PRISM: Iterative Cross-Modal Posterior Refinement for Dynamic Text-Attributed Graphs
Pith reviewed 2026-05-08 13:55 UTC · model grok-4.3
The pith
PRISM refines semantic priors into behavior-conditioned posteriors through iterative cross-modal updates in dynamic text-attributed graphs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
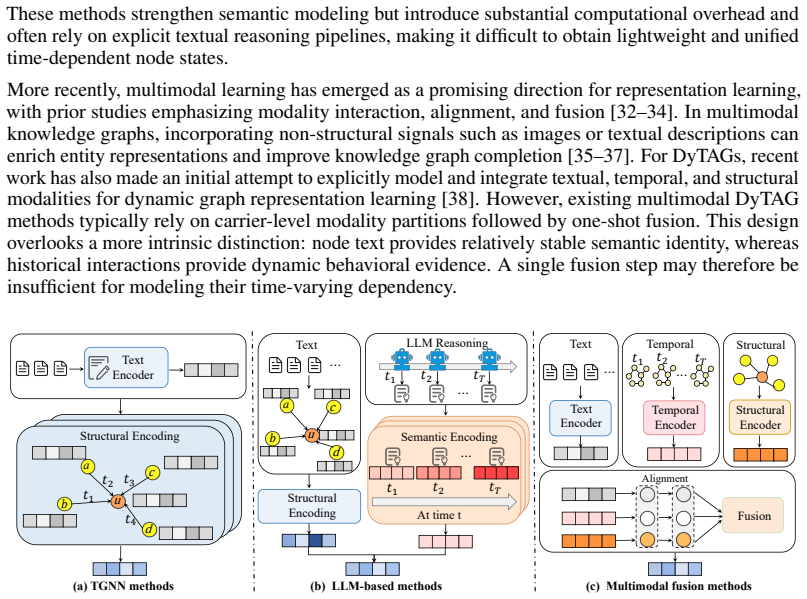
PRISM organizes DyTAG information into semantic and behavioral modalities, providing a more intrinsic alternative to carrier-level modality partitions. Instead of fusing the two modalities in a single step, PRISM learns a refinement trajectory that progressively transforms semantic priors into behavior-conditioned posterior states through cross-modal interaction with behavioral evidence. Extensive experiments on DTGB benchmark datasets show that PRISM achieves strong performance on temporal link prediction and destination node retrieval tasks.
What carries the argument
The iterative cross-modal posterior refinement trajectory that progressively converts semantic priors into behavior-conditioned posterior states.
If this is right
- The semantic-behavioral partition supplies a more natural organization of DyTAG information than carrier-level splits.
- Iterative refinement produces stronger results on temporal link prediction than existing one-shot fusion approaches.
- The same trajectory improves destination node retrieval accuracy on the DTGB benchmarks.
- Ablation results confirm that both the modality split and the iterative steps contribute to the observed gains.
Where Pith is reading between the lines
- The same progressive refinement pattern could be tested on other dynamic multimodal settings, such as time-stamped documents with user interaction logs.
- If the trajectory proves stable, it might simplify architecture design by replacing elaborate single-pass fusion layers in graph models.
- Real-time deployment in recommendation or social systems could benefit from stopping the refinement early when behavioral evidence is still sparse.
Load-bearing premise
That splitting DyTAG data into semantic and behavioral modalities is inherently better than other partitions and that performing the combination iteratively captures evolving dependencies more effectively than one-shot fusion.
What would settle it
A one-shot fusion baseline using the same semantic-behavioral split that matches or exceeds PRISM on the DTGB temporal link prediction benchmark would undermine the value of the iterative refinement process.
Figures



read the original abstract
Dynamic text-attributed graphs (DyTAGs) provide a powerful framework for modeling evolving systems in which node semantics and time-dependent interactions are tightly coupled. Recently, multimodal learning has emerged as a promising yet underexplored direction for enhancing DyTAG representation learning. However, existing methods typically rely on rigid modality partitions and one-shot fusion strategies, which limit their ability to capture the intrinsic and evolving dependencies between node semantics and interaction behaviors. To address these limitations, we propose \textbf{PRISM}, an iterative cross-modal posterior refinement framework for DyTAG representation learning. PRISM organizes DyTAG information into semantic and behavioral modalities, providing a more intrinsic alternative to carrier-level modality partitions. Instead of fusing the two modalities in a single step, PRISM learns a refinement trajectory that progressively transforms semantic priors into behavior-conditioned posterior states through cross-modal interaction with behavioral evidence. Extensive experiments on DTGB benchmark datasets show that PRISM achieves strong performance on temporal link prediction and destination node retrieval tasks. Further ablation studies validate the effectiveness of semantic--behavioral modeling and iterative posterior refinement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PRISM, an iterative cross-modal posterior refinement framework for dynamic text-attributed graphs (DyTAGs). It organizes information into semantic and behavioral modalities as an alternative to carrier-level partitions and learns a refinement trajectory that progressively transforms semantic priors into behavior-conditioned posterior states through cross-modal interaction with behavioral evidence. The approach is evaluated on temporal link prediction and destination node retrieval tasks using DTGB benchmarks, where it reports strong performance, with ablation studies validating the semantic-behavioral modeling and iterative refinement choices.
