CITYMPC: A Large-Scale Physics-Informed Benchmark and Tool for Generative Complete Multipath Wireless Channel Modeling
Pith reviewed 2026-05-19 14:30 UTC · model grok-4.3
The pith
CITYMPC generates complete multipath wireless channel parameters from point-of-view imagery and terrain height maps alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CITYMPC is a conditional variational autoencoder that predicts the complete per-path multipath component parameter set, including complex channel gain, propagation delay, azimuth and elevation angles of departure and arrival, directly from point-of-view imagery and terrain height maps, achieving received power mean absolute error of 1.29 dB and first-path delay mean absolute error of 7.25 ns against ray-tracing ground truth across 427,397 links in five urban environments without requiring explicit three-dimensional scene geometry at inference time.
What carries the argument
Conditional variational autoencoder conditioned on point-of-view imagery and terrain height maps to output the full multipath component parameter set.
If this is right
- Supports large-scale environment-aware channel generation for wireless network planning without running ray tracing on every new scene.
- Enables release of a multi-city ray-traced dataset as a public benchmark for future scene-conditioned models.
- Allows quantitative measurement of cross-city distribution shift to guide model robustness improvements.
- Provides a generative framework that can sample varied channel realizations consistent with a given visual and terrain input.
Where Pith is reading between the lines
- The method could be paired with publicly available mapping imagery to produce channel models for cities lacking detailed 3D reconstructions.
- Extension to sequences of images might support modeling of time-varying channels caused by moving vehicles or pedestrians.
- Similar conditioning on visual and elevation data could be tested in non-urban settings such as suburban or indoor environments to broaden applicability.
Load-bearing premise
That point-of-view imagery and terrain height maps alone contain enough information to accurately reconstruct the full set of multipath component parameters that would otherwise require explicit 3D scene geometry.
