MMTalker: Multiresolution 3D Talking Head Synthesis with Multimodal Feature Fusion
Pith reviewed 2026-05-13 19:43 UTC · model grok-4.3
The pith
MMTalker synthesizes detailed 3D talking heads from speech by combining UV mesh parameterization with dual cross-attention fusion of audio and geometric features.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
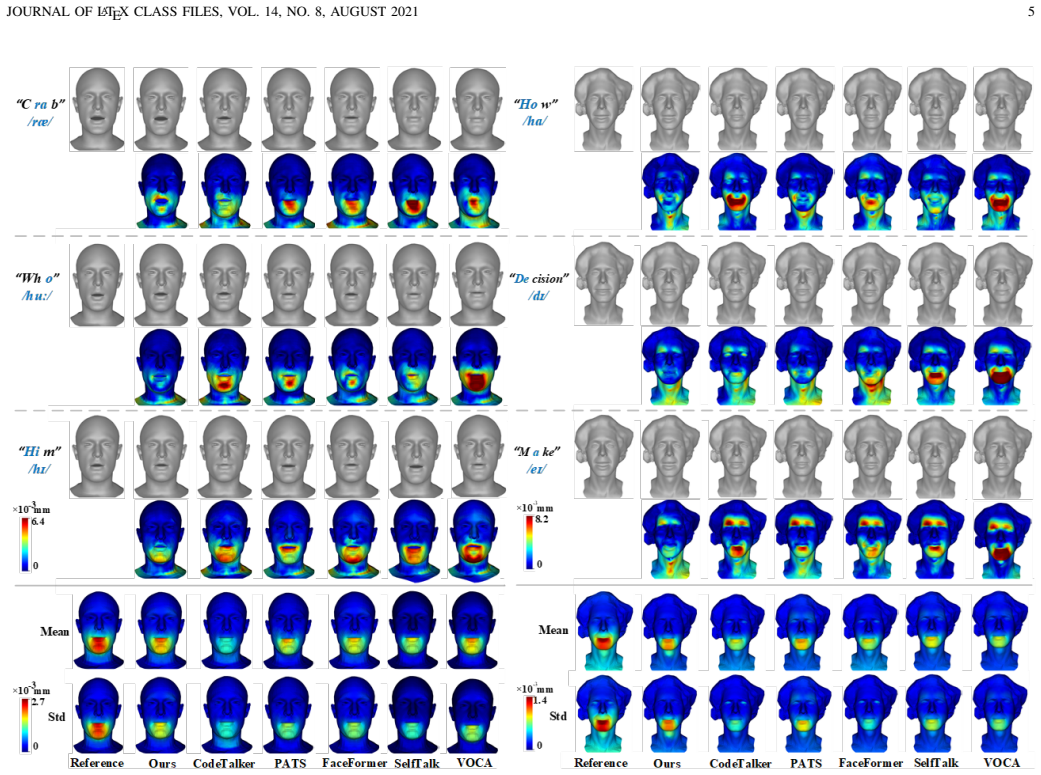
MMTalker achieves continuous representation of 3D faces with fine details by establishing UV-to-mesh correspondence and applying differentiable non-uniform sampling with learnable per-triangle probabilities. It extracts motion features from multiple modalities using a residual graph convolutional network on sampled points together with a dual cross-attention module that aligns hierarchical speech features against spatiotemporal geometric features of the mesh. A lightweight regression network then jointly processes the canonical UV samples and the fused motion encoding to predict vertex-wise geometric displacements of the animated face.
What carries the argument
Dual cross-attention fusion of hierarchical speech features and explicit spatiotemporal mesh geometry, applied after non-uniform differentiable sampling on UV-parameterized meshes.
If this is right
- Lip and eye synchronization accuracy increases on standard 3D talking-head benchmarks.
- Vertex displacements become more faithful to fine facial details captured in the continuous UV representation.
- The same fusion architecture can be reused for other speech-conditioned 3D tasks that require temporal geometric consistency.
- Real-time avatar pipelines require less manual correction because the predicted motions already respect both audio timing and mesh topology.
