Multi-level Self-supervised Pretraining on Compositional Hierarchical Graph for Molecular Property Prediction
Pith reviewed 2026-05-20 20:18 UTC · model grok-4.3
The pith
MolCHG pretrains on a compositional hierarchical graph with independent bond nodes to improve molecular property prediction on seven of nine benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
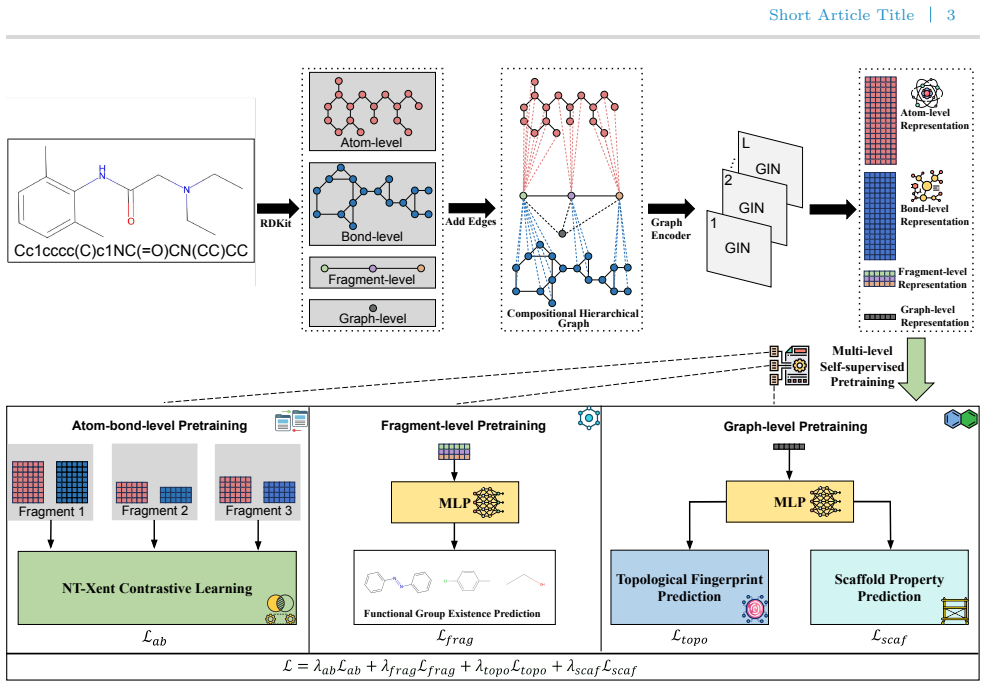
The central claim is that a Compositional Hierarchical Graph with four node types across three semantic levels, together with atom-bond cross-view contrastive learning, fragment functional group prediction, and graph-level structure prediction, produces more effective pretrained representations for downstream molecular property prediction than single-granularity baselines.
What carries the argument
The Compositional Hierarchical Graph, which defines atom nodes, parallel bond nodes, fragment nodes that aggregate both atom and bond views, and a top-level graph node to encode global topology.
If this is right
- The model achieves the best performance on seven of nine MoleculeNet benchmarks for both classification and regression tasks.
- It remains competitive with the strongest baselines on the remaining datasets.
- Ablation studies confirm that atom-bond contrastive, fragment functional group, and graph-level structure objectives each contribute to the gains.
- Bond-level information evolves as independent node representations rather than auxiliary edge attributes.
- Fragment nodes aggregate atom-level and bond-level semantics on equal footing.
Where Pith is reading between the lines
- The same multi-level structure could be tested on other relational domains such as protein interaction graphs or material composition networks.
- Explicit bond representations may improve downstream tasks that involve bond formation or cleavage, such as reaction prediction.
- Combining the pretrained encoder with larger chemistry language models might yield better few-shot generalization on property tasks outside the current benchmarks.
Load-bearing premise
The three level-specific pretraining objectives supply complementary supervision signals that each improve downstream performance when used together.
What would settle it
An ablation experiment in which removing any one of the three pretraining tasks produces no drop, or even an improvement, in accuracy on the MoleculeNet benchmarks would falsify the complementarity premise.
