DialSort: Non-Comparative Integer Sorting via the Self-Indexing Principle: Architecture, Implementation, and Substrate-Aware Analysis
Pith reviewed 2026-05-19 20:29 UTC · model grok-4.3
The pith
DialSort sorts bounded-universe integers by treating the histogram of counts as the final ordered sequence, eliminating the prefix-sum step through direct key indexing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DialSort eliminates the prefix-sum pass entirely by treating the histogram H as the canonical ordered representation, not as an intermediate structure. Each integer key simultaneously encodes its value and its canonical position in the ordered address space [0, U-1]. To support parallel ingestion without serialization, the Conflict Resolution Network resolves concurrent writes using equality checks exclusively, with no magnitude comparisons. Formal proofs establish O(n+U) sequential and O(n/k + log k + U) parallel time bounds.
What carries the argument
the self-indexing principle, under which each key value maps directly to a fixed index in the histogram array that then serves as the sorted output
If this is right
- Sequential execution finishes in O(n + U) time for n keys drawn from a universe of size U.
- A k-thread parallel version finishes in O(n/k + log k + U) time.
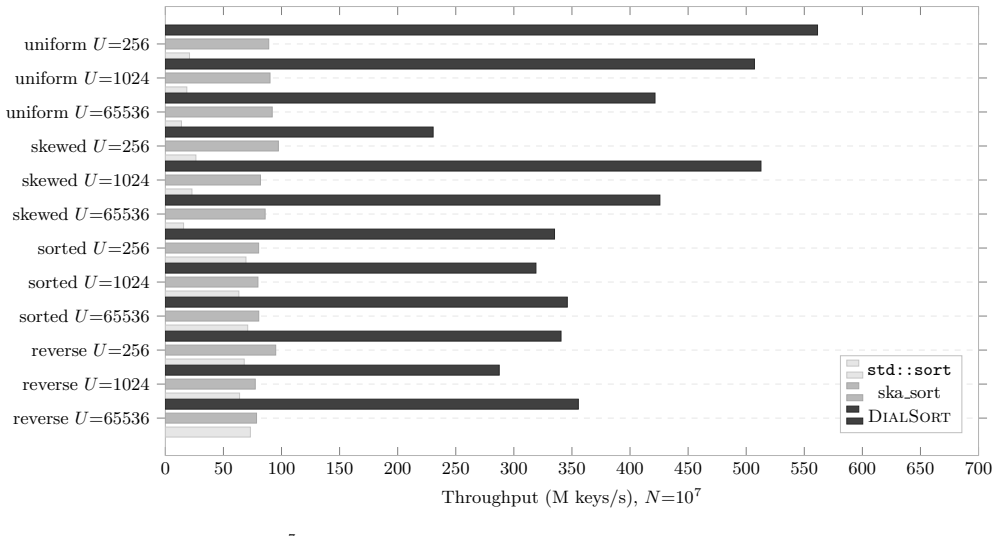
- A prototype on 8-thread x86 hardware reaches 39.77 times the speed of std::sort for suitable inputs.
- The method beats classic counting sort in 46 of 48 tested configurations and requires no auxiliary scatter buffer.
Where Pith is reading between the lines
- Range-compression steps could be added upstream so that inputs with unknown or large ranges still fit the bounded-U premise.
- The pipelined additive reduction tree used for conflict resolution may apply to other concurrent counting or aggregation tasks.
- Hardware designs that accelerate equality-checked writes could raise the observed throughput beyond the current 115.9 million keys per second.
- The same direct-mapping idea might shorten passes in related bounded-universe tasks such as frequency tables or bucket partitioning.
Load-bearing premise
All input keys are non-negative integers that lie inside a known upper bound U small enough to allocate a histogram array of size U.
What would settle it
Run the algorithm on the input [3, 1, 4, 1, 5] with declared U equal to 6 and check whether the histogram array ends up containing the values in ascending order with no separate prefix-sum calculation performed.
Figures










read the original abstract
Sorting over bounded-universe integer keys has traditionally relied on counting sort and radix sort, both of which incur mandatory prefix-sum passes, auxiliary scatter buffers, or multiple permutation passes. This paper introduces DialSort, a non-comparative sorting architecture based on the self-indexing principle: each integer key simultaneously encodes its value and its canonical position in the ordered address space [0,U-1]. DialSort eliminates the prefix-sum pass entirely by treating the histogram H as the canonical ordered representation, not as an intermediate structure. To support parallel ingestion without serialization, we introduce the Conflict Resolution Network (CRN), a pipelined additive reduction tree that resolves concurrent writes using equality checks exclusively, with no magnitude comparisons. Formal proofs establish O(n+U) sequential and O(n/k + log k + U) parallel time bounds. A software prototype on an 8-thread Intel x86-64 achieves 39.77x speedup over std::sort and peak throughput of 115.9 M keys/s. Against Classic Counting Sort, DialSort wins 46 of 48 configurations. Against IPS4o, DialSort outperforms it in 24 of 48 sequential and 29 of 48 parallel configurations. Against ska_sort, it wins 46 of 48 configurations. All 208 benchmark configurations passed correctness verification. DialSort is not a universal replacement for comparison-based sorting, but a domain-specialized architecture for bounded-universe workloads where sorting reduces to a geometric read over memory. Benchmark source and five open interactive simulators are released alongside this paper.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DialSort, a non-comparative sorting architecture for bounded-universe non-negative integers based on the self-indexing principle. Keys map directly to positions in a histogram H, which is used as the canonical ordered representation, eliminating the prefix-sum pass. The Conflict Resolution Network (CRN) enables parallel processing by resolving concurrent writes with equality checks. Formal proofs claim O(n+U) sequential and O(n/k + log k + U) parallel time bounds. A prototype achieves 39.77x speedup over std::sort, wins against Classic Counting Sort in 46/48 configs, and all 208 benchmarks pass correctness verification.
