ADMEDTAGGER: an annotation framework for distillation of expert knowledge for the Polish medical language
Pith reviewed 2026-05-21 15:48 UTC · model grok-4.3
The pith
A multilingual LLM annotates Polish medical texts to train compact classifiers reaching F1 above 0.80.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using a pretrained multilingual LLM to annotate Polish medical texts creates labeled data that trains DistilBERT, BioBERT, and HerBERT classifiers to high F1 scores, yielding compact models that function as efficient alternatives to direct LLM use for clinical text categorization.
What carries the argument
The ADMEDTAGGER framework that treats a multilingual LLM as teacher model to distill expert knowledge into smaller BERT-based classifiers for Polish medical language.
If this is right
- The trained classifiers enable multi-class categorization of Polish medical texts without needing full-scale LLMs at inference time.
- Resource use drops dramatically: models are roughly 500 times smaller and use 300 times less GPU memory with hundreds of times faster inference.
- The framework scales annotation for other low-resource medical domains by combining LLM labeling with limited human checks.
- DistilBERT emerges as the strongest of the three architectures tested on this Polish clinical dataset.
Where Pith is reading between the lines
- The same teacher-student setup could extend to other languages that lack large annotated medical corpora.
- Periodic human audits of LLM-generated labels might further improve classifier robustness over time.
- Deploying the compact models in clinical software could support real-time Polish text processing where compute is limited.
Load-bearing premise
The labels generated by Llama 3.1 are sufficiently accurate and unbiased to train reliable classifiers even though only part of them received manual verification.
What would settle it
Independent expert re-annotation of a held-out portion of the corpus or direct comparison of model outputs against fresh human labels on unseen documents would confirm or refute the reported F1 scores.
Figures





read the original abstract
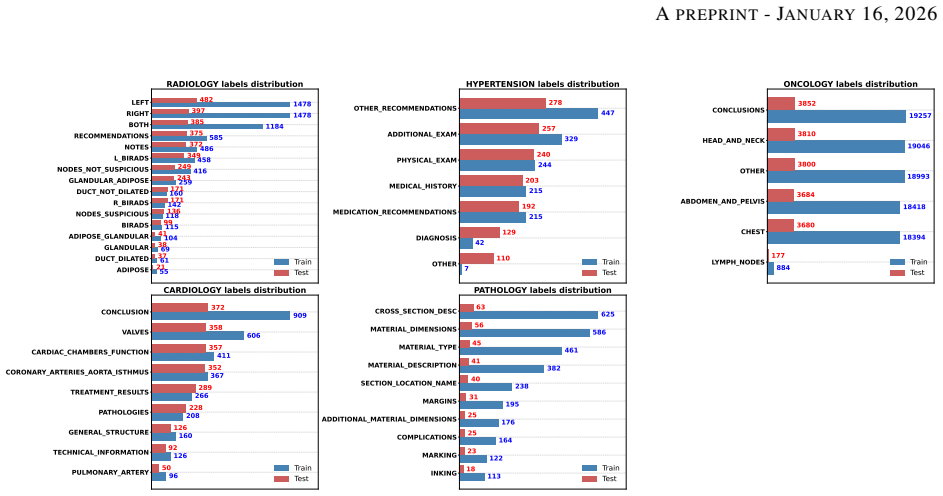
In this work, we present an annotation framework that demonstrates how a multilingual LLM pretrained on a large corpus can be used as a teacher model to distill the expert knowledge needed for tagging medical texts in Polish. This work is part of a larger project called ADMEDVOICE, within which we collected an extensive corpus of medical texts representing five clinical categories - Radiology, Oncology, Cardiology, Hypertension, and Pathology. Using this data, we had to develop a multi-class classifier, but the fundamental problem turned out to be the lack of resources for annotating an adequate number of texts. Therefore, in our solution, we used the multilingual Llama3.1 model to annotate an extensive corpus of medical texts in Polish. Using our limited annotation resources, we verified only a portion of these labels, creating a test set from them. The data annotated in this way were then used for training and validation of 3 different types of classifiers based on the BERT architecture - the distilled DistilBERT model, BioBERT fine-tuned on medical data, and HerBERT fine-tuned on the Polish language corpus. Among the models we trained, the DistilBERT model achieved the best results, reaching an F1 score > 0.80 for each clinical category and an F1 score > 0.93 for 3 of them. In this way, we obtained a series of highly effective classifiers that represent an alternative to large language models, due to their nearly 500 times smaller size, 300 times lower GPU VRAM consumption, and several hundred times faster inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ADMEDTAGGER, an annotation framework that employs the multilingual Llama 3.1 model to annotate a corpus of Polish medical texts across five clinical categories: Radiology, Oncology, Cardiology, Hypertension, and Pathology. Due to limited annotation resources, only a portion of the LLM-generated labels is manually verified to form a test set, while the annotated data is used to train and validate three BERT-based classifiers: DistilBERT, BioBERT, and HerBERT. The DistilBERT model achieves the best performance with F1 scores exceeding 0.80 for each category and 0.93 for three of them, positioning these compact models as efficient alternatives to large language models.