What would settle it
Compare CITYMPC predictions against real-world channel measurements collected in a sixth urban area never seen during training and check whether the received power and delay errors remain near 1.29 dB and 7.25 ns.
Figures



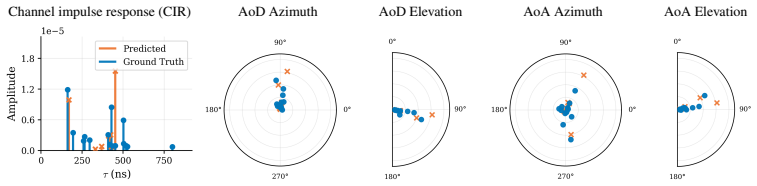

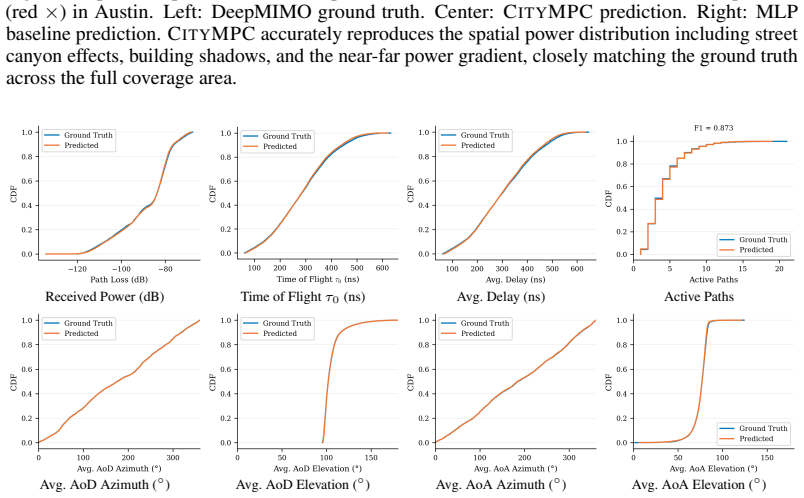



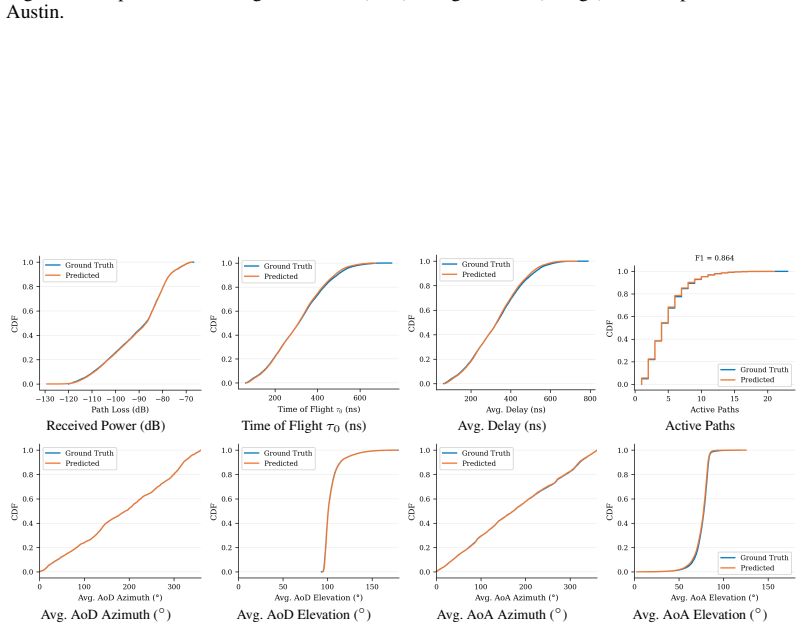
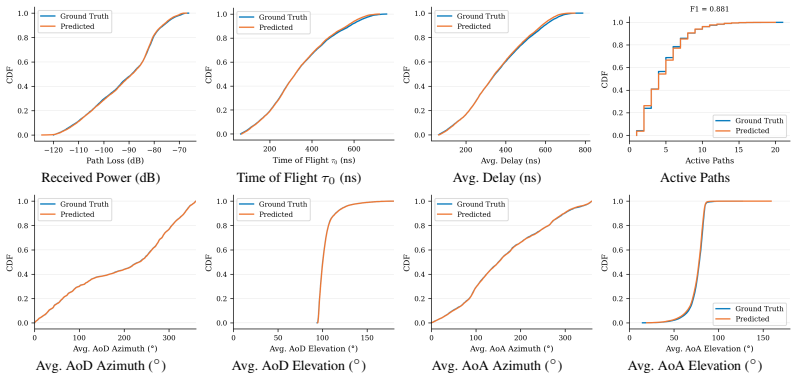


read the original abstract
Multipath wireless channels are fully characterized by multipath components (MPCs), including complex channel gain, propagation delay, angle of departure (AoD) and angle of arrival (AoA) in azimuth and elevation. Generating these parameters with the fidelity of ray tracing (RT) remains an open problem. Existing methods either incur the computational cost of RT or require explicit 3D scene geometry at inference. We present CITYMPC, a conditional variational autoencoder (cVAE) that predicts the complete per-path MPC parameter set from point-of-view imagery and terrain height maps alone, achieving environment-aware channel generation without access to any three-dimensional scene geometry at inference. Trained and evaluated across five urban environments spanning 427,397 links, CITYMPC matches RT ground truth to within 1.29 dB received power mean absolute error (MAE) and 7.25 ns $\tau_0$ MAE. CITYMPC is a generative channel modeling framework and reproducible benchmark, released together with a large-scale multi-city ray-traced dataset to accelerate future scene-conditioned channel modeling research. We further analyze cross-city distribution shift to characterize the per-city diversity of the benchmark.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CITYMPC, a conditional variational autoencoder (cVAE) that generates the full set of multipath component (MPC) parameters—including complex gain, delay, AoD, and AoA in azimuth and elevation—from point-of-view imagery and terrain height maps alone. It claims to match ray-tracing ground truth to within 1.29 dB received-power MAE and 7.25 ns delay MAE across 427,397 links in five urban environments, while releasing a large-scale multi-city ray-traced dataset and benchmark for scene-conditioned channel modeling. The work also includes cross-city distribution-shift analysis.