Figures



read the original abstract
Self-supervised pretraining on molecular graphs has emerged as a promising approach for molecular property prediction, yet most existing methods operate at a single structural granularity and treat bond information as auxiliary edge attributes rather than as an independent semantic layer. In this work, we propose MolCHG, a multi-level self-supervised pretraining framework built upon a novel Compositional Hierarchical Graph that organizes molecular structure into four types of nodes across three semantic levels. By introducing a bond graph that operates in parallel with the atom graph, our architecture elevates bond-level information to independently evolving node representations, enabling fragment nodes to aggregate atom-level and bond-level semantics on an equal footing. We design three level-specific pretraining objectives: an atom-bond cross-view contrastive task that aligns the atom-view and bond-view representations within each fragment, a fragment-level functional group prediction task to inject domain-relevant chemical knowledge, and graph-level structure prediction tasks to encode global molecular topology. Experiments on nine MoleculeNet benchmarks demonstrate that MolCHG achieves the best performance on seven datasets across both classification and regression tasks, remaining competitive with the strongest baselines on the rest. Ablation studies further confirm that the multi-level supervision signals are complementary and that each component contributes to the overall performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MolCHG, a multi-level self-supervised pretraining framework for molecular property prediction built on a novel Compositional Hierarchical Graph (CHG). The CHG organizes molecular structure into four node types across three semantic levels, with a parallel bond graph that elevates bond information to independently evolving node representations. Three level-specific pretraining objectives are defined: an atom-bond cross-view contrastive task, a fragment-level functional group prediction task, and graph-level structure prediction tasks. Experiments on nine MoleculeNet benchmarks report that MolCHG achieves the best performance on seven datasets (both classification and regression), with ablations indicating that the multi-level signals are complementary.
Significance. If the reported gains prove robust under rigorous statistical evaluation, the work could meaningfully advance self-supervised graph learning for molecules by treating bonds as a first-class semantic layer and injecting domain knowledge at multiple granularities. The parallel bond-graph design and the combination of contrastive, functional-group, and topology objectives represent a coherent extension beyond single-granularity pretraining methods and may yield more transferable representations for downstream chemical tasks.
major comments (2)
- [Experiments / Results] Experimental section (results and ablations): the central claim that MolCHG outperforms baselines on seven of nine MoleculeNet tasks is only partially supported because the manuscript provides no error bars, no statistical significance tests, no explicit description of data splits or random seeds, and no details on whether baselines were re-implemented with identical hyperparameters. These omissions are load-bearing for the performance comparison.
- [Ablation studies] Ablation studies: while the abstract states that the three supervision signals are complementary, the manuscript does not quantify the marginal contribution of each objective (e.g., via incremental addition or removal) with the same rigor applied to the main results, leaving the weakest assumption in the reader's report only weakly substantiated.
minor comments (2)
- [Method / Graph Construction] Notation for the four node types and three semantic levels is introduced without a compact summary table or diagram legend, making it difficult to track which node type participates in which pretraining objective.
- [Experiments] The manuscript should cite the exact MoleculeNet dataset versions and preprocessing pipelines used, as small differences in featurization can affect reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. These suggestions highlight important aspects of experimental rigor that will strengthen the presentation of our results. We address each major comment below and commit to incorporating the necessary revisions in the updated version.
read point-by-point responses
-
Referee: [Experiments / Results] Experimental section (results and ablations): the central claim that MolCHG outperforms baselines on seven of nine MoleculeNet tasks is only partially supported because the manuscript provides no error bars, no statistical significance tests, no explicit description of data splits or random seeds, and no details on whether baselines were re-implemented with identical hyperparameters. These omissions are load-bearing for the performance comparison.
