VARS-FL: Validation-Aligned Client Selection for Non-IID Federated Learning in IoT Systems
Pith reviewed 2026-05-08 15:37 UTC · model grok-4.3
The pith
Client selection scored by server validation loss reduction speeds convergence in non-IID IoT federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
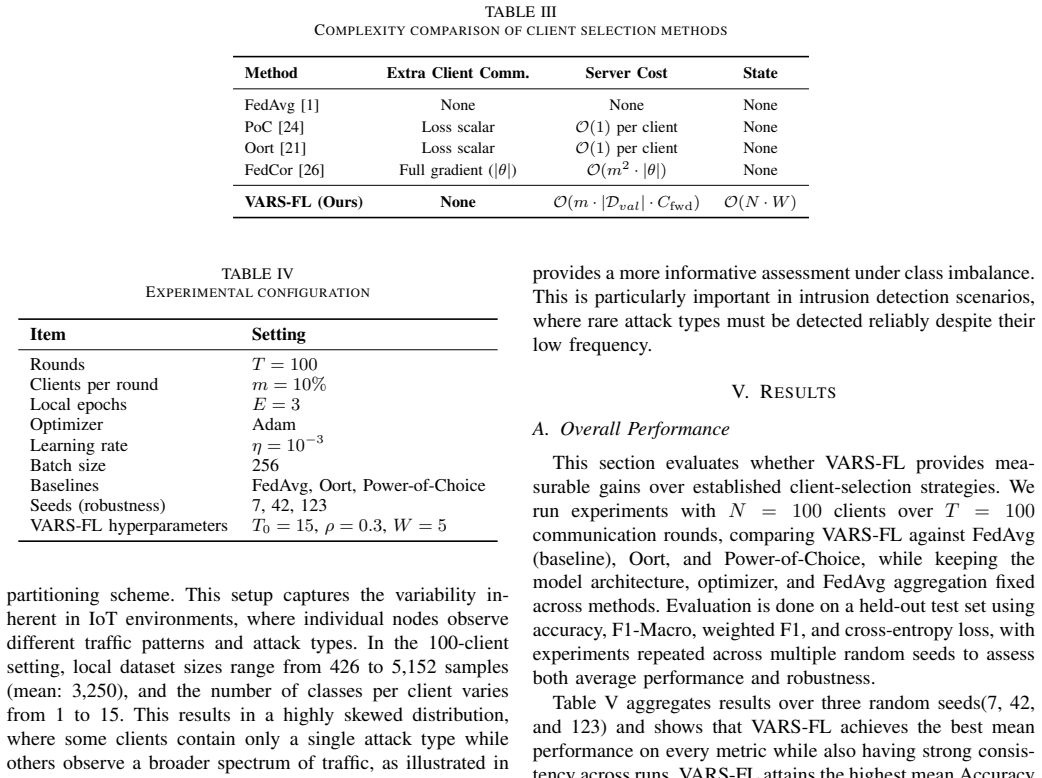
VARS-FL quantifies each client's contribution by the reduction in server-side validation loss after its update is applied, aggregates these signals into a reputation score via a sliding-window average plus a logarithmically scaled participation term, and selects clients for each round according to that reputation. The method requires no modification to local training or to FedAvg aggregation. On a 15-class non-IID intrusion detection task drawn from the Edge-IIoTset dataset with 100 clients, it improves final accuracy and F1-Macro, reduces loss, and reaches 80 percent accuracy in up to 36 percent fewer rounds than FedAvg, Oort, or Power-of-Choice across multiple random seeds.
What carries the argument
Validation-aligned reputation scoring, which converts the per-round drop in server validation loss into a history-aware client ranking for selection decisions.
If this is right
- Target accuracy is reached with up to 36 percent fewer communication rounds.
- Final accuracy and F1-Macro scores rise compared with random selection and two published alternatives.
- Training stability improves under the heterogeneous data patterns found across IoT devices.
- No changes to client-side optimization or central aggregation are required.
- Gains appear consistently across repeated trials with different random seeds.
Where Pith is reading between the lines
- The same validation-reduction signal could be tested in other non-IID domains where a central validation set is feasible, such as cross-hospital medical imaging.
- Fewer total rounds would lower cumulative communication and energy costs for battery-powered IoT fleets.