Significance. If the performance claims prove robust, the contribution would be significant: it offers a practical route to environment-aware generative channel modeling that avoids both the runtime cost of ray tracing and the need for explicit 3-D geometry at inference time. The scale of the released dataset and the explicit treatment of cross-city shift are concrete assets that could accelerate follow-on research in wireless propagation modeling.
major comments (2)
- [§3] §3 (Model Architecture and Training): The manuscript provides no description of the cVAE encoder/decoder architecture, the precise form of the evidence lower bound, the weighting of reconstruction versus KL terms, the handling of variable-length path sets, or the train/validation/test splits. Without these details the reported aggregate MAEs cannot be verified as free of overfitting or leakage, directly undermining the central claim that the model generalizes from imagery and terrain maps alone.
- [§4.3] §4.3 (Per-path and Cross-city Results): The 1.29 dB power and 7.25 ns delay MAEs are reported only in aggregate; no per-path error statistics are given for angle parameters, nor is there a breakdown of performance on paths whose reflectors lie outside the camera FOV or below terrain-map resolution. Urban ray-tracing ground truth routinely contains such occluded paths; if the cVAE cannot recover them, the per-path fidelity claim fails even when aggregate statistics appear acceptable.
minor comments (2)
- [Abstract] The title and abstract describe the method as “physics-informed,” yet the presented cVAE is a standard conditional generative model with no explicit physics constraints or ray-tracing priors inside the network; a clarifying sentence would avoid misinterpretation.
- [§5] Figure captions and axis labels in the cross-city shift plots should explicitly state the number of links per city and the exact metric used for the shift quantification.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us strengthen the reproducibility and completeness of the manuscript. We address each major comment below and have incorporated revisions to provide the requested details and analyses.
read point-by-point responses
-
Referee: [§3] §3 (Model Architecture and Training): The manuscript provides no description of the cVAE encoder/decoder architecture, the precise form of the evidence lower bound, the weighting of reconstruction versus KL terms, the handling of variable-length path sets, or the train/validation/test splits. Without these details the reported aggregate MAEs cannot be verified as free of overfitting or leakage, directly undermining the central claim that the model generalizes from imagery and terrain maps alone.
Authors: We agree that these implementation details are necessary for full reproducibility and to substantiate the generalization claims. In the revised manuscript we have expanded Section 3 with a complete description of the cVAE, including the encoder and decoder network architectures (layer counts, dimensions, and activations), the exact ELBO objective, the specific weighting coefficients between reconstruction and KL terms together with their selection rationale, the padding-and-masking strategy used to accommodate variable-length MPC sets, and the precise train/validation/test split ratios with city-wise stratification to avoid leakage. These additions allow independent verification that the reported MAEs reflect genuine generalization rather than overfitting. revision: yes
-
Referee: [§4.3] §4.3 (Per-path and Cross-city Results): The 1.29 dB power and 7.25 ns delay MAEs are reported only in aggregate; no per-path error statistics are given for angle parameters, nor is there a breakdown of performance on paths whose reflectors lie outside the camera FOV or below terrain-map resolution. Urban ray-tracing ground truth routinely contains such occluded paths; if the cVAE cannot recover them, the per-path fidelity claim fails even when aggregate statistics appear acceptable.
