Joint Interference Detection and Identification via Adversarial Multi-task Learning
Pith reviewed 2026-05-10 17:59 UTC · model grok-4.3
The pith
Adversarial multi-task learning with a derived bound on task similarity outperforms single-task baselines for joint wireless interference detection, modulation identification, and interference identification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
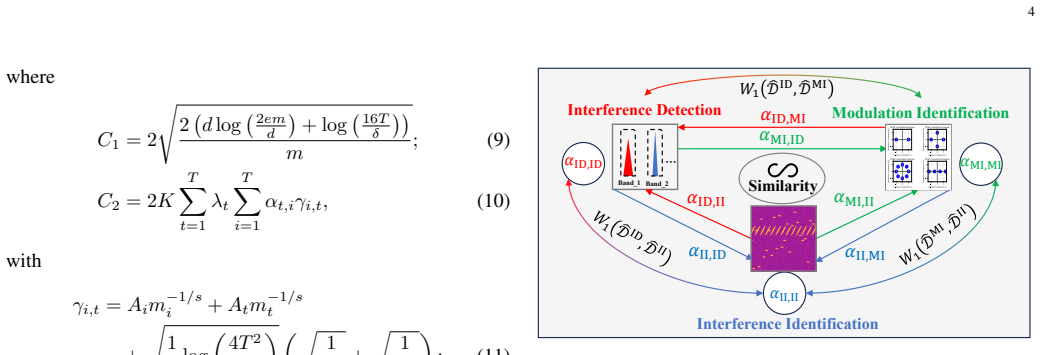
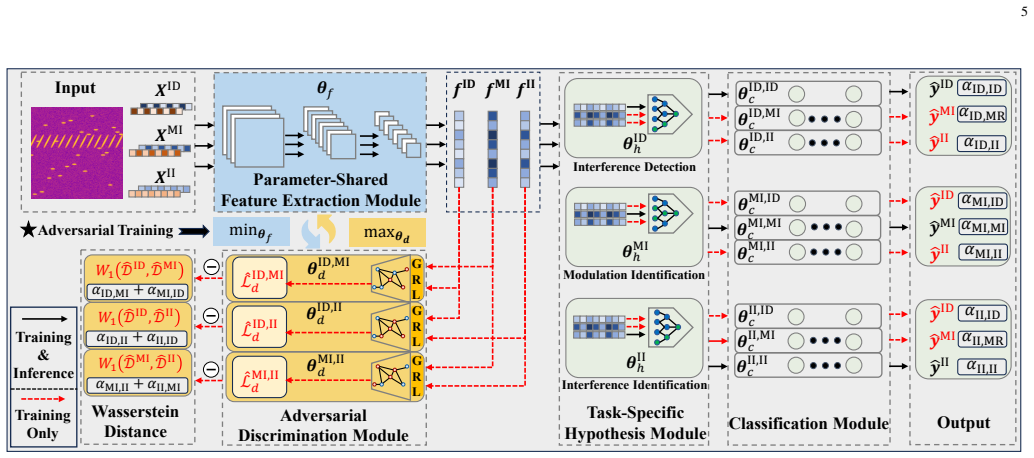
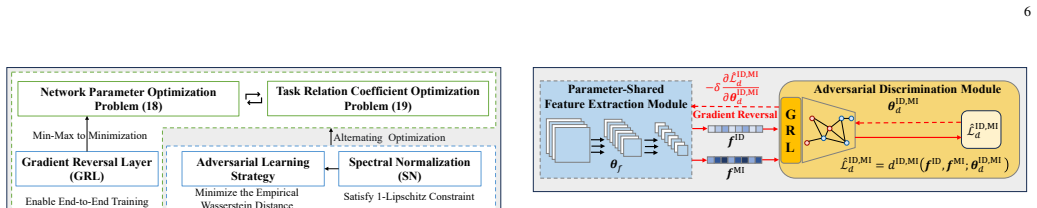
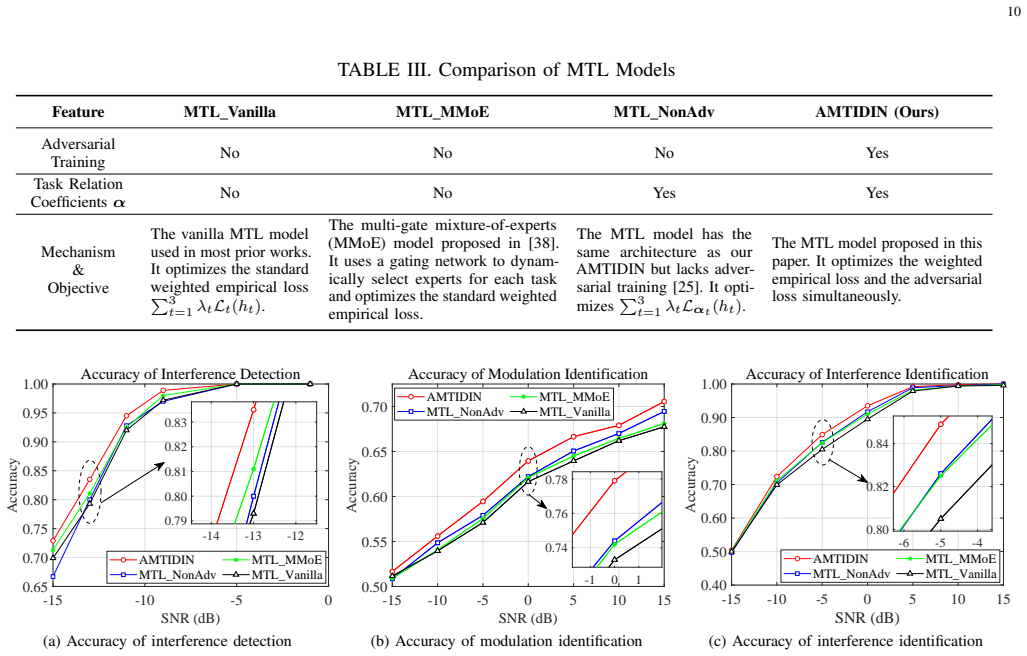
The paper claims that deriving an upper bound on weighted expected loss in multi-task learning, which explicitly connects performance to task similarity quantified by Wasserstein distance and learnable relation coefficients, guides the design of AMTIDIN. This network uses adversarial