pages 1674–1683, 2023. 6, 7
work page 2023
-
[2]
Track-on: Transformer-based online point tracking with memory
G ¨orkay Aydemir, Xiongyi Cai, Weidi Xie, and Fatma G¨uney. Track-on: Transformer-based online point tracking with memory. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24- 28, 2025. OpenReview.net, 2025. 7
work page 2025
-
[3]
Ar- trackv2: Prompting autoregressive tracker where to look and how to describe
Yifan Bai, Zeyang Zhao, Yihong Gong, and Xing Wei. Ar- trackv2: Prompting autoregressive tracker where to look and how to describe. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19048– 19057, 2024. 7
work page 2024
-
[4]
A benchmark and simulator for uav track- ing
UT Benchmark. A benchmark and simulator for uav track- ing. InEuropean conference on computer vision, 2016. 6
work page 2016
-
[5]
Creatures great and SMAL: Recovering the shape and motion of animals from video
Benjamin Biggs, Thomas Roddick, Andrew Fitzgibbon, and Roberto Cipolla. Creatures great and SMAL: Recovering the shape and motion of animals from video. InACCV, 2018. 1, 7
work page 2018
-
[6]
Hiptrack: Visual tracking with historical prompts
Wenrui Cai, Qingjie Liu, and Yunhong Wang. Hiptrack: Visual tracking with historical prompts. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19258–19267, 2024. 7
work page 2024
-
[7]
Ro- bust object modeling for visual tracking
Yidong Cai, Jie Liu, Jie Tang, and Gangshan Wu. Ro- bust object modeling for visual tracking. InProceedings of the IEEE/CVF international conference on computer vision, pages 9589–9600, 2023. 7
work page 2023
-
[8]
Pix2seq: A language modeling framework for object detection.arXiv preprint arXiv:2109.10852, 2021
Ting Chen, Saurabh Saxena, Lala Li, David J Fleet, and Ge- offrey Hinton. Pix2seq: A language modeling framework for object detection.arXiv preprint arXiv:2109.10852, 2021. 1, 2
-
[9]
Sam-adapter: Adapting segment anything in underperformed scenes
Tianrun Chen, Lanyun Zhu, Chaotao Deng, Runlong Cao, Yan Wang, Shangzhan Zhang, Zejian Li, Lingyun Sun, Ying Zang, and Papa Mao. Sam-adapter: Adapting segment anything in underperformed scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3367–3375, 2023. 2
work page 2023
-
[10]
Seqtrack: Sequence to sequence learning for visual ob- ject tracking
Xin Chen, Houwen Peng, Dong Wang, Huchuan Lu, and Han Hu. Seqtrack: Sequence to sequence learning for visual ob- ject tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14572– 14581, 2023. 7
work page 2023
-
[11]
Ho Kei Cheng and Alexander G. Schwing. Xmem: Long- term video object segmentation with an atkinson-shiffrin memory model. InComputer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXVIII, 2022. 7
work page 2022
-
[12]
Ho Kei Cheng, Yu-Wing Tai, and Chi-Keung Tang. Rethink- ing space-time networks with improved memory coverage for efficient video object segmentation. InAdvances in Neu- ral Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, 2021. 7
work page 2021
-
[13]
Ho Kei Cheng, Seoung Wug Oh, Brian L. Price, Alexan- der G. Schwing, and Joon-Young Lee. Tracking anything with decoupled video segmentation. InIEEE/CVF Interna- tional Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, 2023. 7
work page 2023
-
[14]
Price, Joon-Young Lee, and Alexander G
Ho Kei Cheng, Seoung Wug Oh, Brian L. Price, Joon-Young Lee, and Alexander G. Schwing. Putting the object back into video object segmentation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, 2024. 7
work page 2024
-
[15]
Local all-pair corre- spondence for point tracking
Seokju Cho, Jiahui Huang, Jisu Nam, Honggyu An, Seun- gryong Kim, and Joon-Young Lee. Local all-pair corre- spondence for point tracking. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part X, pages 306–325. Springer, 2024. 7
work page 2024
-
[16]