Where Pith is reading between the lines
- The sampling-plus-attention pattern may generalize to other ill-posed 1D-to-3D mappings such as text-to-gesture or music-to-body motion.
- Temporal consistency over long utterances could be tested by measuring drift in eye-blink frequency across minute-long speech clips.
- Adding an auxiliary video encoder to the fusion stage might further tighten synchronization when visual cues are available.
Load-bearing premise
The combination of non-uniform sampling on UV meshes and dual cross-attention will resolve the ambiguities in speech-to-3D-motion mapping without creating new artifacts or needing extra post-processing.
What would settle it
Quantitative evaluation on a held-out test set showing no reduction in lip-sync error (such as lip vertex distance or synchronization offset) relative to the strongest baseline would falsify the central performance claim.
Figures








read the original abstract
Speech-driven three-dimensional (3D) facial animation synthesis aims to build a mapping from one-dimensional (1D) speech signals to time-varying 3D facial motion signals. Current methods still face challenges in maintaining lip-sync accuracy and producing realistic facial expressions, primarily due to the highly ill-posed nature of this cross-modal mapping. In this paper, we introduce a novel 3D audio-driven facial animation synthesis method through multi-resolution representation and multi-modal feature fusion, called MMTalker which can accurately reconstruct the rich details of 3D facial motion. We first achieve the continuous representation of 3D face with details by mesh parameterization and non-uniform differentiable sampling. The mesh parameterization technique establishes the correspondence between UV plane and 3D facial mesh and is used to offer ground truth for the continuous learning. Differentiable non-uniform sampling enables precise facial detail acquisition by setting learnable sampling probability in each triangular face. Next, we employ residual graph convolutional network and dual cross-attention mechanism to extract discriminative facial motion feature from multiple input modalities. This proposed multimodal fusion strategy takes full use of the hierarchical features of speech and the explicit spatiotemporal geometric features of facial mesh. Finally, a lightweight regression network predicts the vertex-wise geometric displacements of the synthesized talking face by jointly processing the sampled points in the canonical UV space and the encoded facial motion features. Comprehensive experiments demonstrate that significant improvements are achieved over state-of-the-art methods, especially in the synchronization accuracy of lip and eye movements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MMTalker for speech-driven 3D facial animation. It achieves continuous 3D face representation via UV mesh parameterization and non-uniform differentiable sampling with learnable per-triangle probabilities, extracts features using a residual GCN and dual cross-attention fusion of speech and geometric modalities, and regresses vertex displacements in canonical UV space. Experiments are said to show significant gains over prior methods, especially in lip and eye synchronization accuracy.
Significance. If the non-uniform sampling and multimodal fusion reliably capture fine-grained 3D motion details without degeneracy, the approach could advance realistic talking-head synthesis for animation and VR by better resolving the ill-posed speech-to-motion mapping while preserving spatiotemporal geometry.
major comments (1)
- [Method (non-uniform differentiable sampling)] The non-uniform differentiable sampling (described after mesh parameterization) sets learnable sampling probabilities per triangular face but supplies no regularization term (entropy, sparsity, or minimum-probability constraint). In the ill-posed speech-to-3D setting this risks collapse onto a small subset of faces, so the subsequent residual GCN + dual cross-attention and regression would operate on an incomplete point set and any reported lip-sync gains could be mesh-specific artifacts rather than a general solution.
minor comments (2)
- [Abstract] The abstract asserts 'significant improvements' and 'accurate reconstruction' without citing any quantitative metrics, ablation tables, or error bars; the full experimental section should make these numbers explicit and comparable to the cited baselines.
- [Method] Notation for the dual cross-attention fusion and the UV-space regression head is introduced without an accompanying equation or diagram; a single schematic would clarify how sampled points and encoded features are jointly processed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and will revise the manuscript accordingly to strengthen the presentation of the non-uniform sampling approach.
read point-by-point responses
-
Referee: [Method (non-uniform differentiable sampling)] The non-uniform differentiable sampling (described after mesh parameterization) sets learnable sampling probabilities per triangular face but supplies no regularization term (entropy, sparsity, or minimum-probability constraint). In the ill-posed speech-to-3D setting this risks collapse onto a small subset of faces, so the subsequent residual GCN + dual cross-attention and regression would operate on an incomplete point set and any reported lip-sync gains could be mesh-specific artifacts rather than a general solution.