training to minimize distributional discrepancies across tasks and adaptive coefficients to model correlations dynamically. The resulting system delivers significantly higher robustness and generalization than single-task learning baselines and existing multi-task methods, with particular gains under limited training data, short signal lengths, and low signal-to-noise ratios. The same analysis shows that modula
What carries the argument
The adversarial multi-task interference detection and identification network (AMTIDIN), which integrates adversarial training to minimize distributional discrepancies across tasks and uses adaptive coefficients to model task correlations dynamically.
If this is right
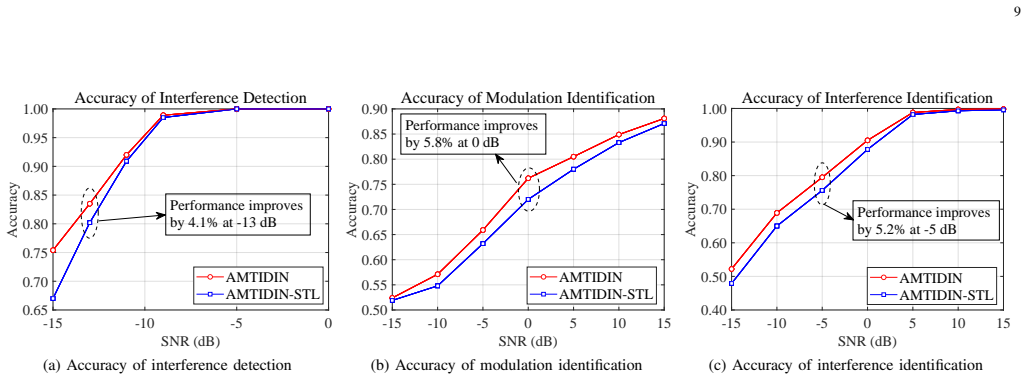
- AMTIDIN achieves higher accuracy and stability than single-task learning baselines across all three tasks.