- If the server validation set drifts over time, a lightweight refresh schedule might be needed to keep the reputation scores aligned.
- Combining the reputation term with an explicit measure of client data diversity could handle more extreme distribution shifts.
Load-bearing premise
That the reduction in server validation loss caused by a client's update is a reliable and unbiased indicator of its value to the global model, and that the validation set stays representative even though client data distributions differ.
What would settle it
Running the identical 100-client non-IID Edge-IIoTset experiment and finding no measurable gains in accuracy, F1-Macro, or rounds needed to reach 80 percent accuracy for VARS-FL versus the baselines would falsify the performance claims.
Figures








read the original abstract
Federated learning (FL) systems typically employ stateless client selection, treating each communication round independently and ignoring accumulated evidence of client contribution quality. Under non-IID data, this leads to slow convergence and unstable training, particularly when selection relies on local proxies (e.g., training loss) that are misaligned with the global optimization objective. These challenges are especially pronounced in Internet of Things (IoT) and Industrial IoT (IIoT) environments, where data is highly heterogeneous and distributed across devices observing different traffic patterns. In this paper, we propose VARS-FL (Validation-Aligned Reputation Scoring for Federated Learning), a client selection framework that quantifies each client's contribution using the reduction in server-side validation loss induced by its update. These per-round signals are aggregated into a Reputation score that combines a sliding-window average of recent contributions with a logarithmically scaled participation term, enabling robust exploration-exploitation selection. VARS-FL requires no changes to local training or aggregation and remains fully compatible with standard FedAvg. We evaluate VARS-FL on a 15-class non-IID IoT intrusion detection task using the Edge-IIoTset dataset, with 100 clients across multiple seeds, and compare it against FedAvg, Oort, and Power-of-Choice. VARS-FL consistently improves accuracy, F1-Macro, and loss, while accelerating convergence (up to 36% fewer rounds to reach 80% accuracy). These results demonstrate that validation-aligned, history-aware client selection provides a more reliable and efficient training process for federated learning in heterogeneous IoT environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes VARS-FL, a client selection strategy for federated learning in non-IID IoT settings. It computes a reputation score for each client based on the reduction in server-side validation loss caused by incorporating the client's update, combined with a sliding-window average and a logarithmically scaled participation count. This score is used to select clients each round in a manner compatible with FedAvg. The method is evaluated on the Edge-IIoTset dataset for 15-class intrusion detection with 100 clients under non-IID partitioning, showing improvements in accuracy, F1-Macro, and convergence speed (up to 36% fewer rounds) over FedAvg, Oort, and Power-of-Choice across multiple seeds.
Significance. Should the validation-aligned reputation mechanism prove robust, the work offers a practical enhancement to client selection in heterogeneous federated learning without requiring changes to local training procedures. The history-aware aspect addresses limitations of stateless selection, and the empirical gains on a realistic IoT intrusion detection task suggest potential applicability in resource-constrained environments. The use of multiple seeds and standard metrics strengthens the empirical case.
major comments (3)
- Abstract and §4 (Evaluation): The server-side validation set used to compute loss reductions is never described—its size, construction (e.g., how the 15 classes are sampled), class balance, or refresh policy across rounds are omitted. This detail is load-bearing for the central claim, because the reputation score and subsequent selection rule rest on the assumption that validation-loss reduction is an unbiased proxy for contribution to the global objective under 15-class non-IID partitions; without it, the reported gains cannot be verified as robust to underrepresented traffic patterns or devices.
- §3 (Reputation Score Definition): The reputation score depends on two free parameters (sliding-window size and the logarithmic scaling coefficient for participation count) whose specific values and sensitivity are not reported or ablated. Because the selection rule is defined directly in terms of these parameters, the 36% convergence improvement and accuracy/F1 gains may be artifacts of particular tuning rather than a general property of validation-aligned scoring.
- §4 (Experiments): No statistical testing (confidence intervals, p-values, or variance across the multiple seeds) is provided for the accuracy, F1-Macro, or round-to-80%-accuracy metrics, nor is there analysis of robustness to alternative non-IID partitionings. This weakens the claim that VARS-FL “consistently improves” performance relative to the three baselines.
minor comments (2)
- §2 (Related Work): The positioning against Oort and Power-of-Choice is clear, but the manuscript would benefit from explicit comparison to other recent validation- or loss-based client selection methods that also avoid local proxies.
