Targeted Linguistic Analysis of Sign Language Models with Minimal Translation Pairs
Pith reviewed 2026-05-07 08:15 UTC · model grok-4.3
The pith
Sign language translation models rely primarily on manual hand cues and miss key non-manual cues from the face and body.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Using the new ASL-MTP dataset of minimal translation pairs for various sign language phenomena, analysis of a state-of-the-art ASL-to-English model demonstrates above-chance performance on most phenomena while showing strong reliance on manual cues and frequent omission of crucial non-manual cues.
What carries the argument
ASL Minimal Translation Pairs (ASL-MTP) dataset with targeted minimal pairs and cue ablation experiments that isolate the contribution of manual versus non-manual input channels.
Load-bearing premise
That ablating specific input cues during training and inference directly reveals the model's learned reliance on those cues without introducing artifacts from the removal process.
What would settle it
Observing whether the model's performance on minimal pairs that differ solely in non-manual cues drops to chance level when those cues are ablated, or remains unchanged when manual cues are removed.
Figures



read the original abstract
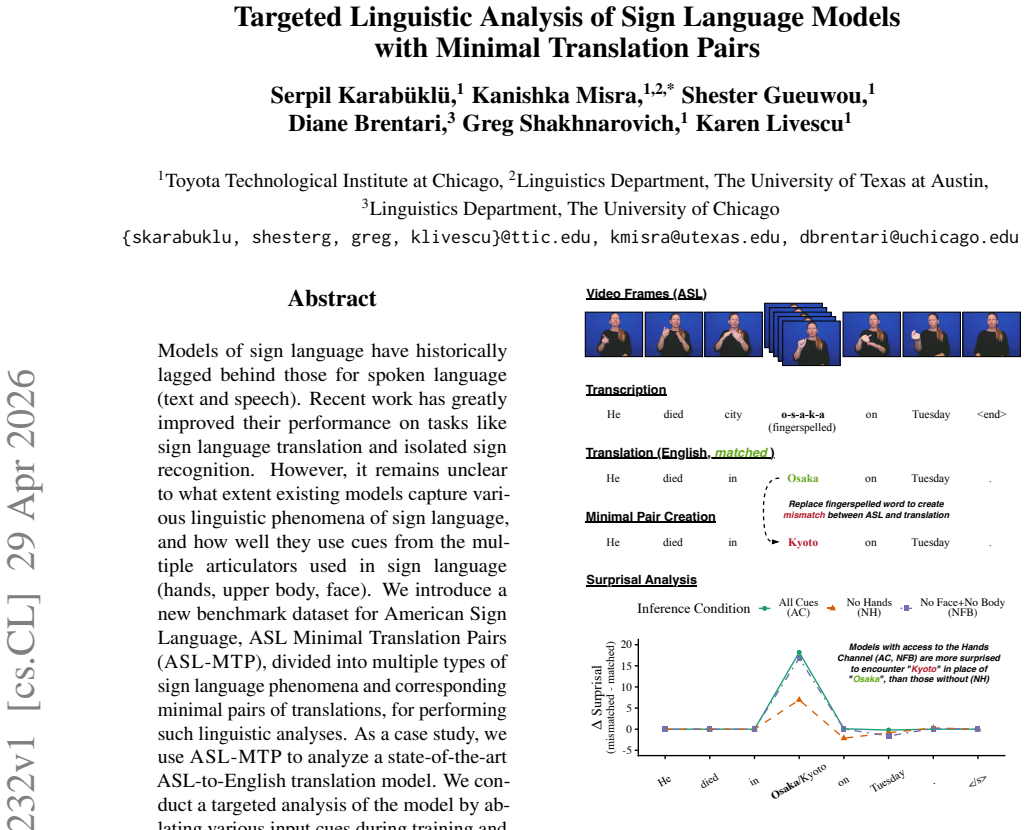
Models of sign language have historically lagged behind those for spoken language (text and speech). Recent work has greatly improved their performance on tasks like sign language translation and isolated sign recognition. However, it remains unclear to what extent existing models capture various linguistic phenomena of sign language, and how well they use cues from the multiple articulators used in sign language (hands, upper body, face). We introduce a new benchmark dataset for American Sign Language, ASL Minimal Translation Pairs (ASL-MTP), divided into multiple types of sign language phenomena and corresponding minimal pairs of translations, for performing such linguistic analyses. As a case study, we use ASL-MTP to analyze a state-of-the-art ASL-to-English translation model. We conduct a targeted analysis of the model by ablating various input cues during training and inference and evaluating on the phenomena in ASL-MTP. Our results show that, while the model performs above chance level on most of the phenomena, it relies strongly on manual cues while often missing crucial non-manual cues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ASL-MTP benchmark dataset of minimal translation pairs for American Sign Language, organized by linguistic phenomena, and applies it as a case study to analyze a state-of-the-art ASL-to-English translation model. The analysis proceeds by ablating manual and non-manual input cues during both training and inference, with the central claim being that the model exceeds chance performance on most phenomena yet relies strongly on manual cues while frequently missing non-manual cues.
