GLUE: Coordinating Pre-Trained Generative Models for System-Level Design
Pith reviewed 2026-05-16 20:23 UTC · model grok-4.3
The pith
GLUE coordinates frozen pre-trained generative models to produce feasible, diverse system-level designs such as UAVs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
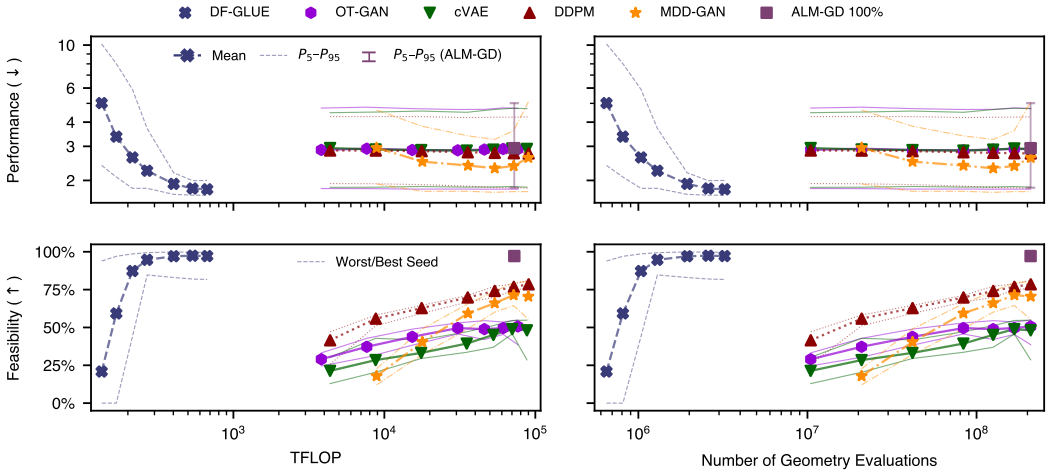
GLUE orchestrates pre-trained, frozen generators while enforcing system-level feasibility, optimality, and diversity. On a UAV design problem with five coupling constraints, data-driven approaches yield diverse, high-performing designs but require large datasets to satisfy constraints reliably. The data-free approach is competitive with Bayesian optimization and gradient-based optimization in performance and feasibility while training a full generative model in only ~10 min on an RTX 4090 GPU, requiring more than two orders of magnitude fewer geometry evaluations and FLOPs than the data-driven method.
What carries the argument
GLUE coordination framework that combines frozen submodel outputs through a differentiable system-level layer to enforce couplings and train for feasibility and diversity.
Load-bearing premise
Compatible submodels must be end-to-end differentiable with a smooth, well-behaved latent-to-output mapping.
What would settle it
On the same UAV task, if the data-free GLUE produces designs with measurably worse performance or feasibility rates than Bayesian optimization while using comparable evaluations, the efficiency and competitiveness claims would not hold.
Figures









read the original abstract
Engineering complex systems (aircraft, buildings, vehicles) requires coordinating geometric and performance couplings across subsystems. As generative models proliferate for specialized domains, a key research gap is how to coordinate frozen, pre-trained submodels to generate full-system designs that are feasible, diverse, and high-performing. We introduce GLUE, which orchestrates pre-trained, frozen generators while enforcing system-level feasibility, optimality, and diversity. Compatible models must be end-to-end differentiable with a smooth, well-behaved latent-to-output mapping. We propose and benchmark (i) data-driven GLUE models trained on pre-generated system-level designs and (ii) a data-free GLUE model trained on a differentiable geometry layer. On a UAV design problem with five coupling constraints, we find that data-driven approaches yield diverse, high-performing designs but require large datasets to satisfy constraints reliably. The data-free approach is competitive with Bayesian optimization and gradient-based optimization in performance and feasibility while training a full generative model in only ~10 min on an RTX 4090 GPU, requiring more than two orders of magnitude fewer geometry evaluations and FLOPs than the data-driven method. We identify equality constraint satisfaction as a key difficulty and remaining limitation, and ablate approaches that improve this for the data-free approach. As a first step toward scaling generative design to complex, real-world engineering systems, this work explores how unmodified, domain-informed submodels can be integrated into a modular generative workflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces GLUE, a coordinating layer for orchestrating multiple pre-trained generative models to produce feasible, diverse, and high-performing system-level designs. It benchmarks a data-driven variant trained on pre-generated system-level data and a data-free variant trained on a differentiable geometry layer, evaluating both on a UAV design problem with five coupling constraints. The data-free approach is claimed to match Bayesian and gradient-based optimization in performance and feasibility while training in ~10 minutes on an RTX 4090 and requiring >100x fewer geometry evaluations and FLOPs.
