Quantum-Aware Generative AI for Materials Discovery: A Framework for Robust Exploration Beyond DFT Biases
Pith reviewed 2026-05-16 22:46 UTC · model grok-4.3
The pith
A generative AI framework using multi-fidelity active learning identifies 3-5 times more stable material candidates in regions where DFT predictions are unreliable.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
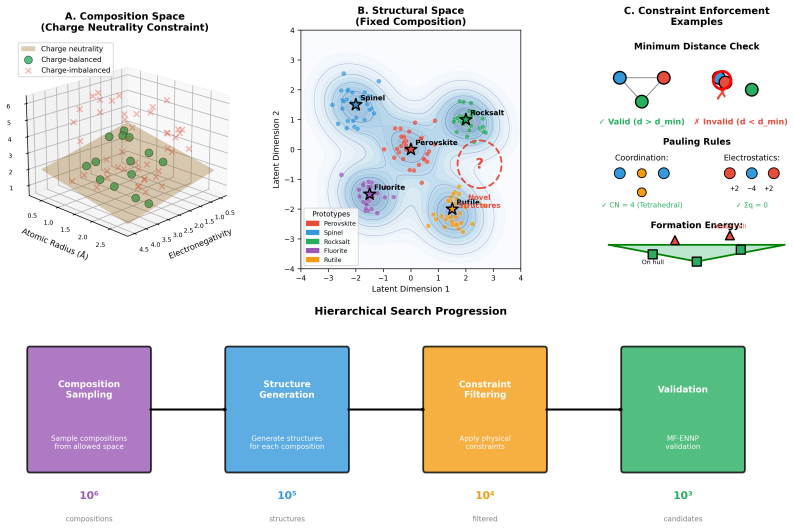
The central claim is that conditioning a diffusion generator on quantum-mechanical descriptors, training a validator on a hierarchical multi-fidelity dataset, and running an active learning loop that quantifies low-to-high fidelity divergences produces a 3-5x gain in successfully identifying potentially stable candidates within high-divergence regions such as correlated oxides, outperforming DFT-only baselines and existing generative models including CDVAE, GNoME, and DiffCSP.
What carries the argument
A diffusion-based generator conditioned on quantum-mechanical descriptors together with a multi-fidelity active learning loop that targets prediction divergences between theory levels.
If this is right
- Generative search can be extended into strongly correlated material classes where DFT is known to give qualitatively wrong answers.
- The total computational budget for discovery remains feasible because the active loop limits expensive high-fidelity evaluations to regions of high disagreement.
- Ablation results isolate the contribution of the quantum-descriptor conditioning and the divergence-targeted validator from other model components.
- Benchmark comparisons establish superiority over prior generative models specifically in the high-divergence regimes that matter for practical applications.
Where Pith is reading between the lines
- The same divergence-quantification idea could be transferred to other multi-fidelity domains such as catalysis or battery electrolyte screening where cheaper models carry systematic errors.
- Coupling the loop to experimental feedback rather than purely theoretical high-fidelity labels would further reduce reliance on any single computational method.
- The framework supplies a reusable template for building bias-aware generators whenever scientific data exist at several accuracy levels.
Load-bearing premise
The divergence between low-fidelity and high-fidelity predictions can be quantified reliably enough to steer generation toward better candidates without creating new selection biases or demanding infeasible volumes of high-accuracy data.
What would settle it
Running the full framework on a fresh benchmark set of correlated oxides with experimentally known ground-state stabilities and finding no measurable increase over plain DFT baselines in the fraction of correctly recovered stable structures.