Significance. This work provides a specialized sorting method that could offer performance advantages in domains with known small universe sizes, such as certain data processing tasks. The empirical speedups and open-source release of benchmarks and simulators are notable strengths, supporting reproducibility. The approach innovates on traditional counting sort by avoiding prefix sums through direct use of the histogram for ordered output generation.
minor comments (4)
- Clarify in the architecture section how the sorted output is explicitly constructed from the histogram H to confirm the elimination of any equivalent linear pass.
- Provide more details on the CRN implementation, including how equality checks are used in the reduction tree, perhaps with pseudocode or a figure reference.
- In the benchmark section, specify the exact values of U, n, and thread counts (k) used in the 48 configurations for each comparison to aid reproducibility.
- The abstract mentions 'Substrate-Aware Analysis'; expand on this in the main text, explaining what substrate means in this context (e.g., hardware or memory model).
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work and for recommending minor revision. The referee correctly identifies the core innovations of DialSort, including the elimination of the prefix-sum pass via self-indexing, the role of the Conflict Resolution Network, the stated time bounds, and the empirical results across the benchmark suite. We appreciate the acknowledgment of the open-source artifacts and reproducibility support.
Circularity Check
Derivation chain is self-contained with no circular reductions
full rationale
The paper derives its O(n+U) sequential and O(n/k + log k + U) parallel time bounds directly from the described architecture: a single pass to build histogram H in O(n) time followed by an ordered traversal over [0, U-1] that emits each key according to its count in O(U + n) time. The CRN is introduced as a pipelined reduction tree using only equality checks for conflict resolution, yielding the parallel bound by construction from the tree depth and per-key work. These follow from the explicit steps and the self-indexing principle (keys as direct indices into [0, U-1]) under the stated precondition of known bounded U. No equations or claims reduce a result to a fitted parameter or prior self-citation; benchmarks are reported as separate empirical measurements. The bounded-universe assumption is a domain precondition, not a circularly derived claim.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Input keys are non-negative integers drawn from a known bounded universe [0, U-1].
- domain assumption U is small enough that an array of size U fits in memory.
invented entities (1)
-
Conflict Resolution Network (CRN)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
each integer key k simultaneously encodes its value and its canonical position in the ordered address space [0,U−1]. DialSort eliminates the prefix-sum pass entirely by treating the histogram H[·] as the canonical ordered representation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Conflict Resolution Network (CRN), a pipelined additive reduction tree that resolves concurrent writes using equality checks exclusively, with no magnitude comparisons
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. E. Knuth,The Art of Computer Program- ming, Vol. 3: Sorting and Searching, 2nd ed. Addison-Wesley, 1998
work page 1998
-
[2]
T. H. Cormen, C. E. Leiserson, R. L. Rivest, and C. Stein,Introduction to Algorithms, 3rd ed. MIT Press, 2009
work page 2009
-
[3]
In-place parallel super scalar sam- plesort (IPS 4o),
M. Axtmann, S. Witt, D. Ferizovic, and P. Sanders, “In-place parallel super scalar sam- plesort (IPS 4o),”ACM Trans. Parallel Com- put., vol. 9, no. 1, pp. 1–62, 2022
work page 2022
-
[4]
P. Sanders and S. Winkel, “Super scalar sam- ple sort,” inProc. ESA, 2004, pp. 784–796
work page 2004
-
[5]
Information sorting in the application of electronic digital computers to business operations,
H. H. Seward, “Information sorting in the application of electronic digital computers to business operations,” MIT, Tech. Rep., 1954
work page 1954
-
[6]
Sorting networks and their ap- plications,
K. E. Batcher, “Sorting networks and their ap- plications,” inAFIPS Spring Joint Comput. Conf., 1968, pp. 307–314
work page 1968
-
[7]
On the computational power of bead sort,
N. Auger, C. Nicaud, and C. Pivoteau, “On the computational power of bead sort,” RAIRO – Theor. Inform. Appl., vol. 46, no. 3, pp. 381–393, 2012
work page 2012
-
[8]
Prefix sums and their appli- cations,
G. E. Blelloch, “Prefix sums and their appli- cations,” CMU School of Computer Science Tech. Rep. CMU-CS-90-190, 1990
work page 1990
-
[9]
R. Sedgewick and K. Wayne,Algorithms, 4th ed. Addison-Wesley, 2011,§6.8. 24
work page 2011
-
[10]
A new sort algorithm: self- indexed sort,
S. Y. Wang, “A new sort algorithm: self- indexed sort,”ACM SIGPLAN Notices, vol. 31, no. 3, pp. 28–36, 1996
work page 1996
-
[11]
Integer sorting inO(n √log logn) expected time and linear space,
Y. Han and M. Thorup, “Integer sorting inO(n √log logn) expected time and linear space,” inProc. IEEE FOCS, 2002, pp. 135– 144
work page 2002
-
[12]
Alveo U50 data center accelerator card data sheet,
Xilinx Inc., “Alveo U50 data center accelerator card data sheet,” DS965, 2021
work page 2021
-
[13]
Wafer-Scale Engine 3 (WSE-3) Data Sheet,
Cerebras Systems, “Wafer-Scale Engine 3 (WSE-3) Data Sheet,” DS03 v3, 2024
work page 2024
-
[14]
Supercharge your HPC research with the Cerebras SDK,
Cerebras Systems, “Supercharge your HPC research with the Cerebras SDK,”Tech- nical Blog, March 2025.https://www. cerebras.ai/blog/supercharge-your- hpc-research-with-the-cerebras-sdk 25
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.