Significance. If the results hold after clarification, the work would provide a modular pathway for integrating domain-specific generative models into complex engineering systems, potentially reducing reliance on large system-level datasets. The reported training efficiency and evaluation savings for the data-free variant are practically relevant, though the departure from frozen pre-trained generators in that variant narrows the advance relative to the stated research gap on coordinating unmodified submodels.
major comments (3)
- [Abstract] Abstract: the central claim that GLUE 'orchestrates pre-trained, frozen generators' is not supported by the data-free variant, which is instead trained directly on a differentiable geometry layer. This mismatch is load-bearing for the mapping from the research gap to the UAV results and requires explicit re-framing or separation of the two variants.
- [Abstract] Abstract: competitive performance numbers against Bayesian and gradient-based baselines are reported without error bars, exact metric definitions, or a full experimental protocol, leaving the feasibility and performance claims only partially supported.
- [Abstract] Abstract: equality constraint satisfaction is identified as a remaining limitation, yet the ablations claimed to improve it for the data-free approach lack quantitative detail on how they affect overall constraint satisfaction rates and diversity metrics.
minor comments (1)
- [Abstract] The assumption that 'compatible models must be end-to-end differentiable with a smooth, well-behaved latent-to-output mapping' should be elevated from the abstract into a dedicated limitations subsection with discussion of its implications for broader applicability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We appreciate the recognition of GLUE's potential as a modular approach for system-level design. We address each major comment below with planned revisions to improve clarity, experimental rigor, and alignment between claims and results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that GLUE 'orchestrates pre-trained, frozen generators' is not supported by the data-free variant, which is instead trained directly on a differentiable geometry layer. This mismatch is load-bearing for the mapping from the research gap to the UAV results and requires explicit re-framing or separation of the two variants.
Authors: We agree that the abstract's phrasing does not accurately distinguish the variants. The data-driven GLUE coordinates multiple frozen pre-trained generators, while the data-free variant is trained end-to-end on a differentiable geometry layer. We will revise the abstract to explicitly separate the two approaches, clarify their respective connections to the research gap on coordinating unmodified submodels, and adjust the UAV results framing accordingly to avoid overgeneralization. revision: yes
-
Referee: [Abstract] Abstract: competitive performance numbers against Bayesian and gradient-based baselines are reported without error bars, exact metric definitions, or a full experimental protocol, leaving the feasibility and performance claims only partially supported.
Authors: We acknowledge that the abstract omits error bars, precise metric definitions, and a complete experimental protocol, which limits the strength of the reported comparisons. In the revision we will add error bars computed over multiple independent runs, provide exact definitions for all metrics (including feasibility rate, performance score, and diversity measures), and include a concise experimental protocol summary in the abstract or main text with reference to the full details in the supplementary material. revision: yes
-
Referee: [Abstract] Abstract: equality constraint satisfaction is identified as a remaining limitation, yet the ablations claimed to improve it for the data-free approach lack quantitative detail on how they affect overall constraint satisfaction rates and diversity metrics.