Significance. If the empirical results and ablations hold under rigorous controls, PRISM could meaningfully advance multimodal representation learning for DyTAGs by replacing one-shot fusion with an iterative trajectory that better models evolving semantic-behavioral dependencies. The explicit validation of modeling choices via ablations is a strength that supports falsifiability of the core design decisions.
major comments (2)
- Abstract: the claim of 'strong performance' on temporal link prediction and destination node retrieval is not accompanied by any quantitative metrics, baseline names, or error bars, preventing assessment of whether the gains are practically meaningful or statistically reliable.
- Modeling section (motivation for modality partition): the assertion that semantic-behavioral partitioning is intrinsically superior to carrier-level partitions is central to the framework but lacks a direct head-to-head ablation or theoretical argument showing why carrier-level splits fail to capture the same dependencies; the existing ablations only validate the chosen split internally.
minor comments (2)
- Abstract: consider adding one or two key performance deltas (e.g., relative improvement over strongest baseline) to make the empirical contribution immediately visible.
- Experiments section: confirm that all reported results include standard deviations across runs and a complete list of baselines with implementation references for reproducibility.
Simulated Author's Rebuttal
Thank you for the detailed review and constructive feedback on our manuscript. We have carefully considered each major comment and provide point-by-point responses below. We plan to incorporate revisions to address the concerns raised.
read point-by-point responses
-
Referee: Abstract: the claim of 'strong performance' on temporal link prediction and destination node retrieval is not accompanied by any quantitative metrics, baseline names, or error bars, preventing assessment of whether the gains are practically meaningful or statistically reliable.
Authors: We agree with this observation. The current abstract uses qualitative language without supporting numbers. In the revised manuscript, we will update the abstract to include specific quantitative results, such as the AUC scores or MRR values achieved by PRISM compared to key baselines (e.g., TGN, DyGFormer), along with standard deviations from multiple runs to indicate reliability. This will allow readers to better evaluate the practical significance of the improvements. revision: yes
-
Referee: Modeling section (motivation for modality partition): the assertion that semantic-behavioral partitioning is intrinsically superior to carrier-level partitions is central to the framework but lacks a direct head-to-head ablation or theoretical argument showing why carrier-level splits fail to capture the same dependencies; the existing ablations only validate the chosen split internally.
Authors: This is a valid point regarding the strength of our motivation. Our existing ablations demonstrate the benefits of the semantic-behavioral split within our framework, but we recognize the need for a direct comparison. We will revise the modeling section to include a more detailed theoretical argument based on the evolving nature of DyTAGs, where semantic priors and behavioral evidence interact iteratively rather than being partitioned by data carrier. Additionally, we will add a head-to-head ablation experiment comparing semantic-behavioral partitioning to carrier-level partitions (e.g., text attributes vs. structural edges) across the DTGB benchmarks, reporting performance differences to substantiate our claims. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description present PRISM as a novel iterative cross-modal framework for DyTAGs, with the semantic-behavioral modality split and posterior refinement trajectory introduced as design choices rather than derived quantities. No equations, parameter fits, or self-citation chains are shown that reduce the claimed performance gains on temporal link prediction or node retrieval to inputs by construction. Ablation studies are invoked to validate the choices empirically, keeping the central proposal self-contained against external benchmarks. This matches the default expectation for non-circular framework papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Semantic and behavioral modalities provide a more intrinsic partition of DyTAG information than carrier-level modality partitions