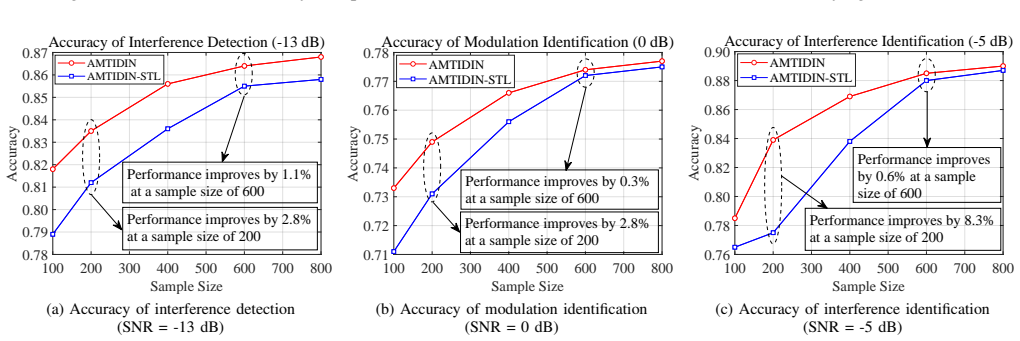
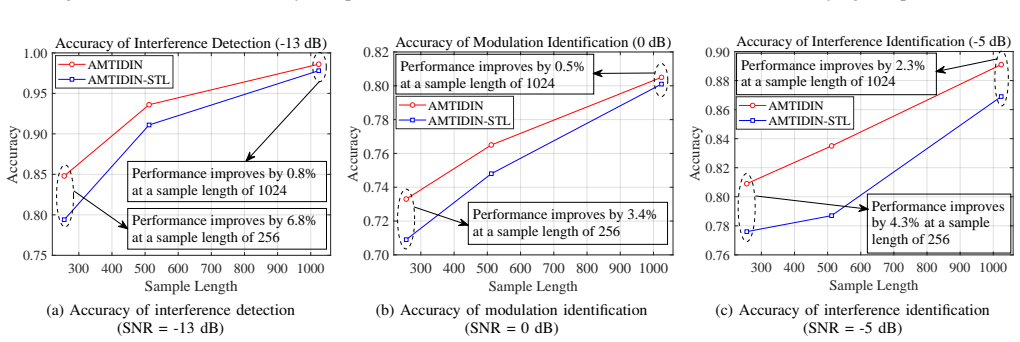
- The model surpasses state-of-the-art multi-task learning methods especially when training data is limited or signals are short.
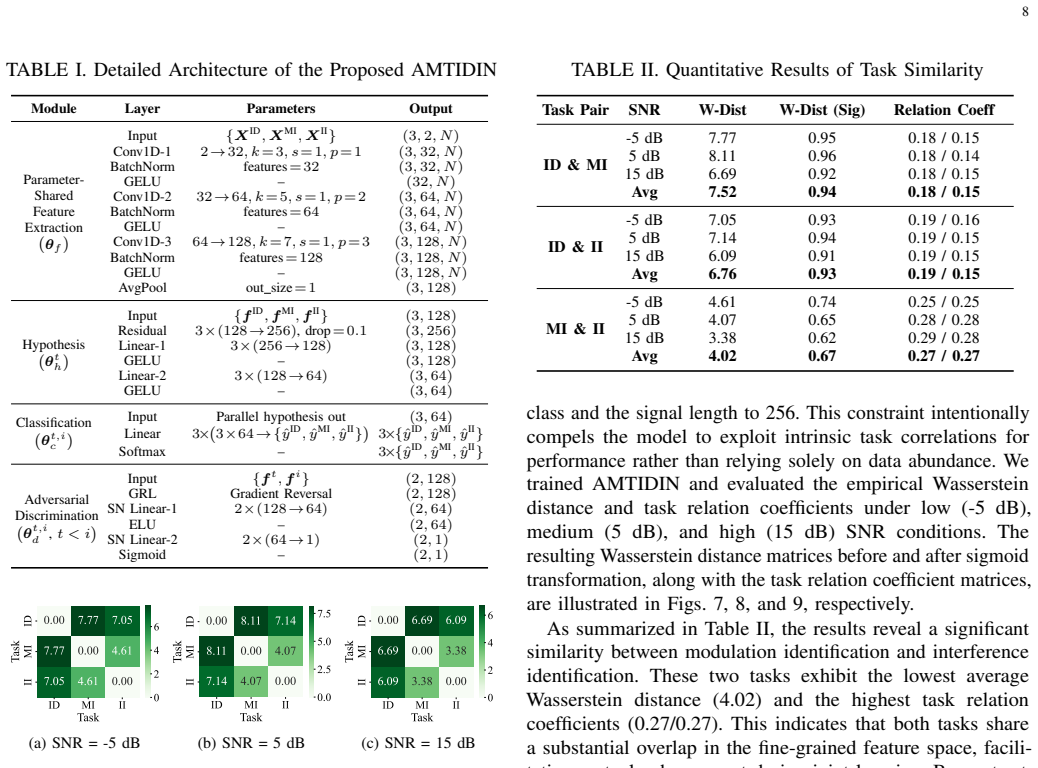
- Quantitative task-similarity analysis shows modulation identification and interference identification share substantial feature overlap distinct from interference detection.