Authors: We agree that the absence of error bars, statistical significance tests, and explicit experimental protocol details weakens the support for the performance claims. In the revised manuscript we will report mean performance and standard deviation across multiple independent runs with different random seeds, include statistical significance tests (e.g., paired t-tests or Wilcoxon tests) against the strongest baselines, explicitly state the data splitting strategy (scaffold splits following MoleculeNet conventions), list the random seeds used, and clarify that all baselines were re-implemented or re-evaluated under identical conditions using the same data splits and hyperparameter settings where feasible. These additions will be placed in the experimental section and supplementary material. revision: yes
-
Referee: [Ablation studies] Ablation studies: while the abstract states that the three supervision signals are complementary, the manuscript does not quantify the marginal contribution of each objective (e.g., via incremental addition or removal) with the same rigor applied to the main results, leaving the weakest assumption in the reader's report only weakly substantiated.
Authors: We concur that a more granular quantification of each pretraining objective’s marginal contribution would better substantiate the complementarity claim. We will expand the ablation studies to present incremental addition experiments (starting from a base model and successively adding the atom-bond contrastive task, the functional-group prediction task, and the graph-level structure tasks) as well as removal experiments. All ablation results will be reported with error bars and accompanied by statistical significance tests to demonstrate that each signal provides a measurable, complementary improvement. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces a novel Compositional Hierarchical Graph architecture with three explicitly defined self-supervised pretraining objectives (atom-bond cross-view contrastive task, fragment-level functional group prediction, and graph-level structure prediction) that operate without reference to downstream molecular property labels. Performance claims rest on empirical results across standard MoleculeNet benchmarks plus ablation studies that isolate each component's contribution. No equations, fitting procedures, or self-citation chains reduce the reported gains to quantities defined by the same inputs or parameters used in evaluation; the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Compositional Hierarchical Graph with four node types across three semantic levels and parallel bond graph
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By introducing a bond graph that operates in parallel with the atom graph, our architecture elevates bond-level information to independently evolving node representations, enabling fragment nodes to aggregate atom-level and bond-level semantics on an equal footing.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We design three level-specific pretraining objectives: an atom–bond cross-view contrastive task... fragment-level functional group prediction... graph-level structure prediction tasks
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Zhaoping Xiong, Dingyan Wang, Xiaohong Liu, Feisheng Zhong, Xiaozhe Wan, Xutong Li, Zhaojun Li, Xiaomin Luo, Kaixian Chen, Hualiang Jiang, et al. Pushing the boundaries of molecular representation for drug discovery with the graph attention mechanism.Journal of medicinal chemistry, 63(16):8749–8760, 2019
work page 2019
-
[2]
Sgac: a graph neural network framework for imbalanced and structure-aware amp classification
Yingxu Wang, Victor Liang, Nan Yin, Siwei Liu, and Eran Segal. Sgac: a graph neural network framework for imbalanced and structure-aware amp classification. Briefings in Bioinformatics, 27(1):bbag038, 2026
work page 2026
-
[3]
Hi-mgt: a hybrid molecule graph transformer for 10 Author Name et al