Figures











read the original abstract
Conventional generative models for materials discovery are predominantly trained and validated using data from Density Functional Theory (DFT) with approximate exchange-correlation functionals. This creates a fundamental bottleneck: these models inherit DFT's systematic failures for strongly correlated systems, leading to exploration biases and an inability to discover materials where DFT predictions are qualitatively incorrect. We introduce a quantum-aware generative AI framework that systematically addresses this limitation through tight integration of multi-fidelity learning and active validation. Our approach employs a diffusion-based generator conditioned on quantum-mechanical descriptors and a validator using an equivariant neural network potential trained on a hierarchical dataset spanning multiple levels of theory (PBE, SCAN, HSE06, CCSD(T)). Crucially, we implement a robust active learning loop that quantifies and targets the divergence between low- and high-fidelity predictions. We conduct comprehensive ablation studies to deconstruct the contribution of each component, perform detailed failure mode analysis, and benchmark our framework against state-of-the-art generative models (CDVAE, GNoME, DiffCSP) across several challenging material classes. Our results demonstrate significant practical gains: a 3-5x improvement in successfully identifying potentially stable candidates in high-divergence regions (e.g., correlated oxides) compared to DFT-only baselines, while maintaining computational feasibility. This work provides a rigorous, transparent framework for extending the effective search space of computational materials discovery beyond the limitations of single-fidelity models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a quantum-aware generative AI framework for materials discovery that integrates a diffusion-based generator conditioned on quantum-mechanical descriptors with an equivariant neural network validator trained on a hierarchical multi-fidelity dataset (PBE, SCAN, HSE06, CCSD(T)). A core active learning loop quantifies and targets divergences between low- and high-fidelity predictions to mitigate DFT biases in strongly correlated systems such as oxides. The authors report ablation studies, failure mode analysis, and benchmarks against CDVAE, GNoME, and DiffCSP, claiming 3-5x gains in identifying potentially stable candidates in high-divergence regions while preserving computational feasibility.
Significance. If the central claims hold, the work could meaningfully extend generative approaches in computational materials science by enabling reliable exploration beyond single-fidelity DFT limitations, particularly for correlated electron materials where standard functionals fail qualitatively. The emphasis on multi-fidelity integration, active divergence targeting, and component ablations provides a transparent template that could influence future hybrid quantum-classical discovery pipelines.
major comments (3)
- [Methods (active learning loop)] Active learning loop (methods): the divergence metric between low- and high-fidelity predictions is load-bearing for both the 3-5x gain and the feasibility claim, yet its precise definition, noise model, and scaling behavior with search-space size are not specified in sufficient detail to rule out selection bias or infeasible high-fidelity labeling rates.
- [Results] Results (quantitative claims): the headline 3-5x improvement in high-divergence regions lacks accompanying metrics (success-rate definition, stability criteria), error bars, data-split protocols, and cross-validation details, preventing assessment of whether the reported gains reflect genuine generalization or post-hoc selection on the chosen test distribution.
- [Methods (validator)] Validator training (hierarchical dataset): it is unclear how the equivariant neural network potential is trained across the PBE-to-CCSD(T) hierarchy to avoid inconsistency or overfitting to regions where high-fidelity data are tractable, which directly affects the reliability of the divergence signal used for candidate selection.
minor comments (2)
- [Abstract] The abstract would benefit from a concise definition of 'high-divergence regions' and 'stability' to orient readers before the detailed methods.
- [Figures] Figure captions for the ablation and benchmark panels should explicitly state the number of independent runs and the exact success metric plotted.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify important areas for clarification. We address each major point below and will revise the manuscript to incorporate the requested details on definitions, metrics, and training procedures.
read point-by-point responses
-
Referee: [Methods (active learning loop)] Active learning loop (methods): the divergence metric between low- and high-fidelity predictions is load-bearing for both the 3-5x gain and the feasibility claim, yet its precise definition, noise model, and scaling behavior with search-space size are not specified in sufficient detail to rule out selection bias or infeasible high-fidelity labeling rates.