- Notation throughout: The equations for the per-round loss reduction and the aggregated reputation score should be numbered and presented formally rather than described only in prose, to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements for clarity, reproducibility, and statistical rigor.
read point-by-point responses
-
Referee: Abstract and §4 (Evaluation): The server-side validation set used to compute loss reductions is never described—its size, construction (e.g., how the 15 classes are sampled), class balance, or refresh policy across rounds are omitted. This detail is load-bearing for the central claim, because the reputation score and subsequent selection rule rest on the assumption that validation-loss reduction is an unbiased proxy for contribution to the global objective under 15-class non-IID partitions; without it, the reported gains cannot be verified as robust to underrepresented traffic patterns or devices.
Authors: We agree that explicit details on the server-side validation set are necessary to support the claims and enable verification. In the revised manuscript, we will expand Section 4 to describe the validation set as a fixed, held-out subset comprising approximately 15% of the Edge-IIoTset data, constructed via stratified sampling to ensure representation of all 15 classes with reported class balance statistics, and not refreshed across rounds to maintain consistent signals for the reputation mechanism. revision: yes
-
Referee: §3 (Reputation Score Definition): The reputation score depends on two free parameters (sliding-window size and the logarithmic scaling coefficient for participation count) whose specific values and sensitivity are not reported or ablated. Because the selection rule is defined directly in terms of these parameters, the 36% convergence improvement and accuracy/F1 gains may be artifacts of particular tuning rather than a general property of validation-aligned scoring.
Authors: We acknowledge that the specific hyperparameter values and their sensitivity were not sufficiently documented. The revised paper will explicitly report the sliding-window size (W=5) and logarithmic scaling coefficient used in experiments. We will also add an ablation study (in the main text or appendix) varying these parameters over reasonable ranges and demonstrating that the reported gains in convergence speed and accuracy remain consistent, addressing concerns about tuning artifacts. revision: yes
-
Referee: §4 (Experiments): No statistical testing (confidence intervals, p-values, or variance across the multiple seeds) is provided for the accuracy, F1-Macro, or round-to-80%-accuracy metrics, nor is there analysis of robustness to alternative non-IID partitionings. This weakens the claim that VARS-FL “consistently improves” performance relative to the three baselines.
Authors: We agree that adding statistical details would strengthen the empirical claims. The revision will include standard deviations and confidence intervals for accuracy, F1-Macro, and convergence metrics across the reported seeds. For robustness to alternative non-IID partitionings, we will add a short analysis using at least one additional partitioning strategy (e.g., varying Dirichlet alpha) in the appendix, while noting that the primary Edge-IIoTset setup is representative of the target IoT scenario; full exhaustive testing may be limited by space but the added results will support the consistency argument. revision: partial
Circularity Check
VARS-FL reputation scoring is an explicit heuristic with no reduction to inputs by construction
full rationale
The paper defines client reputation directly from per-round reductions in server-side validation loss (aggregated via sliding-window average plus log participation) and uses this for selection. This construction is not fitted to the final accuracy or F1 target; the performance gains are asserted via empirical comparison on Edge-IIoTset rather than derived from any self-referential equation. No load-bearing step equates a claimed prediction to its own inputs, no uniqueness theorem is invoked, and no self-citation chain supports the core mechanism. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (2)
- sliding-window size
- logarithmic scaling coefficient for participation
axioms (2)
- domain assumption Server maintains a representative validation set whose loss reduction accurately reflects client contribution to the global model.