Authors: We agree that the current description of the ablations is insufficiently quantitative. We will expand the manuscript to report specific numerical results from the ablations, including changes in overall constraint satisfaction rates (e.g., percentage of designs satisfying all five coupling constraints) and diversity metrics (e.g., latent-space coverage or output variance) for the data-free variant, allowing readers to assess the magnitude of improvement. revision: yes
Circularity Check
No significant circularity: GLUE performance claims rest on external benchmarks against independent optimizers
full rationale
The paper trains either a data-driven GLUE on pre-generated system-level designs or a data-free GLUE on a differentiable geometry layer, then directly compares the resulting designs' performance and feasibility to separate Bayesian optimization and gradient-based optimization baselines. These comparisons are external and not obtained by renaming fitted parameters or by construction from the coordinating layer itself. No equation reduces a claimed prediction to an input by definition, no uniqueness theorem is imported via self-citation, and no ansatz is smuggled through prior work. The differentiability assumption is stated explicitly as a prerequisite rather than derived from the results. This is a standard empirical benchmarking setup with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Compatible models must be end-to-end differentiable with a smooth, well-behaved latent-to-output mapping.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce GLUE models, which orchestrate pre-trained, frozen generative models across subsystems... Loss Formulation. Equation 2 shows the DF-GLUE training loss... λperf(λmOmass + λdOd) + λbbCbb + ... + λDPPDPP(x) + λMILMI
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The data-free approach is competitive with Bayesian optimization and gradient-based optimization in performance and feasibility while training a full generative model in only ~10 min
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
W. Para, P. Guerrero, T. Kelly, L. Guibas, P. Wonka, Gen- erative layout modeling using constraint graphs, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, Montreal, QC, Canada, 2021, pp. 6670– 6680.doi:10.1109/ICCV48922.2021.00662. 1, 2
-
[2]
W. Chen, K. Chiu, M. D. Fuge, Airfoil design parameteri- zation and optimization using bézier generative adversar- ial networks, AIAA Journal 58 (11) (2020) 4723–4735. doi:10.2514/1.J059317. 1, 2, 3, 4, 15, 16
-
[3]
B. Sanchez-Lengeling, A. Aspuru-Guzik, Inverse molecu- lar design using machine learning: Generative models for matter engineering, Science 361 (6400) (2018) 360–365. doi:10.1126/science.aat2663. 1, 2
-
[4]
V . Balmer, S. V . Kuhn, R. Bischof, L. Salamanca, W. Kauf- mann, F. Perez-Cruz, M. A. Kraus, Design space explo- ration and explanation via conditional variational autoen- coders in meta-model-based conceptual design of pedes- trian bridges, Automation in Construction 163 (2024) 105411. doi:https://doi.org/10.1016/j.autcon. 2024.105411. 1
-
[5]
T. Brzin, M. Brojan, Using a generative adversarial net- work for the inverse design of soft morphing composite beams, Engineering Applications of Artificial Intelligence 133 (2024). doi:10.1016/j.engappai.2024.108527. 2
-
[6]
Y . Tang, K. Kojima, T. Koike-Akino, Y . Wang, P. Wu, Y . Xie, M. H. Tahersima, D. K. Jha, K. Parsons, M. Qi, Generative deep learning model for inverse design of inte- grated nanophotonic devices, Laser & Photonics Reviews 14 (12) (2020).doi:10.1002/lpor.202000287. 2
-
[7]