Authors: We appreciate this observation. The submitted manuscript does not include an explicit regularization term on the learnable per-face sampling probabilities. The end-to-end training with reconstruction losses on vertex displacements and multimodal fusion does encourage sampling of informative regions, as supported by our ablations, but we acknowledge the risk of collapse in this ill-posed setting. In the revised manuscript we will add an entropy regularization term to the sampling probabilities to promote diversity. We will also include visualizations of the learned probability distribution across faces and an ablation comparing performance with and without the term to demonstrate that the reported gains are robust rather than mesh-specific artifacts. revision: yes
Circularity Check
No circularity: architecture trains end-to-end on external mesh data without self-referential reduction
full rationale
The derivation chain consists of standard mesh parameterization to obtain UV correspondences (used as fixed ground truth), followed by a learnable but regularized sampling step inside a neural pipeline whose outputs are vertex displacements regressed from multimodal features. No equation equates a prediction to a fitted parameter by construction, no self-citation supplies a uniqueness theorem, and no ansatz is smuggled via prior work. The method remains falsifiable against held-out 3D sequences; reported lip-sync gains are empirical outcomes rather than algebraic identities.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A morphable model for the synthesis of 3d faces,
V . Blanz and T. Vetter, “A morphable model for the synthesis of 3d faces,” in Seminal Graphics Papers: Pushing the Boundaries, V olume2, 2023, pp. 157–164
work page 2023
-
[2]
Available: http://dx.doi.org/10.1145/3130800.3130810
T. Li, T. Bolkart, M. J. Black, H. Li, and J. Romero, “Learning a model of facial shape and expression from 4d scans,” ACM Trans. Graph., vol. 36, no. 6, Nov. 2017. [Online]. Available: https://doi.org/10.1145/3130800.3130813
-
[3]
Video- audio driven real-time facial animation,
Y . Liu, F. Xu, J. Chai, X. Tong, L. Wang, and Q. Huo, “Video- audio driven real-time facial animation,” ACM Transactions on Graphics (TOG), vol. 34, no. 6, pp. 1–10, 2015
work page 2015
-
[4]
Multi- task audio-driven facial animation,
Y . Kim, S. An, Y . Jo, S. Park, S. Kang, I. Oh, and D. D. Kim, “Multi- task audio-driven facial animation,” in ACM SIGGRAPH 2019 Posters, 2019, pp. 1–2
work page 2019
-
[5]
Modality dropout for improved performance- driven talking faces,
A. Hussen Abdelaziz, B.-J. Theobald, P. Dixon, R. Knothe, N. Apos- toloff, and S. Kajareker, “Modality dropout for improved performance- driven talking faces,” in Proceedings of the 2020 International Conference on Multimodal Interaction, 2020, pp. 378–386
work page 2020
-
[6]
Speech-driven facial animation with spectral gathering and temporal attention,
Y . Chai, Y . Weng, L. Wang, and K. Zhou, “Speech-driven facial animation with spectral gathering and temporal attention,” Frontiers of Computer Science, vol. 16, no. 3, p. 163703, 2022
work page 2022
-
[7]
Cap- ture, learning, and synthesis of 3d speaking styles,
D. Cudeiro, T. Bolkart, C. Laidlaw, A. Ranjan, and M. J. Black, “Cap- ture, learning, and synthesis of 3d speaking styles,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2019
work page 2019
-
[8]
Geometry-guided dense perspective network for speech-driven facial animation,
J. Liu, B. Hui, K. Li, Y . Liu, Y . Lai, Y . Zhang, Y . Liu, and J. Yang, “Geometry-guided dense perspective network for speech-driven facial animation,” CoRR, vol. abs/2008.10004, 2020. [Online]. Available: https://arxiv.org/abs/2008.10004