- ad hoc to paper A refinement trajectory can progressively transform semantic priors into behavior-conditioned posterior states through cross-modal interaction
Reference graph
Works this paper leans on
-
[1]
Representation learning for dynamic graphs: A survey.Journal of Machine Learning Research, 21(70):1–73, 2020
Seyed Mehran Kazemi, Rishab Goel, Kshitij Jain, Ivan Kobyzev, Akshay Sethi, Peter Forsyth, and Pascal Poupart. Representation learning for dynamic graphs: A survey.Journal of Machine Learning Research, 21(70):1–73, 2020
2020
-
[2]
Foundations and modeling of dynamic networks using dynamic graph neural networks: A survey.IEEE Access, 9:79143–79168, 2021
Joakim Skarding, Bogdan Gabrys, and Katarzyna Musial. Foundations and modeling of dynamic networks using dynamic graph neural networks: A survey.IEEE Access, 9:79143–79168, 2021
2021
-
[3]
A comprehensive survey of dynamic graph neural networks: Models, frameworks, benchmarks, experiments and challenges.IEEE Transactions on Knowledge and Data Engineering, 2025
ZhengZhao Feng, Rui Wang, TianXing Wang, Mingli Song, Sai Wu, and Shuibing He. A comprehensive survey of dynamic graph neural networks: Models, frameworks, benchmarks, experiments and challenges.IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[4]
Microscopic evolution of social networks
Jure Leskovec, Lars Backstrom, Ravi Kumar, and Andrew Tomkins. Microscopic evolution of social networks. InProceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 462–470, 2008
2008
-
[5]
TTERGM: Social theory- driven network simulation
Yifan Huang, Clayton Thomas Barham, Eric Page, and PK Douglas. TTERGM: Social theory- driven network simulation. InNeurIPS 2022 Temporal Graph Learning Workshop, 2022
2022
-
[6]
Aligning dynamic social networks: An optimization over dynamic graph autoencoder.IEEE Transactions on Knowledge and Data Engineering, 35(6):5597–5611, 2022
Li Sun, Zhongbao Zhang, Feiyang Wang, Pengxin Ji, Jian Wen, Sen Su, and Philip S Yu. Aligning dynamic social networks: An optimization over dynamic graph autoencoder.IEEE Transactions on Knowledge and Data Engineering, 35(6):5597–5611, 2022
2022
-
[7]
LightGCN: Simplifying and powering graph convolution network for recommendation
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. LightGCN: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 639–648, 2020
2020
-
[8]
Dynamic graph neural networks for sequential recommendation.IEEE Transactions on Knowledge and Data Engineering, 35 (5):4741–4753, 2022
Mengqi Zhang, Shu Wu, Xueli Yu, Qiang Liu, and Liang Wang. Dynamic graph neural networks for sequential recommendation.IEEE Transactions on Knowledge and Data Engineering, 35 (5):4741–4753, 2022
2022
-
[9]
Dynamic graph evolution learning for recommendation
Haoran Tang, Shiqing Wu, Guandong Xu, and Qing Li. Dynamic graph evolution learning for recommendation. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1589–1598, 2023
2023
-
[10]
Recurrent event network: Autoregressive structure inference over temporal knowledge graphs
Woojeong Jin, Meng Qu, Xisen Jin, and Xiang Ren. Recurrent event network: Autoregressive structure inference over temporal knowledge graphs. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 6669–6683, 2020
2020
-
[11]
Temporal knowledge graph reasoning based on evolutional representation learning
Zixuan Li, Xiaolong Jin, Wei Li, Saiping Guan, Jiafeng Guo, Huawei Shen, Yuanzhuo Wang, and Xueqi Cheng. Temporal knowledge graph reasoning based on evolutional representation learning. InProceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 408–417, 2021
2021
-
[12]
Temporal knowledge graph completion: A survey
Borui Cai, Yong Xiang, Longxiang Gao, He Zhang, Yunfeng Li, and Jianxin Li. Temporal knowledge graph completion: A survey. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, pages 6545–6553, 2023. 10
2023
-
[13]
DTGB: A comprehensive benchmark for dynamic text-attributed graphs
Jiasheng Zhang, Jialin Chen, Menglin Yang, Aosong Feng, Shuang Liang, Jie Shao, and Rex Ying. DTGB: A comprehensive benchmark for dynamic text-attributed graphs. InAdvances in Neural Information Processing Systems, volume 38, 2024
2024
-
[14]
GDGB: A benchmark for generative dynamic text-attributed graph learning
Jie Peng, Jiarui Ji, Runlin Lei, Zhewei Wei, Yongchao Liu, and Chuntao Hong. GDGB: A benchmark for generative dynamic text-attributed graph learning. InInternational Conference on Learning Representations, 2026
2026
-
[15]