A. Kadan, K. Ryczko, E. Lloyd, A. Roitberg, T. Yamazaki, Guided multi-objective generative ai to enhance structure- based drug design, Chemical Science 16 (29) (2025) 13196– 13210.doi:10.1039/D5SC01778E. 2
-
[8]
K. Zuo, S. Bu, W. Zhang, J. Hu, Z. Ye, X. Yuan, Fast sparse flow field prediction around airfoils via multi-head perceptron based deep learning architecture, Aerospace Science and Technology 130 (2022). doi:10.1016/j. ast.2022.107942. 2
work page doi:10.1016/j 2022
-
[9]
H. Karali, M. U. Demirezen, M. A. Yukselen, G. Inalhan, Design of a deep learning based nonlinear aerodynamic surrogate model for uavs, in: AIAA Scitech 2020 Forum, American Institute of Aeronautics and Astronautics, 2020. doi:10.2514/6.2020-1288. 2
-
[10]
J. Tao, G. Sun, Application of deep learning based multi- fidelity surrogate model to robust aerodynamic design op- timization, Aerospace Science and Technology 92 (2019) 722–737.doi:10.1016/j.ast.2019.07.002. 2
-
[11]
L. Regenwetter, C. Weaver, F. Ahmed, Framed: An automl approach for structural performance prediction of bicycle frames, Computer-Aided Design 156 (2023) 103446. doi: https://doi.org/10.1016/j.cad.2022.103446. 2
-
[12]
T. Benamara, P. Breitkopf, I. Lepot, C. Sainvitu, P. Vil- lon, Multi-fidelity pod surrogate-assisted optimization: Concept and aero-design study, Structural and Multidis- ciplinary Optimization 56 (6) (2017) 1387–1412. doi: 10.1007/s00158-017-1730-4. 2
-
[13]
S. G. Kontogiannis, M. A. Savill, A generalized method- ology for multidisciplinary design optimization using sur- rogate modelling and multifidelity analysis, Optimization and Engineering 21 (3) (2020) 723–759. doi:10.1007/ s11081-020-09504-z. 2
work page 2020
-
[14]
W. Yao, X. Chen, Q. Ouyang, M. Van Tooren, A surro- gate based multistage-multilevel optimization procedure for multidisciplinary design optimization, Structural and Multidisciplinary Optimization 45 (4) (2012) 559–574. doi:10.1007/s00158-011-0714-z. 2
-
[15]
S. Massoudi, C. Picard, J. Schiffmann, An Integrated Approach to Designing Robust Gas-Bearing Supported Turbocompressors Through Surrogate Modeling and Con- strained All-At-Once Multi-Objective Optimization, Jour- nal of Mechanical Design 146 (121706) (2024). doi: 10.1115/1.4065823. 2, 6
-
[16]
[HBP23] Aamal Abbas Hussain, Francesco Belardinelli, and G eorgios Piliouras
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y . Bengio, Gener- ative adversarial networks, Communications of the ACM 63 (11) (2020) 139–144.doi:10.1145/3422622. 2
-
[17]
D. P. Kingma, M. Welling, Auto-encoding variational bayes, in: International Conference on Learning Repre- sentations, 2014.doi:10.48550/arXiv.1312.6114. 2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1312.6114 2014
-
[18]
A. Cobb, A. Roy, D. Elenius, K. Koneripalli, S. Jha, On diverse system-level design using manifold learning and partial simulated annealing, Proceedings of the Design Society 2 (2022) 1541–1548. doi:10.1017/pds.2022
-
[20]
Q. Chen, M. Fuge, Compressing latent space via least vol- ume, in: The Twelfth International Conference on Learn- ing Representations, 2024. doi:10.48550/arXiv.2404. 17773. 2, 4, 10, 16
-
[21]
X. Chen, Y . Duan, R. Houthooft, J. Schulman, I. Sutskever, P. Abbeel, Infogan: Interpretable representation learning by information maximizing generative adversarial nets, in: Advances in Neural Information Processing Systems, V ol. 29, 2016.doi:10.48550/arXiv.1606.03657. 2 12
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1606.03657 2016
-
[22]
Learning Generative Models with Sinkhorn Divergences
