Use of AI Tools: Guidelines to Maintain Academic Integrity in Computing Colleges
Pith reviewed 2026-05-10 16:12 UTC · model grok-4.3
The pith
A framework of guidelines and a formal model enables responsible integration of AI tools in computing education while preserving academic integrity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
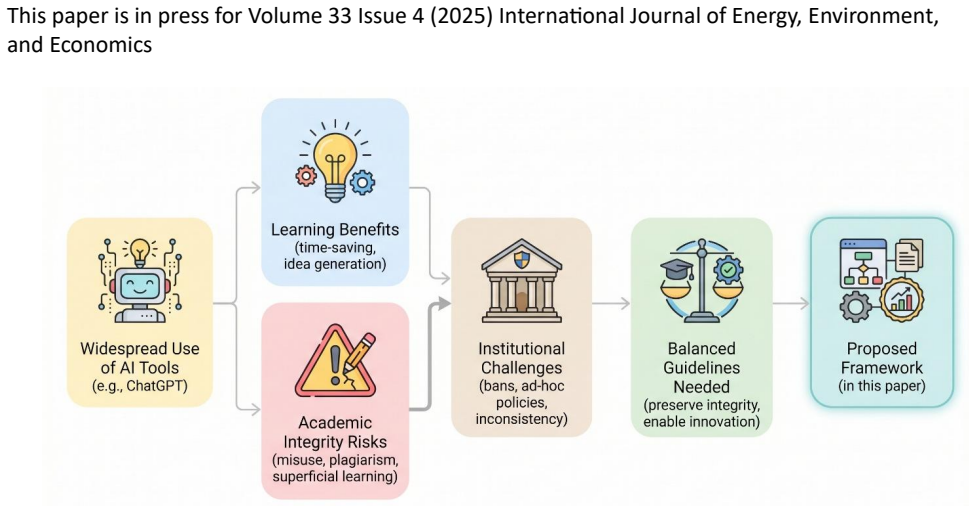
The authors classify common assessment techniques in computing education and analyze their exposure to AI assistance. They then offer general guidelines for responsible AI integration across formats, provide targeted recommendations for specific assessment types to support learning goals and deter misconduct, and present a formal mathematical model as a structured way to evaluate student assessments when AI tools are involved.
What carries the argument
The formal mathematical model that supplies a structured framework for assessing student work completed with the aid of AI tools.
If this is right
- General guidelines allow instructors to adapt their pedagogy for AI across various computing assessments.
- Assessment-specific recommendations help preserve the intended learning outcomes for each format.
- The formal model offers a consistent structure for determining the extent of AI influence in submissions.
- Together these tools support the use of AI for improved efficiency and confidence while safeguarding integrity.
Where Pith is reading between the lines
- Such a framework might inspire similar guideline sets for fields outside of computing.
- Real-world application of the model could reveal whether it leads to fairer grading practices.
- The guidelines may require updates as AI capabilities evolve rapidly.
- Departments could incorporate these ideas into faculty development programs.
Load-bearing premise
That these guidelines and the accompanying mathematical model can be applied effectively to maintain academic integrity alongside AI benefits, despite lacking any reported tests or validation.
What would settle it
Observing whether classes that follow the guidelines show lower rates of AI-related misconduct or if the model accurately flags AI contributions in sample submissions.
Figures

read the original abstract
The rapid adoption of AI tools such as ChatGPT has significantly transformed academic practices, offering considerable benefits for both students and faculty in computing disciplines. These tools have been shown to enhance learning efficiency, academic self-efficacy, and confidence. However, their increasing use also raises pressing concerns regarding the preservation of academic integrity -- an essential pillar of the educational process. This paper explores the implications of widespread AI tool usage within computing colleges, with a particular focus on how to align their use with the principles of academic honesty. We begin by classifying common assessment techniques employed in computing education and examine how each may be impacted by AI-assisted tools. Building on this foundation, we propose a set of general guidelines applicable across various assessment formats to help instructors responsibly integrate AI tools into their pedagogy. Furthermore, we provide targeted, assessment-specific recommendations designed to uphold educational objectives while mitigating risks of academic misconduct. These guidelines serve as a practical framework for instructors aiming to balance the pedagogical advantages of AI tools with the imperative of maintaining academic integrity in computing education. Finally, we introduce a formal model that provides a structured mathematical framework for evaluating student assessments in the presence of AI-assisted tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper classifies common assessment techniques in computing education and examines their vulnerability to AI tools such as ChatGPT. It proposes a set of general guidelines for instructors to integrate AI responsibly into pedagogy, supplies targeted recommendations for specific assessment formats to uphold academic integrity, and introduces a formal mathematical model intended to provide a structured framework for evaluating student work in the presence of AI assistance.