Yutao Cui, Cheng Jiang, Gangshan Wu, and Limin Wang. Mixformer: End-to-end tracking with iterative mixed atten- tion.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. 7
work page 2024
-
[17]
Samwise: Infusing wisdom in sam2 for text-driven video segmentation, 2024
Claudia Cuttano, Gabriele Trivigno, Gabriele Rosi, Carlo Masone, and Giuseppe Averta. Samwise: Infusing wisdom in sam2 for text-driven video segmentation, 2024. 2
work page 2024
-
[18]
Epic-kitchens visor benchmark: Video segmenta- tions and object relations
Ahmad Darkhalil, Dandan Shan, Bin Zhu, Jian Ma, Amlan Kar, Richard Higgins, Sanja Fidler, David Fouhey, and Dima Damen. Epic-kitchens visor benchmark: Video segmenta- tions and object relations. InAdvances in Neural Information Processing Systems, pages 13745–13758. Curran Associates, Inc., 2022. 7
work page 2022
-
[19]
Henghui Ding, Chang Liu, Shuting He, Xudong Jiang, Philip H.S. Torr, and Song Bai. Mose: A new dataset for video object segmentation in complex scenes. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision (ICCV), pages 20224–20234, 2023. 4, 6, 7, 1
work page 2023
-
[20]
Shuangrui Ding, Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Yuhang Cao, Yuwei Guo, Dahua Lin, and Jiaqi Wang. Sam2long: Enhancing sam 2 for long video seg- mentation with a training-free memory tree.arXiv preprint arXiv:2410.16268, 2024. 2
-
[21]
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adria Re- casens, Lucas Smaira, Yusuf Aytar, Joao Carreira, Andrew Zisserman, and Yi Yang. TAP-vid: A benchmark for track- ing any point in a video.Advances in Neural Information Processing Systems, 35:13610–13626, 2022. 1, 4, 6, 7
work page 2022
-
[22]
Tapir: Tracking any point with per-frame initialization and temporal refinement
Carl Doersch, Yi Yang, Mel Vecerik, Dilara Gokay, Ankush Gupta, Yusuf Aytar, Joao Carreira, and Andrew Zisserman. Tapir: Tracking any point with per-frame initialization and temporal refinement. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 10061– 10072, 2023. 7
work page 2023
-
[23]
Lasot: A high-quality benchmark for large-scale single ob- ject tracking
Heng Fan, Liting Lin, Fan Yang, Peng Chu, Ge Deng, Sijia Yu, Hexin Bai, Yong Xu, Chunyuan Liao, and Haibin Ling. Lasot: A high-quality benchmark for large-scale single ob- ject tracking. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2019. 1, 4, 6
work page 2019
-
[24]
Generalized relation modeling for transformer tracking
Shenyuan Gao, Chunluan Zhou, and Jun Zhang. Generalized relation modeling for transformer tracking. InProceedings of 9 the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18686–18695, 2023. 7
work page 2023
-
[25]
Ross Goroshin, Michael F Mathieu, and Yann LeCun. Learn- ing to linearize under uncertainty.Advances in neural infor- mation processing systems, 28, 2015. 3
work page 2015
-
[26]
Tag: Tracking at any granularity, 2024
Adam Harley, Yang You, Yang Zheng, Xinglong Sun, Nikhil Raghuraman, Sheldon Liang, Wen-Hsuan Chu, Suya You, Achal Dave, Pavel Tokmakov, Rares Ambrus, Katerina Fragkiadaki, and Leonidas Guibas. Tag: Tracking at any granularity, 2024. 7, 8
work page 2024
-
[27]
Particle video revisited: Tracking through occlusions using point trajectories
Adam W Harley, Zhaoyuan Fang, and Katerina Fragkiadaki. Particle video revisited: Tracking through occlusions using point trajectories. InEuropean Conference on Computer Vi- sion, pages 59–75. Springer, 2022. 7
work page 2022
-
[28]
Lvos: A benchmark for long-term video object segmentation
Lingyi Hong, Wenchao Chen, Zhongying Liu, Wei Zhang, Pinxue Guo, Zhaoyu Chen, and Wenqiang Zhang. Lvos: A benchmark for long-term video object segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13480–13492, 2023. 1, 6
work page 2023
-
[29]