Authors: We acknowledge that aggregate metrics alone leave open questions about per-path fidelity, especially for angles and occluded paths. The revised manuscript now reports per-path MAE statistics for AoD and AoA (azimuth and elevation). We also add a stratified breakdown separating paths whose dominant reflectors lie inside versus outside the camera FOV or terrain-map coverage. The results show expected degradation on fully occluded paths, yet the generative model still produces aggregate channel statistics (power and delay) that remain close to ray-tracing ground truth. We have clarified in the text that the central claims concern environment-aware channel statistics rather than exact per-path recovery for every individual MPC. revision: yes
Circularity Check
No significant circularity: standard supervised generative model trained on external RT labels
full rationale
The paper trains a cVAE on ray-traced ground-truth MPC parameters (derived from explicit 3D geometry during data generation) to learn a conditional mapping from POV imagery plus terrain height maps. At inference the model applies only the learned parameters to new imagery/terrain inputs and outputs the per-path set; this is a conventional supervised learning pipeline whose outputs are not algebraically or definitionally identical to the training inputs. No self-definitional equations, fitted-input predictions, load-bearing self-citations, imported uniqueness theorems, or smuggled ansatzes appear in the abstract or described method. The central claim therefore remains independent of the target result and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Variational inference provides a tractable approximation to the posterior distribution in the conditional VAE
- domain assumption Imagery and terrain height maps encode sufficient information about propagation paths to allow accurate MPC parameter prediction
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
transformer-based cVAE ... learned slot queries ... Kendall uncertainty weighting ... ChannelViT towers
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
predicts the complete per-path MPC parameter set from point-of-view imagery and terrain height maps alone
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
ITU-R. Recommendation M.2160: Framework and Overall Objectives of the Future Devel- opment of IMT for 2030 and Beyond, 2023. URL https://www.itu.int/rec/R-REC-M. 2160/en. Accessed: 2026-01-24
work page 2030
-
[2]
6G Roadmap for Vertical Industries, 2023
Next G Alliance. 6G Roadmap for Vertical Industries, 2023. URL https://nextgalliance. org/white_papers/6g-roadmap-vertical-industries/ . ATIS, Accessed: 2026-01-24
work page 2023
-
[3]
Brinton, Mung Chiang, Kwang Taik Kim, David J
Christopher G. Brinton, Mung Chiang, Kwang Taik Kim, David J. Love, Michael Beesley, Morris Repeta, John Roese, Per Beming, Erik Ekudden, Clara Li, Geng Wu, Nishant Batra, Amitava Ghosh, V olker Ziegler, Tingfang Ji, Rajat Prakash, and John Smee. Key Focus Areas and Enabling Technologies for 6G. IEEE Communications Magazine, 63(3):84–91, 2025. doi: 10.110...
-
[4]
Hwanjin Kim, Junil Choi, and David J. Love. Machine-Learning Techniques for Wireless Channel Prediction: Insights and Practical Guidance. IEEE Wireless Communications, pages 1–8, 2026. doi: 10.1109/MWC.2026.3678210
-
[5]
Radio Propagation Measurements and Channel Modeling
Theodore S Rappaport, Kate A Remley, Camillo Gentile, Andreas F Molisch, and Alenka Zaji´c. Radio Propagation Measurements and Channel Modeling. Cambridge University Press, 2022
work page 2022
-
[6]
Mathew K. Samimi and Theodore S. Rappaport. 3-D Millimeter-Wave Statistical Channel Model for 5G Wireless System Design. IEEE Transactions on Microwave Theory and Techniques, 64 (7):2207–2225, 2016. doi: 10.1109/TMTT.2016.2574851