- Performance gains are largest under low signal-to-noise ratios, supporting use in noisy non-cooperative environments.
Where Pith is reading between the lines
- The same theoretical bound on task similarity could be applied to other groups of correlated signal-processing tasks such as joint channel estimation and decoding.
- Replacing simulated training data with real over-the-air captures would test whether the learned coefficients remain stable outside laboratory distributions.
- The revealed feature overlap between modulation and interference identification suggests that future models could drop one task entirely when only the other is needed.
Load-bearing premise
The derived upper bound on weighted expected loss accurately captures real task similarity via Wasserstein distance and the learnable task relation coefficients will generalize beyond the training distributions used in the experiments.
What would settle it
Running the same comparative experiments on a fresh dataset containing unseen interference types or different propagation conditions and finding that AMTIDIN no longer outperforms the single-task and multi-task baselines would falsify the generalization claim.
Figures



read the original abstract
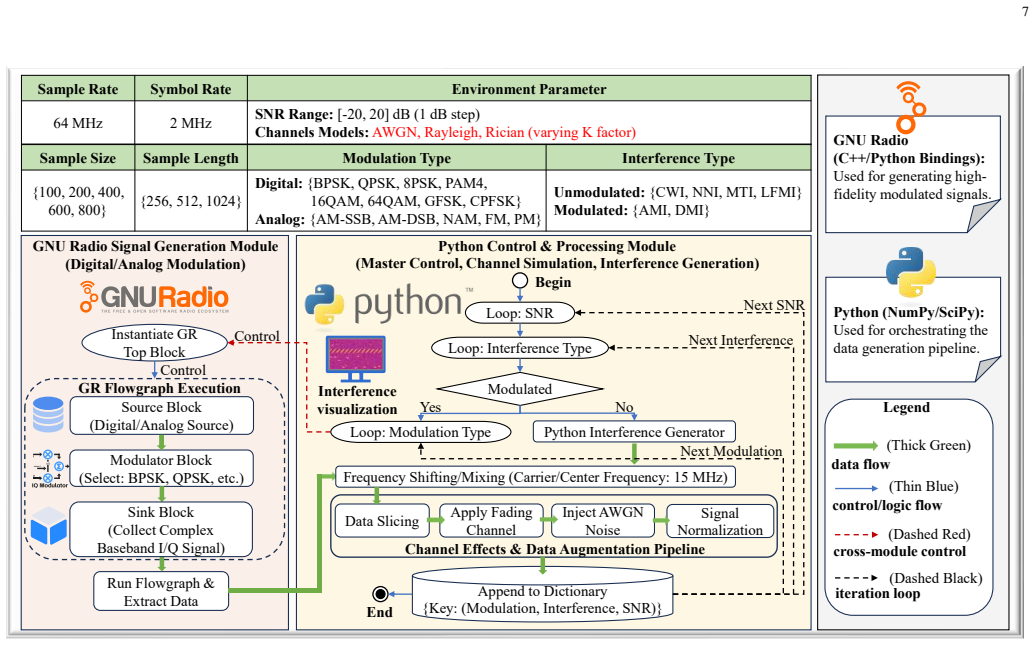
Precise interference detection and identification are crucial for enhancing the survivability of communication systems in non-cooperative wireless environments. While deep learning (DL) has advanced this field, existing single-task learning (STL) approaches neglect inherent task correlations. Furthermore, emerging multi-task learning (MTL) methods often lack a theoretical foundation for quantifying and modeling task relationships. To bridge this gap, we establish a theoretically grounded MTL framework for joint interference detection, modulation identification, and interference identification. First, we derive an upper bound for the weighted expected loss in MTL frameworks. This bound explicitly connects MTL performance to task similarity, quantified by the Wasserstein distance and learnable task relation coefficients. Guided by this theory, we present the adversarial multi-task interference detection and identification network (AMTIDIN), which integrates adversarial training to minimize distributional discrepancies across tasks and uses adaptive coefficients to model task correlations dynamically. Crucially, we conducted a quantitative analysis of task similarity to reveal intrinsic task relationships, specifically that modulation identification and interference identification share a substantial feature overlap distinct from interference detection. Extensive comparative experiments demonstrate that AMTIDIN significantly outperforms both its task-specific STL baseline and state-of-the-art MTL baselines in robustness and generalization, particularly under challenging conditions with limited training data, short signal lengths, and low signal-to-noise ratios (SNRs).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a theoretically grounded multi-task learning (MTL) framework for joint interference detection, modulation identification, and interference identification. It derives an upper bound on the weighted expected loss that links MTL performance to task similarity (via Wasserstein distance and learnable task relation coefficients), introduces the AMTIDIN network that combines adversarial training to reduce distributional discrepancies with adaptive coefficients to model correlations, performs a quantitative task-similarity analysis showing substantial feature overlap between modulation and interference identification (distinct from detection), and reports that AMTIDIN outperforms task-specific STL baselines and state-of-the-art MTL methods in robustness and generalization, especially under limited training data, short signal lengths, and low SNR.