Significance. If the guidelines prove actionable and the formal model is fully specified with consistent, demonstrably useful outputs, the work could supply a practical reference for computing educators seeking to harness AI benefits while safeguarding integrity. The dual structure of general and assessment-specific recommendations offers a systematic starting point that, once validated, might inform departmental policies or faculty development programs.
major comments (2)
- [Formal model section] The section introducing the formal model states that it supplies a 'structured mathematical framework' for evaluating assessments with AI tools, yet no equations, variable definitions, parameters, or functional form are provided. Without these, the model cannot be checked for internal consistency or shown to yield actionable evaluations, which directly undercuts the central claim that the framework helps instructors balance benefits and integrity.
- [Guidelines and recommendations sections] No concrete worked example applies either the general guidelines or the model to a specific assessment (e.g., a programming assignment or closed-book exam), and the manuscript contains no empirical data, pilot results, or comparison against human grading or misconduct rates. This absence leaves the claim that the proposals effectively mitigate risks untested and therefore load-bearing for the paper's overall contribution.
minor comments (1)
- [Abstract] The abstract asserts that the guidelines 'serve as a practical framework' but does not clarify how the general guidelines relate to or are instantiated by the assessment-specific recommendations; a short bridging sentence would improve readability.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments highlight important areas for improvement in the presentation of the formal model and the need for illustrative applications. We address each major comment below and commit to revisions that strengthen the manuscript without altering its conceptual focus.
read point-by-point responses
-
Referee: [Formal model section] The section introducing the formal model states that it supplies a 'structured mathematical framework' for evaluating assessments with AI tools, yet no equations, variable definitions, parameters, or functional form are provided. Without these, the model cannot be checked for internal consistency or shown to yield actionable evaluations, which directly undercuts the central claim that the framework helps instructors balance benefits and integrity.
Authors: We accept this observation. The manuscript introduces the formal model at a conceptual level but does not supply the explicit mathematical components required for verification or practical use. In the revised version we will expand the section to include a fully specified model with all equations, variable definitions, parameters, and the functional form. This will permit direct checks for internal consistency and demonstrate how the framework can be applied to balance pedagogical benefits against integrity risks. revision: yes
-
Referee: [Guidelines and recommendations sections] No concrete worked example applies either the general guidelines or the model to a specific assessment (e.g., a programming assignment or closed-book exam), and the manuscript contains no empirical data, pilot results, or comparison against human grading or misconduct rates. This absence leaves the claim that the proposals effectively mitigate risks untested and therefore load-bearing for the paper's overall contribution.
Authors: We agree that worked examples would make the guidelines and model more actionable. The revised manuscript will include concrete examples applying both the general guidelines and the formal model to specific assessments, such as a programming assignment and a closed-book exam. The paper is a conceptual proposal grounded in classification of assessment techniques and analysis of AI capabilities; it does not present original empirical data or pilot studies because its contribution lies in the framework and recommendations rather than experimental validation. We will explicitly note this scope limitation and outline directions for future empirical testing. revision: partial
- The absence of original empirical data, pilot results, or quantitative comparisons validating the effectiveness of the proposed guidelines and model in reducing academic misconduct.