-
[7]
Fundamentals of Wireless Communication
David Tse and Pramod Viswanath. Fundamentals of Wireless Communication. Cambridge University Press, 2005
work page 2005
-
[8]
Study on Channel Model for Frequencies from 0.5 to 100 GHz, 2026
3rd Generation Partnership Project (3GPP). Study on Channel Model for Frequencies from 0.5 to 100 GHz, 2026. URL https://www.3gpp.org/ftp/Specs/archive/38_series/ 38.901/38901-j20.zip. TR 38.901 v19.1.0, accessed: 2026-01-24
work page 2026
-
[9]
Jakob Hoydis, Sebastian Cammerer, Fayçal Ait Aoudia, Merlin Nimier-David, Lorenzo Maggi, Guillermo Marcus, Avinash Vem, and Alexander Keller. Sionna, 2022. https://nvlabs. github.io/sionna/
work page 2022
-
[10]
Sionna RT: Differentiable Ray Tracing for Radio Propagation Modeling
Jakob Hoydis, Faycal Ait Aoudia, Sebastian Cammerer, Merlin Nimier-David, Nikolaus Binder, Guillermo Marcus, and Alexander Keller. Sionna RT: Differentiable Ray Tracing for Radio Propagation Modeling. In 2023 IEEE Globecom Workshops (GC Wkshps), pages 317–321,
work page 2023
-
[11]
doi: 10.1109/GCWkshps58843.2023.10465179
-
[12]
Shu Sun, George R. MacCartney, and Theodore S. Rappaport. A novel millimeter-wave channel simulator and applications for 5g wireless communications. In 2017 IEEE International Conference on Communications (ICC), pages 1–7, 2017. doi: 10.1109/ICC.2017.7996792
-
[13]
Wireless InSite: 3D Wireless Prediction Software, 2021
Remcom. Wireless InSite: 3D Wireless Prediction Software, 2021
work page 2021
-
[14]
ChannelGAN: Deep Learning-Based Channel Modeling and Generating
Han Xiao, Wenqiang Tian, Wendong Liu, and Jia Shen. ChannelGAN: Deep Learning-Based Channel Modeling and Generating. IEEE Wireless Communications Letters, 11(3):650–654,
-
[15]
doi: 10.1109/LWC.2021.3140102
-
[16]
Genera- tive Diffusion Models for Radio Wireless Channel Modelling and Sampling
Ushnish Sengupta, Chinkuo Jao, Alberto Bernacchia, Sattar Vakili, and Da-shan Shiu. Genera- tive Diffusion Models for Radio Wireless Channel Modelling and Sampling. In GLOBECOM 2023 - 2023 IEEE Global Communications Conference, pages 4779–4784, 2023. doi: 10.1109/GLOBECOM54140.2023.10437154
- [17]
-
[18]
Taekyun Lee, Juseong Park, Hyeji Kim, and Jeffrey G. Andrews. Generating high dimen- sional user-specific wireless channels using diffusion models. IEEE Transactions on Wireless Communications, 25:2907–2921, 2026. doi: 10.1109/TWC.2025.3600286. 11
-
[19]
WiNeRT: Towards Neural Ray Tracing for Wireless Channel Modelling and Differ- entiable Simulations
Tribhuvanesh Orekondy, Pratik Kumar, Shreya Kadambi, Hao Ye, Joseph Soriaga, and Arash Behboodi. WiNeRT: Towards Neural Ray Tracing for Wireless Channel Modelling and Differ- entiable Simulations. In The Eleventh International Conference on Learning Representations,
-
[20]
URLhttps://openreview.net/forum?id=tPKKXeW33YU
-
[21]
Kejia Bian, Meixia Tao, Shu Sun, and Jun Yu. GeNeRT: A Physics-Informed Approach to Intelligent Wireless Channel Modeling via Generalizable Neural Ray Tracing, 2025. URL https://arxiv.org/abs/2506.18295
-
[22]
Xiucheng Wang, Qiming Zhang, Nan Cheng, Junting Chen, Zezhong Zhang, Zan Li, Shuguang Cui, and Xuemin Shen. RadioDiff-3D: A 3D× 3D Radio Map Dataset and Generative Diffusion Based Benchmark for 6G Environment-Aware Communication.IEEE Transactions on Network Science and Engineering, 13:3773–3789, 2026. doi: 10.1109/TNSE.2025.3590545
-
[23]
Agrawal, Richard Newcombe, and Ahmed Alkhateeb
Shuaifeng Jiang, Qi Qu, Xiaqing Pan, Abhishek K. Agrawal, Richard Newcombe, and Ahmed Alkhateeb. Learnable wireless digital twins: Reconstructing electromagnetic field with neural representations. IEEE Open Journal of the Communications Society, 6:1568–1590, 2025. doi: 10.1109/OJCOMS.2025.3535959