Lingyi Hong, Zhongying Liu, Wenchao Chen, Chenzhi Tan, Yuang Feng, Xinyu Zhou, Pinxue Guo, Jinglun Li, Zhaoyu Chen, Shuyong Gao, et al. Lvos: A benchmark for large- scale long-term video object segmentation.arXiv preprint arXiv:2404.19326, 2024. 6, 7
-
[30]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Represen- tations, ICLR 2022, Virtual Event, April 25-29, 2022. Open- Review.net, 2022. 4
work page 2022
-
[31]
Lianghua Huang, Xin Zhao, and Kaiqi Huang. Got-10k: A large high-diversity benchmark for generic object tracking in the wild.IEEE Transactions on Pattern Analysis and Ma- chine Intelligence, 43(5):1562–1577, 2021. 1, 4, 6, 7
work page 2021
-
[32]
Shaofei Huang, Rui Ling, Hongyu Li, Tianrui Hui, Zongheng Tang, Xiaoming Wei, Jizhong Han, and Si Liu. Unleashing the temporal-spatial reasoning capacity of gpt for training-free audio and language referenced video object segmentation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3715–3723, 2025. 2
work page 2025
-
[33]
Co- tracker3: Simpler and better point tracking by pseudo- labelling real videos
Nikita Karaev, Iurii Makarov, Jianyuan Wang, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker3: Simpler and better point tracking by pseudo- labelling real videos.CoRR, abs/2410.11831, 2024. 7
-
[34]
Co- tracker: It is better to track together
Nikita Karaev, Ignacio Rocco, Benjamin Graham, Natalia Neverova, Andrea Vedaldi, and Christian Rupprecht. Co- tracker: It is better to track together. InComputer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXII, pages 18–35. Springer, 2024. 7
work page 2024
-
[35]
Segment anything in high quality
Lei Ke, Mingqiao Ye, Martin Danelljan, Yifan Liu, Yu-Wing Tai, Chi-Keung Tang, and Fisher Yu. Segment anything in high quality. InNeurIPS, 2023. 2
work page 2023
-
[36]
Need for speed: A benchmark for higher frame rate object tracking
Hamed Kiani Galoogahi, Ashton Fagg, Chen Huang, Deva Ramanan, and Simon Lucey. Need for speed: A benchmark for higher frame rate object tracking. InProceedings of the IEEE International Conference on Computer Vision (ICCV),
-
[37]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer White- head, Alexander C. Berg, Wan-Yen Lo, Piotr Doll ´ar, and Ross Girshick. Segment anything.arXiv:2304.02643, 2023. 2, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
TAPTR: tracking any point with transformers as detection
Hongyang Li, Hao Zhang, Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, and Lei Zhang. TAPTR: tracking any point with transformers as detection. InComputer Vi- sion - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XVI, pages 57–75. Springer, 2024. 7
work page 2024
-
[39]
Onevos: unifying video object segmentation with all-in-one transformer framework
Wanyun Li, Pinxue Guo, Xinyu Zhou, Lingyi Hong, Yangji He, Xiangyu Zheng, Wei Zhang, and Wenqiang Zhang. Onevos: unifying video object segmentation with all-in-one transformer framework. InEuropean Conference on Com- puter Vision, pages 20–40. Springer, 2024. 7
work page 2024
-
[40]
Tracking meets lora: Faster training, larger model, stronger performance
Liting Lin, Heng Fan, Zhipeng Zhang, Yaowei Wang, Yong Xu, and Haibin Ling. Tracking meets lora: Faster training, larger model, stronger performance. InEuropean Confer- ence on Computer Vision, pages 300–318. Springer, 2024. 7
work page 2024
-
[41]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer vision–ECCV 2014: 13th European conference, zurich, Switzerland, September 6-12, 2014, proceedings, part v 13, pages 740–755. Springer, 2014. 4, 1
work page 2014
-
[42]
SAMRefiner: Taming segment anything model for universal mask refine- ment
Yuqi Lin, Hengjia Li, Wenqi Shao, Zheng Yang, Jun Zhao, Xiaofei He, Ping Luo, and Kaipeng Zhang. SAMRefiner: Taming segment anything model for universal mask refine- ment. InThe Thirteenth International Conference on Learn- ing Representations, 2025. 2
work page 2025
-
[43]
Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taix´e, and Bastian Leibe. Hota: A higher order metric for evaluating multi-object tracking.International Journal of Computer Vision, pages 1–31, 2020. 7
work page 2020
-
[44]
Trackingnet: A large-scale dataset and benchmark for object tracking in the wild
Matthias Muller, Adel Bibi, Silvio Giancola, Salman Al- subaihi, and Bernard Ghanem. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. InThe European Conference on Computer Vision (ECCV), 2018. 1, 4, 6, 7
work page 2018
-
[45]
Simtrack: A simulation- based framework for scalable real-time object pose detection and tracking
Karl Pauwels and Danica Kragic. Simtrack: A simulation- based framework for scalable real-time object pose detection and tracking. In2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1300–1307. IEEE, 2015. 7
work page 2015
-
[46]
Vast- track: Vast category visual object tracking
Liang Peng, Junyuan Gao, Xinran Liu, Weihong Li, Shaohua Dong, Zhipeng Zhang, Heng Fan, and Libo Zhang. Vast- track: Vast category visual object tracking. InAdvances in Neural Information Processing Systems 38: Annual Con- ference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024. 6, 7
work page 2024
-
[47]
A benchmark dataset and evaluation methodology for video 10 object segmentation
Federico Perazzi, Jordi Pont-Tuset, Brian McWilliams, Luc Van Gool, Markus Gross, and Alexander Sorkine-Hornung. A benchmark dataset and evaluation methodology for video 10 object segmentation. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. 7
work page 2016
-
[48]
The 2017 DAVIS Challenge on Video Object Segmentation
Jordi Pont-Tuset, Federico Perazzi, Sergi Caelles, Pablo Ar- bel´aez, Alex Sorkine-Hornung, and Luc Van Gool. The 2017 davis challenge on video object segmentation.arXiv preprint arXiv:1704.00675, 2017. 1, 4, 6
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[49]
Perception test: A diagnostic benchmark for multimodal video models
Viorica P ˘atr˘aucean, Lucas Smaira, Ankush Gupta, Adri`a Re- casens Continente, Larisa Markeeva, Dylan Banarse, Skanda Koppula, Joseph Heyward, Mateusz Malinowski, Yi Yang, Carl Doersch, Tatiana Matejovicova, Yury Sulsky, Antoine Miech, Alex Frechette, Hanna Klimczak, Raphael Koster, Junlin Zhang, Stephanie Winkler, Yusuf Aytar, Simon Osin- dero, Dima Da...
work page 2023
-
[50]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Breaking the “object” in video object segmentation
Pavel Tokmakov, Jie Li, and Adrien Gaidon. Breaking the “object” in video object segmentation. InCVPR, 2023. 6, 7
work page 2023
-
[52]
A distractor-aware memory for visual object tracking with sam2.arXiv preprint arXiv:2411.17576, 2024
Jovana Videnovic, Alan Lukezic, and Matej Kristan. A distractor-aware memory for visual object tracking with sam2.arXiv preprint arXiv:2411.17576, 2024. 2
-
[53]
Omnitracker: Unifying visual object tracking by tracking-with-detection
Junke Wang, Zuxuan Wu, Dongdong Chen, Chong Luo, Xiyang Dai, Lu Yuan, and Yu-Gang Jiang. Omnitracker: Unifying visual object tracking by tracking-with-detection. IEEE Trans. Pattern Anal. Mach. Intell., 47(4):3159–3174,
-
[54]
Towards more flexible and accurate object tracking with natural language: Algo- rithms and benchmark
Xiao Wang, Xiujun Shu, Zhipeng Zhang, Bo Jiang, Yaowei Wang, Yonghong Tian, and Feng Wu. Towards more flexible and accurate object tracking with natural language: Algo- rithms and benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13763–13773, 2021. 6, 7
work page 2021
-
[55]
Zhongdao Wang, Hengshuang Zhao, Ya-Li Li, Shengjin Wang, Philip Torr, and Luca Bertinetto. Do different track- ing tasks require different appearance models?Advances in neural information processing systems, 34:726–738, 2021. 1, 2
work page 2021
-
[56]
Autoregressive visual tracking