- domain assumption VARS-FL requires no changes to local training or the FedAvg aggregation step.
invented entities (1)
-
Reputation score
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), 2017, pp. 1273–1282
work page 2017
-
[2]
Advances and open problems in federated learning,
P. Kairouz, H. B. McMahan, B. Avent, A. Bellet, M. Bennis, A. N. Bhagoji, K. Bonawitz, Z. Charles, G. Cormode, R. Cummingset al., “Advances and open problems in federated learning,”Foundations and Trends in Machine Learning, vol. 14, no. 1–2, pp. 1–210, 2021
work page 2021
-
[3]
M. A. Ferrag, O. Friha, D. Hamouda, L. Maglaras, and H. Janicke, “Edge-iiotset: A new comprehensive realistic cyber security dataset of iot and iiot applications for centralized and federated learning,”IEEE Access, vol. 10, pp. 40 281–40 306, 2022
work page 2022
-
[4]
Decentralized federated learning with non-iid data: Challenges, trends, and future opportunities,
W.-C. Chung, C.-A. Lo, Y .-H. Lin, Z.-H. Chen, and C.-L. Hung, “Decentralized federated learning with non-iid data: Challenges, trends, and future opportunities,”ACM Computing Surveys, vol. 58, no. 8, pp. 1–41, 2026
work page 2026
-
[5]
D. Hamouda, M. A. Ferrag, N. Benhamida, and H. Seridi, “Ppss: A privacy-preserving secure framework using blockchain-enabled feder- ated deep learning for industrial iots,”Pervasive and Mobile Computing, vol. 88, p. 101738, 2023
work page 2023
-
[6]
D. Hamouda, M. A. Ferrag, N. Benhamida, H. Seridi, and M. C. Ghanem, “Revolutionizing intrusion detection in industrial iot with distributed learning and deep generative techniques,”Internet of Things, vol. 26, p. 101149, 2024
work page 2024
-
[7]
Federated learning: Strategies for improving communication efficiency,
J. Kone ˇcný, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh, and D. Bacon, “Federated learning: Strategies for improving communication efficiency,” inNIPS Workshop on Private Multi-Party Machine Learning, 2016
work page 2016
-
[8]
Practical secure aggregation for privacy-preserving machine learning,
K. Bonawitz, V . Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” inProceedings of the ACM SIGSAC Conference on Computer and Communications Security (CCS), 2017
work page 2017
-
[9]
QSGD: Communication-efficient SGD via gradient quantization and encoding,
D. Alistarh, J. Grubic, J. Li, R. Tomioka, and M. V ojnovic, “QSGD: Communication-efficient SGD via gradient quantization and encoding,” inAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[10]
Sparse communication for distributed gra- dient descent,
A. F. Aji and K. Heafield, “Sparse communication for distributed gra- dient descent,” inProceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2017
work page 2017
-
[11]
Client selection for federated learning with heterogeneous resources in mobile edge,
T. Nishio and R. Yonetani, “Client selection for federated learning with heterogeneous resources in mobile edge,” inProceedings of the IEEE International Conference on Communications (ICC), 2019, pp. 1–7
work page 2019
-
[12]
Joint device scheduling and resource allocation for latency constrained federated learning,
W. Shi, S. Zhou, Z. Niu, M. Jiang, and L. Geng, “Joint device scheduling and resource allocation for latency constrained federated learning,”IEEE Transactions on Wireless Communications, vol. 20, no. 1, pp. 453–467, 2021
work page 2021
-
[13]
Federated learning for cyber physical systems: a comprehensive survey,
M. K. Quan, P. N. Pathirana, M. Wijayasundara, S. Setunge, D. C. Nguyen, C. G. Brinton, D. J. Love, and H. V . Poor, “Federated learning for cyber physical systems: a comprehensive survey,”IEEE Communications Surveys & Tutorials, 2025
work page 2025
-
[14]
Federated learning for computationally constrained heterogeneous devices: A survey,
K. Pfeiffer, M. Rapp, R. Khalili, and J. Henkel, “Federated learning for computationally constrained heterogeneous devices: A survey,”ACM Computing Surveys, vol. 55, no. 14s, pp. 1–27, 2023
work page 2023
-
[15]