Open graph benchmark: Datasets for machine learning on graphs
Weihua Hu, Matthias Fey, Marinka Zitnik, Yuxiao Dong, Hongyu Ren, Bowen Liu, Michele Catasta, and Jure Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020
2020
-
[16]
Xiaoxin He, Xavier Bresson, Thomas Laurent, Bryan Hooi, et al. Explanations as features: Llm-based features for text-attributed graphs.arXiv preprint arXiv:2305.19523, 2(4):8, 2023
-
[17]
A comprehensive study on text-attributed graphs: Benchmarking and rethinking.Advances in Neural Information Processing Systems, 36:17238– 17264, 2023
Hao Yan, Chaozhuo Li, Ruosong Long, Chao Yan, Jianan Zhao, Wenwen Zhuang, Jun Yin, Peiyan Zhang, Weihao Han, Hao Sun, et al. A comprehensive study on text-attributed graphs: Benchmarking and rethinking.Advances in Neural Information Processing Systems, 36:17238– 17264, 2023
2023
-
[18]
Nguyen, John Boaz Lee, Ryan A
Giang H. Nguyen, John Boaz Lee, Ryan A. Rossi, Nesreen K. Ahmed, Eunyee Koh, and Sungchul Kim. Continuous-time dynamic network embeddings. InCompanion Proceedings of the Web Conference 2018, pages 969–976, 2018
2018
-
[19]
Tempo- ral graph benchmark for machine learning on temporal graphs.Advances in Neural Information Processing Systems, 36:2056–2073, 2023
Shenyang Huang, Farimah Poursafaei, Jacob Danovitch, Matthias Fey, Weihua Hu, Emanuele Rossi, Jure Leskovec, Michael Bronstein, Guillaume Rabusseau, and Reihaneh Rabbany. Tempo- ral graph benchmark for machine learning on temporal graphs.Advances in Neural Information Processing Systems, 36:2056–2073, 2023
2056
-
[20]
TGB 2.0: A benchmark for learning on temporal knowledge graphs and heterogeneous graphs
Julia Gastinger, Shenyang Huang, Mikhail Galkin, Erfan Loghmani, Ali Parviz, Farimah Poursafaei, Jacob Danovitch, Emanuele Rossi, Ioannis Koutis, Heiner Stuckenschmidt, et al. TGB 2.0: A benchmark for learning on temporal knowledge graphs and heterogeneous graphs. Advances in neural information processing systems, 37:140199–140229, 2024
2024
-
[21]
Predicting dynamic embedding trajectory in temporal interaction networks
Srijan Kumar, Xikun Zhang, and Jure Leskovec. Predicting dynamic embedding trajectory in temporal interaction networks. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1269–1278, 2019
2019
-
[22]
DyRep: Learning representations over dynamic graphs
Rakshit Trivedi, Hanjun Dai, Yichen Wang, and Le Song. DyRep: Learning representations over dynamic graphs. InInternational Conference on Learning Representations, 2019
2019
-
[23]
Inductive repre- sentation learning on temporal graphs
Da Xu, Chuanwei Ruan, Evren Körpeoglu, Sushant Kumar, and Kannan Achan. Inductive repre- sentation learning on temporal graphs. InInternational Conference on Learning Representations, 2020
2020
-
[24]
Temporal Graph Networks for Deep Learning on Dynamic Graphs
Emanuele Rossi, Benjamin Paul Chamberlain, Fabrizio Frasca, Davide Eynard, Federico Monti, and Michael M. Bronstein. Temporal graph networks for deep learning on dynamic graphs. arXiv preprint arXiv:2006.10637, 2020
work page internal anchor Pith review arXiv 2006
-
[25]
Inductive representation learning in temporal networks via causal anonymous walks
Yanbang Wang, Yen-Yu Chang, Yunyu Liu, Jure Leskovec, and Pan Li. Inductive representation learning in temporal networks via causal anonymous walks. InInternational Conference on Learning Representations, 2021
2021
-
[26]
arXiv preprint arXiv:2105.07944 , year=
Lu Wang, Xiaofu Chang, Shuang Li, Yunfei Chu, Hui Li, Wei Zhang, Xiaofeng He, Le Song, Jingren Zhou, and Hongxia Yang. TCL: Transformer-based dynamic graph modelling via contrastive learning.arXiv preprint arXiv:2105.07944, 2021
-
[27]
Do we really need complicated model architectures for temporal networks? InInternational Conference on Learning Representations, 2023
Weilin Cong, Si Zhang, Jian Kang, Baichuan Yuan, Hao Wu, Xin Zhou, Hanghang Tong, and Mehrdad Mahdavi. Do we really need complicated model architectures for temporal networks? InInternational Conference on Learning Representations, 2023
2023
-
[28]
Towards better dynamic graph learning: New architecture and unified library.Advances in Neural Information Processing Systems, 36: 67686–67700, 2023
Le Yu, Leilei Sun, Bowen Du, and Weifeng Lv. Towards better dynamic graph learning: New architecture and unified library.Advances in Neural Information Processing Systems, 36: 67686–67700, 2023. 11
2023
- [29]
-
[30]
Unifying text semantics and graph structures for temporal text-attributed graphs with large language models