-
[9]
Meshtalk: 3d face animation from speech using cross-modality disentanglement,
A. Richard, M. Zollh ¨ofer, Y . Wen, F. D. la Torre, and Y . Sheikh, “Meshtalk: 3d face animation from speech using cross-modality disentanglement,” CoRR, vol. abs/2104.08223, 2021. [Online]. Available: https://arxiv.org/abs/2104.08223
-
[10]
Pose-aware 3d talking face synthesis using geometry-guided audio-vertices attention,
B. Li, X. Wei, B. Liu, Z. He, J. Cao, and Y .-K. Lai, “Pose-aware 3d talking face synthesis using geometry-guided audio-vertices attention,” IEEE Transactions on Visualization and Computer Graphics, pp. 1–15, 2024
work page 2024
-
[11]
Computation conformal geometry, 2008
XianfengDavidGu and Shing-TungYau, Computation conformal geometry. Computation conformal geometry, 2008
work page 2008
-
[12]
Real-time facial animation with image-based dynamic avatars,
C. Cao, H. Wu, Y . Weng, T. Shao, and K. Zhou, “Real-time facial animation with image-based dynamic avatars,” ACM Transactions on Graphics, vol. 35, no. 4, pp. 1–12, 2016
work page 2016
-
[13]
Text-based editing of talking-head video,
O. Fried, A. Tewari, M. Zollhfer, A. Finkelstein, and M. Agrawala, “Text-based editing of talking-head video,” ACM Transactions on Graphics (TOG), 2019
work page 2019
-
[14]
H. Kim, P. Garrido, A. Tewari, W. Xu, J. Thies, M. Nießner, P. P ´erez, C. Richardt, M. Zollh ¨ofer, and C. Theobalt, “Deep video portraits,” CoRR, vol. abs/1805.11714, 2018. [Online]. Available: http://arxiv.org/abs/1805.11714
-
[16]
Available: https://arxiv.org/abs/2106.04185
[Online]. Available: https://arxiv.org/abs/2106.04185
-
[17]
Realtime facial animation with on- the-fly correctives,
H. Li, J. Yu, Y . Ye, and C. Bregler, “Realtime facial animation with on- the-fly correctives,” Acm Transactions on Graphics, vol. 32, no. 4CD, pp. 1–10, 2013
work page 2013
-
[18]
Neural voice puppetry: Audio-driven facial reenactment,
J. Thies, M. Elgharib, A. Tewari, C. Theobalt, and M. Nießner, “Neural voice puppetry: Audio-driven facial reenactment,” CoRR, vol. abs/1912.05566, 2019. [Online]. Available: http://arxiv.org/abs/1912. 05566
-
[19]
Realtime performance-based facial animation,
T. Weise, S. Bouaziz, H. Li, and M. Pauly, “Realtime performance-based facial animation,” ACM Transactions on Graphics, vol. 30, no. 4, p. 77, 2011
work page 2011
-
[20]
State of the art on monocular 3d face reconstruction, tracking, and applications,
M. Zollh ¨ofer, J. Thies, P. Garrido, D. Bradley, T. Beeler, P. P ´erez, M. Stamminger, M. Nießner, and C. Theobalt, “State of the art on monocular 3d face reconstruction, tracking, and applications,” Computer Graphics Forum, vol. 37, no. 2, pp. 523–550, 2018
work page 2018
-
[21]
Expressive speech- driven facial animation,
Y . Cao, W. C. Tien, P. Faloutsos, and F. Pighin, “Expressive speech- driven facial animation,”ACM Transactions on Graphics (TOG), vol. 24, no. 4, pp. 1283–1302, 2005
work page 2005
-
[23]
Available: https://arxiv.org/abs/2007.08547
[Online]. Available: https://arxiv.org/abs/2007.08547
-
[24]
Lip movements generation at a glance,
L. Chen, Z. Li, R. K. Maddox, Z. Duan, and C. Xu, “Lip movements generation at a glance,” CoRR, vol. abs/1803.10404, 2018. [Online]. Available: http://arxiv.org/abs/1803.10404
-
[25]
Out of time: Automated lip sync in the wild,
J. S. Chung and A. Zisserman, “Out of time: Automated lip sync in the wild,” in Asian Conference on Computer Vision, 2017
work page 2017
-
[26]
Speech-driven facial animation using cascaded gans for learning of motion and texture,