Significance. If the upper bound is shown to be tight and the performance gains are demonstrably driven by the modeled task relations (rather than generic adversarial regularization), the work would offer a principled approach to exploiting task correlations in wireless signal processing, improving robustness in non-cooperative environments. The quantitative task-similarity analysis is a constructive element that could guide future MTL designs in related domains.
major comments (2)
- [Theoretical derivation of the upper bound] The central theoretical claim is that the derived upper bound on weighted expected loss explicitly connects MTL performance to task similarity quantified by Wasserstein distance and learnable coefficients. However, no evidence is provided that the bound is tight, that the Wasserstein term dominates the loss gap relative to STL/MTL baselines, or that the adaptive coefficients generalize beyond the training SNR/length distributions rather than overfitting them.
- [Experimental results and comparative analysis] The empirical claim that AMTIDIN significantly outperforms STL and MTL baselines under challenging conditions rests on the assumption that gains arise from the theory-guided components. Without ablations isolating the learnable coefficients and adversarial discrepancy minimization from standard MTL regularization, or statistical tests on the reported improvements, it remains unclear whether the outperformance is attributable to the proposed framework.
minor comments (2)
- [Abstract and experimental section] The abstract references 'extensive comparative experiments' and 'quantitative task-similarity analysis' but does not specify the number of independent runs, error bars, or exact dataset splits; these details are needed for reproducibility.
- [Method description] Notation for the learnable task relation coefficients and the precise form of the Wasserstein-based discrepancy term should be introduced with explicit equations to allow readers to verify the bound derivation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important aspects of the theoretical and empirical contributions that we will address through clarifications and targeted revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Theoretical derivation of the upper bound] The central theoretical claim is that the derived upper bound on weighted expected loss explicitly connects MTL performance to task similarity quantified by Wasserstein distance and learnable coefficients. However, no evidence is provided that the bound is tight, that the Wasserstein term dominates the loss gap relative to STL/MTL baselines, or that the adaptive coefficients generalize beyond the training SNR/length distributions rather than overfitting them.
Authors: We appreciate the referee's emphasis on empirical validation of the theoretical bound. The derivation establishes an upper bound that motivates the use of Wasserstein distance for discrepancy minimization and learnable coefficients to capture task relations, providing a principled basis for the AMTIDIN design and the observed task similarity analysis. While the original manuscript does not include direct empirical checks on bound tightness or dominance of the Wasserstein term, we will revise the paper to add a dedicated analysis section. This will compare the theoretical bound against empirical weighted losses across SNR and signal length regimes, include ablations quantifying the Wasserstein contribution relative to baselines, and test coefficient generalization on out-of-distribution SNR and length data to address potential overfitting concerns. revision: yes
-
Referee: [Experimental results and comparative analysis] The empirical claim that AMTIDIN significantly outperforms STL and MTL baselines under challenging conditions rests on the assumption that gains arise from the theory-guided components. Without ablations isolating the learnable coefficients and adversarial discrepancy minimization from standard MTL regularization, or statistical tests on the reported improvements, it remains unclear whether the outperformance is attributable to the proposed framework.