Circularity Check
No derivation chain or equations present; guidelines and model introduced at descriptive level only
full rationale
The manuscript classifies assessments, proposes general and assessment-specific guidelines for AI use, and states that it introduces a formal model providing a structured mathematical framework. No explicit equations, variables, derivations, fitted parameters, or self-citations appear in the abstract or described content. Without any load-bearing mathematical steps or reductions to inputs, no circularity patterns (self-definitional, fitted-input-as-prediction, etc.) can be identified. The central claims rest on untested assertions rather than a derivational chain that could be circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Bin-Nashwan, M. Sadallah, M. Bouteraa, Use of ChatGPT in academia: Academic Integrity hangs in the balance, 2023
work page 2023
- [2]
-
[3]
M. Timothy, 3 reasons why ChatGPT became the fastest growing app of all time, available at: https://www.makeuseof.com/how-chatgpt-became-fastest-growing-app/, 2023
work page 2023
-
[4]
Similarweb, chat.openai.com overview. https://www.similarweb. com/website/chat.openai.com/#overview, 2023
work page 2023
-
[5]
F. Duarte, Number of ChatGPT users (2023), available at:, 2023 https://explodingtopics.com/blog/chatgpt-users
work page 2023
- [6]
-
[7]
Huang, Alarmed by AI Chatbots, Universities Start Revamping How They Teach, 2023 (New York Times)
K. Huang, Alarmed by AI Chatbots, Universities Start Revamping How They Teach, 2023 (New York Times)
work page 2023
-
[8]
Becker, A theory of the allocation of time, Econ
G.S. Becker, A theory of the allocation of time, Econ. J. 75 (299) (1965) 493–517
work page 1965
-
[9]
[K. Martha, Factors affecting academic performance of undergraduate students at Uganda Christian University, Caribbean Teaching Scholar 1 (2) (2010) 79–92
work page 2010
-
[10]
S.W. Litvin, R.E. Goldsmith, B. Pan, Electronic word-of-mouth in hospitality and tourism management, Tourism Manag. 29 (3) (2008) 458–468, https://doi.org/ 10.1016/j.tourman.2007.05.011
-
[11]
A. Reyes-Menendez, J.R. Saura, J.G. Martinez-Navalon, The impact of e-WOM on hotels management reputation: exploring tripadvisor review credibility with the ELM model, IEEE Access 7 (2019) 68868– 68877
work page 2019
- [12]
-
[13]
I. Ajzen, Constructing a TPB Questionnaire: Conceptual and Methodological Considerations, available at:, 2002 https://people.umass.edu/aizen/pdf/tpb. measurement.pdf
work page 2002
- [14]
-
[15]
T.A. Judge, E.A. Locke, C.C. Durham, A.N. Kluger, Dispositional effects on job and life satisfaction: the role of core evaluations, J. Appl. Psychol. 83 (1) (1998) 17–34, https://doi.org/10.1037/0021- 9010.83.1.17
-
[16]
M. Bong, E.M. Skaalvik, Academic self-concept and self-efficacy: how different are they really? Educ. Psychol. Rev. 15 (1) (2003) 1–40, https://doi.org/ 10.1023/A:1021302408382
-
[17]
C. Midgley, M.L. Maehr, L.Z. Hruda, E. Anderman, L. Anderman, K.E. Freeman, T. Urdan, Manual for the Patterns of Adaptive Learning Scales, University of Michigan, Ann Arbor, 2000, pp. 734–763
work page 2000
-
[18]
Fisher, Stress and Strategy, Routledge, 2015, https://doi.org/10.4324/9781315627212
S. Fisher, Stress and Strategy, Routledge, 2015, https://doi.org/10.4324/9781315627212. S.A. Bin- Nashwan et al. Technology in Society 75 (2023) 102370
- [19]
-
[20]
A. Bozkurt, R. Sharma, Generative artificial intelligence in education: Opportunities, challenges, and implications, Educational Technology & Society, 27 (1) (2024) 1–17
work page 2024
-
[21]
M. Kasneci, S. Sessler, M. Küchemann, et al., ChatGPT for good? On opportunities and challenges of large language models for education, Learning and Individual Differences 103 (2024) 102274. This paper is in press for Volume 33 Issue 4 (2025) International Journal of Energy, Environment, and Economics 16