Xing Wei, Yifan Bai, Yongchao Zheng, Dahu Shi, and Yi- hong Gong. Autoregressive visual tracking. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9697–9706, 2023. 7
work page 2023
-
[57]
Dropmae: Masked autoen- coders with spatial-attention dropout for tracking tasks
Qiangqiang Wu, Tianyu Yang, Ziquan Liu, Baoyuan Wu, Ying Shan, and Antoni B Chan. Dropmae: Masked autoen- coders with spatial-attention dropout for tracking tasks. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14561–14571, 2023. 7
work page 2023
-
[58]
Object track- ing benchmark.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015
Yi Wu, Jongwoo Lim, and Ming-Hsuan Yang. Object track- ing benchmark.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015. 6
work page 2015
-
[59]
Cat-sam: Con- ditional tuning for few-shot adaptation of segment anything model
Aoran Xiao, Weihao Xuan, Heli Qi, Yun Xing, Ruijie Ren, Xiaoqin Zhang, Ling Shao, and Shijian Lu. Cat-sam: Con- ditional tuning for few-shot adaptation of segment anything model. InEuropean Conference on Computer Vision, pages 189–206. Springer, 2024. 2
work page 2024
-
[60]
YouTube-VOS: A Large-Scale Video Object Segmentation Benchmark
Ning Xu, Linjie Yang, Yuchen Fan, Dingcheng Yue, Yuchen Liang, Jianchao Yang, and Thomas Huang. Youtube-vos: A large-scale video object segmentation benchmark.arXiv preprint arXiv:1809.03327, 2018. 1, 4, 6, 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[61]
Integrating boxes and masks: A multi-object framework for unified visual tracking and segmentation
Yuanyou Xu, Zongxin Yang, and Yi Yang. Integrating boxes and masks: A multi-object framework for unified visual tracking and segmentation. InIEEE/CVF International Con- ference on Computer Vision, ICCV 2023, Paris, France, Oc- tober 1-6, 2023, pages 9704–9717. IEEE, 2023. 7
work page 2023
-
[62]
Learning spatio-temporal transformer for vi- sual tracking
Bin Yan, Houwen Peng, Jianlong Fu, Dong Wang, and Huchuan Lu. Learning spatio-temporal transformer for vi- sual tracking. InProceedings of the IEEE/CVF international conference on computer vision, pages 10448–10457, 2021. 4
work page 2021
-
[63]
Towards grand unification of object tracking
Bin Yan, Yi Jiang, Peize Sun, Dong Wang, Zehuan Yuan, Ping Luo, and Huchuan Lu. Towards grand unification of object tracking. InComputer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXI, pages 733–751. Springer, 2022. 1, 2, 7
work page 2022
-
[64]
Universal instance perception as object discovery and retrieval
Bin Yan, Yi Jiang, Jiannan Wu, Dong Wang, Ping Luo, Ze- huan Yuan, and Huchuan Lu. Universal instance perception as object discovery and retrieval. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 15325– 15336. IEEE, 2023. 1, 2, 7
work page 2023
-
[65]
Cheng-Yen Yang, Hsiang-Wei Huang, Wenhao Chai, Zhongyu Jiang, and Jenq-Neng Hwang. Samurai: Adapting segment anything model for zero-shot visual tracking with motion-aware memory, 2024. 2
work page 2024
-
[66]
Decoupling features in hier- archical propagation for video object segmentation
Zongxin Yang and Yi Yang. Decoupling features in hier- archical propagation for video object segmentation. InAd- vances in Neural Information Processing Systems 35: An- nual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. 7
work page 2022
-
[67]
Associating ob- jects with transformers for video object segmentation
Zongxin Yang, Yunchao Wei, and Yi Yang. Associating ob- jects with transformers for video object segmentation. In Advances in Neural Information Processing Systems 34: An- nual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, 2021. 7
work page 2021
-
[68]
Joint feature learning and relation modeling for tracking: A one-stream framework
Botao Ye, Hong Chang, Bingpeng Ma, Shiguang Shan, and Xilin Chen. Joint feature learning and relation modeling for tracking: A one-stream framework. InEuropean conference on computer vision, pages 341–357. Springer, 2022. 7