Authors: We agree that stronger isolation of components and statistical rigor would better substantiate the claims. The reported gains are tied to the theory-guided elements (adversarial training and adaptive coefficients), as supported by the task-similarity analysis showing feature overlap between modulation and interference identification. In the revision, we will add ablation experiments that disable the adversarial discrepancy minimization and the learnable coefficients independently, comparing against standard MTL regularization baselines. We will also conduct multiple independent training runs and report statistical significance tests (e.g., paired t-tests with p-values) on the performance differences, focusing on the challenging regimes of low SNR, limited data, and short signals to confirm attribution to the proposed framework. revision: yes
Circularity Check
No circularity: theoretical bound and empirical comparisons are independent
full rationale
The paper derives an upper bound on weighted expected loss that links MTL performance to task similarity (Wasserstein distance plus learnable coefficients), then uses this to motivate an adversarial MTL architecture with adaptive coefficients. Experiments compare the resulting model against STL and MTL baselines under varied data/SNR/length conditions. No quoted equation or step reduces the bound, the learned coefficients, or the performance claims to a tautological fit or self-citation chain; the bound is presented as a first-principles derivation, the coefficients are standard learnable parameters, and outperformance is shown via direct empirical evaluation rather than by construction from the bound itself. The framework is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- learnable task relation coefficients
axioms (1)
- domain assumption An upper bound exists for the weighted expected loss in MTL that explicitly depends on task similarity measured by Wasserstein distance
invented entities (1)
-
AMTIDIN network
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Towards secure semantic transmission in the era of GenAI: A diffusion-based framework,
B. Heet al., “Towards secure semantic transmission in the era of GenAI: A diffusion-based framework,”IEEE Commun. Mag., Feb. 2026, early access, doi: 10.1109/MCOM.001.2500553
-
[2]
Dynamic spectrum anti-jamming communications: Challenges and opportunities,
X. Wanget al., “Dynamic spectrum anti-jamming communications: Challenges and opportunities,”IEEE Commun. Mag., vol. 58, no. 2, pp. 79–85, Feb. 2020
work page 2020
-
[3]
Jamming attacks and anti-jamming strategies in wireless networks: A comprehensive survey,
H. Pirayesh and H. Zeng, “Jamming attacks and anti-jamming strategies in wireless networks: A comprehensive survey,”IEEE Commun. Surveys Tuts., vol. 24, no. 2, pp. 767–809, 2nd Quart. 2022
work page 2022
-
[4]
S. Zhao, Y . Zhou, L. Zhang, Y . Guo, and S. Tang, “Discrimination between radar targets and deception jamming in distributed multiple-radar architectures,”IET Radar Sonar Navig., vol. 11, no. 7, pp. 1124–1131, Jul. 2017
work page 2017
-
[5]
D. Wang, N. Zhang, Z. Li, F. Gao, and X. Shen, “Leveraging high order cumulants for spectrum sensing and power recognition in cognitive radio networks,”IEEE Trans. Wireless Commun., vol. 17, no. 2, pp. 1298–1310, Feb. 2018
work page 2018
-
[6]
X. Yan, G. Liu, H.-C. Wu, G. Zhang, Q. Wang, and Y . Wu, “Robust modulation classification over α-stable noise using graph-based fractional lower-order cyclic spectrum analysis,”IEEE Trans. Veh. Technol., vol. 69, no. 3, pp. 2836–2849, Mar. 2020
work page 2020
-
[7]
Time-frequency analysis of seismic data using synchrosqueezing transform,
P. Wang, J. Gao, and Z. Wang, “Time-frequency analysis of seismic data using synchrosqueezing transform,”IEEE Geosci. Remote Sens. Lett., vol. 11, no. 12, pp. 2042–2044, Dec. 2014
work page 2042
-
[8]
Recognition of UA V video signal using RF fingerprints in the presence of WiFi interference,
M. Zuo, S. Xie, X. Zhang, and M. Yang, “Recognition of UA V video signal using RF fingerprints in the presence of WiFi interference,”IEEE Access, vol. 9, pp. 88 844–88 851, 2021
work page 2021
-
[9]