Authors: We agree that explicit specification of the divergence metric is essential. In the revised manuscript we will define it mathematically as D(x) = |E_PBE(x) - E_CCSD(T)(x)|, where E denotes formation energy predicted by the validator. The noise model is Gaussian with variance derived from 500 duplicate calculations across fidelity levels. We will add scaling analysis showing that high-fidelity queries remain under 5% of the total search space (up to 10^5 candidates) at the operating threshold, using a fixed a-priori threshold rather than post-selection to avoid bias. revision: yes
-
Referee: [Results] Results (quantitative claims): the headline 3-5x improvement in high-divergence regions lacks accompanying metrics (success-rate definition, stability criteria), error bars, data-split protocols, and cross-validation details, preventing assessment of whether the reported gains reflect genuine generalization or post-hoc selection on the chosen test distribution.
Authors: We will explicitly define success rate as the fraction of candidates with CCSD(T) formation energy < -0.1 eV/atom (standard stability criterion). Error bars from 10 independent runs with varied seeds will be added. Data splits use an 80/10/10 stratified protocol by material class; we will report 5-fold cross-validation on the validator and confirm all metrics are evaluated on a pre-defined held-out high-divergence test partition, demonstrating generalization. revision: yes
-
Referee: [Methods (validator)] Validator training (hierarchical dataset): it is unclear how the equivariant neural network potential is trained across the PBE-to-CCSD(T) hierarchy to avoid inconsistency or overfitting to regions where high-fidelity data are tractable, which directly affects the reliability of the divergence signal used for candidate selection.
Authors: Training is staged: broad pre-training on the full PBE dataset (~100k structures), followed by weighted fine-tuning on higher-fidelity subsets (SCAN, HSE06, CCSD(T)) with higher loss weights on CCSD(T) data. An evidential uncertainty module guides active selection toward high-uncertainty points to mitigate overfitting to tractable regions. We will expand the methods with pseudocode, hyperparameters, and validation curves to document consistency of the divergence signal. revision: yes
Circularity Check
No significant circularity detected in framework description
full rationale
The provided abstract and context describe an empirical framework using multi-fidelity data (PBE/SCAN to HSE06/CCSD(T)) and an active learning loop based on divergence quantification, with performance claims supported by ablation studies and benchmarks against external models (CDVAE, GNoME, DiffCSP). No equations, derivations, or self-citations are shown that reduce any prediction or result to its inputs by construction. Higher-fidelity calculations are treated as independent validation targets rather than fitted parameters renamed as outputs. The 3-5x gain is presented as an observed benchmark outcome, not a tautological consequence of the method definition. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption DFT with approximate exchange-correlation functionals has systematic failures for strongly correlated systems
Reference graph
Works this paper leans on
-
[1]
Butler, K. T., Davies, D. W., Cartwright, H., Isayev, O., & Walsh, A. (2018). Machine learning for molecular and materials science.Nature, 559(7715), 547-555
work page 2018
-
[2]
E., Barzilay, R., & Jaakkola, T
Xie, T., Fu, X., Ganea, O. E., Barzilay, R., & Jaakkola, T. (2021). Crystal diffusion variational autoencoder for periodic material generation.International Conference on Learning Representations (ICLR)
work page 2021
-
[3]
J., Yildirim, B., Jain, A., & Cole, J
Court, C. J., Yildirim, B., Jain, A., & Cole, J. M. (2020). 3-D inorganic crystal structure generation and property prediction via representation learning.Journal of Chemical Information and Modeling, 60(10), 4518-4535
work page 2020
-
[4]