Significance. If the results hold with confirmed label quality, this work provides a practical method for addressing data scarcity in Polish medical NLP by distilling LLM knowledge into lightweight classifiers. It could enable efficient, deployable tools for clinical text classification with substantially lower computational costs than full LLMs.
major comments (1)
- [Annotation framework and experimental setup] The performance claims rest on training data produced by Llama 3.1 with only partial manual verification for the test set. No quantitative details are supplied on annotation error rates, per-category agreement between Llama 3.1 labels and human verification, or error analysis on the verified subset (see the annotation framework description and results reporting). This omission is load-bearing for the central distillation claim, as unquantified label noise could affect what the downstream models actually learn.
minor comments (1)
- [Abstract] The abstract states F1 > 0.80 for each category and > 0.93 for three but does not indicate the exact scale of the verified test set or the split ratios used for training/validation; adding these numbers would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting an important aspect of our experimental design. We address the major comment below and describe the changes we will make in revision.
read point-by-point responses
-
Referee: [Annotation framework and experimental setup] The performance claims rest on training data produced by Llama 3.1 with only partial manual verification for the test set. No quantitative details are supplied on annotation error rates, per-category agreement between Llama 3.1 labels and human verification, or error analysis on the verified subset (see the annotation framework description and results reporting). This omission is load-bearing for the central distillation claim, as unquantified label noise could affect what the downstream models actually learn.
Authors: We agree that quantitative characterization of label quality is necessary to fully support the distillation claim. The manuscript states that only a portion of the Llama 3.1-generated labels was manually verified to form the test set, but it does not report agreement statistics or error analysis. In the revised manuscript we will add a dedicated subsection under the annotation framework that reports, for each of the five categories: (i) the exact number of samples that received human verification, (ii) the percentage agreement between the Llama 3.1 label and the human annotator, and (iii) a concise error analysis of the main types of discrepancies observed. These additions will allow readers to assess the degree of label noise present in the training data and will directly address the concern that unquantified noise could undermine the reported performance of the distilled classifiers. The high F1 scores obtained on the human-verified test set remain the primary empirical support for the effectiveness of the approach, but we accept that the requested metrics are required for a complete evaluation. revision: yes
Circularity Check
No significant circularity; evaluation is independent of training labels
full rationale
The paper's core claim rests on training classifiers (including DistilBERT) on Llama 3.1-generated labels for Polish medical texts across five categories, with only a portion of labels manually verified to form a held-out test set. Reported F1 scores (>0.80 overall, >0.93 on three categories) are measured directly on this separate human-verified test set. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes appear in the provided text that would reduce the performance numbers to the LLM labels by construction. The derivation chain is therefore self-contained against an external benchmark (manual verification), with any label-noise concerns falling under correctness risk rather than circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Llama 3.1 can generate sufficiently accurate category labels for Polish medical texts to train effective classifiers.