work page 2024
-
[22]
J. Rudolph, S. Tan, S. Tan, ChatGPT: Bullshit spewer or the end of traditional assessments in higher education?, Journal of Applied Learning & Teaching 7 (1) (2024) 1–22
work page 2024
- [23]
-
[24]
J. Malinka, M. Peresini, F. Vojtko, P. Hujnák, On the educational impact of GitHub Copilot in programming courses, ACM Transactions on Computing Education 24 (1) (2024) Article 6
work page 2024
- [25]
-
[26]
OECD, Artificial Intelligence in Education: Challenges and Opportunities for Sustainable Learning, OECD Publishing, Paris, 2024
work page 2024
-
[27]
IEEE Educational Activities, Artificial Intelligence and Academic Integrity in Engineering Education, IEEE, 2024
work page 2024
-
[28]
Jan, S., Ali, T., Alzahrani, A., & Musa, S. (2018). Deep convolutional generative adversarial networks for intent-based dynamic behavior capture. Int. J. Eng. Technol, 7(4), 101-103
work page 2018
-
[29]
Ismail, R., Syed, T. A., & Musa, S. (2014, January). Design and implementation of an efficient framework for behaviour attestation using n-call slides. In Proceedings of the 8th International Conference on Ubiquitous Information Management and Communication (pp. 1-8)
work page 2014
-
[30]
Syed, T. A., Jan, S., Siddiqui, M. S., Alzahrani, A., Nadeem, A., Ali, A., & Ullah, A. (2022). CAR- tourist: An integrity-preserved collaborative augmented reality framework-tourism as a use-case. Applied Sciences, 12(23), 12022
work page 2022
-
[31]
Alqahtany, S. S., & Syed, T. A. (2024). Integrating blockchain and deep learning for enhanced mobile vpn forensics: a comprehensive framework. Applied Sciences, 14(11), 4421
work page 2024
-
[32]
Mastoi, Q. U. A., Memon, M. F., Jan, S., Jamil, A., Faique, M., Ali, Z., ... & Syed, T. A. (2025). Enhancing Deepfake Content Detection Through Blockchain Technology. International Journal of Advanced Computer Science & Applications, 16(6)
work page 2025
-
[33]
Ali, T., Khan, Y., Ali, T., Faizullah, S., Alghamdi, T., & Anwar, S. (2020). An Automated Permission Selection Framework for Android Platform: T. Ali et al. Journal of Grid Computing, 18(3), 547-561
work page 2020
-
[34]
A blockchain-monitored agentic ai architecture for trusted perception- reasoning-action pipelines,
Jan, S., Razzaqi, H. A., Akarma, A., & Belgaum, M. R. (2025). A Blockchain-Monitored Agentic AI Architecture for Trusted Perception-Reasoning-Action Pipelines. arXiv preprint arXiv:2512.20985
-
[35]
A., Khan, S., Jan, S., Ali, G., Nauman, M., Akarma, A., & Ali, A
Syed, T. A., Khan, S., Jan, S., Ali, G., Nauman, M., Akarma, A., & Ali, A. (2025). Agentic ai framework for cloudburst prediction and coordinated response. arXiv preprint arXiv:2511.22767
-
[36]
Asmat, H., Din, I. U., Almogren, A., Syed, T. A., & Rodrigues, J. J. (2026). Consumer-Centric Explainable Multimodal Digital Twin Modeling for Personalized Alzheimer’s Detection in Healthcare 5.0. IEEE Transactions on Consumer Electronics
work page 2026
-
[37]
A., Ali, G., Akarma, A., Belgaum, M
Jan, S., Syed, T. A., Ali, G., Akarma, A., Belgaum, M. R., & Ali, A. (2025). Agentic ai framework for individuals with disabilities and neurodivergence: A multi-agent system for healthy eating, daily routines, and inclusive well-being. arXiv preprint arXiv:2511.22737
-
[38]
A., Alshahrani, A., Ullah, A., Akarma, A., Khan, S., Nauman, M., & Jan, S
Syed, T. A., Alshahrani, A., Ullah, A., Akarma, A., Khan, S., Nauman, M., & Jan, S. (2025). FinAgent: An Agentic AI Framework Integrating Personal Finance and Nutrition Planning. arXiv preprint arXiv:2512.20991. Declarations Ethics approval and consent to participate: This work complies with ethical standards. No human or animal participants were involved...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.