The interference classification and recognition based on SF-SVM algorithm,
G.-S. Wang, Q.-H. Ren, and Y .-Z. Su, “The interference classification and recognition based on SF-SVM algorithm,” inProc. IEEE Int. Conf. Commun. Softw. Netw. (ICCSN), May 2017, pp. 835–841
work page 2017
-
[10]
Deep learning for spectrum sensing,
J. Gao, X. Yi, C. Zhong, X. Chen, and Z. Zhang, “Deep learning for spectrum sensing,”IEEE Wireless Commun. Lett., vol. 8, no. 6, pp. 1727–1730, Dec. 2019
work page 2019
-
[11]
ConvLSTM- based spectrum sensing at very low SNR,
Q. Wang, B. Su, C. Wang, L. P. Qian, Y . Wu, and X. Yang, “ConvLSTM- based spectrum sensing at very low SNR,”IEEE Wireless Commun. Lett., vol. 12, no. 6, pp. 967–971, Jun. 2023
work page 2023
-
[12]
K. N. R. S. V . Prasad, K. B. D’souza, and V . K. Bhargava, “A downscaled faster-RCNN framework for signal detection and time- frequency localization in wideband RF systems,”IEEE Trans. Wireless Commun., vol. 19, no. 7, pp. 4847–4862, Jul. 2020
work page 2020
-
[13]
Deep learning models for wireless signal classification with distributed low-cost spectrum sensors,
S. Rajendran, W. Meert, D. Giustiniano, V . Lenders, and S. Pollin, “Deep learning models for wireless signal classification with distributed low-cost spectrum sensors,”IEEE Trans. Cogn. Commun. Netw., vol. 4, no. 3, pp. 433–445, Sep. 2018
work page 2018
-
[14]
DeepSIG: A hybrid heterogeneous deep learning framework for radio signal classification,
K. Qiu, S. Zheng, L. Zhang, C. Lou, and X. Yang, “DeepSIG: A hybrid heterogeneous deep learning framework for radio signal classification,” IEEE Trans. Wireless Commun., vol. 23, no. 1, pp. 775–788, Jan. 2024
work page 2024
-
[15]
W. Kong, X. Jiao, Y . Xu, B. Zhang, and Q. Yang, “A transformer-based contrastive semi-supervised learning framework for automatic modulation recognition,”IEEE Trans. Cogn. Commun. Netw., vol. 9, no. 4, pp. 950– 962, Aug. 2023
work page 2023
-
[16]
Y . Li, X. Shi, H. Tan, Z. Zhang, X. Yang, and F. Zhou, “Multi- representation domain attentive contrastive learning based unsupervised automatic modulation recognition,”Nat. Commun., vol. 16, no. 1, p. 5951, Jul. 2025
work page 2025
-
[17]
Wireless interference identification with convolutional neural networks,
M. Schmidt, D. Block, and U. Meier, “Wireless interference identification with convolutional neural networks,” inProc. IEEE Int. Conf. Ind. Informat. (INDIN), Jul. 2017, pp. 180–185
work page 2017
-
[18]
Intelligent wireless interference identi- fication with lightweight transformer network,
P. Wang, Z. Wang, and Z. Han, “Intelligent wireless interference identi- fication with lightweight transformer network,”IEEE Trans. Commun., vol. 73, no. 11, pp. 11 355–11 367, Nov. 2025
work page 2025
-
[19]
Multi-domain networks for wireless interference recognition,
P. Wang, Y . Cheng, B. Dong, Q. Peng, and S. Li, “Multi-domain networks for wireless interference recognition,”IEEE Trans. Veh. Technol., vol. 71, no. 6, pp. 6534–6547, Jun. 2022
work page 2022
-
[20]
Wireless interference recognition with multimodal learning,
P. Wang, K. Ma, Y . Bai, C. Sun, Z. Wang, and S. Chen, “Wireless interference recognition with multimodal learning,”IEEE Trans. Wireless Commun., vol. 23, no. 12, pp. 18 576–18 591, Dec. 2024
work page 2024
-
[21]
JDMR-net: Joint detection and modulation recognition networks for LPI radar signals,
Z. Zhang, M. Zhu, Y . Li, and S. Wang, “JDMR-net: Joint detection and modulation recognition networks for LPI radar signals,”IEEE Trans. Aerosp. Electron. Syst., vol. 59, no. 6, pp. 7575–7589, Dec. 2023
work page 2023
-
[22]
Joint signal detection and automatic modulation classification via deep learning,
H. Xinget al., “Joint signal detection and automatic modulation classification via deep learning,”IEEE Trans. Wireless Commun., vol. 23, no. 11, pp. 17 129–17 142, Nov. 2024
work page 2024
-
[23]
Multi-task based deep learning approach for open-set wireless signal identification in ISM band,
J. Gong, X. Qin, and X. Xu, “Multi-task based deep learning approach for open-set wireless signal identification in ISM band,”IEEE Trans. Cogn. Commun. Netw., vol. 8, no. 1, pp. 121–135, Mar. 2022
work page 2022
-
[24]