Reference graph
Works this paper leans on
-
[1]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Dis- tilling the knowledge in a neural network.arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
A comprehensive survey on knowledge distillation.arXiv preprint arXiv:2503.12067, 2025
Amir M Mansourian et al. A comprehensive survey on knowledge distillation.arXiv preprint arXiv:2503.12067, 2025
-
[3]
A survey on knowledge distilla- tion: Recent advancements.ScienceDirect, Novem- ber 2024
N Moslemi et al. A survey on knowledge distilla- tion: Recent advancements.ScienceDirect, Novem- ber 2024
work page 2024
-
[4]
ACM Transactions Team. Survey on knowledge dis- tillation for large language models: Methods, evalua- tion, and application.ACM Transactions on Intelli- gent Systems and Technology, 2024
work page 2024
-
[5]
Xiaohui Zhang, Wei Li, Jian Wang, et al. Coun- terclockwise block-by-block knowledge distillation for neural network compression.Scientific Reports, 15(1):91152, 2025
work page 2025
-
[6]
Uncertainty-based knowledge distillation for bayesian deep neural network compression
Mina Hemmatian, Ali Shahzadi, and Saeed Mozaf- fari. Uncertainty-based knowledge distillation for bayesian deep neural network compression. International Journal of Approximate Reasoning, 173:109289, 2024
work page 2024
-
[7]
David E Hernandez, Torbjörn Nordling, et al. Knowl- edge distillation: Enhancing neural network com- pression with integrated gradients.arXiv preprint arXiv:2503.13008, 2025
-
[8]
Knowledge distillation: A survey
Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International Journal of Computer Vision, 129:1789– 1819, 2021
work page 2021
-
[9]
A Survey on Knowledge Distillation of Large Language Models
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. A survey on knowledge distil- lation of large language models.arXiv preprint arXiv:2402.13116, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. 10 APREPRINT- JANUARY16, 2026 InProceedings of NAACL-HLT, pages 4171–4186, 2019
work page 2026
-
[11]
M Fields et al. A survey of text classification with transformers: How wide? how large? how long? how accurate? how expensive? how safe?IEEE Access, 2024
work page 2024
-
[12]
Improving bert-based model for med- ical text classification with an optimization algo- rithm
Karim Gasmi. Improving bert-based model for med- ical text classification with an optimization algo- rithm. InAdvances in Computational Collective Intel- ligence. ICCCI 2022. Communications in Computer and Information Science, volume 1653, Cham, 2022. Springer
work page 2022
-
[13]
S Patel et al. Survey of transformers and towards ensemble learning using transformers for natural lan- guage processing.PMC, 2024
work page 2024
-
[14]
Hussein T Al-Natsheh et al. Rethinking of bert sen- tence embedding for text classification.Neural Com- puting and Applications, August 2024
work page 2024
-
[15]
Qiushi Sun, Zhangyue Yin, Xiang Li, Zhiyong Wu, Xipeng Qiu, and Lingpeng Kong
Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. How to fine-tune bert for text classification?arXiv preprint arXiv:1905.05583, 2019
-
[16]
Yuxin Li, Wei Zhang, Hao Wang, et al. Short-text sentiment classification model based on bert and dual- stream transformer gated attention mechanism.Elec- tronics, 14(19):3904, 2025
work page 2025
-
[17]
Imad El Maaroufi, Youssef Mellah, Karim El Kharki, et al. Lnlf-bert: Transformer for long document classification with multiple attention levels.IEEE Access, 2024
work page 2024
-
[18]
J Jiang et al. Are we really making much progress in text classification? a comparative review.arXiv preprint arXiv:2204.03954, 2025