Zhichao Tan, Youcai Zhao, Tao Zhou, and Kunsen Lin. Hi-mgt: a hybrid molecule graph transformer for 10 Author Name et al. toxicity identification.Journal of Hazardous Materials, 457:131808, 2023
work page 2023
-
[4]
Haohui Zhang, Juntong Wu, Shichao Liu, and Shen Han. A pre-trained multi-representation fusion network for molecular property prediction.Information Fusion, 103:102092, 2024
work page 2024
-
[5]
Ruizhe Chen, Chunyan Li, Longyue Wang, Mingquan Liu, Shugao Chen, Jiahao Yang, and Xiangxiang Zeng. Pretraining graph transformer for molecular representation with fusion of multimodal information.Information Fusion, 115:102784, 2025
work page 2025
-
[6]
Xiuyu Jiang, Liqin Tan, and Qingsong Zou. Dgcl: dual- graph neural networks contrastive learning for molecular property prediction.Briefings in Bioinformatics, 25(6):bbae474, 2024
work page 2024
-
[7]
Wenbo Zhang, Yihui Wang, Jin Liu, Bowen Ke, Jiancheng Lv, and Xianggen Liu. Task-specific pre- training for molecular property prediction.Briefings in Bioinformatics, 27(1):bbag010, 2026
work page 2026
-
[8]
Yuankai Luo, Lei Shi, and Veronika Thost. Improving self-supervised molecular representation learning using persistent homology.Advances in Neural Information Processing Systems, 36:34043–34073, 2023
work page 2023
-
[9]
Pengyong Li, Jun Wang, Yixuan Qiao, Hao Chen, Yihuan Yu, Xiaojun Yao, Peng Gao, Guotong Xie, and Sen Song. An effective self-supervised framework for learning expressive molecular global representations to drug discovery.Briefings in Bioinformatics, 22(6):bbab109, 2021
work page 2021
-
[10]
Yuyang Wang, Jianren Wang, Zhonglin Cao, and Amir Barati Farimani. Molecular contrastive learning of representations via graph neural networks.Nature Machine Intelligence, 4(3):279–287, 2022
work page 2022
-
[11]
Strategies for pre-training graph neural networks
Weihua Hu, Bowen Liu, Joseph Gomes, Marinka Zitnik, Percy Liang, Vijay Pande, and Jure Leskovec. Strategies for pre-training graph neural networks.arXiv preprint arXiv:1905.12265, 2019
-
[12]
Jiele Wu, Haozhe Ma, Zhihan Guo, Thanh Vinh Vo, and Tze Yun Leong. Hierarchical molecular representation learning via fragment-based self-supervised embedding prediction.arXiv preprint arXiv:2602.20344, 2026
-
[13]
Molclw: Molecular contrastive learning with learnable weighted substructures
Jiahe Li, Wenjie Du, and Yang Wang. Molclw: Molecular contrastive learning with learnable weighted substructures. In2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pages 828–831. IEEE, 2024
work page 2024
-
[14]
Motif-driven contrastive learning of graph representations
Shichang Zhang, Ziniu Hu, Arjun Subramonian, and Yizhou Sun. Motif-driven contrastive learning of graph representations.arXiv preprint arXiv:2012.12533, 2020
-
[15]
Zaixi Zhang, Qi Liu, Hao Wang, Chengqiang Lu, and Chee-Kong Lee. Motif-based graph self-supervised learning for molecular property prediction.Advances in Neural Information Processing Systems, 34:15870–15882, 2021
work page 2021
-
[16]
Kha-Dinh Luong and Ambuj K Singh. Fragment-based pretraining and finetuning on molecular graphs.Advances in Neural Information Processing Systems, 36:17584– 17601, 2023
work page 2023
-
[17]
Kevin Yang, Kyle Swanson, Wengong Jin, Connor Coley, Philipp Eiden, Hua Gao, Angel Guzman-Perez, Timothy Hopper, Brian Kelley, Miriam Mathea, et al. Analyzing learned molecular representations for property prediction.Journal of chemical information and modeling, 59(8):3370–3388, 2019
work page 2019
-
[18]
Communicative representation learning on attributed molecular graphs
Ying Song, Shuangjia Zheng, Zhangming Niu, Zhang-Hua Fu, Yutong Lu, and Yuedong Yang. Communicative representation learning on attributed molecular graphs. In29th International Joint Conference on Artificial Intelligence and the 17th Pacific Rim International Conference on Artificial Intelligence (IJCAI-PRICAI2020). International Joint Conferences on Arti...