A. Genevay, G. Peyré, M. Cuturi, Learning generative mod- els with sinkhorn divergences, in: International Conference on Artificial Intelligence and Statistics, PMLR, 2018, pp. 1608–1617. doi:10.48550/arXiv.1706.00292. 2, 4, 32
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1706.00292 2018
-
[23]
M. Arjovsky, S. Chintala, L. Bottou, Wasserstein gen- erative adversarial networks, in: International Confer- ence on Machine Learning, PMLR, 2017, pp. 214–223. doi:10.48550/arXiv.1701.07875. 2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1701.07875 2017
-
[24]
Q. Chen, P. Tsilifis, M. Fuge, Bayesian inverse problems with conditional sinkhorn generative adversarial networks in least volume latent spaces, Neural Networks 191 (Nov. 2025).doi:10.1016/j.neunet.2025.107740. 2
-
[26]
J. Song, C. Meng, S. Ermon, Denoising diffusion implicit models, in: International Conference on Learning Rep- resentations, 2021. doi:10.48550/arXiv.2010.02502. 2
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.02502 2021
-
[27]
F. Mazé, F. Ahmed, Diffusion models beat gans on topol- ogy optimization, Proceedings of the AAAI Conference on Artificial Intelligence 37 (8) (2023) 9108–9116. doi: 10.1609/aaai.v37i8.26093. 2, 3
-
[28]
Chen, W., Jia, H., Lai, S., Wu, K., Xiao, H., Hu, L., and Yue, Y
J.-H. Bastek, W. Sun, D. Kochmann, Physics-informed diffusion models, in: The Thirteenth International Confer- ence on Learning Representations, 2025. doi:10.48550/ arXiv.2403.14404. 2
-
[29]
C. Diniz, M. Fuge, Optimizing diffusion to diffuse opti- mal designs, in: AIAA SCITECH 2024 Forum, Ameri- can Institute of Aeronautics and Astronautics, 2024.doi: 10.2514/6.2024-2013. 2, 3, 4
-
[30]
G. Giannone, A. Srivastava, O. Winther, F. Ahmed, Align- ing optimization trajectories with diffusion models for constrained design generation, in: Thirty-seventh Con- ference on Neural Information Processing Systems, 2023. doi:10.48550/arXiv.2305.18470. 2
-
[31]
E. Herron, J. Rade, A. Jignasu, B. Ganapathysubramanian, A. Balu, S. Sarkar, A. Krishnamurthy, Latent diffusion models for structural component design, Computer-Aided Design 171 (2024). doi:10.1016/j.cad.2024.103707. 2
-
[32]
E. J. Cramer, J. E. Dennis, Jr., P. D. Frank, R. M. Lewis, G. R. Shubin, Problem formulation for multidisciplinary optimization, SIAM Journal on Optimization 4 (4) (1994) 754–776.doi:10.1137/0804044. 2
-
[33]
J. Sobieszczanski-Sobieski, Multidisciplinary design opti- mization: An emerging new engineering discipline, in: J. Herskovits (Ed.), Advances in Structural Optimiza- tion, V ol. 25, Springer Netherlands, pp. 483–496. doi: 10.1007/978-94-011-0453-1_14. 2
-
[34]
J. R. R. A. Martins, A. B. Lambe, Multidisciplinary design optimization: A survey of architectures, AIAA Journal 51 (9) (2013) 2049–2075. doi:10.2514/1.J051895. 2, 3
-
[35]
J.-N. Walther, A.-A. Gastaldi, R. Maierl, A. Jungo, M. Zhang, Integration aspects of the collaborative aero- structural design of an unmanned aerial vehicle, CEAS Aeronautical Journal 11 (1) (2020) 217–227. doi:10. 1007/s13272-019-00412-2. 2
work page 2020
-
[36]
J.-H. Kim, T. Tsuchiya, Openvsp based aerodynamic de- sign optimization tool building method and its application to tailless uav, in: Proceedings of the 33rd Congress of the International Council of the Aeronautical Sciences (ICAS), Stockholm, Sweden, 2022. 2, 32
work page 2022
-
[37]
C. Parrott, S. Peddada, J. T. Allison, K. James, Machine learning surrogates for optimal 2d spatial packaging of interconnected systems with physics interactions (spi2), in: AIAA A VIATION 2023 Forum, American Institute of Aeronautics and Astronautics, 2023. doi:10.2514/6. 2023-4375. 3