-
[19]
Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. Biobert: A pre-trained biomedical language representation model for biomedical text mining.Bioinformatics, 36(4):1234–1240, 2020
work page 2020
-
[20]
Omid Rohanian, Mohammadmahdi Nouriborji, Hannah Jauncey, Samaneh Kouchaki, Farhad Nooralahzadeh, Lei Clifton, Laura Merson, and David A Clifton. Lightweight transformers for clini- cal natural language processing.Natural Language Engineering, pages 1–28, 2023
work page 2023
-
[21]
ClinicalBERT: Modeling Clinical Notes and Predicting Hospital Readmission
Kexin Huang, Jaan Altosaar, and Rajesh Ran- ganath. Clinicalbert: Modeling clinical notes and predicting hospital readmission.arXiv preprint arXiv:1904.05342, 2020
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[22]
Yifan Peng, Shankai Yan, and Zhiyong Lu. Transfer learning in biomedical natural language processing: An evaluation of bert and elmo on ten benchmarking datasets.arXiv preprint arXiv:1906.05474, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[23]
Laila Rasmy, Yang Xiang, Ziqian Xie, Cui Tao, and Degui Zhi. Med-bert: pretrained contextualized em- beddings on large-scale structured electronic health records for disease prediction.npj Digital Medicine, 4(1):1–13, 2021
work page 2021
-
[24]
ClinRaGen Research Team. Knowledge-augmented multimodal clinical rationale generation for disease diagnosis with small language models.arXiv preprint arXiv:2411.07611, 2025
-
[25]
Eunkyung Kim, Kai Huang, Yu Xing, Xiaoqian Jiang, et al. Attention mechanism with bert for content annotation and categorization of pregnancy-related questions on a community q&a site. InAMIA An- nual Symposium Proceedings, volume 2020, pages 625–634. American Medical Informatics Association, 2021
work page 2020
-
[26]
Luca Putelli, Alfonso E Gerevini, Alberto Lavelli, Tahir Mehmood, and Ivan Serina. On the behaviour of bert’s attention for the classification of medical reports.CEUR Workshop Proceedings, 3277, 2022
work page 2022
-
[27]
Publicly available clinical bert embed- dings
Emily Alsentzer, John Murphy, William Boag, Wei- Hung Weng, Di Jin, Tristan Naumann, and Matthew McDermott. Publicly available clinical bert embed- dings. InProceedings of the 2nd Clinical Natural Language Processing Workshop, pages 72–78. ACL, 2019
work page 2019
-
[28]
G Wang et al. Comparison of bert implementations for natural language processing of narrative medical documents.ScienceDirect, 2020
work page 2020
-
[29]
Large language model influence on diagnostic reasoning: A randomized clinical trial
Ethan Tanner et al. Large language model influence on diagnostic reasoning: A randomized clinical trial. JAMA Network Open, 7(10), 2024
work page 2024
-
[30]
Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
Karan Singhal, Shekoofeh Azizi, Tao Tu, S Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Tanwani, Heather Cole-Lewis, Stephen Pfohl, et al. Large language models encode clinical knowledge.Nature, 620(7972):172–180, 2023
work page 2023
-
[31]
Shuang Wang, Zhenyu Zhao, Xi Ouyang, Qian Wang, and Dinggang Shen. Large language models for dis- ease diagnosis: a scoping review.npj Artificial Intel- ligence, 1(1):11, 2025
work page 2025
-
[32]
Shuo Liu, Yanglin Pan, Kejia Wang, Xiaodong Jia, et al. Application of large language models in disease diagnosis and treatment.Chinese Medical Journal, 2025
work page 2025
-
[33]
Hajar Sakai and Sarah S Lam. Kdh-mltc: Knowledge distillation for healthcare multi-label text classifica- tion.arXiv preprint arXiv:2505.07162, 2025
-
[34]