M. P. Uddin, Y . Xiang, M. Hasan, J. Bai, Y . Zhao, and L. Gao, “A systematic literature review of robust federated learning: Issues, solutions, and future research directions,”ACM Computing Surveys, vol. 57, no. 10, pp. 1–62, 2025
work page 2025
-
[16]
Client selection in federated learning: Principles, challenges, and opportunities,
L. Fu, H. Zhang, G. Gao, M. Zhang, and X. Liu, “Client selection in federated learning: Principles, challenges, and opportunities,”IEEE Internet of Things Journal, vol. 10, no. 24, pp. 21 811–21 819, 2023
work page 2023
-
[17]
Green federated learning: A new era of green aware ai,
D. Thakur, A. Guzzo, G. Fortino, and F. Piccialli, “Green federated learning: A new era of green aware ai,”ACM Computing Surveys, vol. 57, no. 8, pp. 1–36, 2025
work page 2025
-
[18]
Bias in federated learning: A compre- hensive survey,
N. Benarba and S. Bouchenak, “Bias in federated learning: A compre- hensive survey,”ACM Computing Surveys, vol. 57, no. 11, pp. 1–36, 2025
work page 2025
-
[19]
Heterogeneous feder- ated learning: State-of-the-art and research challenges,
M. Ye, X. Fang, B. Du, P. C. Yuen, and D. Tao, “Heterogeneous feder- ated learning: State-of-the-art and research challenges,”ACM Computing Surveys, vol. 56, no. 3, pp. 1–44, 2023
work page 2023
-
[20]
Communication and computation efficiency in federated learning: A survey,
O. R. A. Almanifi, C.-O. Chow, M.-L. Tham, J. H. Chuah, and J. Kanesan, “Communication and computation efficiency in federated learning: A survey,”Internet of Things, vol. 22, p. 100742, 2023
work page 2023
-
[21]
Oort: Efficient federated learning via guided participant selection,
F. Lai, X. Zhu, H. V . Madhyastha, and M. Chowdhury, “Oort: Efficient federated learning via guided participant selection,” inProceedings of the 15th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2021, pp. 19–35
work page 2021
-
[22]
E. T. M. Beltrán, M. Q. Pérez, P. M. S. Sánchez, S. L. Bernal, G. Bovet, M. G. Pérez, G. M. Pérez, and A. H. Celdrán, “Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges,”IEEE Communications Surveys & Tutorials, vol. 25, no. 4, pp. 2983–3013, 2023
work page 2023
-
[23]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProceedings of Machine Learning and Systems (MLSys), 2020
work page 2020
-
[24]
Towards understanding biased client selection in federated learning,
Y . Jee Cho, J. Wang, and G. Joshi, “Towards understanding biased client selection in federated learning,” inProceedings of The 25th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, vol. 151. PMLR, 2022, pp. 10 351–10 375
work page 2022
-
[25]
J. Goetz, K. Malik, D. Bui, S. Moon, H. Liu, and A. Kumar, “Active federated learning,”arXiv preprint arXiv:1909.12641, 2019
-
[26]
Fed- Cor: Correlation-based active client selection strategy for heterogeneous federated learning,
M. Tang, X. Ning, Y . Wang, J. Sun, Y . Wang, H. Li, and C. Yao, “Fed- Cor: Correlation-based active client selection strategy for heterogeneous federated learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10 102– 10 111
work page 2022
-
[27]
FLTrust: Byzantine- robust federated learning via trust bootstrapping,
X. Cao, M. Fang, J. Liu, and N. Z. Gong, “FLTrust: Byzantine- robust federated learning via trust bootstrapping,” inProceedings of the Network and Distributed System Security Symposium (NDSS), 2021
work page 2021
-
[28]
On the convergence of FedAvg on non-IID data,
X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of FedAvg on non-IID data,” inInternational Conference on Learning Representations (ICLR), 2020
work page 2020
-
[29]
SCAFFOLD: Stochastic controlled averaging for federated learning,
S. P. Karimireddy, S. Kale, M. Mohri, S. J. Reddi, S. Stich, and A. T. Suresh, “SCAFFOLD: Stochastic controlled averaging for federated learning,” inProceedings of the International Conference on Machine Learning (ICML), 2020, pp. 5132–5143
work page 2020
-
[30]
Model-contrastive federated learning,
Q. Li, B. He, and D. Song, “Model-contrastive federated learning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 10 713–10 722
work page 2021
-
[31]
FedScale: Benchmarking model and system perfor- mance of federated learning at scale,