-
[24]
Juseong Park, Taekyun Lee, Yunchou Xing, Jie Chen, Amitava Ghosh, and Jeffrey G. Andrews. Learning ray-tracing for radio propagation via cross-attention-based diffusion models. In 2025 59th Asilomar Conference on Signals, Systems, and Computers, pages 1210–1214, 2025. doi: 10.1109/IEEECONF67917.2025.11443807
-
[25]
RadioUNet: Fast Ra- dio Map Estimation With Convolutional Neural Networks
Ron Levie, Ça ˘gkan Yapar, Gitta Kutyniok, and Giuseppe Caire. RadioUNet: Fast Ra- dio Map Estimation With Convolutional Neural Networks. IEEE Transactions on Wireless Communications, 20(6):4001–4015, 2021. doi: 10.1109/TWC.2021.3054977
-
[26]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors,Computer Vision – ECCV 2020, pages 213–229, Cham, 2020. Springer International Publishing. ISBN 978-3-030-58452-8
work page 2020
-
[27]
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics, 2018. URL https://arxiv.org/abs/ 1705.07115
work page internal anchor Pith review Pith/arXiv arXiv 2018
- [28]
-
[29]
Rappaport, Shu Sun, Rimma Mayzus, Hang Zhao, Yaniv Azar, Kevin Wang, George N
Theodore S. Rappaport, Shu Sun, Rimma Mayzus, Hang Zhao, Yaniv Azar, Kevin Wang, George N. Wong, Jocelyn K. Schulz, Mathew Samimi, and Felix Gutierrez. Millimeter wave mobile communications for 5g cellular: It will work! IEEE Access, 1:335–349, 2013. doi: 10.1109/ACCESS.2013.2260813
-
[30]
Wenzel Jakob, Sébastien Speierer, Nicolas Roussel, Merlin Nimier-David, Delio Vicini, Tizian Zeltner, Baptiste Nicolet, Miguel Crespo, Vincent Leroy, and Ziyi Zhang. Mitsuba 3 renderer,
-
[31]
https://mitsuba-renderer.org
-
[32]
Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red H...
work page 2020
-
[33]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes, 2022. URL https: //arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Learning structured output representation using deep conditional generative models
Kihyuk Sohn, Honglak Lee, and Xinchen Yan. Learning structured output representation using deep conditional generative models. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 28. Curran Associates, Inc., 2015. URL https://proceedings.neurips.cc/paper_files/paper/ 2015/file/...
work page 2015
-
[35]
Channel vision transformers: An image is worth 1 x 16 x 16 words
Yujia Bao, Srinivasan Sivanandan, and Theofanis Karaletsos. Channel vision transformers: An image is worth 1 x 16 x 16 words. In The Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=CK5Hfb5hBG
work page 2024
-
[36]
Jakub M. Tomczak and Max Welling. Vae with a vampprior, 2018. URL https://arxiv. org/abs/1705.07120
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling
Diederik P. Kingma, Tim Salimans, Rafal Jozefowicz, Xi Chen, Ilya Sutskever, and Max Welling. Improved variational inference with inverse autoregressive flow. In Proceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, page 4743–4751, Red Hook, NY , USA, 2016. Curran Associates Inc. ISBN 9781510838819
work page 2016
-
[38]
Generating sentences from a continuous space
Samuel R Bowman, Luke Vilnis, Oriol Vinyals, Andrew M Dai, Rafal Jozefowicz, and Samy Bengio. Generating sentences from a continuous space. In 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, pages 10–21. Association for Com- putational Linguistics (ACL), 2016
work page 2016
-
[39]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization, 2019. URL https: //arxiv.org/abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[40]
Lukas Kirchdorfer, Cathrin Elich, Simon Kutsche, Heiner Stuckenschmidt, Lukas Schott, and Jan M. Köhler. Analytical uncertainty-based loss weighting in multi-task learning. International Journal of Computer Vision, 2025. doi: 10.1007/s11263-025-02625-x. Preprint: arXiv:2408.07985