work page doi:10.2514/6 2023
-
[38]
BikeBench: A Bicycle De- sign Benchmark for Generative Models with Objectives and Constraints
L. Regenwetter, Y . A. Obaideh, F. Chiotti, I. Lykourentzou, F. Ahmed, Bike-bench: A bicycle design benchmark for generative models with objectives and constraints (2025). doi:10.48550/arXiv.2508.00830. 3, 6
-
[39]
A. Berzins, A. Radler, E. V olkmann, S. Sanokowski, S. Hochreiter, J. Brandstetter, Geometry-informed neural networks (2025). doi:10.48550/arXiv.2402.14009. 3
-
[40]
F. Felten, G. Apaza, G. Bräunlich, C. Diniz, X. Dong, A. Drake, M. Habibi, N. J. Hoffman, M. Keeler, S. Mas- soudi, F. G. VanGessel, M. Fuge, Engibench: A frame- work for data-driven engineering design research (2025). doi:10.48550/arXiv.2508.00831. 3
-
[41]
I. M. Kroo, Mdo for large-scale design, in: Multidisci- plinary Design Optimization: State of the Art, SIAM, Philadelphia, PA, 1997, pp. 22–44. 3
work page 1997
-
[42]
W. Chen, M. Fuge, Synthesizing designs with interpart dependencies using hierarchical generative adversarial net- works, Journal of Mechanical Design 141 (11) (2019). doi:10.1115/1.4044076. 3
-
[43]
S. Dong, L. Ding, X. Chen, Y . Li, Y . Wang, Y . Wang, Q. Wang, J. Kim, C. Gao, Z. Huang, Z. Wang, T. Xue, D. Xu, From one to more: Contextual part latents for 3d generation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2025. doi:10. 48550/arXiv.2507.08772. 3 13
-
[44]
N. Talabot, O. Clerc, A. C. Demirtas, A. Goujon, H. Le, D. Oner, P. Fua, PartSDF: Part-based implicit neural rep- resentation for composite 3D shape parametrization and optimization, arXiv preprint arXiv:2502.12985 (2025). doi:10.48550/arXiv.2502.12985. 3
-
[45]
L. Regenwetter, G. Giannone, A. Srivastava, D. Gutfreund, F. Ahmed, Constraining generative models for engineer- ing design with negative data, Transactions on Machine Learning Research (2024). doi:10.48550/arXiv.2306. 15166. 3, 5, 32
-
[46]
M. Elfeki, C. Couprie, M. Riviere, M. Elhoseiny, GDPP: Learning diverse generations using determinantal point processes, in: Proceedings of the 36th International Con- ference on Machine Learning, V ol. 97 of Proceedings of Machine Learning Research, PMLR, 2019, pp. 1774–1783. doi:10.48550/arXiv.1812.00068. 3, 28
-
[47]
W. Chen, F. Ahmed, Padgan: Learning to generate high- quality novel designs, Journal of Mechanical Design 143 (031703) (2020). doi:10.1115/1.4048626. 3, 17, 28
- [48]
-
[49]
K. Deb, A. Pratap, S. Agarwal, T. Meyarivan, A fast and elitist multiobjective genetic algorithm: Nsga-ii 6 (2) 182– 197.doi:10.1109/4235.996017. 3
-
[50]
D. Mahapatra, V . Rajan, Multi-task learning with user pref- erences: Gradient descent with controlled ascent in pareto optimization, in: International Conference on Machine Learning, PMLR, 2020, pp. 6597–6607. 3
work page 2020
-
[51]
A. Chandrasekhar, K. Suresh, Tounn: topology optimiza- tion using neural networks, Structural and Multidisci- plinary Optimization 63 (3) (2021) 1135–1149. 3
work page 2021
-
[52]
A. Joglekar, H. Chen, L. B. Kara, Dmf-tonn: direct mesh- free topology optimization using neural networks, Engi- neering with Computers 40 (4) (2024) 2227–2240. 3
work page 2024
-
[54]
T. D. Economon, F. Palacios, S. R. Copeland, T. W. Lukaczyk, J. J. Alonso, Su2: An open-source suite for multiphysics simulation and design, AIAA Journal 54 (3) (2016) 828–846.doi:10.2514/1.J053813. 3
-
[55]
P. He, C. A. Mader, J. R. Martins, K. J. Maki, An aero- dynamic design optimization framework using a discrete adjoint approach with openfoam 168 285–303. doi: 10.1016/j.compfluid.2018.04.012. 3
-
[56]