F. Lai, Y . Dai, S. Singapuram, J. Liu, X. Zhu, H. V . Madhyastha, and M. Chowdhury, “FedScale: Benchmarking model and system perfor- mance of federated learning at scale,” inProceedings of the International Conference on Machine Learning (ICML), 2022, pp. 11 814–11 827
work page 2022
-
[32]
Machine learning with adversaries: Byzantine tolerant gradient descent,
P. Blanchard, E. M. El Mhamdi, R. Guerraoui, and J. Stainer, “Machine learning with adversaries: Byzantine tolerant gradient descent,” inAd- vances in Neural Information Processing Systems (NeurIPS), 2017, pp. 119–129
work page 2017
-
[33]
The hidden vul- nerability of distributed learning in Byzantium,
E. M. El Mhamdi, R. Guerraoui, and S. Rouault, “The hidden vul- nerability of distributed learning in Byzantium,” inProceedings of the International Conference on Machine Learning (ICML), 2018, pp. 3521– 3530
work page 2018
-
[34]
Exploiting shared representations for personalized federated learning,
L. Collins, H. Hassani, A. Mokhtari, and S. Shakkottai, “Exploiting shared representations for personalized federated learning,” inProceed- ings of the International Conference on Machine Learning (ICML), 2021, pp. 2089–2099
work page 2021
-
[35]
Personalized federated learning with Moreau envelopes,
C. T. Dinh, N. H. Tran, and T. D. Nguyen, “Personalized federated learning with Moreau envelopes,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020, pp. 21 394–21 405
work page 2020
-
[36]
On upper-confidence bound policies for switching bandit problems,
A. Garivier and É. Moulines, “On upper-confidence bound policies for switching bandit problems,” inProceedings of the International Conference on Algorithmic Learning Theory (ALT), 2011, pp. 174–188
work page 2011
-
[37]
A tutorial on Thompson sampling,
D. J. Russo, B. Van Roy, A. Kazerouni, I. Osband, and Z. Wen, “A tutorial on Thompson sampling,”Foundations and Trends in Machine Learning, vol. 11, no. 1, pp. 1–96, 2018
work page 2018
-
[38]
A survey on security and privacy of federated learning,
V . Mothukuri, R. M. Parizi, S. Pouriyeh, Y . Huang, A. Dehghantanha, and G. Srivastava, “A survey on security and privacy of federated learning,”Future Generation Computer Systems, vol. 115, pp. 619–640, 2021
work page 2021
-
[39]
DÏoT: A federated self-learning anomaly detec- tion system for iot,
T. D. Nguyen, S. Marchal, M. Miettinen, H. Fereidooni, N. Asokan, and A.-R. Sadeghi, “DÏoT: A federated self-learning anomaly detec- tion system for iot,” inIEEE International Conference on Distributed Computing Systems (ICDCS), 2019
work page 2019
-
[40]
Federated learning for malware detection in IoT devices,
V . Rey, P. M. Sanchez Sanchez, A. H. Celdrán, and G. Bovet, “Federated learning for malware detection in IoT devices,”Computer Networks, vol. 204, p. 108693, 2022
work page 2022
-
[41]
Internet of things intrusion detection: Centralized, on-device, or feder- ated learning?
S. T. Rahman, A. Mansoor, M. Shamim Hossain, and M. M. Rahman, “Internet of things intrusion detection: Centralized, on-device, or feder- ated learning?”IEEE Network, vol. 34, no. 6, pp. 310–317, 2020
work page 2020
-
[42]
Toward generating a new intrusion detection dataset and intrusion traffic characterization,
I. Sharafaldin, A. H. Lashkari, and A. A. Ghorbani, “Toward generating a new intrusion detection dataset and intrusion traffic characterization,” in Proceedings of the 4th International Conference on Information Systems Security and Privacy (ICISSP), 2018, pp. 108–116
work page 2018
-
[43]
N. Moustafa, “A new distributed architecture for evaluating AI-based security systems at the edge: Network TON_IoT datasets,”Sustainable Cities and Society, vol. 72, p. 102994, 2021
work page 2021
-
[44]
N-BaIoT: Network-based detection of IoT botnet attacks using deep autoencoders,
Y . Meidan, M. Bohadana, Y . Mathov, Y . Mirsky, A. Shabtai, D. Bre- itenbacher, and Y . Elovici, “N-BaIoT: Network-based detection of IoT botnet attacks using deep autoencoders,”IEEE Pervasive Computing, vol. 17, no. 3, pp. 12–22, 2018
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.