work page 2020
-
[19]
Yunqing Liu, Yi Zhou, and Wenqi Fan. Enhancing molecular property predictions by learning from bond modelling and interactions.arXiv preprint arXiv:2603.00568, 2026
-
[20]
Xuan Zang, Xianbing Zhao, and Buzhou Tang. Hierarchical molecular graph self-supervised learning for property prediction.Communications Chemistry, 6(1):34, 2023
work page 2023
-
[21]
A hierarchical interaction message net for accurate molecular property prediction
Huiyang Hong, Xinkai Wu, Hongyu Sun, Chaoyang Xie, Qi Wang, and Yuquan Li. A hierarchical interaction message net for accurate molecular property prediction. Communications Chemistry, 2026
work page 2026
-
[22]
Xiangzhe Kong, Wenbing Huang, Zhixing Tan, and Yang Liu. Molecule generation by principal subgraph mining and assembling.Advances in Neural Information Processing Systems, 35:2550–2563, 2022
work page 2022
-
[23]
On the art of compiling and using’drug-like’chemical fragment spaces.ChemMedChem, 3(10):1503, 2008
Jorg Degen, Christof Wegscheid-Gerlach, Andrea Zaliani, and Matthias Rarey. On the art of compiling and using’drug-like’chemical fragment spaces.ChemMedChem, 3(10):1503, 2008
work page 2008
-
[24]
Gihan Panapitiya, Peiyuan Gao, C Mark Maupin, and Emily G Saldanha. Fragnet: a graph neural network for molecular property prediction with four levels of interpretability.Journal of the American Chemical Society, 148(9):9930–9950, 2026
work page 2026
-
[25]
Moleculenet: a benchmark for molecular machine learning.Chemical science, 9(2):513– 530, 2018
Zhenqin Wu, Bharath Ramsundar, Evan N Feinberg, Joseph Gomes, Caleb Geniesse, Aneesh S Pappu, Karl Leswing, and Vijay Pande. Moleculenet: a benchmark for molecular machine learning.Chemical science, 9(2):513– 530, 2018
work page 2018
-
[26]
O-Joun Lee et al. Pre-training graph neural networks on molecules by using subgraph-conditioned graph information bottleneck. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 17204–17213, 2025
work page 2025
-
[27]
Teague Sterling and John J Irwin. Zinc 15–ligand discovery for everyone.Journal of chemical information and modeling, 55(11):2324–2337, 2015
work page 2015
-
[28]
How Powerful are Graph Neural Networks?
Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks?arXiv preprint arXiv:1810.00826, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Will Hamilton, Zhitao Ying, and Jure Leskovec. Inductive representation learning on large graphs.Advances in neural information processing systems, 30, 2017
work page 2017
-
[30]
Petar Veliˇ ckovi´ c, William Fedus, William L Hamilton, Pietro Li` o, Yoshua Bengio, and R Devon Hjelm. Deep graph infomax.arXiv preprint arXiv:1809.10341, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
Graph contrastive learning automated
Yuning You, Tianlong Chen, Yang Shen, and Zhangyang Wang. Graph contrastive learning automated. In International conference on machine learning, pages 12121–12132. PMLR, 2021
work page 2021
-
[32]
Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. Graph contrastive learning with augmentations.Advances in neural information processing systems, 33:5812–5823, 2020
work page 2020
-
[33]
Minghao Xu, Hang Wang, Bingbing Ni, Hongyu Guo, and Jian Tang. Self-supervised graph-level representation Short Article Title 11 learning with local and global structure. InInternational conference on machine learning, pages 11548–11558. PMLR, 2021
work page 2021
-
[34]
Yu Rong, Yatao Bian, Tingyang Xu, Weiyang Xie, Ying Wei, Wenbing Huang, and Junzhou Huang. Self-supervised graph transformer on large-scale molecular data.Advances in neural information processing systems, 33:12559–12571, 2020
work page 2020
-
[35]
Zhiyuan Liu, Yaorui Shi, An Zhang, Enzhi Zhang, Kenji Kawaguchi, Xiang Wang, and Tat-Seng Chua. Rethinking tokenizer and decoder in masked graph modeling for molecules.Advances in Neural Information Processing Systems, 36:25854–25875, 2023
work page 2023
-
[36]
Motif-aware attribute masking for molecular graph pre-training.arXiv preprint arXiv:2309.04589, 2023
Eric Inae, Gang Liu, and Meng Jiang. Motif-aware attribute masking for molecular graph pre-training.arXiv preprint arXiv:2309.04589, 2023
-
[37]
Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9(11), 2008
work page 2008
-
[38]
David L Davies and Donald W Bouldin. A cluster separation measure.IEEE transactions on pattern analysis and machine intelligence, (2):224–227, 1979
work page 1979
-
[39]
Peter J Rousseeuw. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis.Journal of computational and applied mathematics, 20:53–65, 1987
work page 1987
-
[40]
Guy W Bemis and Mark A Murcko. The properties of known drugs. 1. molecular frameworks.Journal of medicinal chemistry, 39(15):2887–2893, 1996
work page 1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.