P. He, C. A. Mader, J. R. R. A. Martins, K. J. Maki, Dafoam: An open-source adjoint framework for multi- disciplinary design optimization with openfoam 58 (3) 1304–1319.doi:10.2514/1.J058853. 3
-
[57]
T. Xue, S. Liao, Z. Gan, C. Park, X. Xie, W. K. Liu, J. Cao, Jax-fem: A differentiable gpu-accelerated 3d finite element solver for automatic inverse design and mechanistic data science, Computer Physics Communications 291 (2023). doi:10.1016/j.cpc.2023.108802. 3
-
[58]
F. L. Ferretti, D. Ferigo, C. Sartore, A. Croci, O. G. Younis, S. Traversaro, D. Pucci, Hardware-accelerated morphol- ogy optimization via physically consistent differentiable simulation (2025). URLhttps://github.com/ami-iit/jaxsim3
work page 2025
-
[59]
E. Todorov, T. Erez, Y . Tassa, Mujoco: A physics engine for model-based control, in: 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, IEEE, 2012, pp. 5026–5033.doi:10.1109/IROS.2012.6386109. 3
-
[60]
M. Banovi ´c, O. Mykhaskiv, S. Auriemma, A. Walther, H. Legrand, J.-D. Müller, Algorithmic differentiation of the open cascade technology cad kernel and its coupling with an adjoint cfd solver, Optimization Methods and Soft- ware 33 (4-6) (2018) 813–828. doi:10.1080/10556788. 2018.1431235. 3
-
[61]
M. Banovi´c, T. Hafemann, A. Stück, Algorithmic differ- entiation of the pythonocc geometric modeling library, in: ECCOMAS Congress 2024 (9th European Congress on Computational Methods in Applied Sciences and Engineer- ing), Lisbon, Portugal, 2024. doi:10.23967/eccomas. 2024.197. 3
-
[62]
D. Cascaval, M. Shalah, P. Quinn, R. Bodik, M. Agrawala, A. Schulz, Differentiable 3d cad programs for bidirectional editing, in: Computer Graphics Forum, V ol. 41, Wiley Online Library, 2022, pp. 309–323. doi:10.1111/cgf. 14476. 3
work page doi:10.1111/cgf 2022
-
[63]
A. Deva Prasad, A. Balu, H. Shah, S. Sarkar, C. Hegde, A. Krishnamurthy, Nurbs-diff: A differentiable program- ming module for nurbs, Computer-Aided Design 146 (2022).doi:10.1016/j.cad.2022.103199. 3
-
[64]
J. J. Park, P. R. Florence, J. Straub, R. A. Newcombe, S. Lovegrove, Deepsdf: Learning continuous signed dis- tance functions for shape representation, in: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 165–174. doi:10.1109/CVPR.2019.00025. 4
-
[65]
Z. Hao, H. Averbuch-Elor, N. Snavely, S. J. Belongie, Dualsdf: Semantic shape manipulation using a two-level representation, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 7628–7638. doi:10.1109/CVPR42600.2020. 00765. 4 14
-
[66]
S. Vasu, N. Talabot, A. Lukoianov, P. Baqué, J. Donier, P. Fua, Hybridsdf: Combining deep implicit shapes and geometric primitives for 3d shape representation and ma- nipulation, in: 2022 International Conference on 3D Vision (3DV), 2022, pp. 617–626. doi:10.1109/3DV57658. 2022.00072. 4
-
[67]
A. Heyrani Nobari, W. Chen, F. Ahmed, Range-gan: De- sign synthesis under constraints using conditional genera- tive adversarial networks, Journal of Mechanical Design (2021) 1–16doi:10.1115/1.4052442. 4
-
[68]
A. D. Cobb, A. Roy, D. Elenius, S. Jha, Design of un- manned air vehicles using transformer surrogate models (2022).doi:10.48550/arXiv.2211.08138. 4
-
[69]
N. Sung, S. Spreizer, M. Elrefaie, K. Samuel, M. C. Jones, F. Ahmed, Blendednet: A blended wing body aircraft dataset and surrogate model for aerodynamic predictions (2025).doi:10.7910/DVN/VJT9EP. 4
-
[71]
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Köpf, E. Yang, Z. DeVito, M. Rai- son, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, S. Chintala, Pytorch: An imperative style, high- performance deep learning library, in: Proceedings of the 33rd International Confere...