Siwei Zhang, Yun Xiong, Yateng Tang, Jiarong Xu, Xi Chen, Zehao Gu, Xuezheng Hao, Zian Jia, and Jiawei Zhang. Unifying text semantics and graph structures for temporal text-attributed graphs with large language models. InProceedings of Neural Information Processing Systems, 2025
2025
-
[31]
Global-recent semantic reasoning on dynamic text-attributed graphs with large language models
Yunan Wang, Jianxin Li, and Ziwei Zhang. Global-recent semantic reasoning on dynamic text-attributed graphs with large language models. InInternational Conference on Learning Representations, 2026
2026
-
[32]
Multimodal machine learn- ing: A survey and taxonomy.IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(2):423–443, 2019
Tadas Baltrusaitis, Chaitanya Ahuja, and Louis-Philippe Morency. Multimodal machine learn- ing: A survey and taxonomy.IEEE Transactions on Pattern Analysis and Machine Intelligence, 41(2):423–443, 2019
2019
-
[33]
Tensor fusion network for multimodal sentiment analysis
Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Tensor fusion network for multimodal sentiment analysis. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 1103–1114, 2017
2017
-
[34]
Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov
Yao-Hung Hubert Tsai, Shaojie Bai, Paul Pu Liang, J. Zico Kolter, Louis-Philippe Morency, and Ruslan Salakhutdinov. Multimodal transformer for unaligned multimodal language sequences. InProceedings of the Annual Meeting of the Association for Computational Linguistics, 2019
2019
-
[35]
Image-embodied knowledge representation learning
Ruobing Xie, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. Image-embodied knowledge representation learning. InProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, pages 3140–3146, 2017
2017
-
[36]
Hybrid transformer with multi-level fusion for multimodal knowledge graph completion
Xiang Chen, Ningyu Zhang, Lei Li, Shumin Deng, Chuanqi Tan, Changliang Xu, Fei Huang, Luo Si, and Huajun Chen. Hybrid transformer with multi-level fusion for multimodal knowledge graph completion. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 904–915, 2022
2022
-
[37]
Multi-modal knowledge graph completion: A survey.ACM Transactions on Asian and Low-Resource Language Information Processing, 2024
Tongtong Liu. Multi-modal knowledge graph completion: A survey.ACM Transactions on Asian and Low-Resource Language Information Processing, 2024
2024
-
[38]
Unlocking multi-modal potentials for link prediction on dynamic text-attributed graphs
Yuanyuan Xu, Wenjie Zhang, Ying Zhang, Xuemin Lin, and Xiwei Xu. Unlocking multi-modal potentials for link prediction on dynamic text-attributed graphs. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 27386–27394, 2026
2026
-
[39]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[40]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Informa- tion Processing Systems, volume 30, 2017
2017
-
[41]
Multimodal generative models for scalable weakly-supervised learning
Mike Wu and Noah Goodman. Multimodal generative models for scalable weakly-supervised learning. InAdvances in Neural Information Processing Systems, volume 31, 2018
2018
-
[42]
Siddharth, Brooks Paige, and Philip H
Yuge Shi, N. Siddharth, Brooks Paige, and Philip H. S. Torr. Variational mixture-of-experts autoencoders for multi-modal deep generative models. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[43]
Sutter, Imant Daunhawer, and Julia E
Thomas M. Sutter, Imant Daunhawer, and Julia E. V ogt. Multimodal generative learning utilizing jensen-shannon-divergence. InAdvances in Neural Information Processing Systems, volume 33, pages 6100–6110, 2020
2020
-
[44]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems, volume 31, 2018. 12
2018
-
[45]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
2020
-
[46]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InInternational Conference on Learning Representations, 2023
2023
-
[47]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations, 2023
2023
-
[48]
Adam: A method for stochastic optimization.International Conference on Learning Representations, 2014
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.International Conference on Learning Representations, 2014. A Notations In this section, we summarize the important notations used in this paper, as detailed in Table 5. Table 5: Notations and descriptions. Notation Description GA dynamic text-attributed graph (DyTAG). VThe node se...
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.