-
[41]
Auxiliary Tasks in Multi-task Learning
Lukas Liebel and Marco Körner. Auxiliary tasks in multi-task learning, 2018. URL https: //arxiv.org/abs/1805.06334
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Proceedings of the 28th International Conference on Neural Information Processing Systems - V olume2, NIPS’14, page 2672–2680, Cambridge, MA, USA, 2014. MIT Press
work page 2014
-
[43]
Denoising diffusion probabilistic models, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models, 2020
work page 2020
-
[44]
Tribhuvanesh Orekondy, Arash Behboodi, and Joseph B. Soriaga. MIMO-GAN: Generative MIMO Channel Modeling, 2022
work page 2022
-
[45]
Nitish Deshpande, Sanjay Ganapathy, and Viraj Shah. Hardware-conditioned generative channel modeling: A diffusion-based approach for location and hardware-aware wireless dataset synthesis. In Open Conference of AI Agents for Science 2025, 2025. URL https: //openreview.net/forum?id=ExGHHgTM2p
work page 2025
-
[46]
Physics-informed generative modeling of wireless channels, 2025
Benedikt Böck, Andreas Oeldemann, Timo Mayer, Francesco Rossetto, and Wolfgang Utschick. Physics-informed generative modeling of wireless channels, 2025. URL https: //openreview.net/forum?id=FFJFT93oa7
work page 2025
-
[47]
Satyavrat Wagle, Akshay Malhotra, Shahab Hamidi-Rad, Aditya Sant, David J. Love, and Christopher G. Brinton. Physics-informed generative approaches for wireless channel modeling,
- [48]
-
[49]
A geometry-based stochastic wireless channel model using channel images,
Seongjoon Kang. A geometry-based stochastic wireless channel model using channel images,
- [50]
-
[51]
NeRF2: Neural Radio-Frequency Radiance Fields
Xiaopeng Zhao, Zhenlin An, Qingrui Pan, and Lei Yang. NeRF2: Neural Radio-Frequency Radiance Fields. In Proceedings of the 29th Annual International Conference on Mobile Computing and Networking, ACM MobiCom ’23, New York, NY , USA, 2023. Association for Computing Machinery. ISBN 9781450399906. doi: 10.1145/3570361.3592527. URL https://doi.org/10.1145/357...
-
[52]
Rf-3dgs: Wireless channel modeling with radio radiance field and 3d gaussian splatting, 2026
Lihao Zhang, Haijian Sun, Samuel Berweger, Camillo Gentile, and Rose Qingyang Hu. Rf-3dgs: Wireless channel modeling with radio radiance field and 3d gaussian splatting, 2026. 13
work page 2026
-
[53]
Haofan Lu, Christopher Vattheuer, Baharan Mirzasoleiman, and Omid Abari. Newrf: a deep learning framework for wireless radiation field reconstruction and channel prediction, 2024
work page 2024
-
[54]
Geo2SigMap: High-Fidelity RF Signal Mapping Using Geographic Databases
Yiming Li, Zeyu Li, Zhihui Gao, and Tingjun Chen. Geo2SigMap: High-Fidelity RF Signal Mapping Using Geographic Databases. In 2024 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), pages 277–285, 2024. doi: 10.1109/DySPAN60163. 2024.10632773
-
[55]
ITU-R. Recommendation ITU-R P.2040-3: Effects of building materials and structures on ra- diowave propagation above about 100 MHz. Technical report, International Telecommunication Union, August 2023. URLhttps://www.itu.int/rec/R-REC-P.2040-3-202308-I/en
work page 2040
-
[56]
No 3D” indicates whether the method operates without a 3D scene mesh at inference. “Per-path Delay
Zhao Chen, Vijay Badrinarayanan, Chen-Yu Lee, and Andrew Rabinovich. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks, 2018. URL https: //openreview.net/forum?id=H1bM1fZCW. 14 A Extended related work and comparison Deep learning approaches to channel modeling fall into three categories. We explore each in turn to giv...
work page 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.