-
[73]
D. Eriksson, M. Jankowiak, High-dimensional bayesian optimization with sparse axis-aligned subspaces, in: Uncer- tainty in Artificial Intelligence, PMLR, 2021, pp. 493–503. doi:10.48550/arXiv.2103.00349. 4, 29
-
[74]
D. Eriksson, M. Pearce, J. Gardner, R. D. Turner, M. Poloczek, Scalable global optimization via local bayesian optimization, Advances in Neural Information Processing Systems 32 (2019). doi:10.48550/arXiv. 1910.01739. 4, 29
work page internal anchor Pith review doi:10.48550/arxiv 2019
-
[75]
pymoo: Multi-Objective Optimization in Python,
J. Blank, K. Deb, pymoo: Multi-objective optimization in python, IEEE Access 8 (2020) 89497–89509. doi: 10.1109/ACCESS.2020.2990567. 6, 11
-
[76]
X. Zhang, L. Zhao, Y . Yu, X. Lin, Y . Chen, H. Zhao, Q. Zhang, Libmoon: A gradient-based multi-objective optimization library in pytorch, Advances in Neural Infor- mation Processing Systems 37 (2024) 2026–2044. doi: 10.48550/arXiv.2409.02969. 6
-
[77]
M. Olson, E. Santorella, L. C. Tiao, S. Cakmak, M. Gar- rard, S. Daulton, Z. J. Lin, S. Ament, B. Beckerman, E. Onofrey, P. Igusti, C. Lara, B. Letham, C. Cardoso, S. S. Shen, A. C. Lin, M. Grange, E. Kashtelyan, D. Eriks- son, M. Balandat, E. Bakshy, Ax: A platform for adaptive experimentation, in: AutoML 2025 ABCD Track, 2025. URLhttps://ax.dev/32
work page 2025
-
[78]
S. F. Hoerner, Fluid-Dynamic Drag: Practical Informa- tion on Aerodynamic Drag and Hydrodynamic Resistance, Hoerner Fluid Dynamics, Bricktown, NJ, 1965. 32 Appendix A. DF-GLUE Hyperparameters Table A.5 lists the specific hyperparameters used for DF- GLUE across the different experiments presented in this work. The hyperparameters include the random seeds,...
work page 1965
-
[79]
This loss is used to encourage boxes with varying aspect ratios
Ramp schedule: λAR−DPP =4 for epochs < 500, linear ramp to 1 over epochs 500–1500 (decreasing). This loss is used to encourage boxes with varying aspect ratios. The mutual information loss is given by: LMI =− 1 B BX i=1 log exp(z⊤ i ˆzi/τ) PB j=1 exp(z⊤ i ˆz j/τ) (B.18) where ˆzi is the predicted latent code from the auxiliary predictor, τ=0.1 is the temp...
-
[80]
focuses on initial convergence with lower penalty weights. Phase two (epochs 500 to 1500) implements progressive ramping with linear weight increases. Phase three (epochs 1500 to 2500) performs fine-tuning under maximum constraint penalties. All sequence lengths (1 to 3 boxes) are trained simultaneously, with random target volumes sampled per epoch to ens...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.