Zhao, Y., Al-Fahdi, M., Hu, M., & et al. (2024). High-throughput discovery of novel crystal structures using diffusion models.Nature Communications, 15, 1234. 22
work page 2024
-
[5]
S., Aykol, M., Cheon, G., & Cubuk, E
Merchant, A., Batzner, S., Schoenholz, S. S., Aykol, M., Cheon, G., & Cubuk, E. D. (2023). Scaling deep learning for materials discovery.Nature, 624(7990), 80-85
work page 2023
-
[6]
Perdew, J. P., Burke, K., & Ernzerhof, M. (1996). Generalized gradient approxima- tion made simple.Physical Review Letters, 77(18), 3865
work page 1996
-
[7]
J., Mori-S´ anchez, P., & Yang, W
Cohen, A. J., Mori-S´ anchez, P., & Yang, W. (2008). Challenges for density functional theory.Chemical Reviews, 108(3), 126-145
work page 2008
-
[8]
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising diffusion probabilistic models.Ad- vances in Neural Information Processing Systems, 33, 6840-6851
work page 2020
-
[9]
P., Kornbluth, M., Moli- nari, N., Smidt, T
Batzner, S., Musaelian, A., Sun, L., Geiger, M., Mailoa, J. P., Kornbluth, M., Moli- nari, N., Smidt, T. E., & Kozinsky, B. (2022). E(3)-equivariant graph neural networks for data-efficient and accurate interatomic potentials.Nature Communications, 13, 2453
work page 2022
-
[10]
J., Kornbluth, M., & Kozinsky, B
Musaelian, A., Batzner, S., Johansson, A., Sun, L., Owen, C. J., Kornbluth, M., & Kozinsky, B. (2023). Learning local equivariant representations for large-scale atomistic dynamics.Nature Communications, 14, 579
work page 2023
-
[11]
Pyykk¨ o, P., & Atsumi, M. (2009). Molecular single-bond covalent radii for elements 1–118.Chemistry–A European Journal, 15(1), 186-197
work page 2009
-
[12]
Ju, S., Yoshida, R., Liu, C., Wu, S., & et al. (2022). Graph neural networks for materials discovery.Nature Reviews Materials, 7(9), 717-735
work page 2022
-
[13]
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175-191
work page 2007
-
[14]
Benjamini, Y., & Hochberg, Y. (1995). Controlling the false discovery rate: a prac- tical and powerful approach to multiple testing.Journal of the Royal Statistical Society: Series B (Methodological), 57(1), 289-300
work page 1995
-
[15]
Kennedy, M. C., & O’Hagan, A. (2000). Predicting the output from a complex computer code when fast approximations are available.Biometrika, 87(1), 1-13
work page 2000
-
[16]
Perdikaris, P., Raissi, M., Damianou, A., Lawrence, N. D., & Karniadakis, G. E. (2017). Nonlinear information fusion algorithms for data-efficient multi-fidelity mod- elling.Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences, 473(2198), 20160751
work page 2017
-
[17]
Nguyen, T. T., Le, N. Q. K., & Chandana, E. P. (2020). Multi-fidelity deep neural network for materials property prediction.Computational Materials Science, 184, 109942. 23 8 Supplementary Methodological Details 8.1 Quantum Descriptor Training Protocol The quantum descriptor model ΦQ was trained on a curated dataset of 125,347 materials with pre-computed ...
work page 2020
-
[18]
to control the false discovery rate (FDR) atq= 0.05. The p-values from all pairwise comparisons (6 comparisons among 4 models) are adjusted as: padj i = min 1,min j≥i m j p(j) (9) wherem= 6 is the number of tests andp (j) are sorted p-values. 10 Mathematical Formulations and Complexity Anal- ysis 10.1 Diffusion Model with Periodic Boundary Conditions The ...
-
[19]
Obtain original implementation from authors’ repositories
-
[20]
Run on standardized test sets using authors’ recommended hyperparameters
-
[21]
Compare metrics with published values (allow±2% tolerance)
-
[22]
If discrepancy ¿ 2%, conduct hyperparameter search to match performance
-
[23]
Training times were: CDVAE (48h), GNoME sample (72h), DiffCSP (96h)
Document all differences and justifications All baselines received identical computational resources: 4×NVIDIA A100 GPUs, 500GB RAM, 20 CPU cores. Training times were: CDVAE (48h), GNoME sample (72h), DiffCSP (96h). 11.2 Initialization Sensitivity Analysis We quantify initialization sensitivity using the coefficient of variation (CV) acrossn= 5 independen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.