work page 2022
-
[69]
Unifiedtt: Visual tracking with unified transformer
Peng Yu, Zhuolei Duan, Sujie Guan, Min Li, and Shaobo Deng. Unifiedtt: Visual tracking with unified transformer. Journal of Visual Communication and Image Representation, 99:104067, 2024. 1
work page 2024
-
[70]
Jointformer: A unified framework with joint modeling for video object segmentation.IEEE Trans
Jiaming Zhang, Yutao Cui, Gangshan Wu, and Limin Wang. Jointformer: A unified framework with joint modeling for video object segmentation.IEEE Trans. Pattern Anal. Mach. Intell., 47(7):6039–6054, 2025. 7 11
work page 2025
-
[71]
Pointodyssey: A large-scale synthetic dataset for long-term point tracking
Yang Zheng, Adam W Harley, Bokui Shen, Gordon Wet- zstein, and Leonidas J Guibas. Pointodyssey: A large-scale synthetic dataset for long-term point tracking. InProceed- ings of the IEEE/CVF International Conference on Com- puter Vision, pages 19855–19865, 2023. 1, 4, 6, 7
work page 2023
-
[72]
Distance-iou loss: Faster and better learning for bounding box regression
Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, and Dongwei Ren. Distance-iou loss: Faster and better learning for bounding box regression. InThe AAAI Confer- ence on Artificial Intelligence (AAAI), pages 12993–13000,
-
[73]
Xizhou Zhu, Jinguo Zhu, Hao Li, Xiaoshi Wu, Hongsheng Li, Xiaohua Wang, and Jifeng Dai. Uni-perceiver: Pre- training unified architecture for generic perception for zero- shot and few-shot tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16804–16815, 2022. 1, 2 12 SAM 2++: Tracking Anything at Any Granulari...
work page 2022
-
[74]
Model Details 8.1. Model Architecture Task-Specific Prompt.In order to unify the different in- puts for each task and not modify the structure of the orig- inal Prompt Encoder, we providetask-specific promptfor each task, which provides an accurate and efficient repre- sentation of the target state of each task. The design of the task-specific prompt for ...
work page 2017
-
[75]
Data Details The key features of this dataset are as follows: (1) High Resolution: The dataset consists of high-resolution videos, ensuring that fine details are preserved and enabling more accurate analysis. (2) Diversity: It encompasses a wide va- riety of scenes, sources, and tracked object categories, pro- viding a rich and representative sample of re...
-
[76]
Video Selection.We downloaded a large number of videos from YouTube and instructed the annotators to select videos and objects that meet the above requirements
-
[77]
Coarse Annotation.Annotators mark key points and tight bounding boxes on target objects
-
[78]
Fine Annotation.To reduce annotator workload and improve efficiency, we use SAM [37] to generate rough masks based on the coarse annotations (points and boxes). Then, annotators refine these masks with the following re- quirements: • Only annotate the visible parts of the present object. • In cases of motion blur, infer the approximate position based on t...
-
[79]
Final Completion.Experts perform a final review to thoroughly assess the accuracy and consistency of all three types of annotations, ensuring that the labeling meets the required standards and that any discrepancies are identified and corrected. 9.3. Data engine To increase the size of the dataset while reducing the work- load, we adopted a selective anno...
-
[80]
Additional Experiments 10.1. Performance Comparison Evaluation metrics.Invideo object segmentationtask, we use standard metrics [47] in most benchmarks: Jaccard indexJ, contour accuracyF, and their averageJ&F. In the YouTubeVOS benchmark,JandFare computed for ”seen” and ”unseen” categories separately.Gis the averagedJ&Ffor both seen and unseen classes. In...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.