Quantifying and Mitigating Self-Preference Bias of LLM Judges
Pith reviewed 2026-05-15 06:54 UTC · model grok-4.3
The pith
LLM judges show self-preference bias uncorrelated with capability, but a multi-dimensional strategy reduces it by 31.5 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
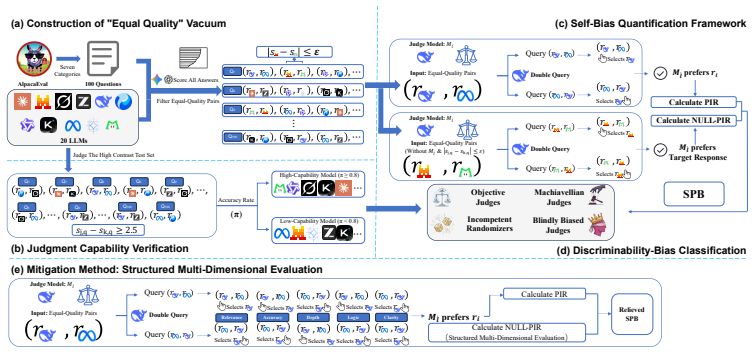
Self-preference bias is a directional deviation where LLMs favor their own generated responses during evaluation. The paper's fully automated framework constructs equal-quality response pairs to quantify bias propensity separately from discriminability without human gold standards. Empirical results across 20 mainstream LLMs show that advanced capabilities are often uncorrelated or negatively correlated with low bias. A structured multi-dimensional evaluation strategy grounded in cognitive load decomposition mitigates this bias by 31.5 percent on average.
What carries the argument
Equal-quality response pairs that statistically disentangle bias propensity from genuine discriminability, combined with the cognitive load decomposition that structures evaluations into multiple independent dimensions.
If this is right
- Bias in LLM-as-a-Judge systems can be quantified at scale without human annotations.
- Mitigation via multi-dimensional evaluation can improve trustworthiness in model alignment and leaderboard construction.
- Advanced model capabilities alone do not solve evaluative fairness.
- Real-world quality control systems using LLM judges can apply the strategy to reduce systematic favoritism.
Where Pith is reading between the lines
- Training methods that improve capability may need separate adjustments to avoid reinforcing self-referential judgments.
- The framework could extend to measuring other directional biases in automated evaluation pipelines.
- Deployments in content moderation or feedback loops might gain reliability by adopting the cognitive load approach.
Load-bearing premise
The constructed pairs of responses have truly negligible quality differences so that any preference can be attributed to bias rather than actual differences.
What would settle it
Human raters detect consistent quality differences in the constructed pairs, or the proposed mitigation strategy shows no reduction in measured bias when true preferences are independently verified.
Figures



read the original abstract
LLM-as-a-Judge has become a dominant approach in automated evaluation systems, playing critical roles in model alignment, leaderboard construction, quality control, and so on. However, the scalability and trustworthiness of this approach can be substantially distorted by Self-Preference Bias (SPB), which is a directional evaluative deviation in which LLMs systematically favor or disfavor their own generated outputs during evaluation. Existing measurements rely on costly human annotations and conflate generative capability with evaluative stance, and thus are impractical for large-scale deployment in real-world systems. To address this issue, we introduce a fully automated framework to quantifying and mitigating SPB, which constructs equal-quality pairs of responses with negligible quality differences, enabling statistical disentanglement of discriminability from bias propensity without human gold standards. Empirical analysis across 20 mainstream LLMs reveals that advanced capabilities are often uncorrelated, or even negatively correlated, with low SPB. To mitigate this bias, we propose a structured multi-dimensional evaluation strategy grounded in cognitive load decomposition, which reduces SPB by 31.5\% on average.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a fully automated framework for quantifying and mitigating Self-Preference Bias (SPB) in LLM-as-a-Judge evaluations. It constructs equal-quality response pairs with negligible quality differences to statistically disentangle bias propensity from discriminability without human gold standards. Through analysis of 20 mainstream LLMs, it finds that advanced capabilities are often uncorrelated or negatively correlated with low SPB. It proposes a structured multi-dimensional evaluation strategy based on cognitive load decomposition that reduces SPB by 31.5% on average.
Significance. If the automated pair construction is valid, this provides a scalable annotation-free method to measure and mitigate bias in LLM judges, which has broad implications for model alignment and leaderboard construction. The empirical results across 20 models are a strength, as is the attempt at a parameter-free statistical separation.
major comments (2)
- [§3] §3: The automated procedure for constructing equal-quality pairs lacks any independent verification (e.g., human ratings or cross-model consistency checks) that residual quality differences are negligible. This assumption is load-bearing for the statistical disentanglement of SPB from discriminability and for the reported correlations across models.