Significance. If the results hold after methodological validation, the work would be significant for computational linguistics by supplying a controlled, phenomenon-specific benchmark that diagnoses how sign language models exploit (or fail to exploit) multi-articulator cues. The introduction of ASL-MTP enables targeted ablations beyond aggregate translation metrics and could guide development of models that better integrate non-manual features, addressing a recognized gap in sign language processing evaluation.
major comments (3)
- [4] Section 4 (experimental setup): Ablating cues during both training and inference confounds measurement of the original model's cue reliance. Training on ablated data alters the input distribution and learned representations, so unchanged performance after non-manual ablation may reflect adaptation to residual manual correlations rather than genuine non-use of those cues in the full-input model. This is load-bearing for the claim that the model 'relies strongly on manual cues while often missing crucial non-manual cues'.
- [3] Section 3 (dataset construction): The minimal translation pairs are assumed to isolate individual phenomena without channel interactions. Co-articulation in natural signing can introduce subtle manual differences when non-manual contrasts are present, allowing the model to exploit unintended cues. Without explicit controls or expert validation of channel independence, performance differences cannot be unambiguously attributed to manual versus non-manual reliance.
- [Abstract] Abstract and results: The manuscript asserts above-chance performance on most phenomena and differential cue reliance but supplies no quantitative results, statistical tests, error bars, dataset sizes, or ablation implementation details. This absence prevents assessment of whether the reported patterns are statistically robust or reproducible.
minor comments (2)
- [2] Section 2: The related work section would benefit from additional citations to prior linguistic analyses of sign language models and existing minimal-pair benchmarks in other modalities.
- [Figures/Tables] Figure and table captions: Additional detail on how ablation conditions are encoded and visualized would improve clarity for readers reproducing the experiments.
Simulated Author's Rebuttal
We thank the referee for their insightful comments on our manuscript introducing the ASL-MTP benchmark. We address each of the major comments point by point below, providing clarifications and indicating the revisions we will make to improve the paper's methodological transparency and robustness.
read point-by-point responses
-
Referee: Section 4 (experimental setup): Ablating cues during both training and inference confounds measurement of the original model's cue reliance. Training on ablated data alters the input distribution and learned representations, so unchanged performance after non-manual ablation may reflect adaptation to residual manual correlations rather than genuine non-use of those cues in the full-input model. This is load-bearing for the claim that the model 'relies strongly on manual cues while often missing crucial non-manual cues'.
Authors: We acknowledge the validity of this concern. Ablating during training changes the model's learned representations, which could lead to adaptation rather than revealing the original model's cue usage. Our training ablations were designed to test learnability of phenomena without certain cues, complementing the inference ablations on the full model. To directly address the confound for the reliance claim, we will add inference-only ablation experiments in the revised Section 4, where we evaluate the original full-input model with cues masked at test time only. This will provide a cleaner measure of cue reliance. We will also update the abstract and discussion to reflect these new results and clarify the purpose of each ablation type. revision: yes
-
Referee: Section 3 (dataset construction): The minimal translation pairs are assumed to isolate individual phenomena without channel interactions. Co-articulation in natural signing can introduce subtle manual differences when non-manual contrasts are present, allowing the model to exploit unintended cues. Without explicit controls or expert validation of channel independence, performance differences cannot be unambiguously attributed to manual versus non-manual reliance.
Authors: We agree that potential co-articulation effects represent a possible limitation in attributing performance differences solely to manual or non-manual cues. The ASL-MTP pairs were selected to isolate specific linguistic phenomena based on linguistic descriptions, with the contrast localized to the relevant articulators. To strengthen this, we will expand Section 3 with a description of the dataset construction process, including consultation with sign language experts to verify the isolation of features and minimize unintended manual variations. We will also report any checks performed for feature correlations and discuss this as a potential caveat in the limitations section. revision: yes
-
Referee: Abstract and results: The manuscript asserts above-chance performance on most phenomena and differential cue reliance but supplies no quantitative results, statistical tests, error bars, dataset sizes, or ablation implementation details. This absence prevents assessment of whether the reported patterns are statistically robust or reproducible.
Authors: We will update the abstract to include key quantitative findings, such as the specific performance metrics above chance level for the phenomena, the sizes of the minimal pair sets for each category, and summaries of the ablation results showing differential cue reliance. In the experimental results section, we will add statistical tests (e.g., binomial tests against chance), error bars from repeated evaluations or bootstrapping, dataset statistics, and precise details on ablation implementation (e.g., the method for removing manual or non-manual information from video inputs). These changes will enhance the reproducibility and allow readers to fully evaluate the robustness of our conclusions. revision: yes
Circularity Check
No significant circularity in empirical ablation analysis
full rationale
The paper introduces the ASL-MTP dataset and performs targeted ablation experiments on an external state-of-the-art ASL-to-English translation model, measuring performance differences across linguistic phenomena under manual and non-manual cue ablations. No derivation chain, equations, or first-principles predictions exist that reduce to the paper's own inputs by construction. The central claims rest on direct experimental measurements rather than self-definitional equivalences, fitted parameters renamed as predictions, or load-bearing self-citations. The analysis is self-contained and externally falsifiable via the reported ablation results on the new benchmark.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Minimal translation pairs can isolate specific linguistic phenomena in sign language without significant confounding from other channels
- domain assumption Ablating input channels during training and inference produces a valid measure of cue reliance in the model
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.