R. Zhaoet al., “Low complexity wireless interference identification in antagonistic environments based on multi-task learning,”IEEE Trans. Veh. Technol., vol. 74, no. 9, pp. 13 953–13 967, Sep. 2025
work page 2025
-
[25]
Adaptive smoothed online multi-task learning,
K. Murugesan, H. Liu, J. Carbonell, and Y . Yang, “Adaptive smoothed online multi-task learning,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), Dec. 2016, pp. 4296–4304
work page 2016
-
[26]
Multi-task learning with labeled and unlabeled tasks,
A. Pentina and C. H. Lampert, “Multi-task learning with labeled and unlabeled tasks,” inProc. Int. Conf. Mach. Learn. (ICML), Aug. 2017, pp. 2807–2816
work page 2017
-
[27]
A theory of learning from different domains,
S. Ben-David, J. Blitzer, K. Crammer, A. Kulesza, F. Pereira, and J. W. Vaughan, “A theory of learning from different domains,”Mach. Learn., vol. 79, no. 1-2, pp. 151–175, May 2010
work page 2010
-
[28]
Theoretical analysis of domain adaptation with optimal transport,
I. Redko, A. Habrard, and M. Sebban, “Theoretical analysis of domain adaptation with optimal transport,” inProc. Eur. Conf. Mach. Learn. Knowl. Discov. Databases (ECML PKDD), Sep. 2017, pp. 737–753
work page 2017
-
[29]
Wasserstein distance guided representation learning for domain adaptation,
J. Shen, Y . Qu, W. Zhang, and Y . Yu, “Wasserstein distance guided representation learning for domain adaptation,” inProc. AAAI Conf. Artif. Intell. (AAAI), Feb. 2018, pp. 4058–4065
work page 2018
-
[30]
A principled approach for learning task similarity in multitask learning,
C. Shui, M. Abbasi, L.- ´E. Robitaille, B. Wang, and C. Gagn ´e, “A principled approach for learning task similarity in multitask learning,” in Proc. Int. Joint Conf. Artif. Intell. (IJCAI), Aug. 2019, pp. 3446–3452
work page 2019
-
[31]
Task similarity estimation through adversarial multitask neural network,
F. Zhou, C. Shui, M. Abbasi, L.-E. Robitaille, B. Wang, and C. Gagn ´e, “Task similarity estimation through adversarial multitask neural network,” IEEE Trans. Neural Netw. Learn. Syst., vol. 32, no. 2, pp. 466–480, Feb. 2021
work page 2021
-
[32]
Wasserstein generative adversarial networks,
M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein generative adversarial networks,” inProc. Int. Conf. Mach. Learn. (ICML), Aug. 2017, pp. 214–223
work page 2017
-
[33]
Domain-adversarial training of neural networks,
Y . Ganinet al., “Domain-adversarial training of neural networks,”J. Mach. Learn. Res., vol. 17, no. 59, pp. 1–35, Apr. 2016
work page 2016
-
[34]
Spectral normal- ization for generative adversarial networks,
T. Miyato, T. Kataoka, M. Koyama, and Y . Yoshida, “Spectral normal- ization for generative adversarial networks,” inProc. Int. Conf. Learn. Represent. (ICLR), Apr. 2018
work page 2018
-
[35]
Improved training of wasserstein GANs,
I. Gulrajani, F. Ahmed, M. Arjovsky, V . Dumoulin, and A. C. Courville, “Improved training of wasserstein GANs,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), Dec. 2017, pp. 5767–5777
work page 2017
-
[36]
CVXPY: A python-embedded modeling language for convex optimization,
S. Diamond and S. Boyd, “CVXPY: A python-embedded modeling language for convex optimization,”J. Mach. Learn. Res., vol. 17, no. 83, pp. 1–5, May 2016
work page 2016
-
[37]
Radio machine learning dataset generation with gnu radio,
T. J. O’Shea and N. West, “Radio machine learning dataset generation with gnu radio,” inProc. GNU Radio Conf., Sep. 2016
work page 2016
-
[38]
Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,
J. Ma, Z. Zhao, X. Yi, J. Chen, L. Hong, and E. H. Chi, “Modeling task relationships in multi-task learning with multi-gate mixture-of-experts,” inProc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. (KDD), Aug. 2018, pp. 1930–1939
work page 2018
-
[39]
J. Weed and F. Bach, “Sharp asymptotic and finite-sample rates of convergence of empirical measures in wasserstein distance,”Bernoulli, vol. 25, no. 4A, pp. 2620–2648, Nov. 2019
work page 2019
-
[40]
Villani,Optimal Transport: Old and New
C. Villani,Optimal Transport: Old and New. Berlin, Germany: Springer, 2009, vol. 338
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.