Medical prediction using discharge- bert and corebert.Referenced in KDH-MLTC, 2025
M Hasan et al. Medical prediction using discharge- bert and corebert.Referenced in KDH-MLTC, 2025
work page 2025
-
[35]
Cross-lingual text classification with minimal resources by transferring a sparse teacher
Giannis Karamanolakis, Daniel Hsu, and Luis Gra- vano. Cross-lingual text classification with minimal resources by transferring a sparse teacher. InFind- ings of the Association for Computational Linguistics: EMNLP 2020, pages 3604–3622, 2020
work page 2020
-
[36]
Y Cho et al. Dsg-kd: Knowledge distillation from domain-specific to general language models.arXiv preprint arXiv:2409.14904, 2024. 11 APREPRINT- JANUARY16, 2026
-
[37]
Ziqing Yang et al. Cross-lingual text classification with multilingual distillation and zero-shot-aware training.arXiv preprint arXiv:2202.13654, 2022
-
[38]
G Katsogiannis-Meimarakis and G Koutrika. Mul- tilingual text categorization and sentiment analysis: A comparative analysis of the utilization of multilin- gual approaches for classifying twitter data.Neural Computing and Applications, May 2023
work page 2023
-
[39]
Moritz Laurer, Wouter van Atteveldt, Andreu Casas, and Kasper Welbers. Cross-lingual classification of political texts using multilingual sentence embed- dings.Political Analysis, 31(3), January 2023
work page 2023
-
[40]
Universal cross-lingual text clas- sification.arXiv preprint arXiv:2406.11028, June 2024
Raviraj Joshi et al. Universal cross-lingual text clas- sification.arXiv preprint arXiv:2406.11028, June 2024
-
[41]
Herbert: Efficiently pretrained transformer-based language model for polish
Robert Mroczkowski, Piotr Rybak, Alina Wróblewska, and Ireneusz Gawlik. Herbert: Efficiently pretrained transformer-based language model for polish. InProceedings of the 8th Workshop on Balto-Slavic Natural Language Processing, pages 1–10, Kiyv, Ukraine, April 2021. Association for Computational Linguistics
work page 2021
-
[42]
Piotr Rybak, Robert Mroczkowski, Janusz Tracz, and Ireneusz Gawlik. Klej: Comprehensive benchmark for polish language understanding.arXiv preprint arXiv:2005.00630, 2020
-
[43]
Wroclaw corpus of consumer reviews sentiment (WCCRS), 2019
Jan Koco ´n, Monika Za ´sko-Zieli´nska, Piotr Miłkowski, Arkadiusz Janz, and Maciej Piasecki. Wroclaw corpus of consumer reviews sentiment (WCCRS), 2019. CLARIN-PL digital repository
work page 2019
-
[44]
Górno´sl ˛ askie Centrum Medyczne Research Team. Deep learning analysis of polish electronic health records for diagnosis prediction in patients with cardiovascular diseases.Personalized Medicine, 12(6):869, May 2022
work page 2022
-
[45]
AssistMED Project Team. Practical use case of natural language processing for observational clin- ical research data retrieval from electronic health records: Assistmed project.Polish Archives of Inter- nal Medicine, 2024
work page 2024
-
[46]
Machine learning tools match physician accuracy in multilingual text annotation
Marta Zielonka, Andrzej Czy˙zewski, Dariusz Szplit, Beata Graff, Anna Szyndler, Mariusz Budzisz, and Krzysztof Narkiewicz. Machine learning tools match physician accuracy in multilingual text annotation. Scientific Reports, 15(1):5487, 2025
work page 2025
-
[47]
Andrzej Czy ˙zewski, Sebastian Cygert, Karolina Marciniuk, Maciej Szczodrak, Arkadiusz Harasim- iuk, Piotr Odya, Marina Galanina, Piotr Szczuko, Bo˙zena Kostek, Beata Graff, et al. A comprehensive polish medical speech dataset for enhancing auto- matic medical dictation.Scientific Data, 12(1):1436, 2025. 12
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.