D. Das, S. Biswas, S. Sinha, and B. Bhowmick, “Speech-driven facial animation using cascaded gans for learning of motion and texture,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16. Springer, 2020, pp. 408–424
work page 2020
-
[27]
Photo-real talking head with deep bidirectional lstm,
B. Fan, L. Wang, F. K. Soong, and L. Xie, “Photo-real talking head with deep bidirectional lstm,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 4884– 4888
work page 2015
-
[28]
Audio- driven emotional video portraits,
X. Ji, H. Zhou, K. Wang, W. Wu, C. C. Loy, X. Cao, and F. Xu, “Audio- driven emotional video portraits,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 14 080–14 089
work page 2021
-
[29]
A lip sync expert is all you need for speech to lip generation in the wild,
K. Prajwal, R. Mukhopadhyay, V . P. Namboodiri, and C. Jawahar, “A lip sync expert is all you need for speech to lip generation in the wild,” in Proceedings of the 28th ACM international conference on multimedia, 2020, pp. 484–492
work page 2020
-
[30]
Realistic speech-driven facial animation with gans,
K. V ougioukas, S. Petridis, and M. Pantic, “Realistic speech-driven facial animation with gans,” International Journal of Computer Vision, vol. 128, no. 5, pp. 1398–1413, 2020
work page 2020
-
[32]
Available: https://arxiv.org/abs/2002.10137
[Online]. Available: https://arxiv.org/abs/2002.10137
-
[33]
Pose- controllable talking face generation by implicitly modularized audio- visual representation,
H. Zhou, Y . Sun, W. Wu, C. C. Loy, X. Wang, and Z. Liu, “Pose- controllable talking face generation by implicitly modularized audio- visual representation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 4176–4186
work page 2021
-
[34]
Faceformer: Speech- driven 3d facial animation with transformers,
Y . Fan, Z. Lin, J. Saito, W. Wang, and T. Komura, “Faceformer: Speech- driven 3d facial animation with transformers,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 18 749–18 758
work page 2022
-
[35]
Codetalker: Speech-driven 3d facial animation with discrete motion prior,
J. Xing, M. Xia, Y . Zhang, X. Cun, J. Wang, and T.-T. Wong, “Codetalker: Speech-driven 3d facial animation with discrete motion prior,” 2023. [Online]. Available: https://arxiv.org/abs/2301.02379
-
[36]
Selftalk: A self-supervised commutative training diagram to compre- hend 3d talking faces,
Z. Peng, Y . Luo, Y . Shi, H. Xu, X. Zhu, H. Liu, J. He, and Z. Fan, “Selftalk: A self-supervised commutative training diagram to compre- hend 3d talking faces,” in Proceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 5292–5301
work page 2023
-
[37]
Pose-aware 3d talking face synthesis using geometry-guided audio-vertices attention,
B. Li, X. Wei, B. Liu, Z. He, J. Cao, and Y .-K. Lai, “Pose-aware 3d talking face synthesis using geometry-guided audio-vertices attention,” IEEE Transactions on Visualization and Computer Graphics, 2024
work page 2024
-
[38]
URL http://proceedings.mlr.press/ v37/allamanis15.html
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” CoRR, vol. abs/2006.11477, 2020. [Online]. Available: https://arxiv. org/abs/2006.11477
-
[39]
Multiface: A dataset for neural face rendering,
C. hsin Wuu, N. Zheng, S. Ardisson, R. Bali, D. Belko, E. Brockmeyer, L. Evans, T. Godisart, H. Ha, X. Huang, A. Hypes, T. Koska, S. Krenn, S. Lombardi, X. Luo, K. McPhail, L. Millerschoen, M. Perdoch, M. Pitts, A. Richard, J. Saragih, J. Saragih, T. Shiratori, T. Simon, M. Stewart, A. Trimble, X. Weng, D. Whitewolf, C. Wu, S.-I. Yu, and Y . Sheikh, “Mult...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.