- [Abstract and results section] Abstract and results section: The 31.5% average reduction is presented without details on the exact statistical tests, confidence intervals, or controls for pair construction variability, making it impossible to assess whether the mitigation gain is robust.
minor comments (2)
- [Early sections] The formal definition of SPB would benefit from an explicit equation in the early sections to clarify how bias propensity is isolated from discriminability.
- [Figures and tables] Figure captions and table legends should explicitly state the number of pairs per model and any filtering criteria applied.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our automated framework. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§3] §3: The automated procedure for constructing equal-quality pairs lacks any independent verification (e.g., human ratings or cross-model consistency checks) that residual quality differences are negligible. This assumption is load-bearing for the statistical disentanglement of SPB from discriminability and for the reported correlations across models.
Authors: We acknowledge the centrality of this assumption but maintain that the framework's design enables statistical disentanglement without external verification. Equal-quality pairs are generated from identical prompts under tightly controlled sampling parameters, ensuring negligible quality variance by construction; the statistical separation then isolates SPB as the directional preference observed in these pairs while discriminability is measured on deliberately unequal pairs. Human ratings would undermine the automated, annotation-free goal. In revision we will add cross-model consistency checks (e.g., verifying that quality orderings remain stable when pairs are re-evaluated by held-out models) and report the resulting agreement statistics in §3. revision: partial
-
Referee: [Abstract and results section] Abstract and results section: The 31.5% average reduction is presented without details on the exact statistical tests, confidence intervals, or controls for pair construction variability, making it impossible to assess whether the mitigation gain is robust.
Authors: We agree that additional statistical rigor is required. In the revised manuscript we will specify the exact tests (paired t-tests with Bonferroni correction across the 20 models), report 95% confidence intervals around the 31.5% mean reduction, and include controls for pair-construction variability via bootstrap resampling of the pair-generation process and sensitivity analysis over prompt templates. These details will appear in the results section and be summarized in the abstract. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical framework for constructing equal-quality response pairs and a cognitive-load-based mitigation strategy, with the 31.5% SPB reduction reported as an observed experimental outcome across 20 LLMs rather than a quantity derived by construction from fitted parameters or self-referential definitions. No equations, ansatzes, or uniqueness theorems are invoked that reduce the central claims to inputs by tautology; the pair-construction procedure is a methodological choice whose validity is external to the reported statistics, and no self-citation load-bearing steps appear in the provided text. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Equal-quality response pairs can be constructed with negligible quality differences
invented entities (1)
-
Self-Preference Bias (SPB)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.1162/coli_a_00524. Gemini Team, & Google DeepMind (2025). Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint , 2507.06261 . URL: https://arxiv. org/abs/2507.06261. Gemma Team, & Google DeepMind (2025). Gemma 3: Open models based on gemini research and tech...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1162/coli_a_00524 2025
-
[2]
Relevance: Whether the response directly and completely answers the question in the instruction
-
[3]
Accuracy: Whether the information in the response is accurate, reliable, and error- free
-
[4]
Depth: Whether the response provides sufficient details, context, and depth
-
[5]
Logic: Whether the logic of the response is clear, coherent, and well-structured
-
[6]
Clarity: Whether the expression of the response is clear, understandable, and well- structured Table A.9: Quality Evaluation Prompt – Evaluation Dimension Definitions. Evaluation Criteria: Relevance & Accuracy Detailed Scoring Criteria (for each dimension): Relevance - 9.0-10.0 points: Fully understands the instruction, response directly and completely add...
-
[7]
Carefully read the instruction and response
-
[8]
Strictly follow the scoring criteria, independently score each dimension (0.0-10.0)
-
[9]
IMPORTANT: Use the full scoring range
-
[10]
Calculate the average of the five dimensions as the overall score
-
[11]
Provide detailed evaluation reasoning Instruction: {instruction} AI Response: {response} Please output the evaluation results in the following format: Dimension Scores: - Relevance: X.X points - Accuracy: X.X points - Depth: X.X points - Logic: X.X points - Clarity: X.X points Overall Score: X.X points Detailed Reasoning: [Specific analysis of each dimens...
-
[12]
Relevance: Which response is more relevant to the instruction? [A/B]
-
[13]
Accuracy: Which response is more accurate and factually correct? [A/B]
-
[14]
Depth: Which response provides more depth and comprehensive coverage? [A/B]
-
[15]
Logic: Which response has better logical structure and reasoning? [A/B]
-
[16]
Clarity: Which response is clearer and more well-organized? [A/B] After evaluating all five dimensions, make your final decision based on overall quality . You MUST output a single letter only: ’A’ or ’B’. Do NOT output any explanation or any other text. Answer (A or B only): Table A.17: structured multi-dimensional evaluation Prompt Template. 38 Appendix...
work page 2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.